问题
- 为什么返回的对象不直接是 Invoker 而是代理类呢
回答 :
Dubbo服务暴露的主要目的是让本地的服务bean能够让其它进程通过网络调用。在暴露服务前,dubbo需要根据配置信息收集服务相关信息,服务的配置信息都配置在ServiceConfig中。Dubbo接收到Spring触发的ContextRefreshedEvent事件后,dubbo进行真正的服务暴露过程。Dubbo服务暴露目的是让消费者调用, Dubbo会将注册的服务bean包装为可执行对象Invoker,但是暴露的服务bean不能任意被消费者调用,所以消费者对服务bean的访问需要受到控制,这些控制的逻辑会放在代理逻辑中实现,而ProxyFactory用于生成代理对象。除此之外,当前进程的服务bean能够被其它进程调用的前提是能够被其它进程发现,所以这会涉及到服务注册的问题,Registry抽象了注册中心。服务调用又会涉及到网络协议,比如长连接还是短连接协议,关于暴露协议的封装由Protocol接口负责。
概述
服务引用的时机
Dubbo 服务引用的时机有两个,第一个是在 Spring 容器调用 ReferenceBean 的 afterPropertiesSet 方法时引用服务,第二个是在 ReferenceBean 对应的服务被注入到其他类中时引用。这两个引用服务的时机区别在于,第一个是饿汉式的,第二个是懒汉式的。默认情况下,Dubbo 使用懒汉式引用服务。如果需要使用饿汉式,可通过配置 dubbo:reference 的 init 属性开启。
服务引用概述过程
外界看到的某个接口的服务引用,而实际是dubbo 经过包装配置的invoker对象。在 Dubbo 中,我们可以通过两种方式引用远程服务。第一种是使用服务直连的方式引用服务,第二种方式是基于注册中心进行引用。服务直连的方式仅适合在调试或测试服务的场景下使用,不适合在线上环境使用。
当我们的服务被注入到其他类中时,Spring 会第一时间调用 getObject 方法,并由该方法执行服务引用逻辑。按照惯例,在进行具体工作之前,需先进行配置检查与收集工作。接着根据收集到的信息决定服务用的方式,有三种,第一种是引用本地 (JVM) 服务,第二是通过直连方式引用远程服务,第三是通过注册中心引用远程服务。不管是哪种引用方式,最后都会得到一个 Invoker 实例。如果有多个注册中心,多个服务提供者,这个时候会得到一组 Invoker 实例,此时需要通过集群管理类 Cluster 将多个 Invoker 合并成一个实例。合并后的 Invoker 实例已经具备调用本地或远程服务的能力了,但并不能将此实例暴露给用户使用,这会对用户业务代码造成侵入。此时框架还需要通过代理工厂类 (ProxyFactory) 为服务接口生成代理类,并让代理类去调用 Invoker 逻辑。避免了 Dubbo 框架代码对业务代码的侵入,同时也让框架更容易使用。
源码分析
服务引用的分析从 ReferenceBean 开始,看一下类结构
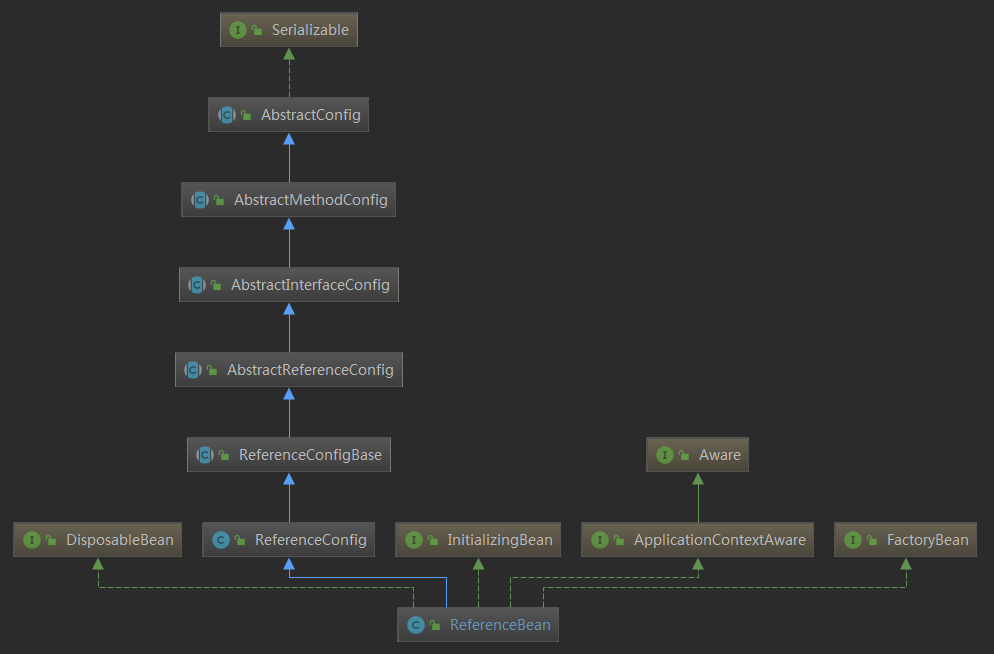
其中 FactoryBean 和 ApplicationContextAware, InitializingBean 都是继承自 spring 用于在 springboot 引用,
//这个方法重写自 InitializingBean,该方法用于当bean set完属性后,用户进行自定义的逻辑
@Override
@SuppressWarnings({"unchecked"})
public void afterPropertiesSet() throws Exception {
// 初始化 dubbo 配置 bean
// Initializes Dubbo's Config Beans before @Reference bean autowiring
prepareDubboConfigBeans();
// lazy init by default.
