概述
项目背景 : 我们的某个服务是专门执行自动任务的 , 对外提供一个 jar 包里面有个自动任务的接口 , 然后各种自动任务的实现在其他各个项目, 并且作为服务提供者注册到zookeeper 上 . 项目在开发阶段时开发环境出现了CPU彪升 , 占用大量内存的现象.
现象
先按 top 命令 ,然后再按大写的 P
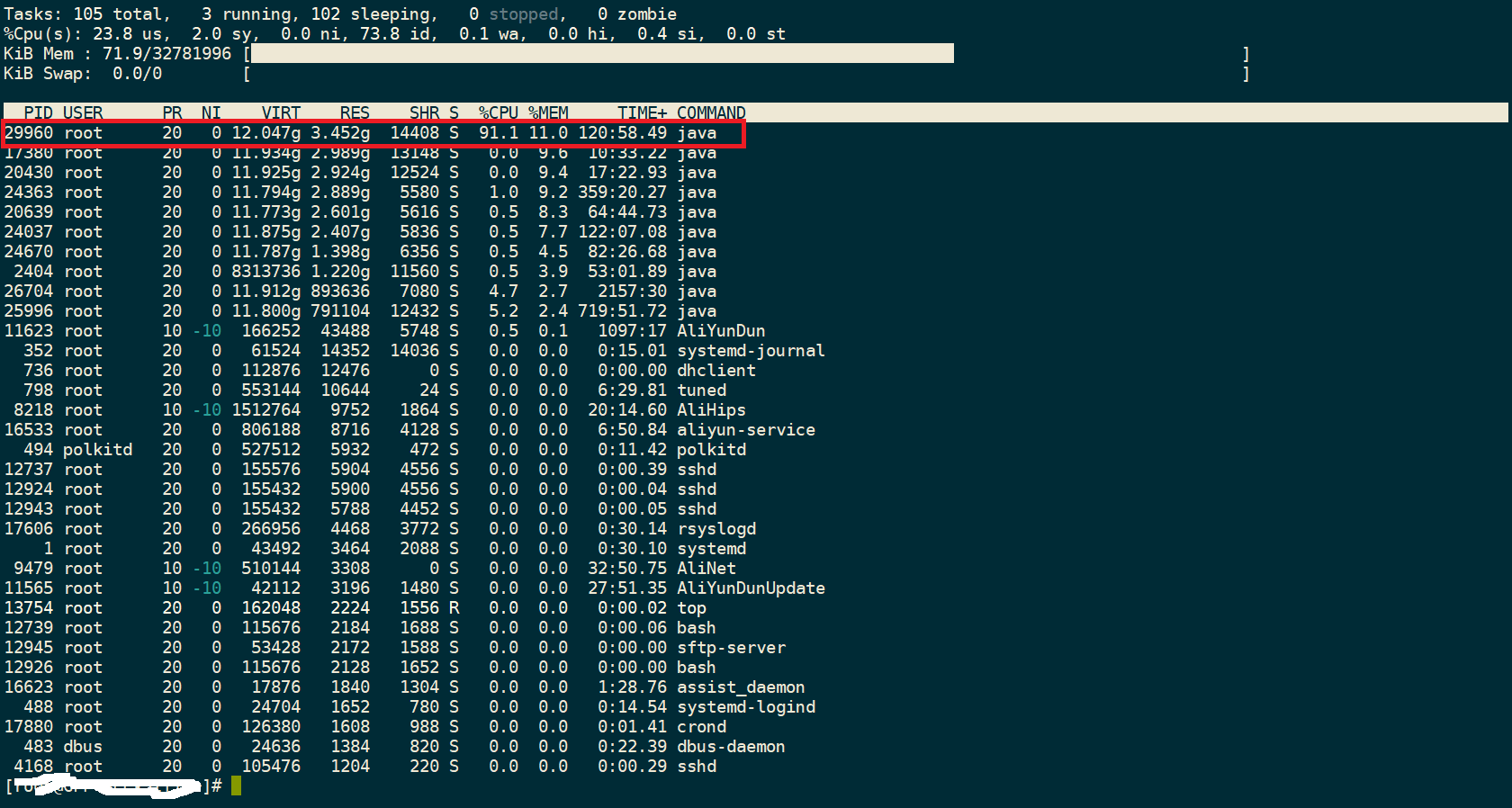
可以看到 PID 29960 占的 CPU 已经达到 91% , (有时候也可能超过 100% , 这是因为多核 CPU 的原因) , 我们首先确定这个PID 对应的应用是什么
ps -aux | grep '29960'
比如说这个应用是 admin , 下面我们在查看一下该 PID 下那个线程消耗的 CPU 资源高 .
top -p 41843 -H
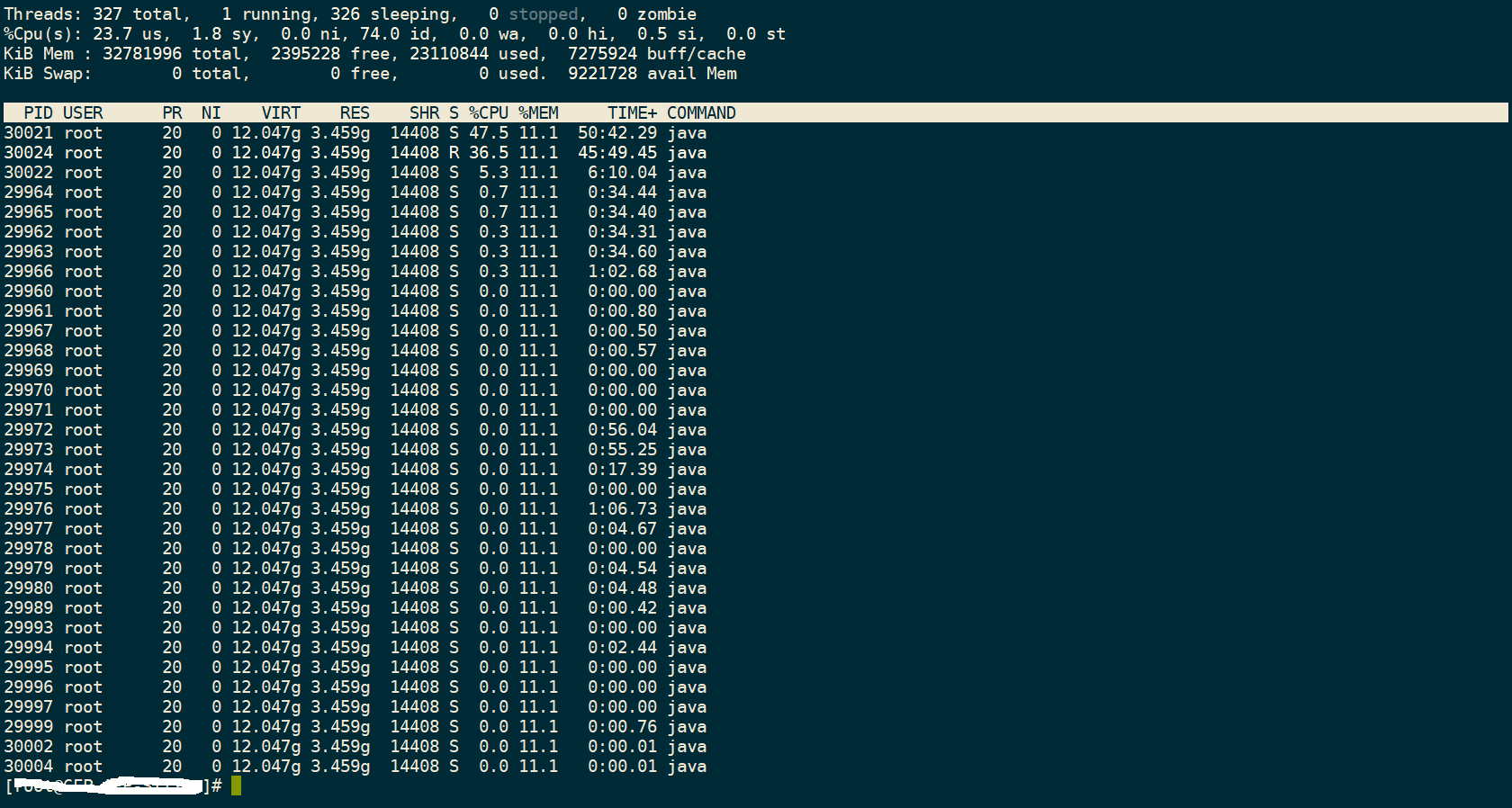
