文章图片来自《MySQL 45讲》非原创
概述
本文将会介绍 order by 排序中的两种情况
- 内存充足,全字段排序
- 内存不充裕,rowid 排序
什么意思呢?全字段排序讲的是整行拿到 sort buffer 中进行排序,然后返回正确的结果给客户端,而 rowid 排序只是取一行中部分字段到 sort buffer 中进行排序,而是否使用到了临时文件则是sort buffer 不够(也有可能需要排序的行数过多,总的来说就是需要排序的行数相对于sort buffer 太大了)这时就会使用到临时文件,使用到临时文件肯定相对于使用内存速度会慢,假如出现这种情况可以优化 SQL 语句对查询进行优化。
示例
例子来自 《MySQL 45讲》非原创 加入我们存在以下表 :
CREATE TABLE `t` ( `id` int(11) NOT NULL, `city` varchar(16) NOT NULL, `name` varchar(16) NOT NULL, `age` int(11) NOT NULL, `addr` varchar(128) DEFAULT NULL, PRIMARY KEY (`id`), KEY `city` (`city`) ) ENGINE=InnoDB;
查询语句如下
select city,name,age from t where city='杭州' order by name limit 1000 ;
然后我们使用 explain 查看一下这条语句的执行逻辑。

Extra这个字段中的“Using filesort”表示的就是需要排序,MySQL会给每个线程分配一块内存用于排序,称为sort_buffer。
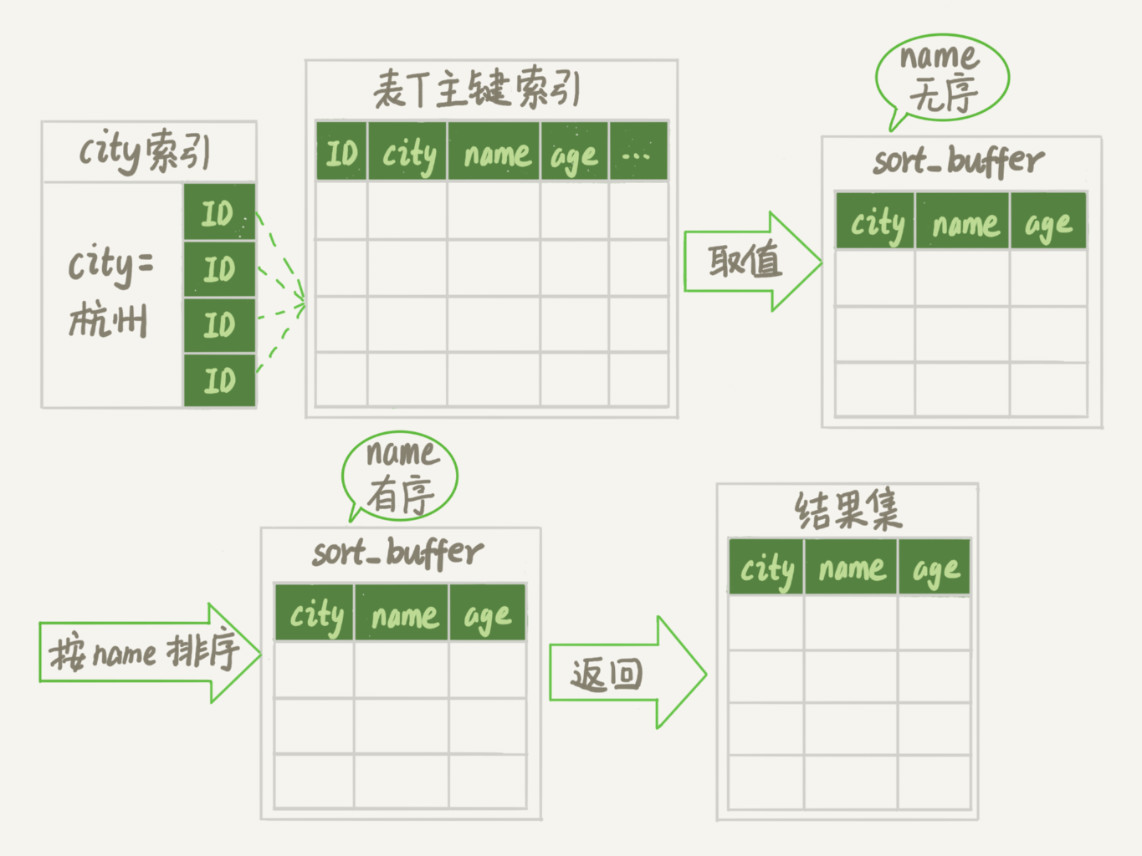
为了说明这个SQL查询语句的执行过程,我们先来看一下city这个索引的示意图。

全排序排序
通常情况下,这个语句执行流程如下所示 :
- 初始化sort_buffer,确定放入name、city、age这三个字段;
- 从索引city找到第一个满足city='杭州’条件的主键id,也就是图中的ID_X;
- 到主键id索引取出整行,取name、city、age三个字段的值,存入sort_buffer中;
- 从索引city取下一个记录的主键id;
- 重复步骤3、4直到city的值不满足查询条件为止,对应的主键id也就是图中的ID_Y;
- 对sort_buffer中的数据按照字段name做快速排序;
- 按照排序结果取前1000行返回给客户端。
我们暂且把这个排序过程,称为全字段排序,执行流程的示意图如下所示,下一篇文章中我们还会用到这个排序。
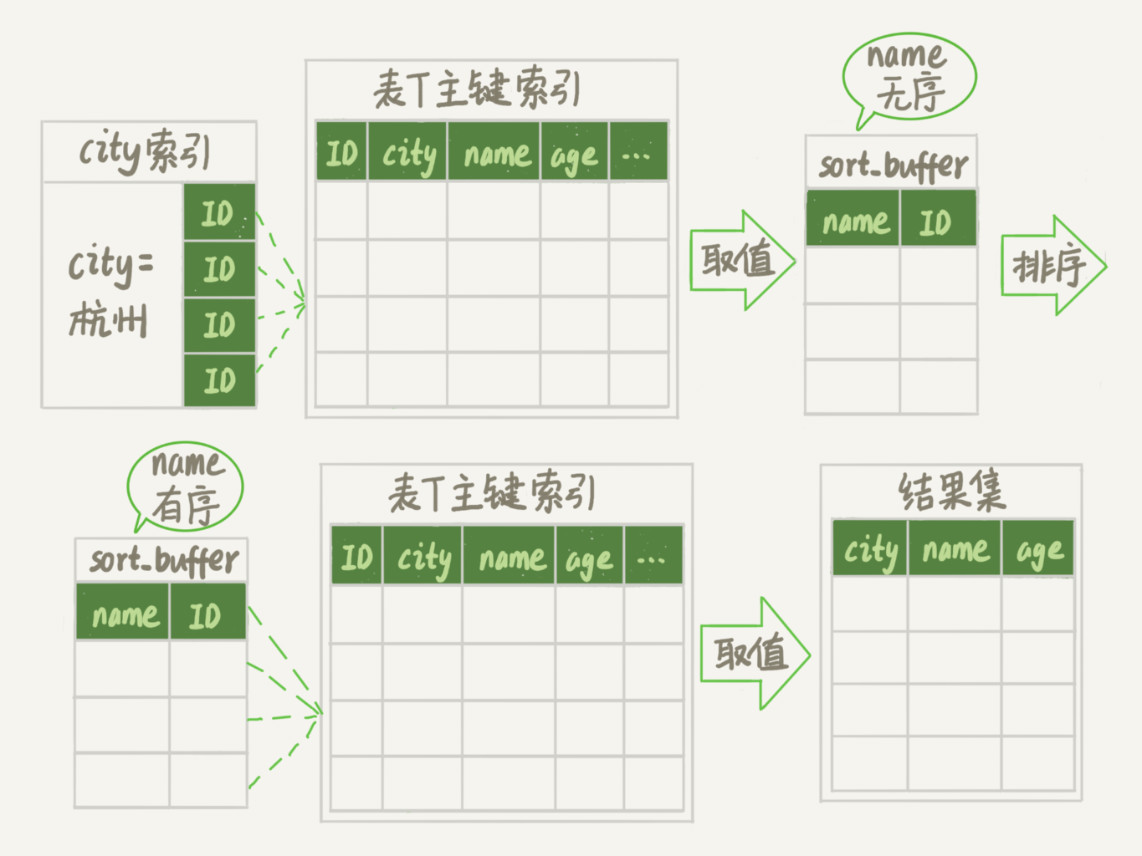
rowid 排序
在全字段排序中,我们是取整一行数据放在 sort buffer 中进行排序,而 rowid 排序则是取部分字段,然后排好后,再回表找到想要返回的字段,回表的操作必定比不回表的操作慢,假如需要我们优化查询语句可以使用覆盖索引进行优化查询语句
补充:
参考
- 《MySQL 45讲》
{
"steps": [
{
"join_preparation": {
"select#": 1,
"steps": [
{
"expanded_query": "/* select#1 */ select t1.city AS city,t1.name AS name,t1.age AS age from t1 where (t1.city = '苏州') order by t1.name limit 1000"
}
]
}
},
{
"join_optimization": {
"select#": 1,
"steps": [
{
"condition_processing": {
"condition": "WHERE",
"original_condition": "(t1.city = '苏州')",