if (init == null) {
init = false;
}
// eager init if necessary.
if (shouldInit()) {
getObject();
}
}
通过 createProxy 的调用栈看到调用会经过 RegistryProtocol 的 doRefer 方法,从这里我们可以大概知道生成 invoker 的过程。

private <T> Invoker<T> doRefer(Cluster cluster, Registry registry, Class<T> type, URL url) {
//这个 RegistryDirectory 存放注册信息的资料,当注册信息发生变化的时候通过 subscribe 方法分发,内部存在一些监听器处理信息时间,同时内部
RegistryDirectory<T> directory = new RegistryDirectory<T>(type, url);
directory.setRegistry(registry);
directory.setProtocol(protocol);
// all attributes of REFER_KEY
Map<String, String> parameters = new HashMap<String, String>(directory.getUrl().getParameters());
URL subscribeUrl = new URL(CONSUMER_PROTOCOL, parameters.remove(REGISTER_IP_KEY), 0, type.getName(), parameters);
if (!ANY_VALUE.equals(url.getServiceInterface()) && url.getParameter(REGISTER_KEY, true)) {
directory.setRegisteredConsumerUrl(getRegisteredConsumerUrl(subscribeUrl, url));
registry.register(directory.getRegisteredConsumerUrl());
}
directory.buildRouterChain(subscribeUrl);
//订阅 providers、configurators、routers 等节点数据
directory.subscribe(subscribeUrl.addParameter(CATEGORY_KEY,
PROVIDERS_CATEGORY + "," + CONFIGURATORS_CATEGORY + "," + ROUTERS_CATEGORY));
//这才是真正生成 invoker 的地方
// 一个注册中心可能有多个服务提供者,因此这里需要将多个服务提供者合并为一个
Invoker invoker = cluster.join(directory);
return invoker;
}
