文章部分图片和总结来自参考资料,侵删
概述
MySQL的可重复读隔离级别,事务T启动的时候会创建一个视图read-view,之后事务T执行期间,即使有其他事务修改了数据,事务T看到的仍然跟在启动时看到的一样。**也就是说,一个在可重复读隔离级别下执行的事务,好像与世无争,不受外界影响。
可重复读的含义
一个事务启动的时候,能够看到所有已经提交的事务结果。但是之后,这个事务执行期间,其他事务的更新对它不可见。
read-view 到底是什么
假如有多个事务,每个事务都生成一个数据的全量拷贝下来,那么数据量是吓人的,MySQL 肯定不是这种方案。 InnoDB里面每个事务有一个唯一的事务ID,叫作transaction id。它是在事务开始的时候向InnoDB的事务系统申请的,是按申请顺序严格递增的。 **而每行数据也都是有多个版本的。**每次事务更新数据的时候,都会生成一个新的数据版本,并且把transaction id赋值给这个数据版本的事务ID,记为row trx_id。同时,旧的数据版本要保留,并且在新的数据版本中,能够有信息可以直接拿到它。也就是说,数据表中的一行记录,其实可能有多个版本(row),每个版本有自己的row trx_id。
如图2所示,就是一个记录被多个事务连续更新后的状态。
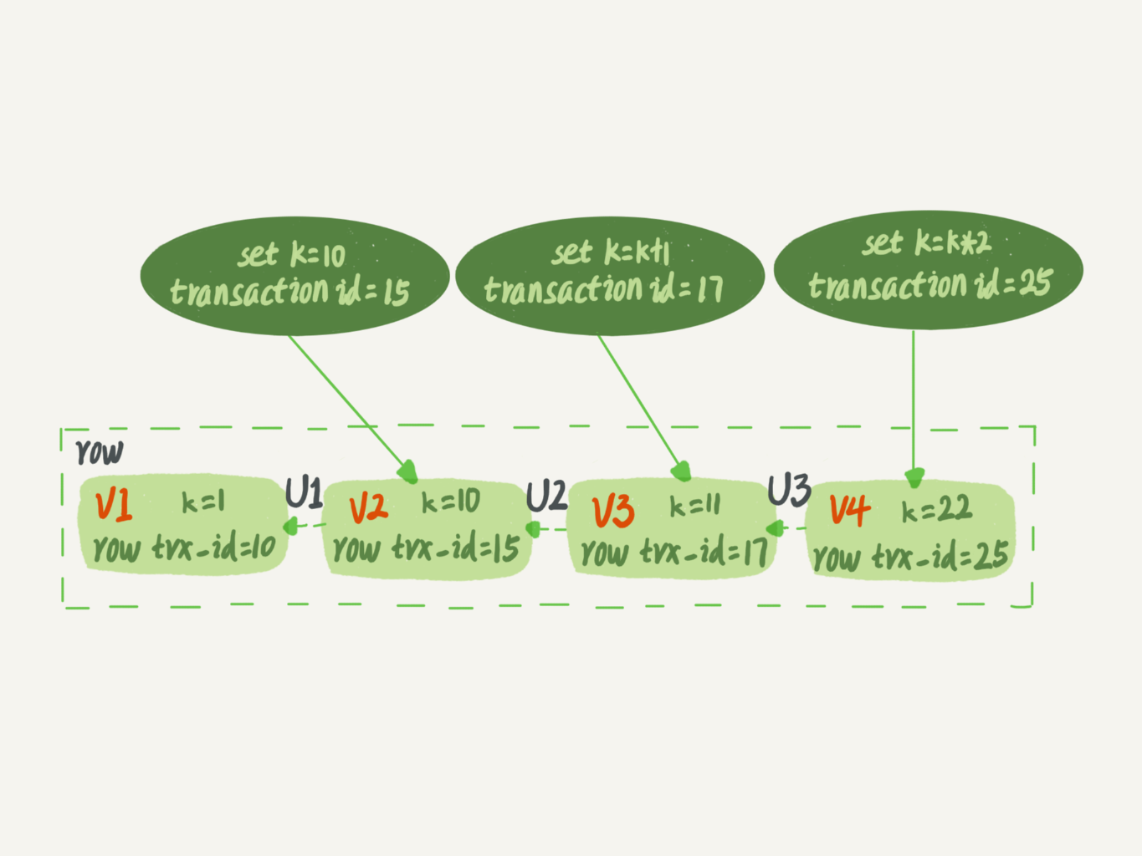
如上图要是有3个事务开启,transaction_id 分别为 15,17,25 那么看到的值分别是 10,11,22 ,可以想象有这样的场景,transaction_id = 15 开启事务看到k 为 10 ,然后transaction_id 为 16也开启了事务,让k更新为 11 ,commit ,transaction_id 为17的开启了事务过来看热闹,那么它拿到的k 为 11 ,后面的 transaction_id 为 25也是同样的道理 ,而为了记录每个事务对该行的操作,k分别从初始值10被set 成不同的值而不是直接记录k 的具体数值。