OK , 这里我们已经知道了该 PID 的最忙的线程, 我们稍微看一下这个线程在干什么事
strace -p 30021
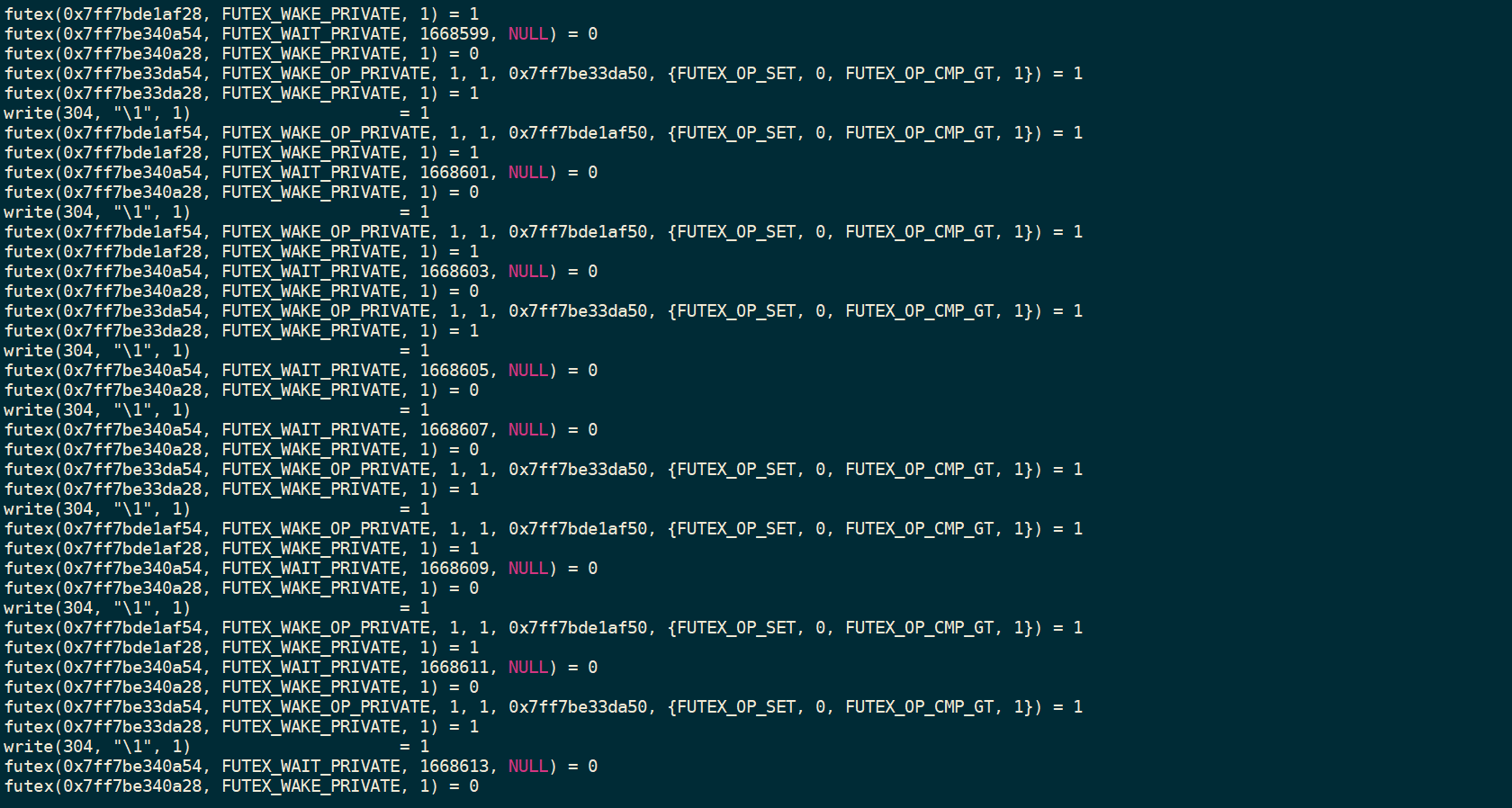
可以看到多个线程正在进行大量的自旋中(自旋锁) , 那么下面我们利用 jstace 命令进行查看这个线程的位置和堆栈 . 使用 jstace
找到某个线程的时候会用到16进制
printf "%x
" 30021
然后使用 jstace 命令
jstack -l 30021 | grep 0x7545 -A20
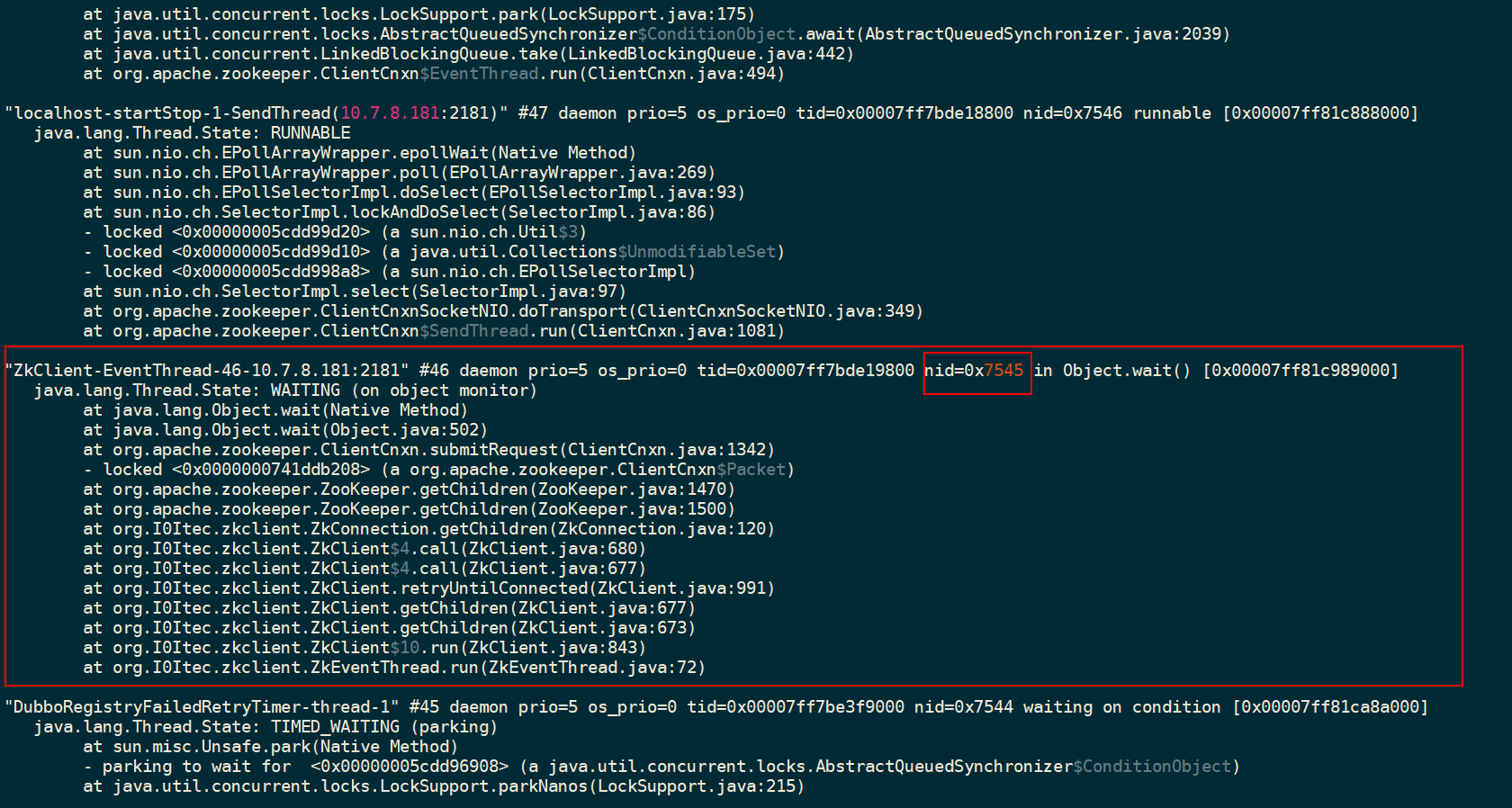
ok , 我们每过几秒在运行一下上面的命令就可以知道该线程是否给阻塞了.
dump 内存文件分析
我们通过上面了知道 CPU 飙升地厉害, 而内存也占用了不少, 于是我们 dump 下了文件进行分析, 我们用 jmap 命令, 然后放大 MAT工具进行分析.