我们发现在返回 inovker 之前的 ,会调用 RegistryDirectory 的 subscribe 方法,这个方法正是就是同个服务提供者生成多个 invoker 的地方,调用栈如下,可以看见该例中调用的是 DubboProtocol 。
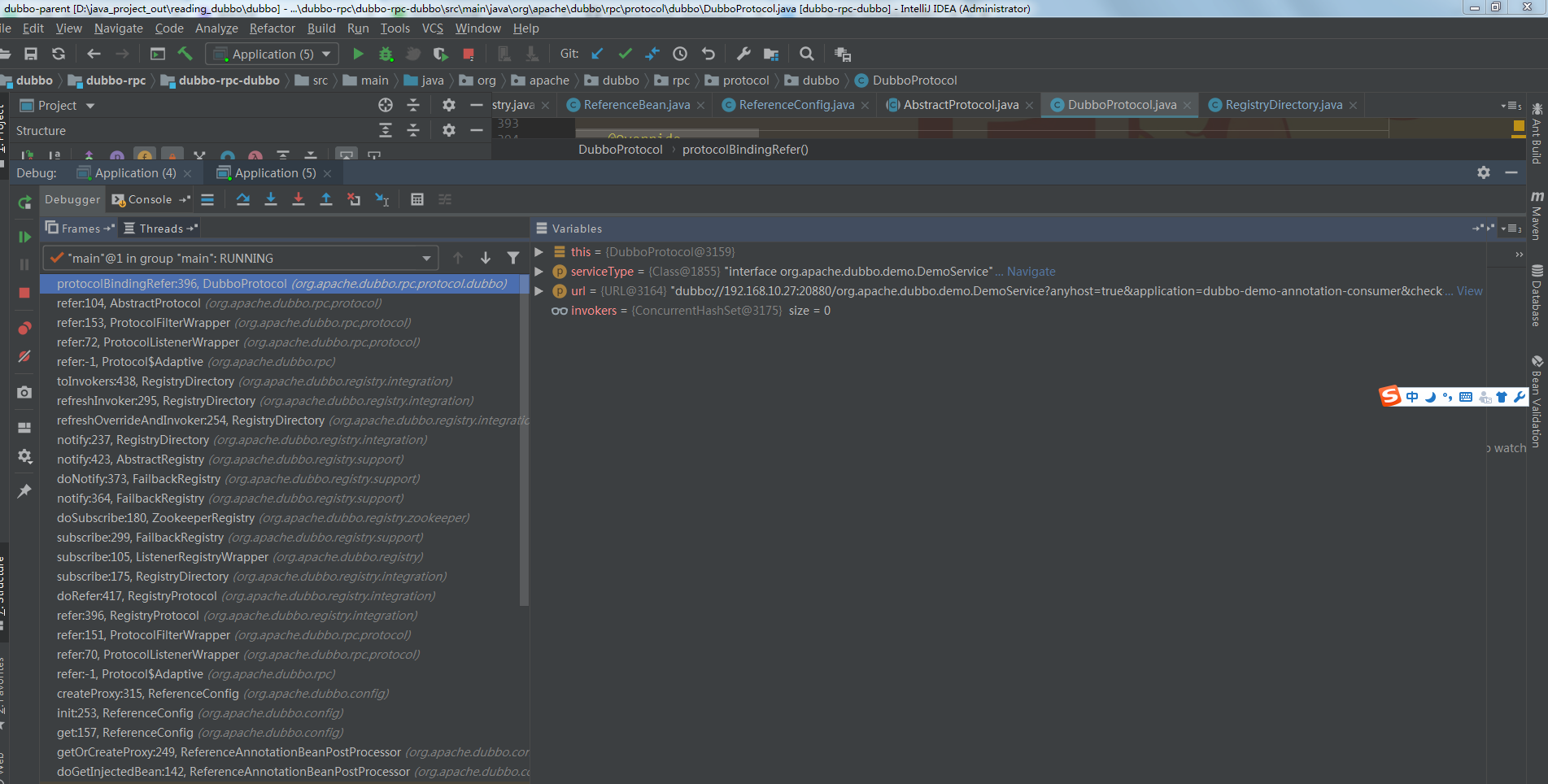
我们稍微讲解一下,然后再分析 DubboProtocol 生成 invoker 的过程。 首先,多个提供者生成 invoker 的步骤在 AbstractRegistry 的 notify 方法中(可以从前面的调用栈找到)
/**
* Notify changes from the Provider side.
*
* @param url consumer side url
* @param listener listener
* @param urls provider latest urls
*/
protected void notify(URL url, NotifyListener listener, List<URL> urls) {
...
// keep every provider's category. 找到提供者的目录(提供者信息)
Map<String, List<URL>> result = new HashMap<>();
for (URL u : urls) {
if (UrlUtils.isMatch(url, u)) {
String category = u.getParameter(CATEGORY_KEY, DEFAULT_CATEGORY);
List<URL> categoryList = result.computeIfAbsent(category, k -> new ArrayList<>());
categoryList.add(u);
}
}
if (result.size() == 0) {
return;
}
Map<String, List<URL>> categoryNotified = notified.computeIfAbsent(url, u -> new ConcurrentHashMap<>());
for (Map.Entry<String, List<URL>> entry : result.entrySet()) {
String category = entry.getKey();
List<URL> categoryList = entry.getValue();
categoryNotified.put(category, categoryList);
//更新操作!!!!要是第一次,必然多个提供者创建多个invoker,从调用栈可以看出下面的 notity 方法最终也调用到了 DubboProtocol 生成 DubboInvoker 的过程。
listener.notify(categoryList);
// We will update our cache file after each notification.