set k = k+1 set k = k*2
你可能会问,前面的文章不是说,语句更新会生成undo log(回滚日志)吗?那么,undo log在哪呢? 实际上,图2中的三个虚线箭头,就是undo log;而V1、V2、V3并不是物理上真实存在的,而是每次需要的时候根据当前版本和undo log计算出来的。比如,需要V2的时候,就是通过V4依次执行U3、U2算出来。 到了这里我们可以知道 undo-log 就是来保存多个版本某行数据的变化逻辑,并且并不是直接储存数值,而是通过逻辑推算出来的。
例子和实现
看上面的例子我们还是很懵到底可重复读是如何实现的?实际上,(以下是通俗的理解,具体的需要查看源码实现)
- row : 维护一个链表
- 事务 :维护一个有时间排序的活跃的数组(活跃的指的是当前开启事务的) row上的链表保存的是对该行修改已经提交的事务;每个事务的保存的活跃数组则是当前该表相关的事务数组,按时间排序,是有序的。 例如以下的例子。

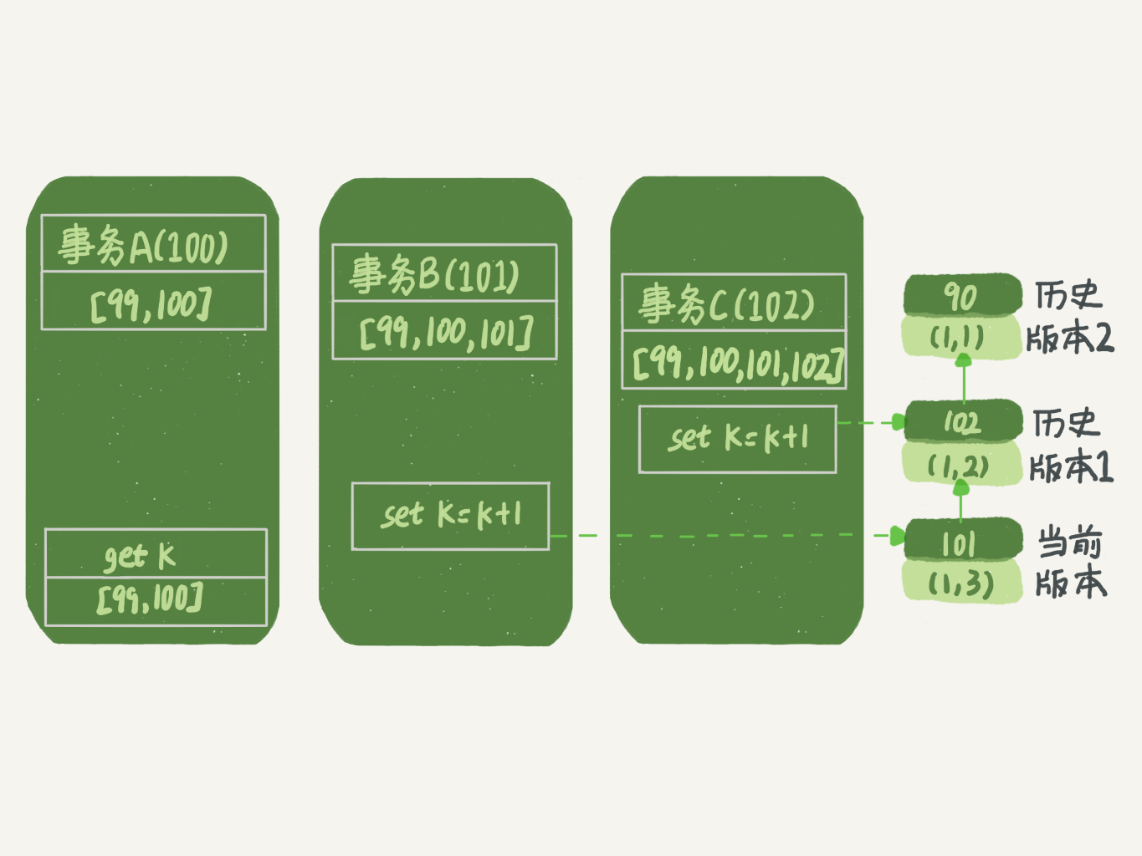
可以看到,当A去查询某行记录的时候,它顺着该row 已经提交的链表查询,一直查到自己的一个txn_id ,而其他的事务不会被读到。 当B更新的时候,则是先读后更新的,这个读,只能读当前的值,而不需要顺着链表确定自己读取的值是多少,成为当前读(current read ) 。
事务去row 链表确定自己读取的值,有这样的规则,
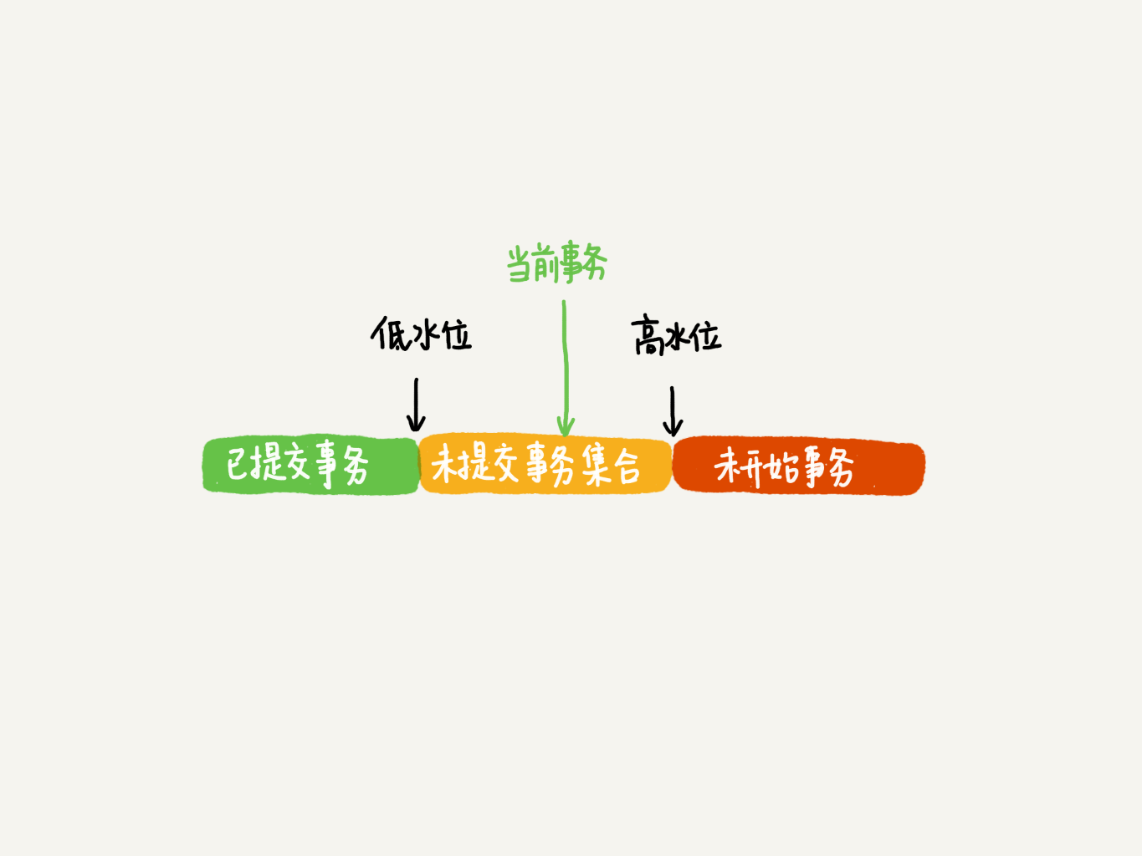
现在事务A要来读数据了,它的视图数组是[99,100]。当然了,读数据都是从当前版本读起的。所以,事务A查询语句的读数据流程是这样的:
- 找到(1,3)的时候,判断出row trx_id=101,比高水位大,处于红色区域,不可见;
- 接着,找到上一个历史版本,一看row trx_id=102,比高水位大,处于红色区域,不可见;
- 再往前找,终于找到了(1,1),它的row trx_id=90,比低水位小,处于绿色区域,可见。 这样执行下来,虽然期间这一行数据被修改过,但是事务A不论在什么时候查询,看到这行数据的结果都是一致的,所以我们称之为一致性读。
假如C事务被换成了 C' 的执行逻辑

那么当B在更新数据的时候,C'还没有提交,B就会一直阻塞在那里,因为该行的写锁被获取了。
读提交
可重复读的核心就是一致性读(consistent read);而事务更新数据的时候,只能用当前读。如果当前的记录的行锁被其他事务占用的话,就需要进入锁等待。
而读提交的逻辑和可重复读的逻辑类似,它们最主要的区别是:
- 在可重复读隔离级别下,只需要在事务开始的时候创建一致性视图,之后事务里的其他查询都共用这个一致性视图;
- 在读提交隔离级别下,每一个语句执行前都会重新算出一个新的视图。
注意读提交的隔离级别下,每一个语句执行前都会重新算出一个新的视图。
MVCC
以下来自官方的描述。
InnoDBis a multi-versioned storage engine: it keeps information about old versions of changed rows, to support transactional features such as concurrency and rollback. This information is stored in the tablespace in a data structure called a rollback segment (after an analogous data structure