【寒假作业三】
作业效果图
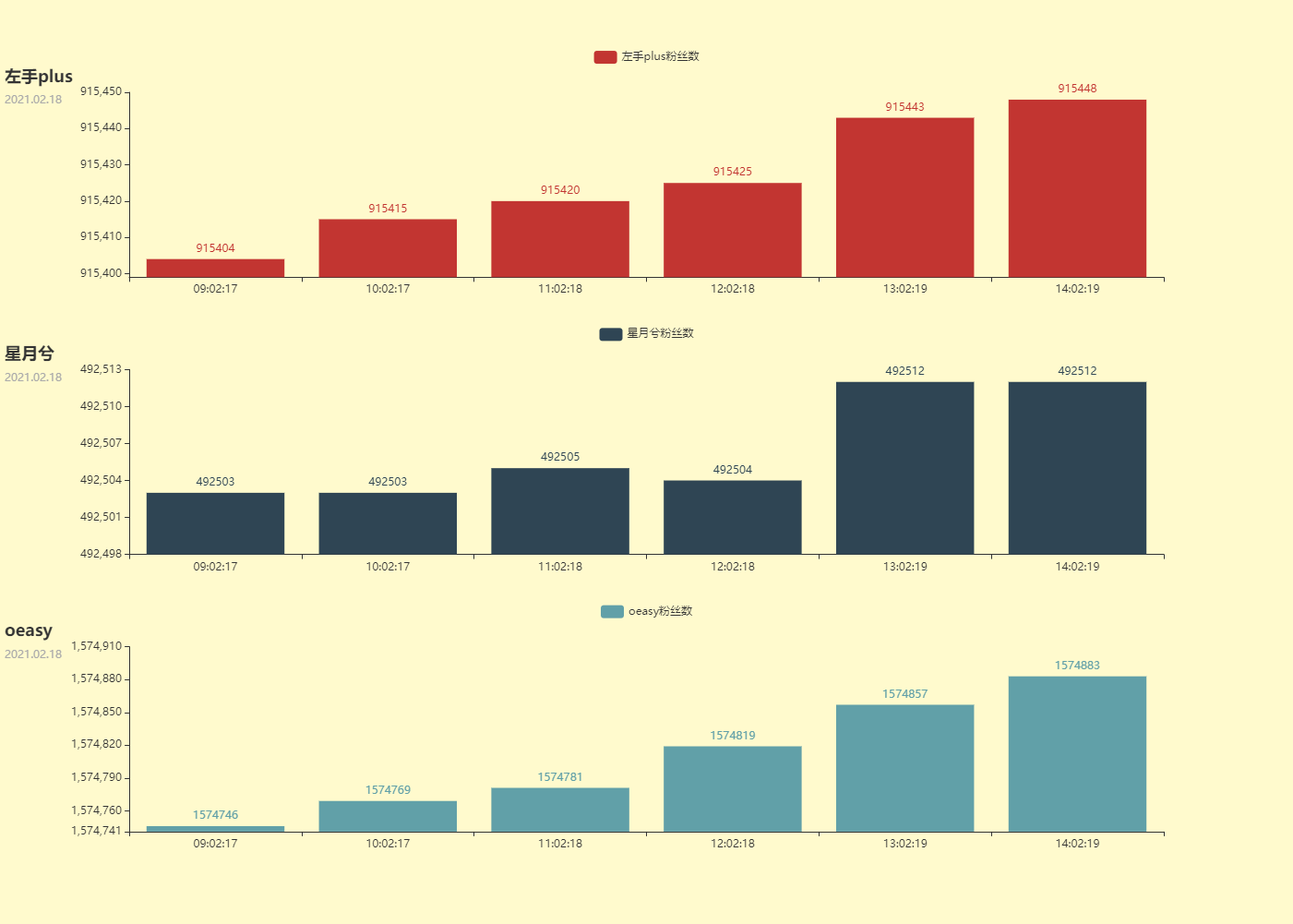


爬虫思路整理
1. 搜寻信息
2.算法
做法一: 利用python的集合
-
重合度=len(set_a.intersection(b))/len(a)
-
最好O(n),最坏O(m*n)
做法二:字典树(python)
-
复杂度:O(nlogn)
-
创建类(初始化)
- 字典
- 类的字典的对象还是这个类(一层一层找下去)
- 判断是否为叶结点的标志变量
- 字典
-
建树(插入)
- 分类讨论
- 没有这个元素:创造这个类的实例
- 有这个元素:不创造,不干活
- 都更新到下一个结点
- 更新标志变量
- 分类讨论
-
搜寻
- 原理:一个字一个字的找
- 分类讨论
- 找不到:掀桌子,不干了
- 找到了:更新结点,接着往下找
-
导入字符串列表
- 遍历,然后分个插入
代码
代码一
import requests
import json # 将response.txt转换为json格式,方便提取信息
import time
from flask import Flask
from pyecharts import options as opts
from pyecharts.charts import Bar, Grid, Pie, Line
from jinja2 import Markup
def get_up_name(up_uid):
base_url_name = "https://api.bilibili.com/x/space/acc/info?mid={}&jsonp=jsonp"
url_name = base_url_name.format(up_uid)
up_response = requests.get(url_name)
json_object = json.loads(up_response.text)
return json_object["data"]["name"]
def get_up_fans(up_uid):
base_url_fans_num = "https://api.bilibili.com/x/relation/stat?vmid={}&jsonp=jsonp"
url_fans_num = base_url_fans_num.format(up_uid)
# {"code":0,"message":"0","ttl":1,"data":{"mid":546195,"following":1,"whisper":0,"black":0,"follower":14262837}}
up_response = requests.get(url_fans_num)
json_object = json.loads(up_response.text)
return json_object["data"]["follower"]
l_fans_nums_1 = []
l_fans_nums_2 = []
l_fans_nums_3 = []
up_uid = ["20166755","17638509","2884629"]#20166755 左手plus 17638509 星月兮 2884629 oeasy
l_up_name = []
for uid in up_uid:
l_up_name.append(get_up_name((uid)))
l_time = []
for i in range(1, 7):
l_fans_nums_1.append(get_up_fans(up_uid[0]))
l_fans_nums_2.append(get_up_fans(up_uid[1]))
l_fans_nums_3.append(get_up_fans(up_uid[2]))
l_time.append(time.strftime("%H:%M:%S",time.localtime()))
print(l_time)
time.sleep(3600)
app = Flask(__name__, static_folder="templates")
def bar_base() -> Grid:
u1 = (
Bar()
.add_xaxis(l_time)
.add_yaxis("{}粉丝数".format(l_up_name[0]), l_fans_nums_1)
.set_global_opts(
title_opts=opts.TitleOpts(title=l_up_name[0],subtitle=time.strftime("%Y.%m.%d",time.localtime()),pos_top="7%"),
legend_opts=opts.LegendOpts(pos_top="5%"),
yaxis_opts=opts.AxisOpts(
min_=l_fans_nums_1[0]-5
)
)
)
u2 = (
Bar()
.add_xaxis(l_time)
.add_yaxis("{}粉丝数".format(l_up_name[1]),l_fans_nums_2)
.set_global_opts(
title_opts=opts.TitleOpts(title=l_up_name[1],subtitle=time.strftime("%Y.%m.%d",time.localtime()),pos_top="37%"),