jmap -dump:live,format=b,file=2021-7-17-21-05.dump 29960
一般dump 下来的文件比较大, 我们可以压缩一下文件
tar -zcvf 2021-7-17-21-05.gz 2021-7-17-21-05.dump
然后下载下来扔到 MAT工具里
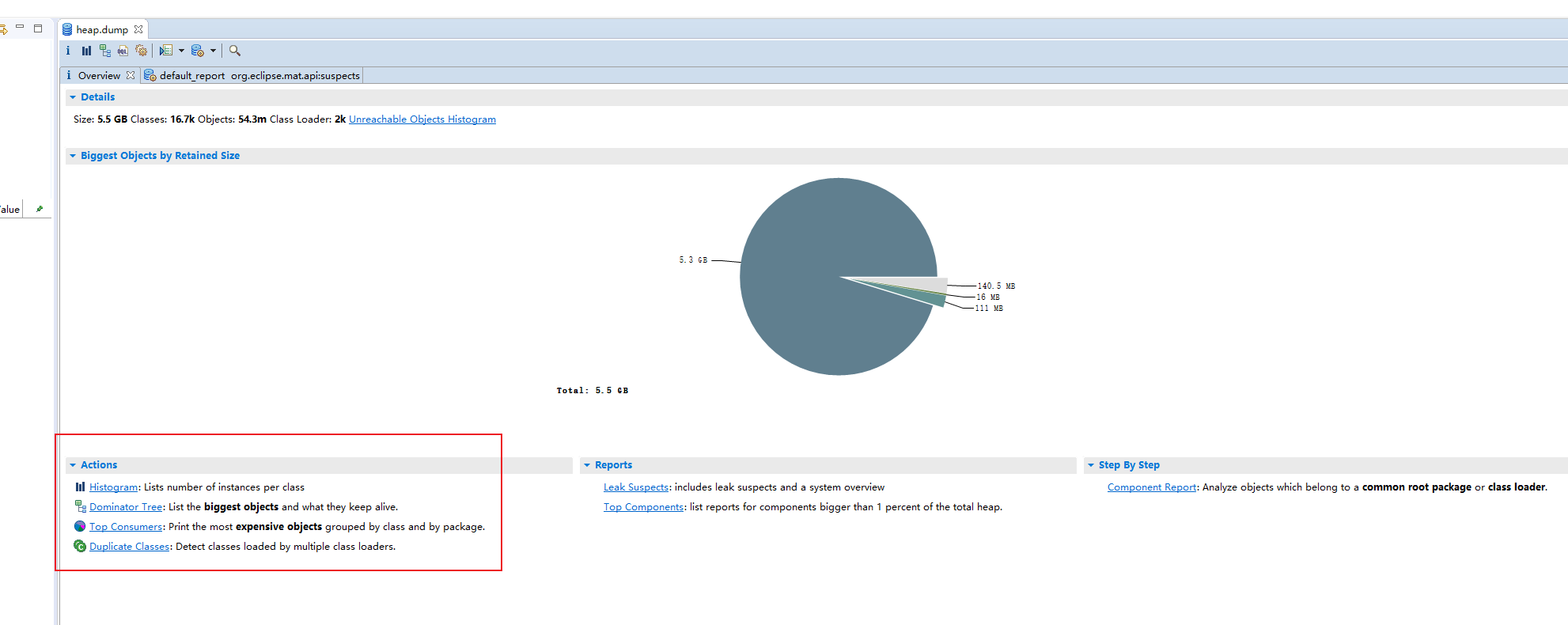
可以看到下面的分析, 其中画红色圈圈的需要关注一下, 我们首先看一下创建实例的数量排序
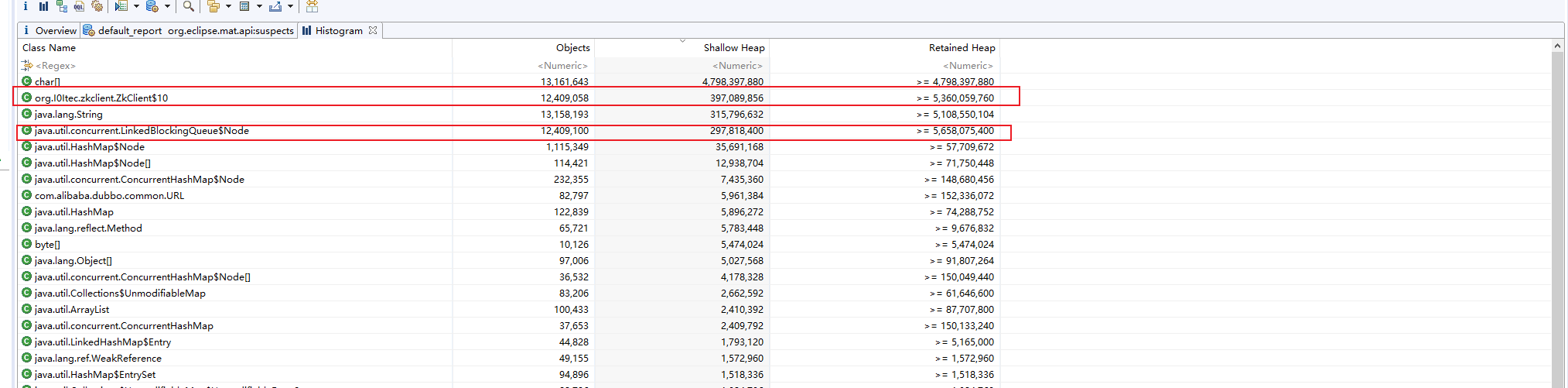
可以看到 zkClient里面的一个内部类对象创建了很多个实例, 并且从占用的内存也可以看出确实是这些对象占用了大量的内存
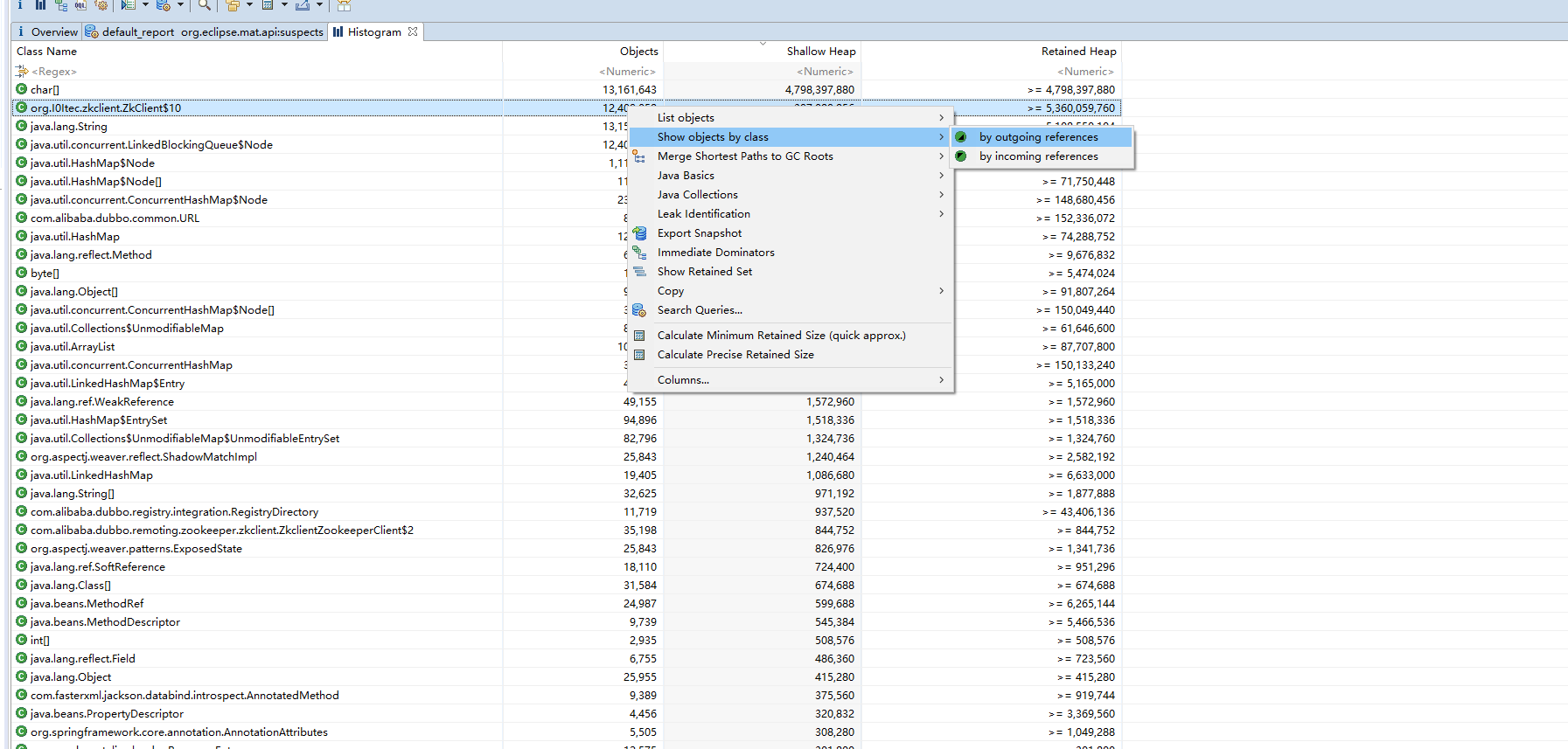
我们看一下引用该对象的有哪些呢? 下面我们先来看看该类在哪里定义, 又为何创建那么多的对象
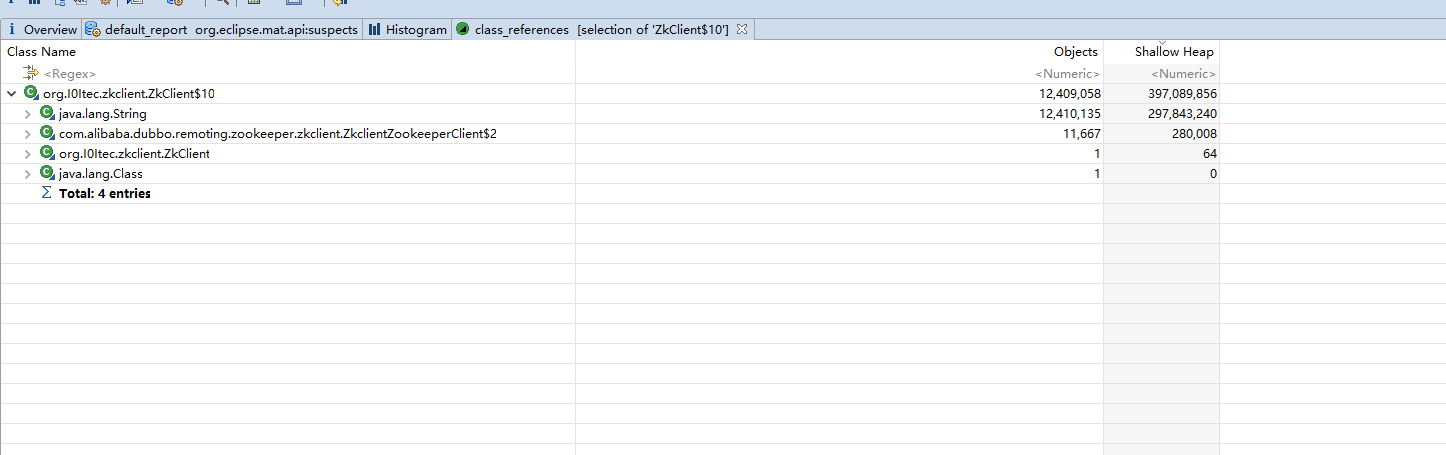
dubbo 框架应用了它, dubbo进入了我们观察的视野, 再看一下大对象分析,
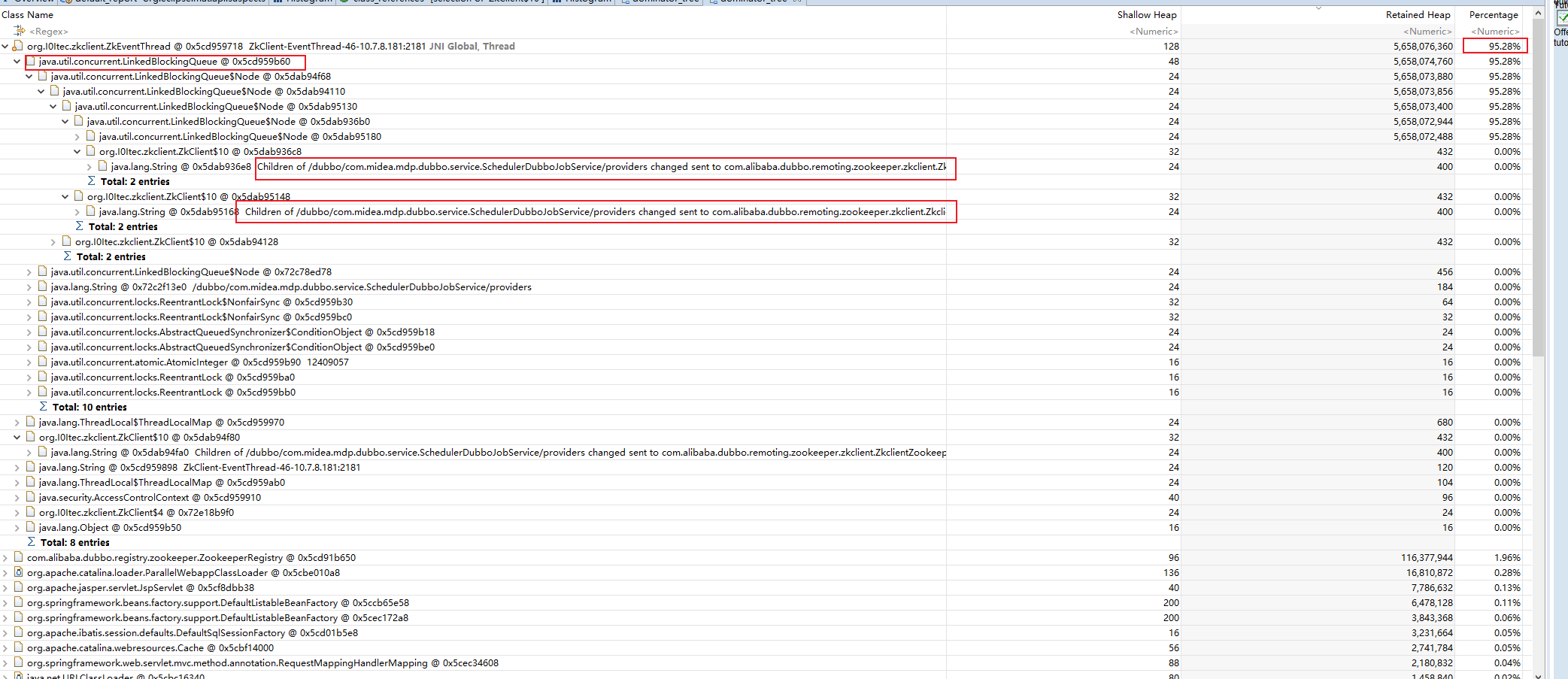
可以看到 zkClient 这个类的某个实例占的内存高达 95% 也就是大概 5G 左右的内存都是消耗在这个对象上的, 我们点开它的属性,发现了里面的一个队列占了大部分的内存比例, 而这些对象都有个特点就是 , zkClient 的某个字段都是 : Children of /dubbo/com.midea.mdp.dubbo.service.SchedulerDubboJobService/providers changed sent to com.alibaba.dubbo.remoting.zookeeper.zkclient.ZkclientZookeeperClient$2@7ecbb7e6
再看看下面的图
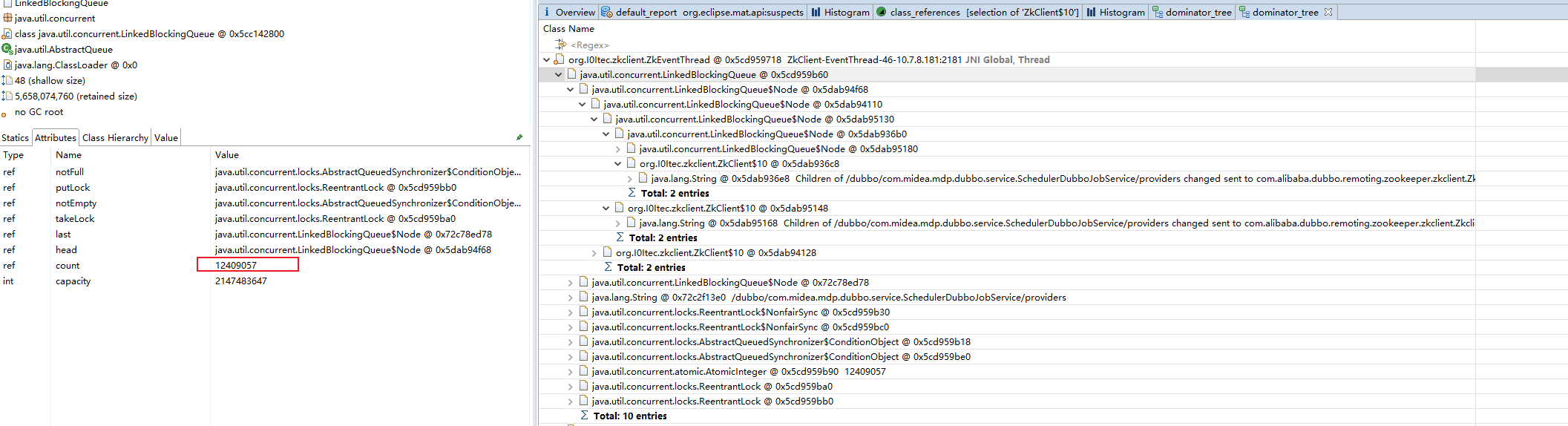
这个队列的数量达到了千万级别的数目, 非常不正常. OK , 下面将根据我们的线索, 我们将会分析占用内存和占用CPU 的原因
class ZkEventThread extends Thread {
private static final Logger LOG = LoggerFactory.getLogger(ZkEventThread.class);
private BlockingQueue<ZkEvent> _events = new LinkedBlockingQueue<ZkEvent>();