in Oracle).InnoDBuses the information in the rollback segment to perform the undo operations needed in a transaction rollback. It also uses the information to build earlier versions of a row for a consistent read.
我们可以知道InnoDB 的多版本储存主要是两方面的作用 :
- concurrency 并发
- rollback 回滚
并发主要就是上文讲的 一致性读 的实现,回滚则是事务执行失败后事务回滚操作。实现称为 MVCC 的功能主要在每个 row 增加了3个字段,分别是 :
- DB_TRX_ID : 用于表示标识事务
- DB_ROLL_PTR : 用与回滚事务
- DB_ROW_ID :插入的时候才会创建
另外,当表中删除一行数据,MySQL 并不会马上就去数据库中进行删除,而是设置一个标识,由 purge Thread 周期再进行更新.
具体的表述可以参看官网描述
查看和设置事务隔离级别
SET [GLOBAL | SESSION ] TRANSACTION ISOLATION LEVEL { READ UNCOMMITTED | READ COMMITTD | REPEATABLE READ | SERIALIZABLE } //查看当前会话隔离级别 SELECT @@tx_isolationG; //查看全局隔离级别 SELECT @@GLOBAL.tx_isolationG;
参考资料
- MySQL实战45讲
- https://dev.mysql.com/doc/refman/8.0/en/innodb-multi-versioning.html (MVCC)