legend_opts=opts.LegendOpts(pos_top="35%"),
yaxis_opts=opts.AxisOpts(
min_=l_fans_nums_2[0] - 5
)
)
)
u3 = (
Bar()
.add_xaxis(l_time)
.add_yaxis("{}粉丝数".format(l_up_name[2]), l_fans_nums_3)
.set_global_opts(
title_opts=opts.TitleOpts(title=l_up_name[2],subtitle=time.strftime("%Y.%m.%d",time.localtime()),pos_top="67%"),
legend_opts=opts.LegendOpts(pos_top="65%"),
yaxis_opts=opts.AxisOpts(
min_=l_fans_nums_3[0] - 5
)
)
)
grid = (
Grid(init_opts=opts.InitOpts(width='1400px', height='1000px', bg_color="#FFFACD"))
# .width("900px")
.add(u1, grid_opts=opts.GridOpts(pos_top="10%", pos_bottom='70%', pos_left="10%",pos_right="10%"))
.add(u2, grid_opts=opts.GridOpts(pos_top="40%", pos_bottom='40%', pos_left="10%",pos_right="10%"))
.add(u3, grid_opts=opts.GridOpts(pos_top="70%", pos_bottom='10%', pos_left="10%",pos_right="10%"))
)
return grid
@app.route("/")
def index():
c = bar_base()
return Markup(c.render_embed())
if __name__ == "__main__":
app.run(port=400
)### 代码二
import requests
import random
import json # 将response.txt转换为json格式,方便提取信息
import time # 作用:设置爬取间隔时间和提取当前时间
import tire_tree # 导入写好的字典树文件
from bs4 import BeautifulSoup # 导入解析库
# 调音师 https://movie.douban.com/subject/30334073/comments?status=P
# 长评数:全部 共 3051 条 实际 2820 条
# 看不见的客人 https://movie.douban.com/subject/26580232/reviews?start=2420
# 长评数:全部 共 2702 条 约 2360 条
# 暴烈无声 https://movie.douban.com/subject/26647117/reviews
# 长评数: 全部 3008 条 约 2700 条
l_commenter_1 = [] # 用于存储电影1的长评评论者的账号
l_commenter_2 = [] # 用于存储电影2的长评评论者的账号
l_commenter_3 = [] # 用于存储电影3的长评评论者的账号
proxy_list = [
{"http": "175.43.34.8:9999"},
{"http": "175.43.33.15:9999"}
]
proxy = random.choice(proxy_list) # ip转换
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/88.0.4324.104 Safari/537.36 "
}
def get_film_information(order, page_num, order_film):
base_url = "https://movie.douban.com/subject/{}/reviews?start={}"
url = base_url.format(order, page_num * 20)
response = requests.get(url, headers=headers, proxies=proxy)
soup = BeautifulSoup(response.text, "html.parser")
items = soup.find_all("header", class_="main-hd") # 找到标签为div,属性class_为“avatar”,多一个下划线是为了避免和class产生冲突
def_flag = True
if not items: # items为空列表
def_flag = False
return def_flag
for item in items:
user_id = str(item.find('a')["href"])[30:-1]
