> 文章图片和描述来自参考资料非原创
概述
文章主要讲 linux 下的关于 page cache 和 buffer cache 的关系和区别。
在我们进行数据持久化,对文件内容进行落盘处理时,我们时常会使用fsync操作,该操作会将文件关联的脏页(dirty page)数据(实际文件内容及元数据信息)一同写回磁盘。这里提到的脏页(dirty page)即为页缓存(page cache)。
块缓存(buffer cache),则是内核为了加速对底层存储介质的访问速度,而构建的一层缓存。他缓存部分磁盘数据,当有磁盘读取请求时,会首先查看块缓存中是否有对应的数据,如果有的话,则直接将对应数据返回,从而减少对磁盘的访问。
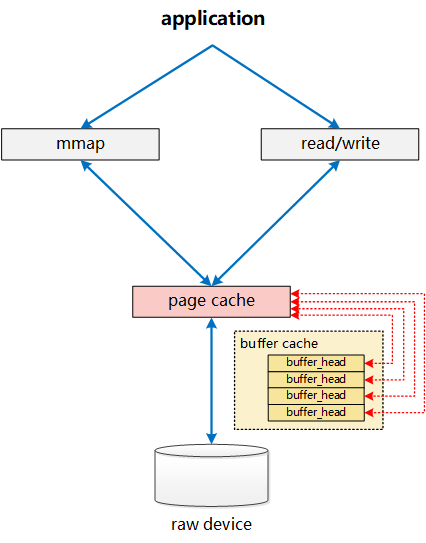
这里放出一张图,这样可以比较直观地知道IO操作的具体位置,图片出处
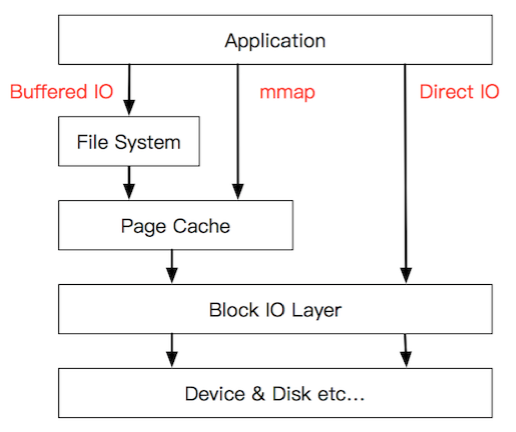
buffer cache
这是计算机最底层的读取的数据块,我们知道计算机从磁盘中读出的数据最小单位为块(block)。关于 Buffer cache 的描述下面来自Linux内核Page Cache和Buffer Cache关系及演化历史
磁盘的最小数据单位为sector,每次读写磁盘都是以sector为单位对磁盘进行操作。sector大小跟具体的磁盘类型有关,有的为512Byte, 有的为4K Bytes。无论用户是希望读取1个byte,还是10个byte,最终访问磁盘时,都必须以sector为单位读取,如果裸读磁盘,那意味着数据读取的效率会非常低。同样,如果用户希望向磁盘某个位置写入(更新)1个byte的数据,他也必须整个刷新一个sector,言下之意,则是在写入这1个byte之前,我们需要先将该1byte所在的磁盘sector数据全部读出来,在内存中,修改对应的这1个byte数据,然后再将整个修改后的sector数据,一口气写入磁盘。为了降低这类低效访问,尽可能的提升磁盘访问性能,内核会在磁盘sector上构建一层缓存,他以sector的整数倍力度单位(block),缓存部分sector数据在内存中,当有数据读取请求时,他能够直接从内存中将对应数据读出。当有数据写入时,他可以直接再内存中直接更新指定部分的数据,然后再通过异步方式,把更新后的数据写回到对应磁盘的sector中。这层缓存则是块缓存Buffer Cache。
page cache
page 是什么,我们在学逻辑空间的时候讲到了,当进程加载到内存中的有可能以页为单位加载进去,或是段页式加载到内存。 所以我们的文件实际上分割为页。page cache 以 page 为单位,缓存文件内容。