private static AtomicInteger _eventId = new AtomicInteger(0);
static abstract class ZkEvent {
private String _description;
public ZkEvent(String description) {
_description = description;
}
public abstract void run() throws Exception;
@Override
public String toString() {
return "ZkEvent[" + _description + "]";
}
}
ZkEventThread(String name) {
setDaemon(true);
setName("ZkClient-EventThread-" + getId() + "-" + name);
}
@Override
public void run() {
LOG.info("Starting ZkClient event thread.");
try {
while (!isInterrupted()) {
ZkEvent zkEvent = _events.take();
int eventId = _eventId.incrementAndGet();
LOG.debug("Delivering event #" + eventId + " " + zkEvent);
try {
zkEvent.run();
} catch (InterruptedException e) {
interrupt();
} catch (ZkInterruptedException e) {
interrupt();
} catch (Throwable e) {
LOG.error("Error handling event " + zkEvent, e);
}
LOG.debug("Delivering event #" + eventId + " done");
}
} catch (InterruptedException e) {
LOG.info("Terminate ZkClient event thread.");
}
}
public void send(ZkEvent event) {
if (!isInterrupted()) {
LOG.debug("New event: " + event);
_events.add(event);
}
}
}
该类继承了 Thread , 可以知道是线程任务类, 该类持有一个阻塞队列, 执行的任务就是不断从中拿去任务出来,然后进行处理. 我们通过代码可以知道该线程的作用是处理 zk 发过来的事件.