# href="https://www.douban.com/people/45238478/"
if order_film == 0:
l_commenter_1.append(user_id)
with open("film_1.txt", "a", encoding="utf-8") as f1: # 存入txt文件,encoding=”utf-8“是为了避免中文出现乱码的情况
f1.write(user_id + '
')
elif order_film == 1:
l_commenter_2.append(user_id)
with open("film_2.txt", "a", encoding="utf-8") as f2:
f2.write(user_id + '
')
elif order_film == 2:
l_commenter_3.append(user_id)
with open("film_3.txt", "a", encoding="utf-8") as f3:
f3.write(user_id + '
')
return def_flag
l_film_order = ["30334073", "26580232", "26647117"]
page = 0
flag = True
while flag:
print("现在正在处理第" + str(page+1) + "页长评")
for i in range(0, 3):
flag = get_film_information(l_film_order[i], page, i)
if not flag:
break
page = page + 1 # 翻页
time.sleep(random.randint(15, 23)) # 随机时停
l_filter = [] # 用于存储电影1和电影2的交叉用户
tree_1 = tire_tree.Tire_Node()
tree_1.Transfer_All_Elements_For_Building(l_commenter_1)
for x in l_commenter_2:
if tree_1.Search_Node(x):
l_filter.append(x)
cnt_intersection = 0
tree_1_2 = tire_tree.Tire_Node()
tree_1_2.Transfer_All_Elements_For_Building(l_filter)
for x in l_commenter_3:
if tree_1_2.Search_Node(x):
cnt_intersection = cnt_intersection + 1
print("三部电影的交叉人数为{}".format(cnt_intersection))
print("总抓取数量为{}".format((page+1)*20))
print("三部电影的重合度为{:.2%}".format(cnt_intersection / ((page + 1) * 20)))
代码三——字典树文件
class Tire_Node:
def __init__(self):
self.Son_Nodes = {}
self.Is_Leaf = False
def Bulid_Tire_Tree(self,word: str):
Cur_Node = self
for char in word:
if str not in Cur_Node.Son_Nodes:
Cur_Node.Son_Nodes[char] = Tire_Node()
Cur_Node = Cur_Node.Son_Nodes[char]
Cur_Node.Is_Leaf = True
def Transfer_All_Elements_For_Building(self,words: [str]):
for word in words:
self.Bulid_Tire_Tree(word)
def Search_Node(self,word):
Cur_Node = self
for str in word:
if str not in Cur_Node.Son_Nodes:
return False
else:
Cur_Node = Cur_Node.Son_Nodes[str]
return True
学习资源
看看都是哪些小可爱关注了我【三分钟学习笔记 Python抓取B站粉丝数】
技巧
-
可以通过在程序中修改ps值来扩大搜寻量
-
每爬取一页需要暂停5s,避免ip被封(time.sleep(5))
-
定时执行
import time for i in range(5): 执行内容 time.sleep(60*60)
工具网站
其他
UID
UID,是用户身份证明(User Identification)的缩写。
UID用户在注册网络平台后,系统会自动地给你一个UID的数值。意思就是给这名用户编个号。
字段
我们把表中的每一行叫做一个“记录”,每一个记录包含这行中的所有信息,就像在通讯录数据库中某个人全部的信息,但记录在数据库中并没有专门的记录名,常常用它所在的行数表示这是第几个记录。字段是比记录更小的单位,字段集合组成记录,每个字段描述文献的某一特征,即数据项,并有唯一的供计算机识别的字段标识符。