// When our Registry has a subscribe failure due to network jitter, we can return at least the existing cache URL.
saveProperties(url);
}
}
最后 AbstractProtocol 的 refer 被调用
@Override
public <T> Invoker<T> refer(Class<T> type, URL url) throws RpcException {
return new AsyncToSyncInvoker<>(protocolBindingRefer(type, url));
}
DubboProtocol 的 protocolBindingRefer 被调用 :
@Override
public <T> Invoker<T> protocolBindingRefer(Class<T> serviceType, URL url) throws RpcException {
optimizeSerialization(url);
// create rpc invoker.
DubboInvoker<T> invoker = new DubboInvoker<T>(serviceType, url, getClients(url), invokers);
invokers.add(invoker);
return invoker;
}
到了这里我们,逻辑不难懂,就是创建一个 DubboInvoker 然后返回。其中有个 getClients 的方法,这个方法用于获取客户端实例,实例类型为 ExchangeClient。ExchangeClient 实际上并不具备通信能力,它需要基于更底层的客户端实例进行通信。比如 NettyClient、MinaClient 等,默认情况下,Dubbo 使用 NettyClient 进行通信。这里做一下分析,DubboProtocol 的 buildReferenceCountExchangeClient 方法
/**
* Build a single client
*
* @param url
* @return
*/
private ReferenceCountExchangeClient buildReferenceCountExchangeClient(URL url) {
ExchangeClient exchangeClient = initClient(url);
return new ReferenceCountExchangeClient(exchangeClient);
}
/**
* Create new connection
*
* @param url
*/
private ExchangeClient initClient(URL url) {
// client type setting.
String str = url.getParameter(CLIENT_KEY, url.getParameter(SERVER_KEY, DEFAULT_REMOTING_CLIENT));
url = url.addParameter(CODEC_KEY, DubboCodec.NAME);
// enable heartbeat by default
url = url.addParameterIfAbsent(HEARTBEAT_KEY, String.valueOf(DEFAULT_HEARTBEAT));
// BIO is not allowed since it has severe performance issue.
if (str != null && str.length() > 0 && !ExtensionLoader.getExtensionLoader(Transporter.class).hasExtension(str)) {
throw new RpcException("Unsupported client type: " + str + "," +
" supported client type is " + StringUtils.join(ExtensionLoader.getExtensionLoader(Transporter.class).getSupportedExtensions(), " "));
}
ExchangeClient client;
try {
// connection should be lazy
if (url.getParameter(LAZY_CONNECT_KEY, false)) {
//假如有指定懒加载
client = new LazyConnectExchangeClient(url, requestHandler);
} else {
//使用 SPI 机制进行调用
client = Exchangers.connect(url, requestHandler);
}
} catch (RemotingException e) {
throw new RpcException("Fail to create remoting client for service(" + url + "): " + e.getMessage(), e);
}
return client;
}
最后会经过
/**
* DefaultMessenger
*
*
*/
public class HeaderExchanger implements Exchanger {
public static final String NAME = "header";
@Override
public ExchangeClient connect(URL url, ExchangeHandler handler) throws RemotingException {
// 这里包含了多个调用,分别如下:
// 1. 创建 HeaderExchangeHandler 对象
// 2. 创建 DecodeHandler 对象
// 3. 通过 Transporters 构建 Client 实例
// 4. 创建 HeaderExchangeClient 对象
return new HeaderExchangeClient(Transporters.connect(url, new DecodeHandler(new HeaderExchangeHandler(handler))), true);
}
...
}
而这个 Transporters中的 connect 方法 也是同样的套路,也是使用 SPI 机制,
public static Client connect(URL url, ChannelHandler... handlers) throws RemotingException {
if (url == null) {
throw new IllegalArgumentException("url == null");
}
ChannelHandler handler;
if (handlers == null || handlers.length == 0) {
handler = new ChannelHandlerAdapter();
} else if (handlers.length == 1) {
handler = handlers[0];
} else {
handler = new ChannelHandlerDispatcher(handlers);
}
//SPI 机制
return getTransporter().connect(url, handler);
}
默认是 netty
public class NettyTransporter implements Transporter {
...
@Override
public Client connect(URL url, ChannelHandler listener) throws RemotingException {
return new NettyClient(url, listener);
}
}
总结
我们可以说服务引用就是Dubbo进行 :
- 消费者注册
- 封装 invoker 返回给消费者,供消费者透明使用 的过程。
参考资料
- dubbo 官方文档