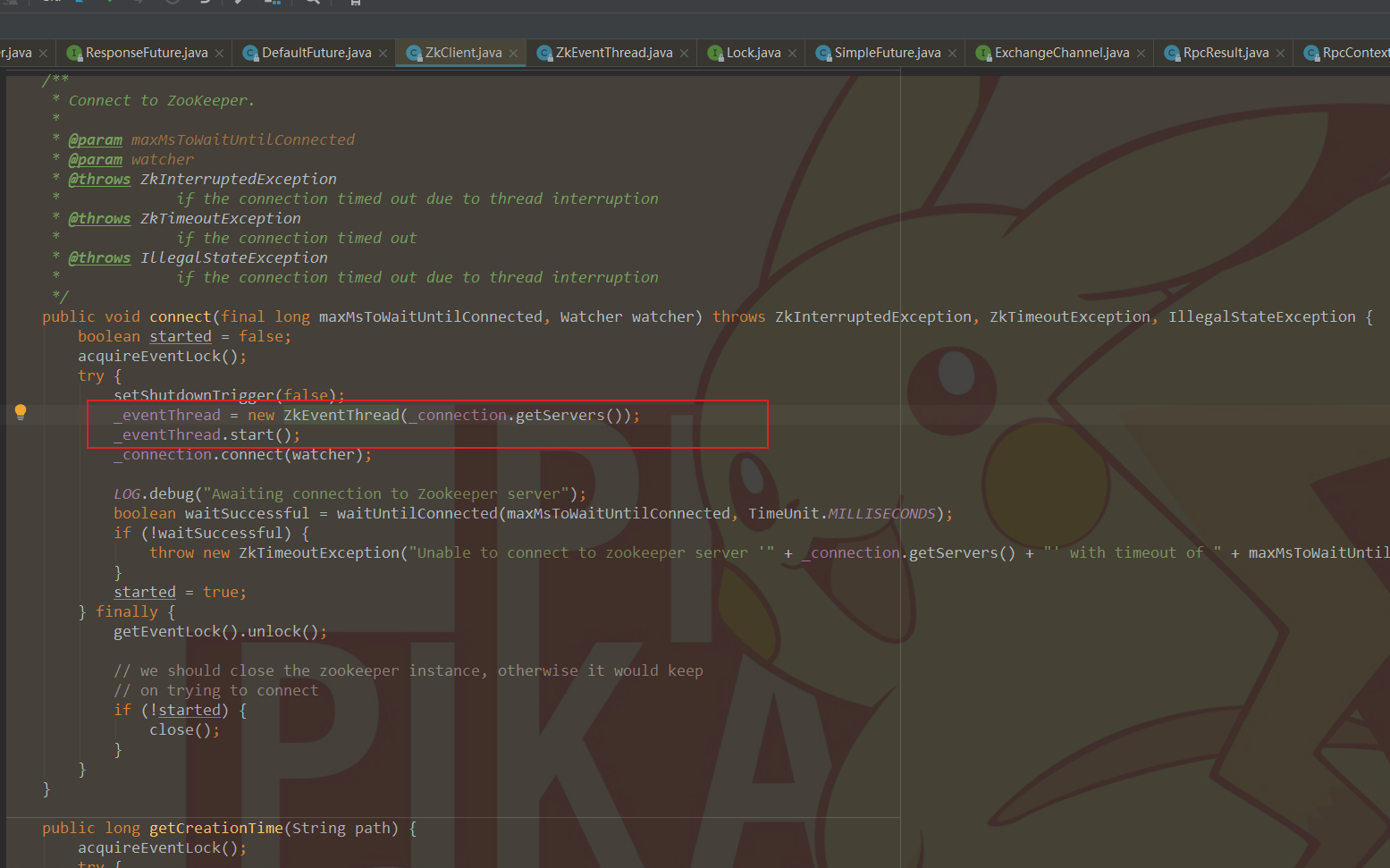
我们可以看到这个 EventThread 在 zkClient 中进行初始化并运行线程执行任务的调用. 知道了这些 , 我分析有两种情况会导致这种现象
- 大量发过来的 event ,直接压垮了处理事件的线程 , event 都在阻塞队列中, 所以我们可以看到那么多的自旋锁在不断尝试获得锁
- 队列的处理过程中遇到了阻塞 ,相当于生产者的效率大大大于消费者, 所以时间久了自然就堆积了.
我先对第二种情况进行了验证, 这里用到了阿里的一个工具arthas,
trace org.I0Itec.zkclient.ZkEventThread$ZkEvent run
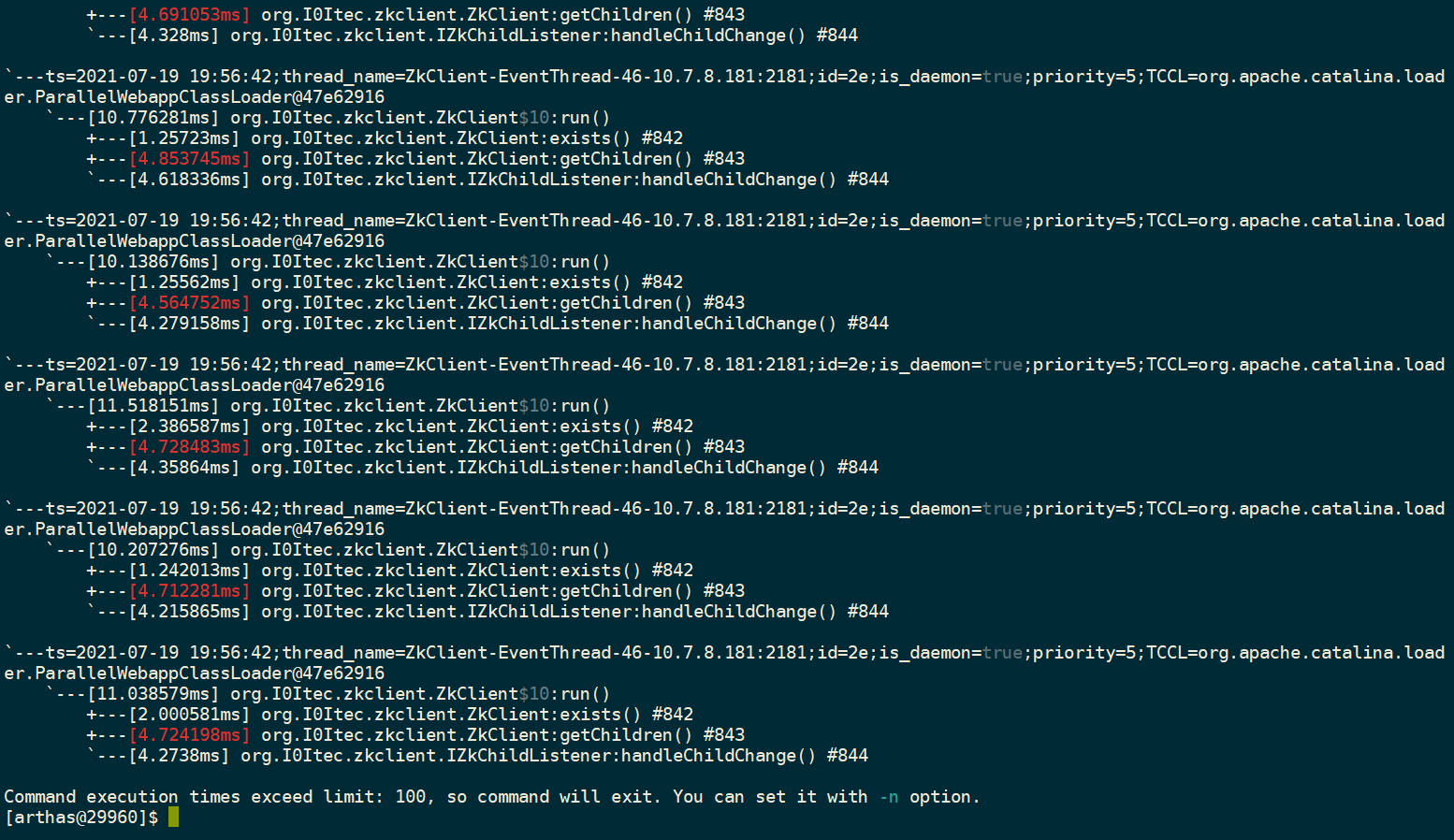
我们可以看到处理事件的线程并没有啥问题 , 处理一个任务都是以毫秒计算的. ok ,既然第二种猜想是不成力的, 那么第一种呢?假设第一种猜想是正确的, 那么事件为什么又会产生那么多呢? 根据我们前面的 MAT 的分析 , 看到了都是
Children of /dubbo/com.xx.mdp.dubbo.service.SchedulerDubboJobService/providers changed sent to com.alibaba.dubbo.remoting.zookeeper.zkclient.ZkclientZookeeperClient$2@7ecbb7e6
这一个相关的事件 ,于是我在代码中进行了跟踪, 找到了事件插入队列的地方 :