"steps": [
{
"transformation": "equality_propagation",
"resulting_condition": "(t1.city = '苏州')"
},
{
"transformation": "constant_propagation",
"resulting_condition": "(t1.city = '苏州')"
},
{
"transformation": "trivial_condition_removal",
"resulting_condition": "(t1.city = '苏州')"
}
]
}
},
{
"substitute_generated_columns": {
}
},
{
"table_dependencies": [
{
"table": "t1",
"row_may_be_null": false,
"map_bit": 0,
"depends_on_map_bits": [
]
}
]
},
{
"ref_optimizer_key_uses": [
{
"table": "t1",
"field": "city",
"equals": "'苏州'",
"null_rejecting": false
}
]
},
{
"rows_estimation": [
{
"table": "t1",
"range_analysis": {
"table_scan": {
"rows": 14963,
"cost": 1524.3
},
"potential_range_indexes": [
{
"index": "PRIMARY",
"usable": false,
"cause": "not_applicable"
},
{
"index": "city",
"usable": true,
"key_parts": [
"city",
"id"
]
}
],
"setup_range_conditions": [
],
"group_index_range": {
"chosen": false,
"cause": "not_group_by_or_distinct"
},
"skip_scan_range": {
"potential_skip_scan_indexes": [
{
"index": "city",
"usable": false,
"cause": "query_references_nonkey_column"
}
]
},
"analyzing_range_alternatives": {
"range_scan_alternatives": [
{
"index": "city",
"ranges": [
"苏州 <= city <= 苏州"
],
"index_dives_for_eq_ranges": true,
"rowid_ordered": true,
"using_mrr": false,
"index_only": false,
"rows": 3058,
"cost": 1121.5,
"chosen": true
}
],
"analyzing_roworder_intersect": {
"usable": false,
"cause": "too_few_roworder_scans"
}
},
"chosen_range_access_summary": {
"range_access_plan": {
"type": "range_scan",
"index": "city",
"rows": 3058,
"ranges": [
"苏州 <= city <= 苏州"
]
},
"rows_for_plan": 3058,
"cost_for_plan": 1121.5,
"chosen": true
}
}
}
]
},
{
"considered_execution_plans": [
{