buffer cache 和 page cache
下面来自参考文章的表述 从linux-2.6.18的内核源码来看,Page Cache和Buffer Cache是一个事物的两种表现:对于一个Page而言,对上,他是某个File的一个Page Cache,而对下,他同样是一个Device上的一组Buffer Cache。
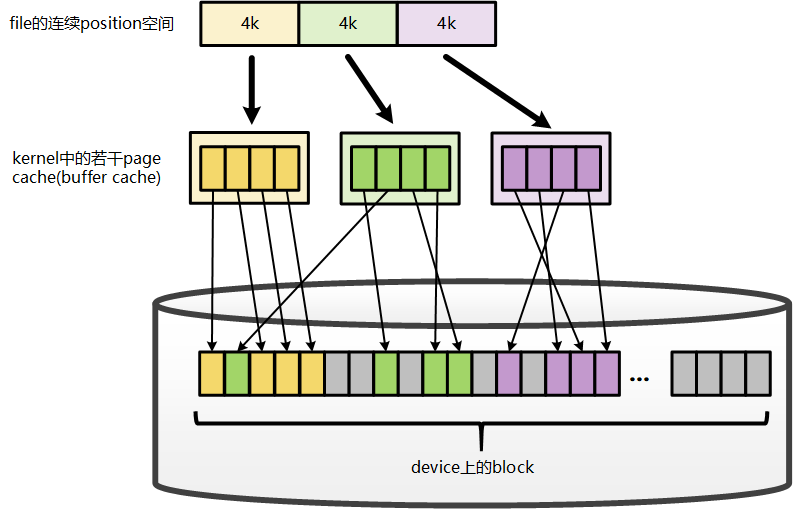
** 可以看到我们逻辑上的 page cache 对应到底层磁盘是 buffer cache **
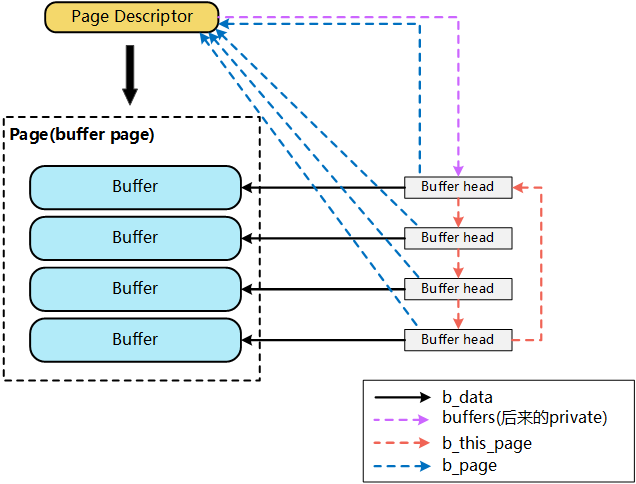
File在地址空间上,以4K(page size)为单位进行切分,每一个4k都可能对应到一个page上(这里可能的含义是指,只有被缓存的部分,才会对应到page上,没有缓存的部分,则不会对应),而这个4k的page,就是这个文件的一个Page Cache。而对于落磁盘的一个文件而言,最终,这个4k的page cache,还需要映射到一组磁盘block对应的buffer cache上,假设block为1k,那么每个page cache将对应一组(4个)buffer cache,而每一个buffer cache,则有一个对应的buffer cache与device block映射关系的描述符:buffer_head,这个描述符记录了这个buffer cache对应的block在磁盘上的具体位置
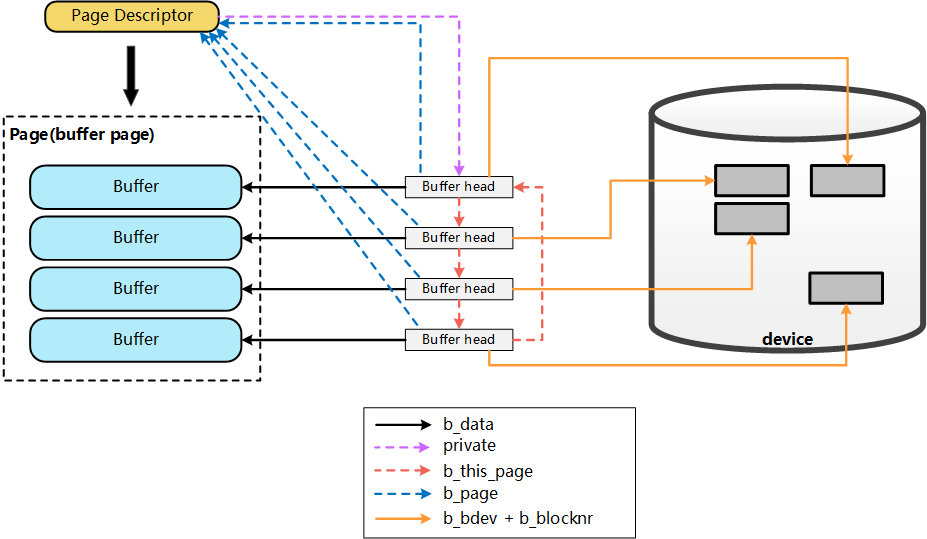
这个图什么意思呢? 多个 buffer 对应一个 page ,所以他们之前的映射关系交由 page descriptor 来维护, 而buffer head 则是真正对应底层设备的数据了。
两类缓存的演进历史
参考资料的共讲到了三个阶段,分别对应的linux版本为 : linux-0.11, linux-2.2.16, linux-2.4.0, linux-2.4.19, linux-2.6.18。有兴趣的可以阅读参考资料,这里不再深入源码级别。
第一阶段 : 仅有 Buffer Cache
第二阶段 : Buffer Cache 和 Page Cache 并存
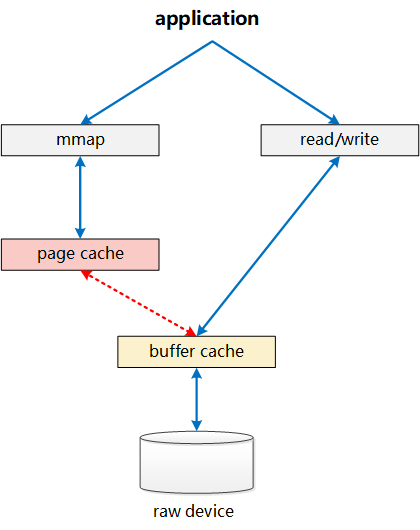
