一、索引简介
1.索引是什么?
MySQL官对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。即得到索引的本质:索引是数据结构。
1)你可以理解为“排好序的快速查找数据结构”。
详解(重要):
在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引。下图就是一种可能的索引方式示例:
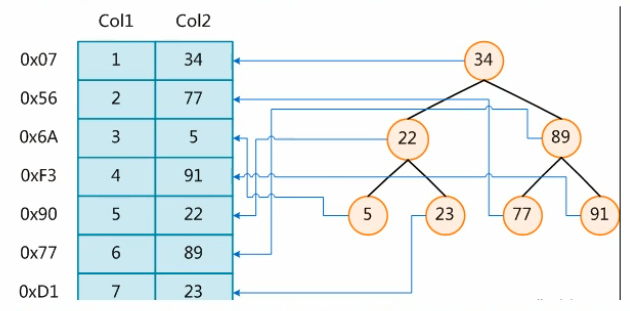
左边是数据表,一共有两列七条记录,最左边的是数据存储的物理地址。
为了加快 Col2 的查找,可以维护一个右边所示的二叉查找树,每个节点分别包含索引键值和一个指向对应数据记录地址的指针,这样就可以运用二叉查找树在一定的复杂度内获取到相应数据,从而快速的检索出符合条件的记录。
我们平时所说的索引,如果没有特别指明,都是指 B 树(多路搜索树,并不一定是二叉树)结构组织的索引。其中聚集索引,次要索引,覆盖索引,复合索引,前缀索引,唯一索引默认都是使用 B+树索引,统称索引。当然,除了B+树这种类型的索引之外,还有哈希索引(hash index)等。
2.索引的优势和劣势
优势:
- 类似大学图书馆建书目索引,提高数据检索的效率,降低数据库的IO成本。
- 通过索引列队数据进行排序,降低数据排序的成本,降低了CPU的消耗。
劣势:
- 实际上索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录,所以索引列也是要占用空间的。
- 虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对标进行insert、update和delete。因为更新表时,MySQl不仅要保存数据,还要保存一下索引文件每次更新添加了索引列的字段,都会调整因为更新索带来的键值变化后的索引信息。
- 索引只是提高效率的一个因素,如果你的MySQL有大数据量的表,就需要花时间研究建立最优秀的索引,或优化查询。
3.MySQL的索引分类
1)单值索引
即一个索引值包含单个列,一个表可以有多个单列索引
创建方法:
a. 建表的时候一起创建
CREATE TABLE mytable ( name VARCHAR(32) , INDEX index_mytable_name (name) );
b. 建表后,直接创建索引
CREATE INDEX index_mytable_name ON mytable(name);
c. 修改表结构
ALTER TABLE mytable ADD INDEX index_mytable_name (name);
注:如果是字符串字段,还可以指定索引的长度,在列命令后面加上索引长度就可以了(例如:name(11))
2)唯一索引
索引列的值必须是唯一的,但允许有空值。(银行卡号)
创建方法:
a. 建表的时候一起创建
CREATE TABLE mytable ( `name` VARCHAR(32) , UNIQUE index_unique_mytable_name (`name`) );
b. 建表后,直接创建索引
CREATE UNIQUE INDEX index_mytable_name ON mytable(name);
c. 修改表结构
ALTER TABLE mytable ADD UNIQUE INDEX index_mytable_name (name);
注:如果是字符串字段,还可以指定索引的长度,在列命令后面加上索引长度就可以了(例如:name(11))
3)复合索引
即一个索引包含多个列。
创建方法:
a. 建表的时候一起创建
CREATE TABLE mytable ( `id` int(11) , `name` VARCHAR(32) , INDEX index_mytable_id_name (`id`,`name`) );
b. 建表后,直接创建索引
CREATE INDEX index_mytable_id_name ON mytable(id,name);
c. 修改表结构
ALTER TABLE mytable ADD INDEX index_mytable_id_name (id,name);
4)主键索引
是一种特殊的唯一索引,一个表只能有一个主键,不允许有空值。一般是在建表的时候同时创建主键索引。
创建方法:
a. 建表的时候一起创建
CREATE TABLE mytable ( `id` int(11) NOT NULL AUTO_INCREMENT , `name` VARCHAR(32) , PRIMARY KEY (`id`) );
b. 修改表结构