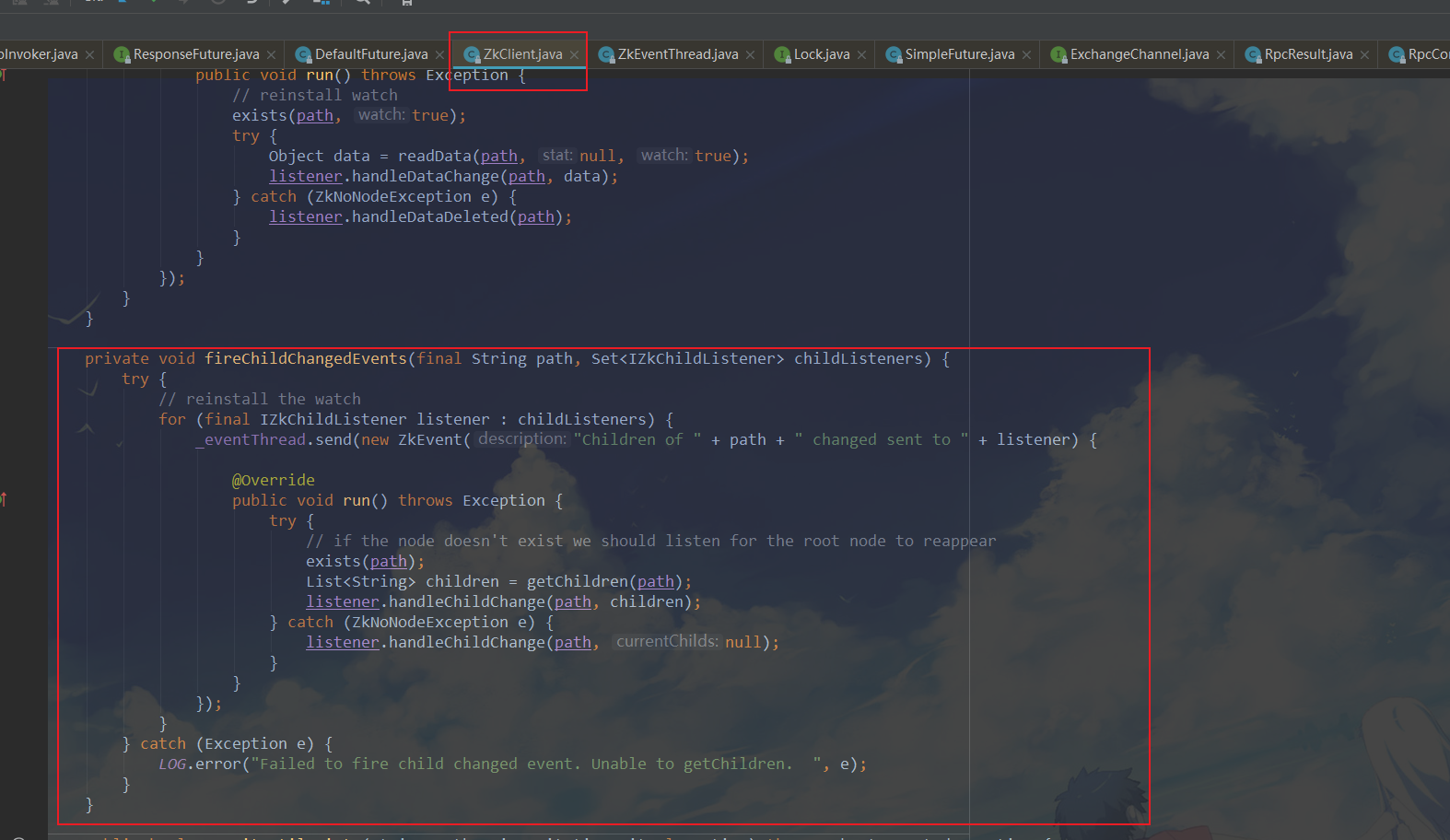
依然使用 trace命令进行查看插入队列的方法是否正常, 判断是否是应该插入的速率远远大于取出的速率
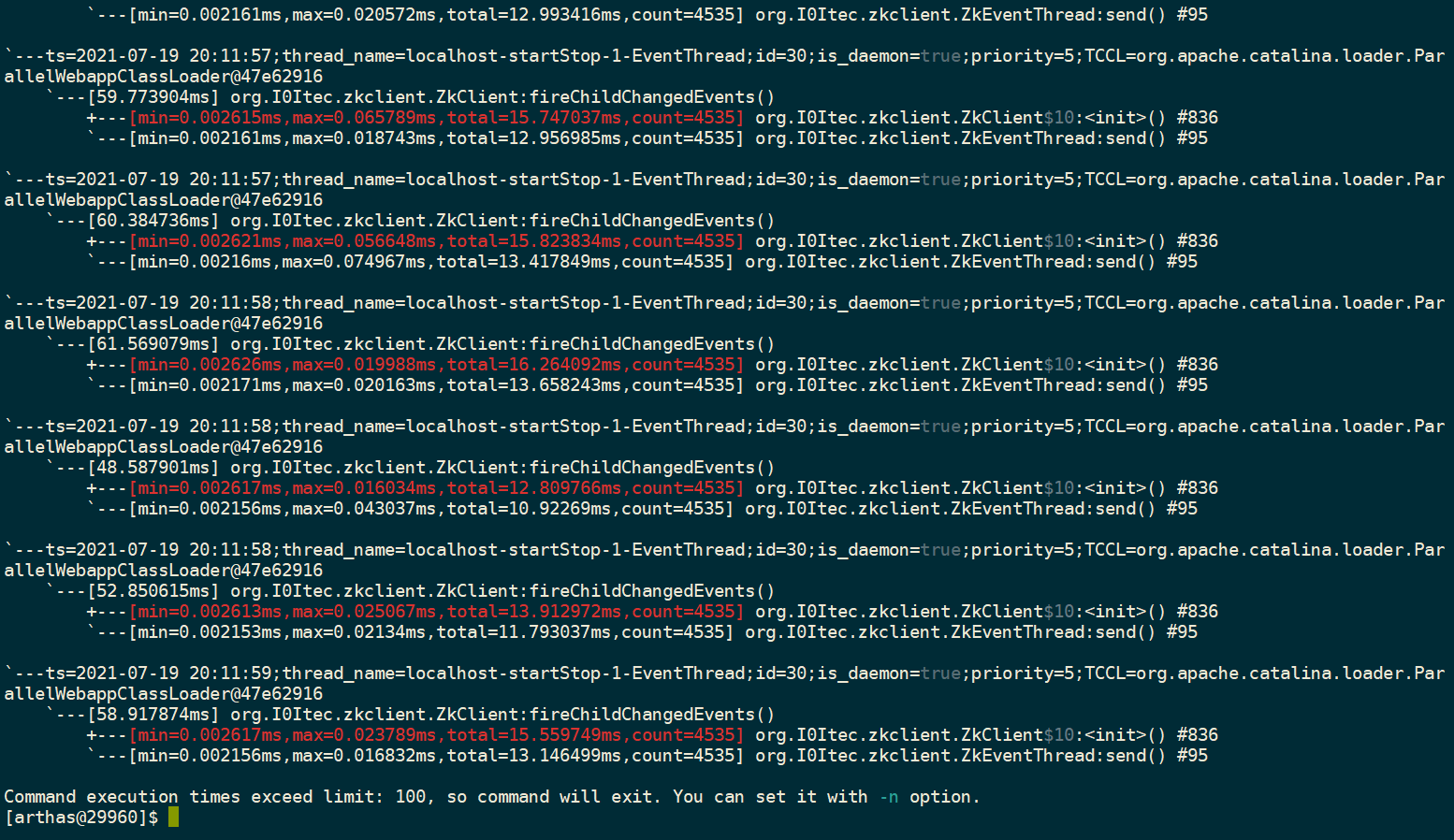
通过上面的分析, 我们基本可以确定的是 :
- 大量的 zk 节点事件阻塞在队列中, 导致自旋锁, 导致CPU 上升, 由于大量数量事件对象导致占用了大量的内存
- 一种可能是由于事件太多, 导致事件堆积; 处理事件的线程处理效率低导致大量事件堆积, 从上面的
trace查看已经证明处理线程并没有阻塞, 处理速度也正常, 下面我们将按照大量事件导致事件堆积的思路进行排查
项目背景
其他项目提供自动任务的提供者 , 最后都由 admin 进行调用消费, zk 节点情况如下 。 admin 应用作用自动任务的执行者, 会定时去调用外部的定时任务接口, 而外部的定时任务接口是使用dubbo, 注册在 zk 上的某个固定节点下, 那么外部的应用是 dubbo 提供者, 而 admin 应用作为消费者,我们刚好在该环境内进行开发测试, 会频繁地上下线应用. 节点结构如下图,
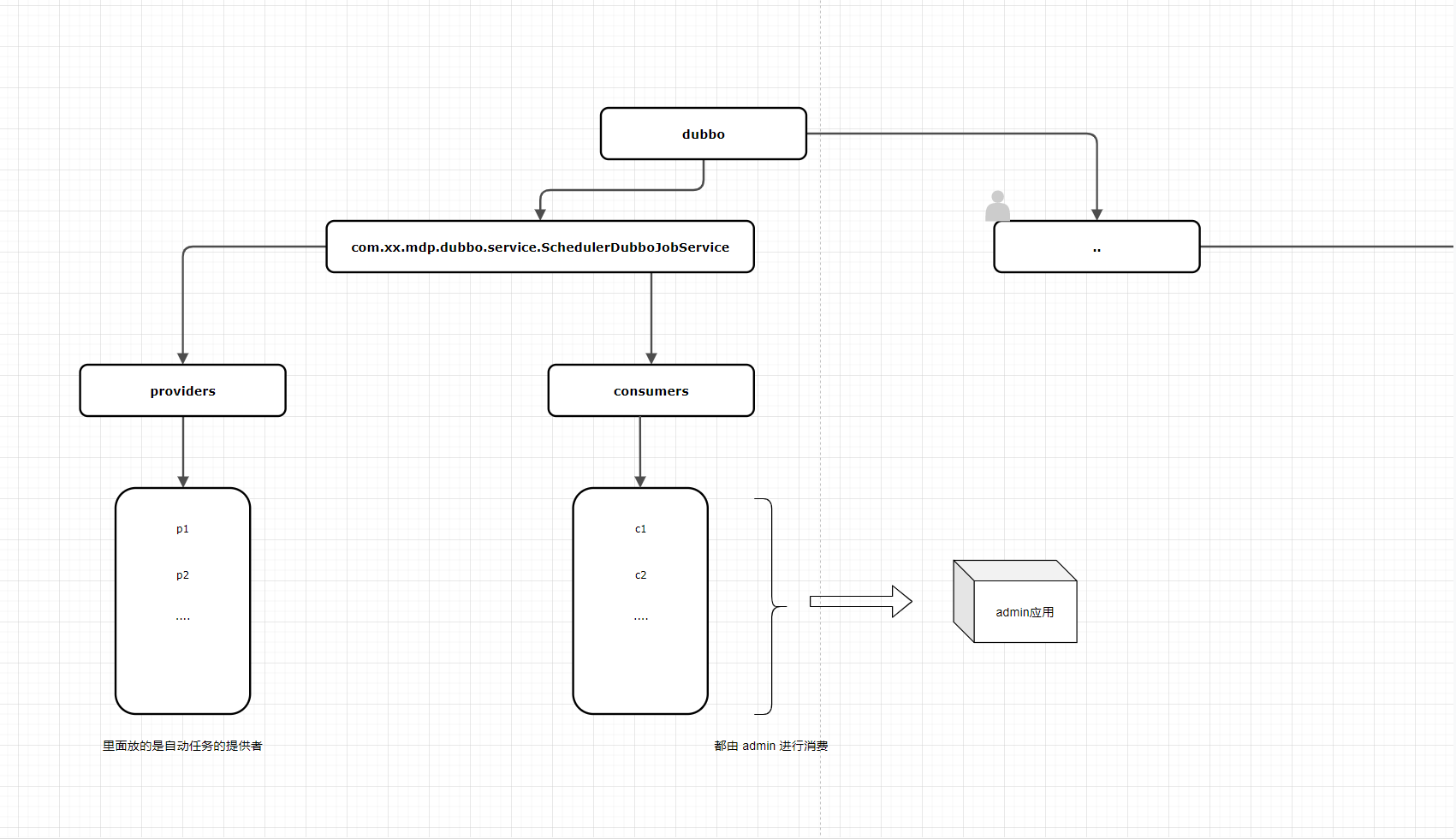
验证猜想
也就是说所有的消费者都在 admin 应用, 而外部的应用充当提供者 , 既然节点是 zk 发的, 那么有没有可能是由于频繁地上下线导致的zk节点变化事件大量产生呢?于是我做了以下实验 , 通过打印日志的方式得到收到事件的数量.