"plan_prefix": [
],
"table": "t1",
"best_access_path": {
"considered_access_paths": [
{
"access_type": "ref",
"index": "city",
"rows": 3058,
"cost": 383.4,
"chosen": true
},
{
"access_type": "range",
"range_details": {
"used_index": "city"
},
"chosen": false,
"cause": "heuristic_index_cheaper"
}
]
},
"condition_filtering_pct": 100,
"rows_for_plan": 3058,
"cost_for_plan": 383.4,
"chosen": true
}
]
},
{
"attaching_conditions_to_tables": {
"original_condition": "(t1.city = '苏州')",
"attached_conditions_computation": [
],
"attached_conditions_summary": [
{
"table": "t1",
"attached": "(t1.city = '苏州')"
}
]
}
},
{
"optimizing_distinct_group_by_order_by": {
"simplifying_order_by": {
"original_clause": "t1.name",
"items": [
{
"item": "t1.name"
}
],
"resulting_clause_is_simple": true,
"resulting_clause": "t1.name"
}
}
},
{
"finalizing_table_conditions": [
{
"table": "t1",
"original_table_condition": "(t1.city = '苏州')",
"final_table_condition ": null
}
]
},
{
"refine_plan": [
{
"table": "t1"
}
]
},
{
"considering_tmp_tables": [
{
"adding_sort_to_table": "t1"
}
]
}
]
}
},
{
"join_execution": {
"select#": 1,
"steps": [
{
"sorting_table": "t1",
"filesort_information": [
{
"direction": "asc",
"expression": "t1.name"
}
],
"filesort_priority_queue_optimization": {
"limit": 1000,
"chosen": true
},
"filesort_execution": [
],
"filesort_summary": {
"memory_available": 262144,
"key_size": 32,
"row_size": 138,
"max_rows_per_buffer": 1001,
"num_rows_estimate": 47566,
"num_rows_found": 3058,
"num_initial_chunks_spilled_to_disk": 0,
"peak_memory_used": 146146,
"sort_algorithm": "std::stable_sort",
"unpacked_addon_fields": "using_priority_queue",
"sort_mode": "<fixed_sort_key, additional_fields>"
}
}
]
}
}
]
}