ALTER TABLE test.t1 ADD CONSTRAINT t1_pk PRIMARY KEY (id);
注:如果是字符串字段,还可以指定索引的长度,在列命令后面加上索引长度就可以了(例如:name(11))
5)全文索引
主要用来查找文本中的关键字,而不是直接与索引中的值相比较。
fulltext索引跟其它索引大不相同,它更像是一个搜索引擎,而不是简单的where语句的参数匹配。
fulltext索引配合match against操作使用,而不是一般的where语句加like。
它可以在create table,alter table ,create index使用,不过目前只有char、varchar,text 列上可以创建全文索引。
创建方法:
a. 建表的时候一起创建
CREATE TABLE `article` ( `id` int(11) NOT NULL AUTO_INCREMENT ,`title` char(250) NOT NULL , `contents` text NULL , `create_at` int(10) NULL DEFAULT NULL , PRIMARY KEY (`id`), FULLTEXT (contents) );
b. 建表后,直接创建索引
CREATE FULLTEXT INDEX index_article_contents ON article(contents);
c. 修改表结构
ALTER TABLE article ADD FULLTEXT INDEX index_article_contents (contents);
6)基本语法
创建:
① create [unique] index indexName on mytable(columnName(length));
② alert mytable add [unique] index [indexName] on (columnName(length));
删除:
drop index [indexName] on mytable;
查看:
show index from table_nameG
4.MySQL索引结构
1)B+ 树
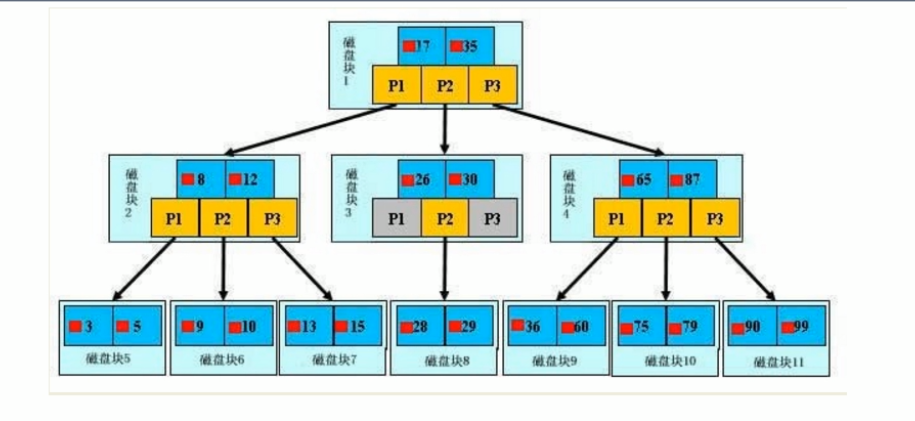
【初始化介绍】
一颗 B+ 树,浅蓝的的快我们成为磁盘块,可以看到每个磁盘块包含几个数据项(深蓝色所示)和指针(黄色所示),如磁盘块1包含数据项17和35,包含指针P1,P2,P3。
P1表示洗浴17的磁盘块,P2表示在17和35之间的磁盘块,P3表示大于35的磁盘块。
真实的数据存在于叶子节点即3、5、9、10、13、15、28、29、36、60、75、79、90、99。
非叶子节点不存储真实的数据,只存储指引搜索方向的数据项,如17、35并不真实存在于数据表中。
【查找过程】
如果要查找数据项29,那么首先会把磁盘块1由磁盘加载到内存,此时发生一次I口, 在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针,内存时间因为非常短(相比磁盘的I0)可以忽略不计,通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,发生第二次I0,29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次I0,同时内存中做二分查找找到29,结束查询,总计三次I0。
真实的情况是,3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次I0,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次I0,那么总共需要百万次的I0,显然成本非常非常高。
5.哪些情况需要创建索引?
1)主键自动建立唯一索引。
2)频繁作为查询条件的字段应该创建索引。
3)查询中与其他表关联的字段,外键关系建立索引。
4)单键/组合索引的选择问题?(在高并发下倾向创建组合索引)。
5)查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度。
6)查询中统计或者分组字段。
6.哪些情况不需要创建索引?
1)表记录太少
2)经常增删改的表,why:提高了查询速度,同时却会降低更新表的速度,如对表进行insert、update、delete,因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。
3)where 条件里用不到的字段不创建索引。
4)数据重复且分布均匀的表字段,因此应该只为最经常查询和最经常排序的数据列建立索引。注意,如果某个数据列包含许多重复的内容,为它建立索引就没有太大的实际效果。