demo案例模拟
为了模拟dubbo 消费者和生产者之间上下线产生的节点变化事件 , 我写了一个 consumer 项目模拟成 admin 一样的角色, 对外提供接口给外围系统实现, 外围作为提供者注册到 zk 节点, 可以看到提供者有4个. 我们将模拟以下场景
consumer 消费者
provider1 提供者
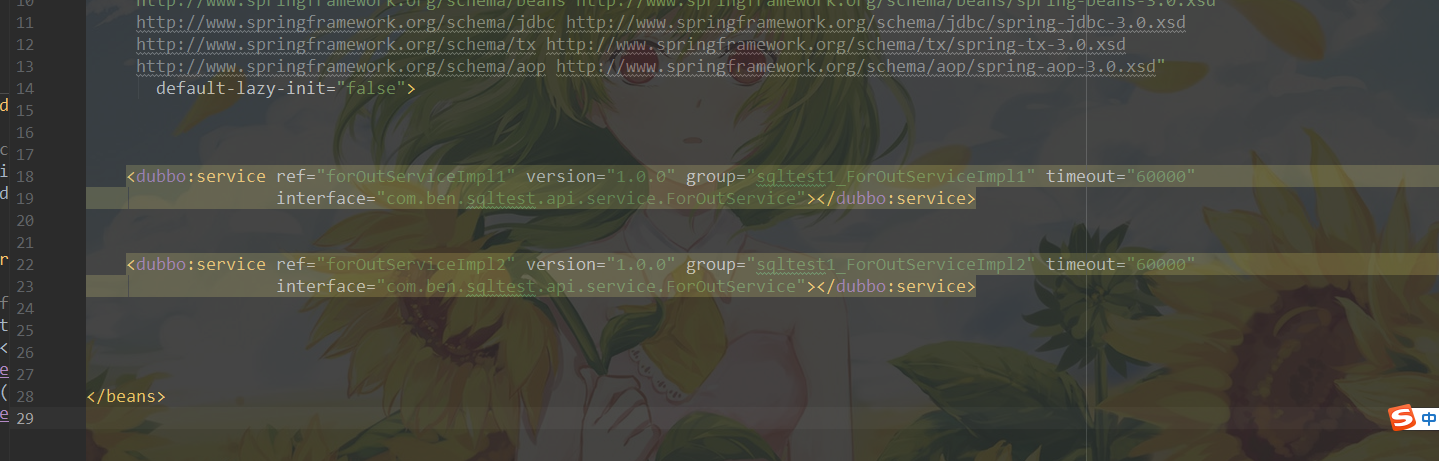
provider2 提供者
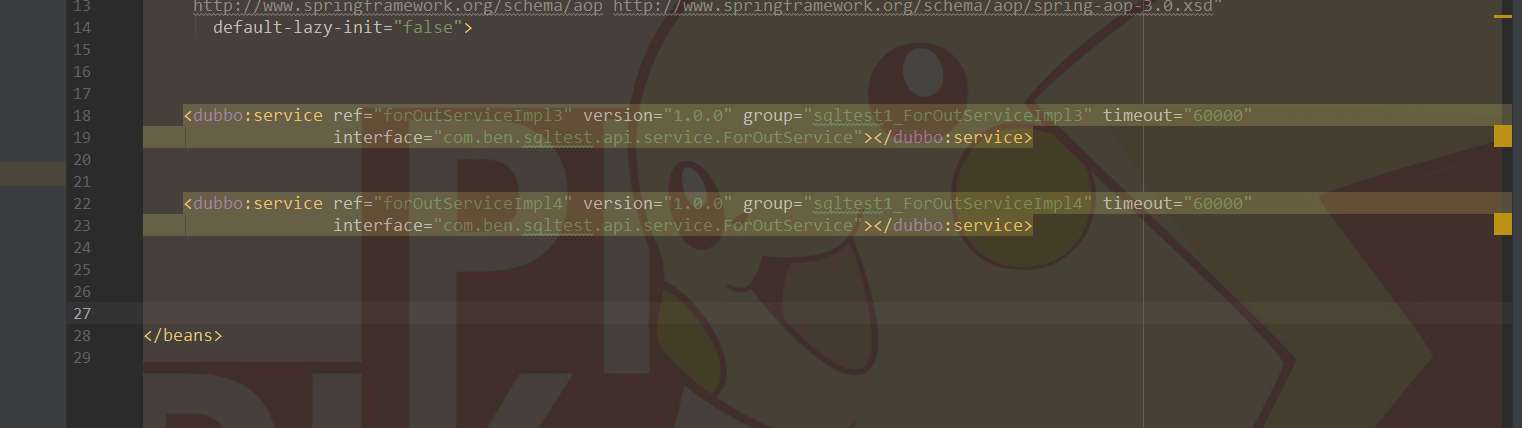
步骤一 : 部分提供者下线
下面两个提供者下线收到的事件 , 共四个 , 下线两个 , 共收到 4个事件 .
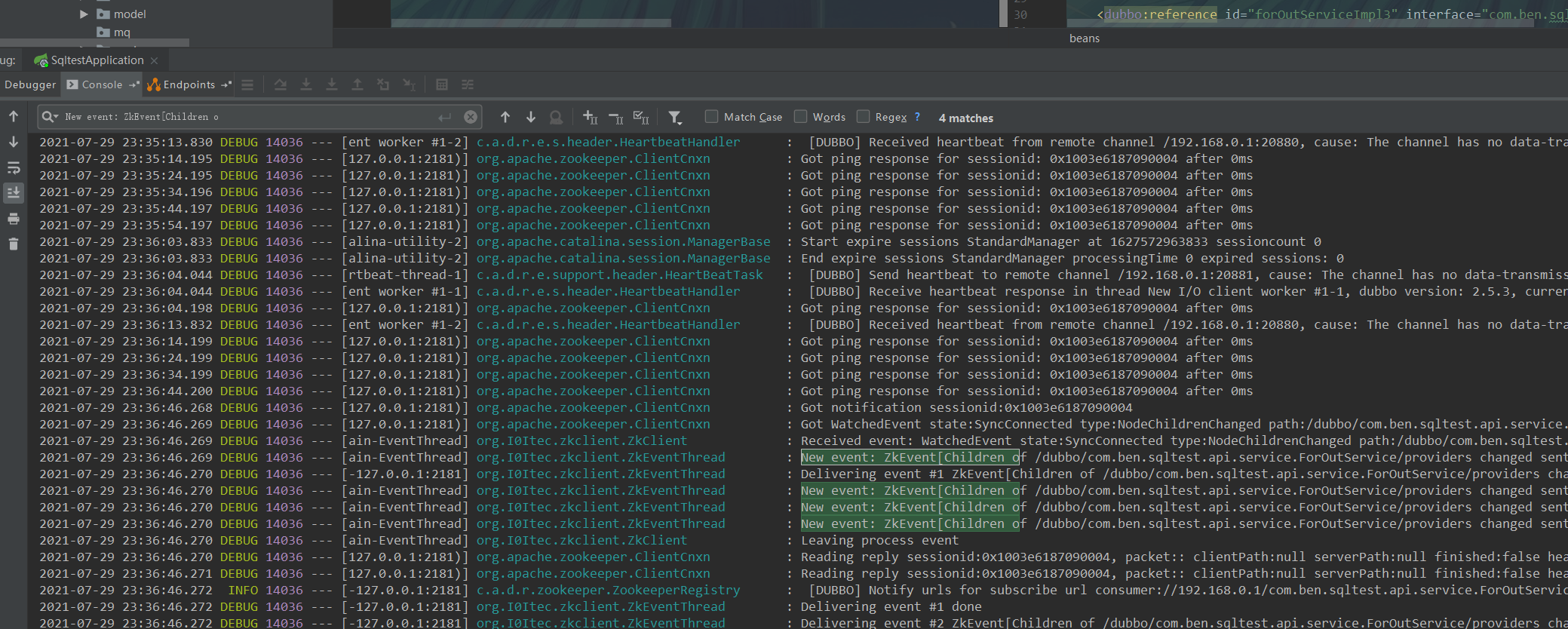
步骤二 : 部分提供者上线
刚才下线了两个提供者 , 剩下两个提供者 , 现在我们再重新上线 . 可以看到我们此时收到的是 12 - 4 = 8个事件.
