redis数据结构
-
string
采取分配冗余空间的方式减少内存频繁分配
当字符串长度少于1MB,扩容都是成倍扩展
当字符串长度大于1MB,每次只会多扩1MB
字符串长度最大为512MB
字符串由多个字节组成,每个字节由8bit组成,就是bitmap(位图)数据结构 -
list
相当于java中的LinkedList
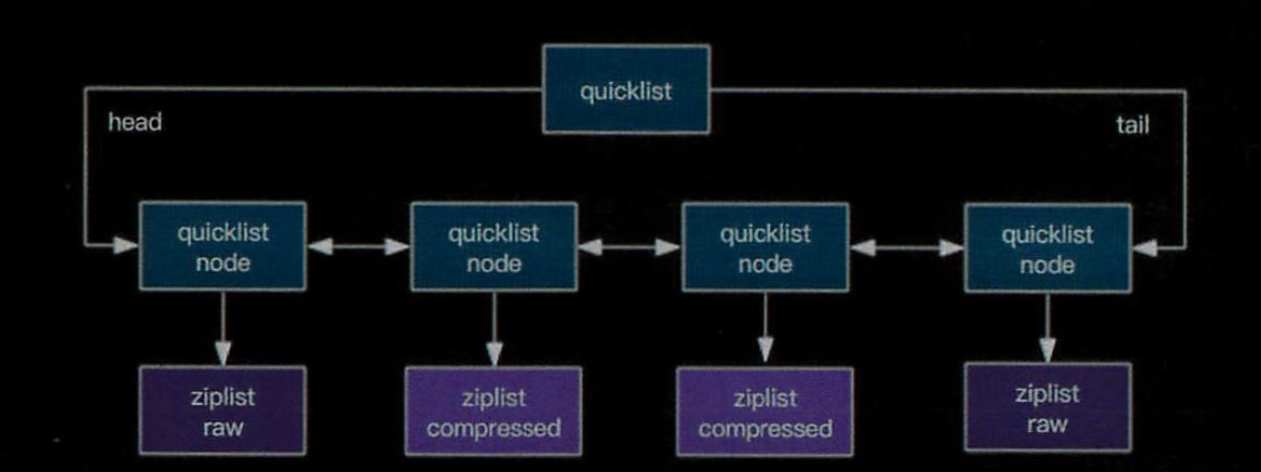
redis底层存储的是quicklist 快速链表
数据量少的时候是ziplist,数据量大的时候改成quicklist
quicklist就是多个ziplist连在一起

-
hash
redis的hash只能是字符串,
rehash是渐进式rehash
在渐进式rehash时,会保留新旧两个hash结构,查询会同时查询两个hash结构,然后在定时任务中渐渐将旧的结构的数据迁移到新的结构 -
set
低层是hashset -
zset
类似于java的soreset和hashmap的结合体
分布式锁
分布式锁需要设置和超时为原子命令
set a a expire 5 nx
超时问题:如果加锁和释放锁之间逻辑执行太长,超出了锁的超时限制,建议分布式锁下的程序执行时间尽量短
解决办法:将set的value设置成随机值,避免别的线程将自己的锁释放,确保当前线程占有的锁不会被其他线程释放掉
除非这个锁是因为到期了而被释放
- 可重入性
如果一个锁支持同一个线程同时加锁,那么这个锁就是可重入的
如果redis要支持可重入锁,需要对客户端的set方法进行包装,使用ThreadLocal变量存储当前持有锁的计数
尽量避免使用可重入锁
延时队列
实现阻塞队列: 使用blpop和brpop取出数据,没有数据的时候阻塞
队列空了:可以使用阻塞指令,但是要注意超时的情况, 可以使用轮询的方式,比较耗性能,可以加sleep让cpu降下来
分布式锁冲突处理: 1.直接抛异常 2.sleep后重试 3.将请求转移到延迟队列,稍后重试