Page Cache仅负责其中mmap部分的处理,而Buffer Cache实际上负责所有对磁盘的IO访问。从上面图中,我们也可看出其中一个问题:write绕过了Page Cache,这里导致了一个同步问题。当write发生时,有效数据是在Buffer Cache中,而不是在Page Cache中。这就导致mmap访问的文件数据可能存在不一致问题。为了解决这个问题,所有基于磁盘文件系统的write,都需要调用update_vm_cache()函数,该操作会修改write相关Buffer Cache对应的Page Cache。从代码中我们可以看到,上述sysv_file_write中,在调用完copy_from_user之后,会调用update_vm_cache
同样,正是这样Page Cache、Buffer Cache分离的设计,导致基于磁盘的文件,同一份数据,可能在Page Cache中有一份,而同时,却还在Buffer Cache中有一份。
第三阶段 : Page & Buffer Cache 两者融合
介于上述Page Cache、Buffer Cache分离设计的弊端,Linux-2.4版本中对Page Cache、Buffer Cache的实现进行了融合,融合后的Buffer Cache不再以独立的形式存在,Buffer Cache的内容,直接存在于Page Cache中,同时,保留了对Buffer Cache的描述符单元:buffer_head
于是就成了这样,mmap和 read/write实际都是对page cache操作,而page cache包含多个buffer cache .
下面这张图和源码相关的示意图,以后阅读代码的时候再看吧。
最后参考资料第一篇的作者列出了注意的地方
[注意]:这里的Page Cache与Buffer Cache的融合,是针对文件这一层面的Page Cache与Buffer Cache的融合。对于跨层的:File层面的Page Cache和裸设备Buffer Cache,虽然都统一到了基于Page的实现,但File的Page Cache和该文件对应的Block在裸设备层访问的Buffer Cache,这两个是完全独立的Page,这种情况下,一个物理磁盘Block上的数据,仍然对应了Linux内核中的两份Page,一个是通过文件层访问的File的Page Cache(Page Cache),一个是通过裸设备层访问的Page Cache(Buffer Cache)。
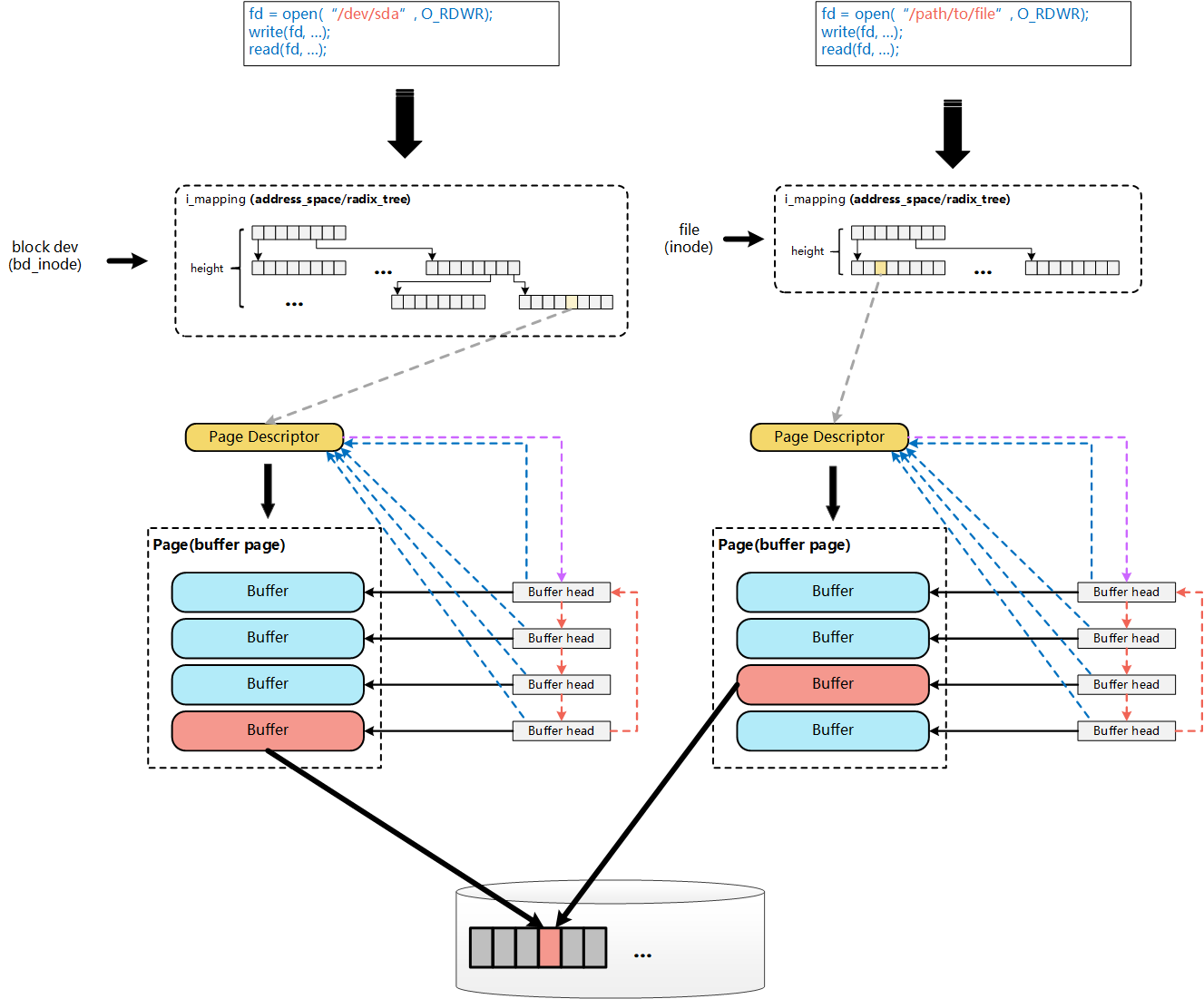
这里看的有点绕,按我的理解就是对于 ** 文件系统的 ** ,在最下层磁盘和上层客户端中间page cache 和 buffer cache 是融合在一起的,有相互的映射关系, 但是文件也可以是认为是一堆封装好的2进制的数据, 那么通过裸设备和最下层磁盘中间之间直接就是buffer cache 了 ,而没有对应的 page cache 。