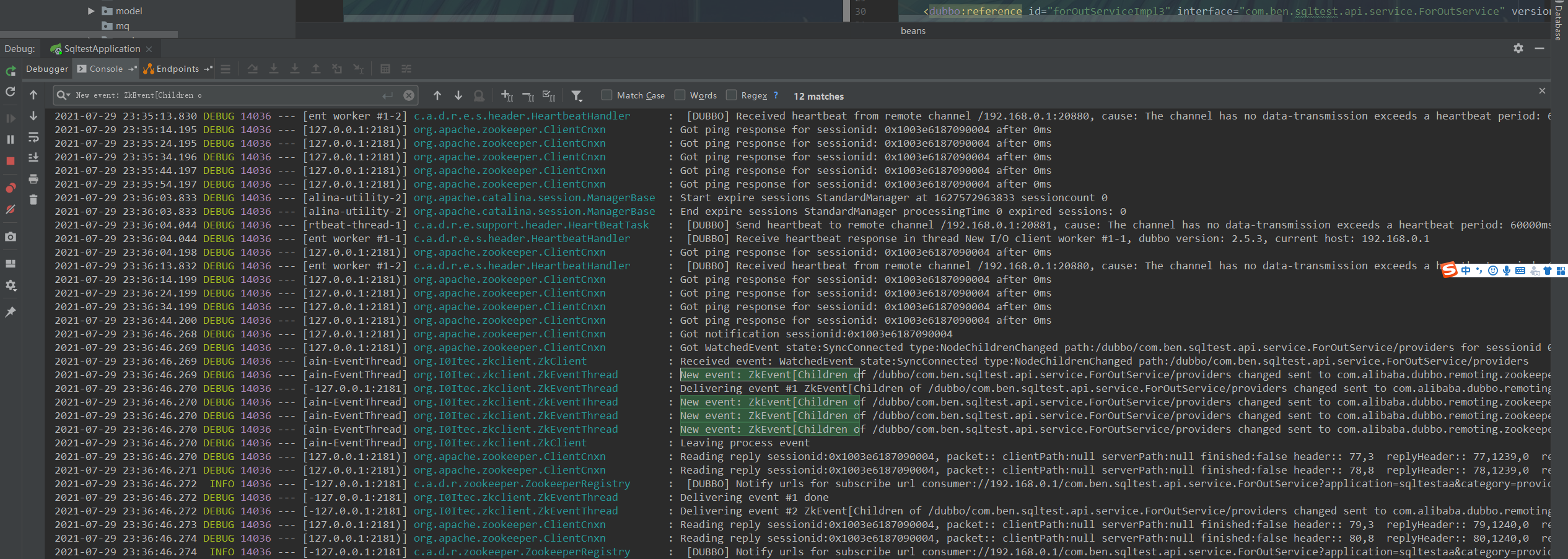
步骤三 : 再次下线
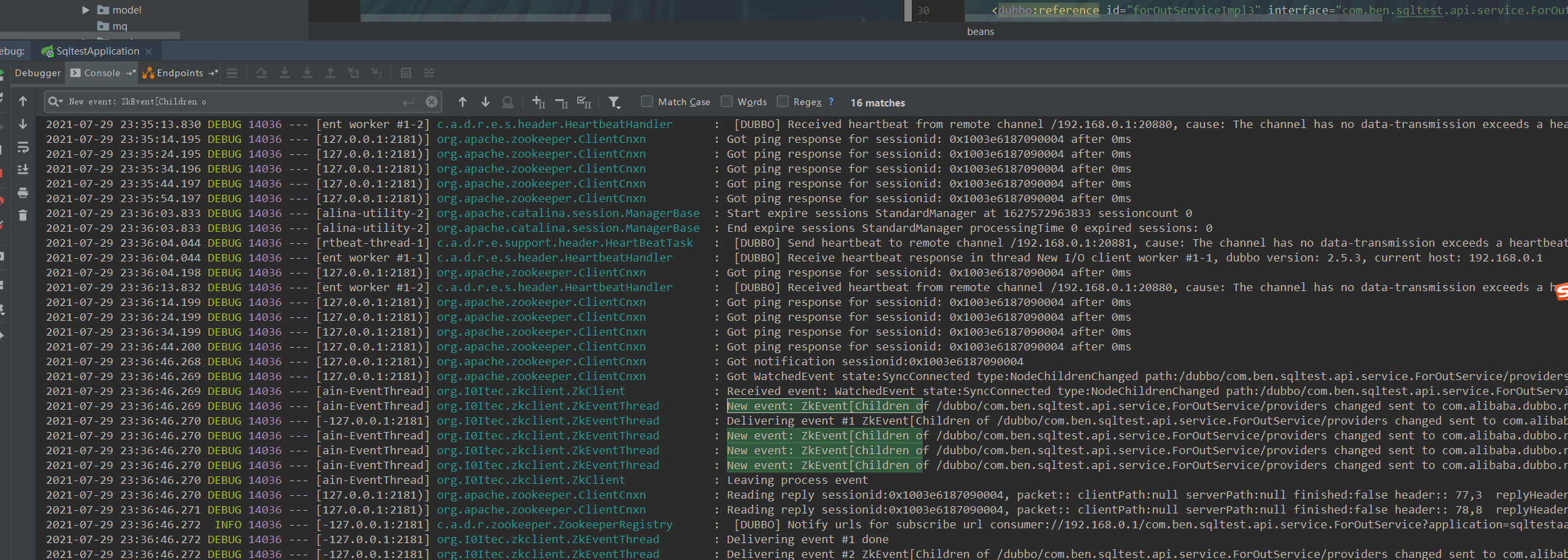
步骤四 : 再次上线
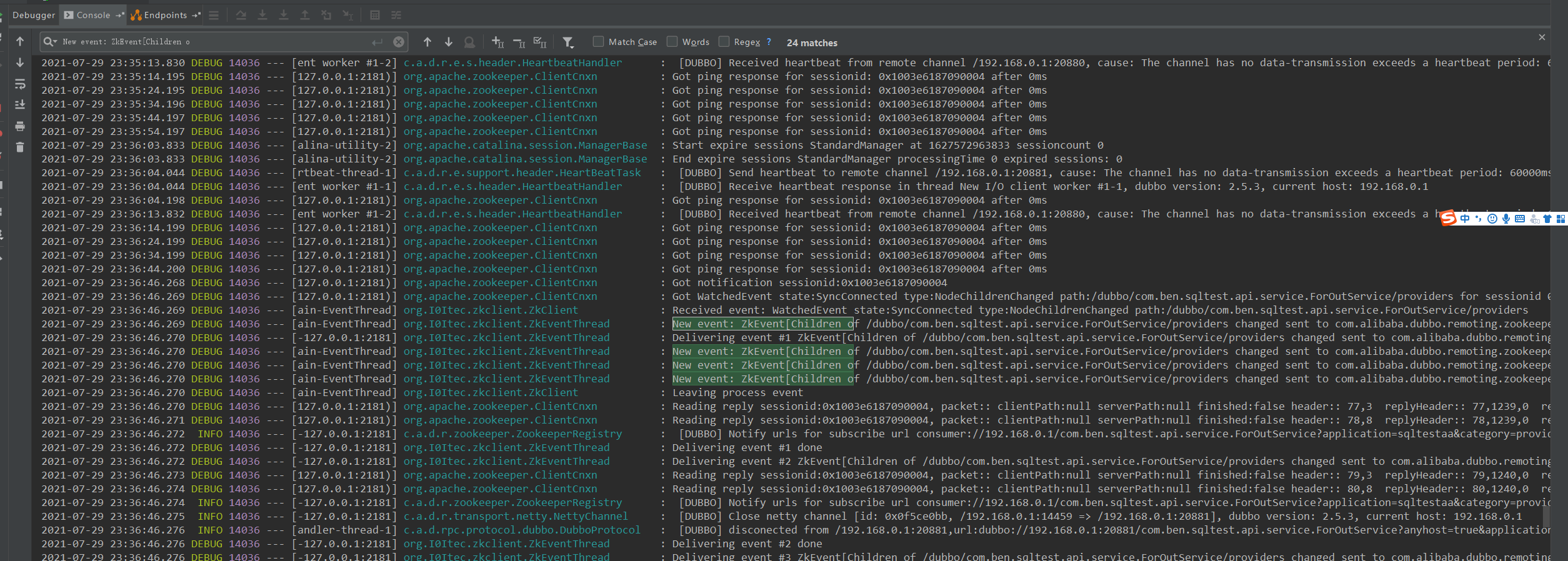
demo 总结
我们通过上面基本上确定了是 provider 上线会触发上线事件 ,并且是数量是 上线提供者数量 * 集体消费者数量 ,频繁上下线会触发事件的数量是可怕的, 而出现事件的线程刚好是单线程 , 并且消费者的应用只有一个 : admin , 于是大量的事件打满了出现事件的线程 , 全都堆积在阻塞队列中进行自旋阻塞 ,从而 CPU 上升 , 内存上升。
总结
通过这一次的分析, 熟悉了一下排查问题的流程, 并通过分析验证了自己的猜想.
参考资料
- https://www.orchome.com/435
- https://www.cnblogs.com/suixianlong/articles/3569433.html
- https://www.cnblogs.com/jiqing9006/p/9270504.html
- https://blog.csdn.net/fuyuwei2015/article/details/73256425 (Linux下如何定位Java进程CPU利用率过高原因)
- https://blog.csdn.net/vic_qxz/article/details/80416456 (Linux下如何定位Java进程CPU利用率过高原因)