字段定义:一个成员,它表示与对象或类关联的变量。
举例说明如下:
类就是某一类事物的抽象描述
对象是类的具体实例
成员是属性和方法的集合
字段用来存储数值或对象的真正实体
比如:
家 这就是一个类,在这个家中你也不知道具体有哪些事物
爸爸 这是一个类的成员,当类没有实例化时,你也不知道具体是谁
地址 这是一个字段 当类没有实例化对象时,你也不知道其具体值是啥
小明家 这就是一个对象,你知道这个家里有哪些人哪些物
小明的爸爸 当类被实例化成对象时,其成员也就确定下来了。
人民广场1号 这个地址也就确定下来了
API
API(Application Programming Interface,应用程序接口)是一些预先定义的接口(如函数、HTTP接口),或指软件系统不同组成部分衔接的约定。 [1] 用来提供应用程序与开发人员基于某软件或硬件得以访问的一组例程,而又无需访问源码,或理解内部工作机制的细节。
时间戳
json
- json.dumps()将一个Python数据结构转换为JSON
- json.loads()将Json字符串解码成python对象
- 若得到的网页的格式不符合json的标准,无法用json转换
- BeautifulSoup
颜色网站
set集合
-
常规操作
basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'} print(basket) #去重能力 #{'orange', 'banana', 'apple', 'pear'} print('apple' in basket) #True print("aedfawe" in basket) a = set("ewarweraefda") b = set("aweiraj;fdg") print(a-b)#差集 包含于a,且不包含于b的元素 print(a|b)#并集 print(a&b)#交集 print(a^b)#(a|b)-(a&b) # set() # {'e', ';', 'f', 'i', 'a', 'w', 'j', 'r', 'g', 'd'} # {'f', 'a', 'w', 'e', 'r', 'd'} # {'i', 'j', ';', 'g'} -
创建空集合
-
set_comment_er= set()
-
-
添加
- 集合名.add(x)
- 集合名.update(基本啥啥都行)
-
个数
-
union(并集)
- 合并单个 x.union(y)
- 合并多个 x.union(y,z)
-
intersection_update() 和intersection()
intersection_update()方法不同于intersection()方法,因为intersection()方法是返回一个新的集合,而intersection_update()方法是在原始的集合上移除不重叠的元素。xnew = x.intersection(y,z)x,intersection(y,z)
-
time模块的学习
import time # 引入time模块
ticks = time.time()
print(ticks)
# 1613476958.230605
# 时间戳单位最适于做日期运算。
# 但是1970年之前的日期就无法以此表示了。
# 太遥远的日期也不行,UNIX和Windows只支持到2038年。
print(time.strftime("%Y.%m.%d %H:%M:%S",time.localtime()))
#2021.02.16 20:10:21
print(time.strftime("%Y.%m.%d",time.localtime()))
#2021.02.16
print(time.strftime("%H:%M:%S",time.localtime()))
#20:12:21
# %y 两位数的年份表示(00-99)
# %Y 四位数的年份表示(000-9999)
# %m 月份(01-12)
# %d 月内中的一天(0-31)
# %H 24小时制小时数(0-23)
# %I 12小时制小时数(01-12)
# %M 分钟数(00-59)
# %S 秒(00-59)
# %a 本地简化星期名称
# %A 本地完整星期名称
# %b 本地简化的月份名称
# %B 本地完整的月份名称
# %c 本地相应的日期表示和时间表示
# %j 年内的一天(001-366)
# %p 本地A.M.或P.M.的等价符
# %U 一年中的星期数(00-53)星期天为星期的开始
# %w 星期(0-6),星期天为星期的开始
# %W 一年中的星期数(00-53)星期一为星期的开始
# %x 本地相应的日期表示
# %X 本地相应的时间表示
# %Z 当前时区的名称
# %% %号本身
re模块的学习
re.match与re.search的区别
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
re.compile()编辑正则表达式
pattern=re.compile()
re.match与re.search
re.search(pattern, string, flags=0)
百分号输出
下阶段
- 西二的flask作业,刷点oj。
感谢
- 感谢小白马大佬,icewolf,lwgg,xsdl,lydl,lydl的指导