延时队列: 通过zset有序列表实现,将消息序列化成zset的value,到期时间设置为score,然后用多个线程轮询到期的任务
位图
用于用户签到类业务,365天只需要365bit
位图的数组是自动扩展的,如果设置的某个偏移位超出了现有内容范围,则自动将数组进行零扩充
setbit s 1 1
getbit s 1
Scan
因为keys * 容易导致阻塞,所以用scan替代keys
scan 0 match a* count 1000
大key扫描
如果key太大,会导致数据迁移卡顿
如果需要扩容的时候,会一次性申请一块大的内存,会导致卡顿,
如果key被删除,会一次性回收一块大的内存,也会导致卡顿
- 扫描大key

redis单线程
1.基于内存
2.多路复用:select系列事件轮询api,非阻塞io
- 指令队列:客户端指令通过队列顺序处理
- 响应队列
- 定时任务
redis持久化
使用操作系统的多进程Copy On Write机制进行
RDB: fork一个子进程做持久化,当父进程修改数据,会先拷贝一份出来修改
所以在子进程建立后,数据是不会变化的
AOF: redis会先执行指令再保存日志
AOF重写: 开辟一个子进程对内存遍历,转换成一系列redis操作指令,序列化到一个新的AOF日志文件,序列化完成后,再将增量AOF日志追加,完成后替换旧的AOF文件
- redis4.0增加混合持久化,重启的时候先加载rdb的内容,然后再加载aof日志,代替了之前的AOF全量文件重放
redis集群
redis主从同步是异步的,不满足一致性
主节点修改数据后会立即返回,从节点会尽量追赶主节点,redis保证数据最终一致性
- 增量同步
主节点将指令记录在本地的buffer中,然后异步将buffer同步到从节点
从节点一边执行同步指令流,一边向主节点反馈自己同步到哪里了 - 快照同步
首先在主节点执行一次bgsave
将当前内存数据全部都保存到磁盘文件中
再将快照传到从节点
从节点加载完成后再通知主节点进行增量同步
sentinel(哨兵)
当主节点挂掉,会选一个最优从节点变成主节点