mmap
我们先来看看没有mmap 的时候。内核需要从拷贝一份到用户态空间,然后用户态修改后再回刷到page cache , 而mmap 就是用了一个映射, 修改的东西直接映射到 page cache 。
mmap 还分 private 和 shared ,下面来自参考文章,有兴趣可以看一下
A file mapping may be private or shared. This refers only to updates made to the contents in memory: in a private mapping the updates are not committed to disk or made visible to other processes, whereas in a shared mapping they are. Kernels use the copy on write(复制写机制) mechanism, enabled by page table entries, to implement private mappings.
linux 的 swap 区
在Linux下,SWAP的作用类似Windows系统下的“虚拟内存”。当物理内存不足时,拿出部分硬盘空间当SWAP分区(虚拟成内存)使用,从而解决内存容量不足的情况。当操作系统中运行多个进程,内存空间又不足,那么就只能把一部分进程换出内存,等运行的时候在放进来,这个过程就像 ‘SWAP’
linux 的 free 命令
[root@iZm5e7bivgszquxjh18i39Z ~]# free
total used free shared buff/cache available
Mem: 840992 152224 107432 440 581336 555368
Swap: 0 0 0
看到我们的buff/cache 就是指缓存。
补充
参考资料
- http://lday.me/2019/09/09/0023_linux_page_cache_and_buffer_cache/ (推荐阅读)
- https://www.cnkirito.moe/mq-million-queue/
- https://www.zhihu.com/question/25105320/answer/181056523
- https://manybutfinite.com/post/page-cache-the-affair-between-memory-and-files/ (推荐阅读)