客户端先连接sentinel,通过sentinel查询主节点的地址,然后和主节点进行数据交互
当主节点发生故障,客户端会向哨兵重新获取主节点地址
codis
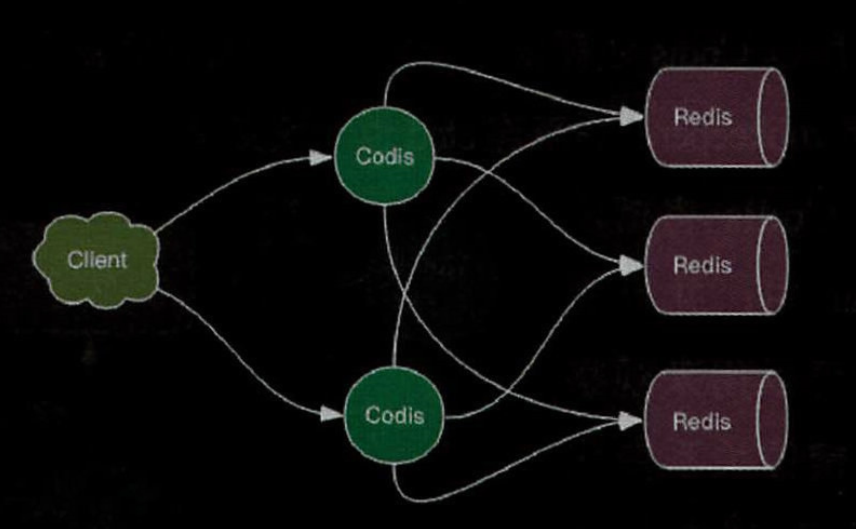
codis默认将所有key划分为1024个槽位,首先对客户端传过来的key进行crc32运算计算hash值,再将hash后的整数值对1024取余就是槽位
-
自动迁移:
增加新的redis实例后,遍历指定slot下所有key,Codis通过SLOTSSCAN扫描出待迁移槽位所有key,然后挨个迁移每个key到新的redis节点 -
自动均衡
在系统空闲的时候观察每个redis实例对应的slot数量,如果不平衡会自动进行迁移 -
codis集群配置中心使用zookeeper
-
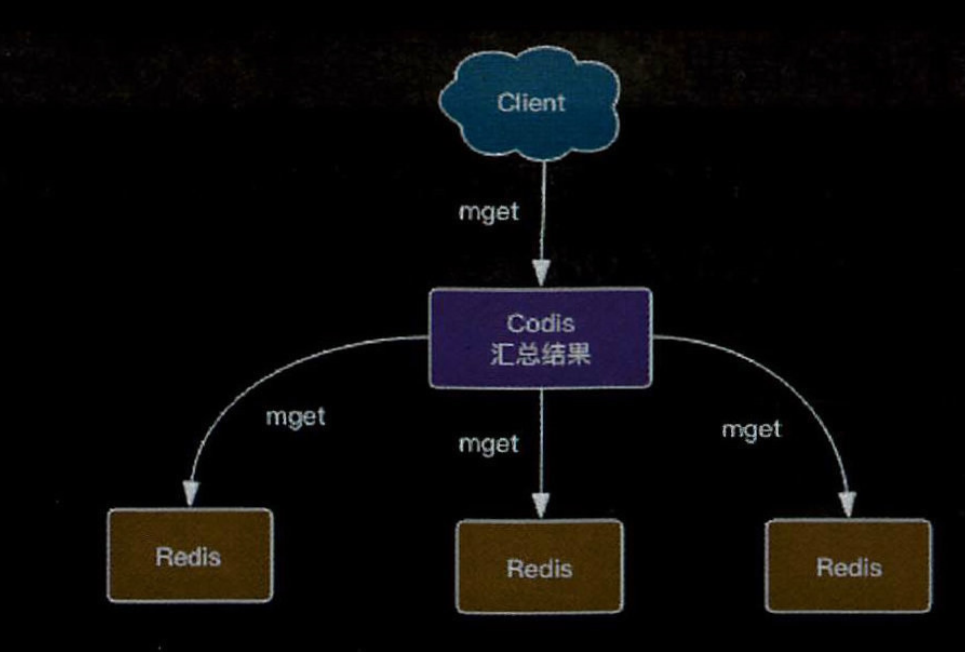
执行mget
redis cluster
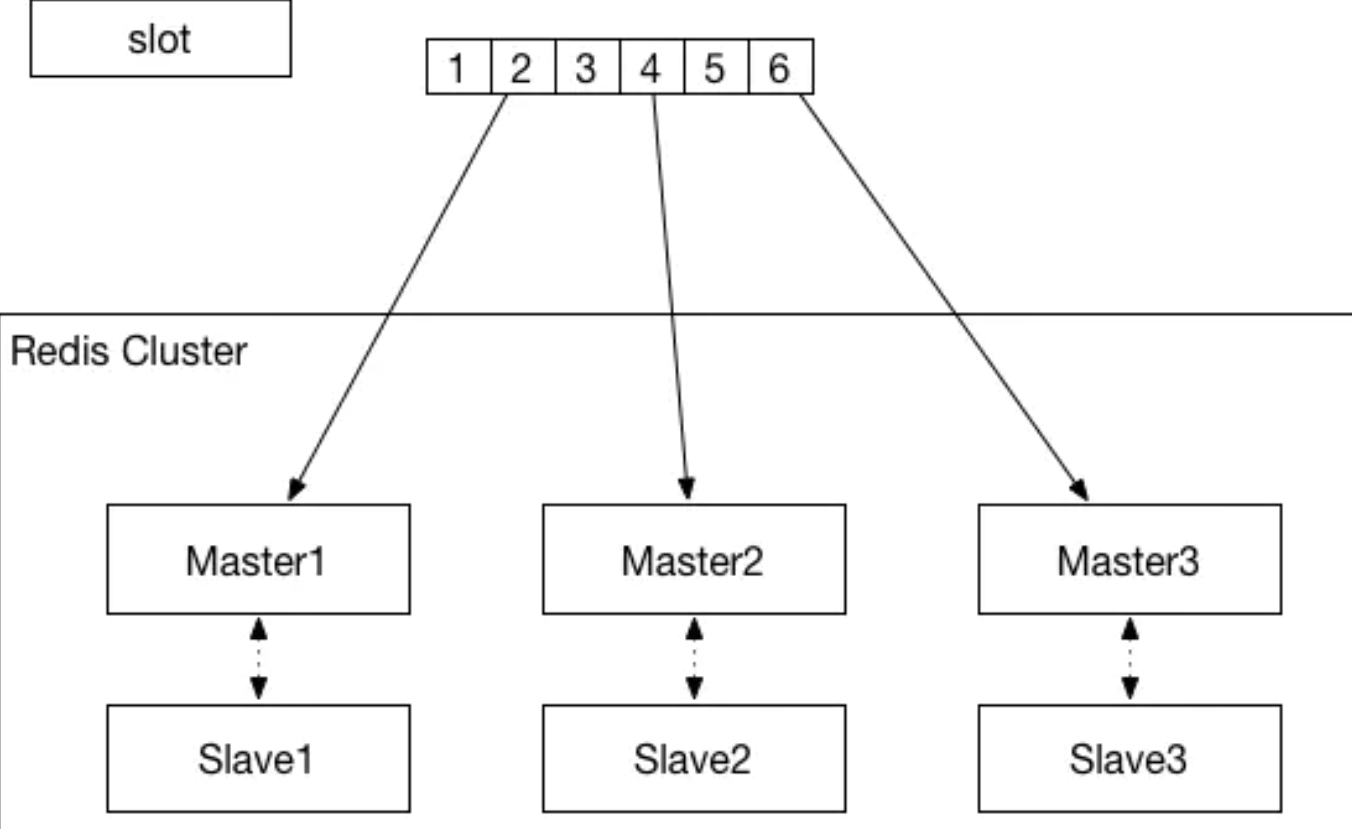
redis cluster由最少3个节点组成
每个节点负责一部分数据
三个节点连接成对等的集群
一共分成16384个槽
Redis集群,要保证16384个槽对应的node都正常工作,如果某个node发生故障,那它负责的slots也就失效,整个集群将不能工作。
为了增加集群的可访问性,官方推荐的方案是将node配置成主从结构,即一个master主节点,挂n个slave从节点。这时,如果主节点失效,Redis Cluster会根据选举算法从slave节点中选择一个上升为主节点,整个集群继续对外提供服务,Redis Cluster本身提供了故障转移容错的能力。
从节点过期策略
从节点不会进行定期扫描,从节点对过期处理是被动的
主节点在key过期后会在AOF写入一个del命令,然后同步到从节点
字符串
字符串叫sds
sds结构:

长度短时,用embstr存储
长度超过44字节,用raw形式存储
list
单个ziplist为8kb,如果超出会新建一个ziplist