前言
我们将从缓冲池开始介绍 ,然后后面开始介绍了 redo log 的底层到底是如何记录物理日志的.
redo log 的动机
redo log 是为了保持事务的持久性的
redo 的刷盘
和大多数关系型数据库一样,InnoDB记录了对数据文件的物理更改,并保证总是日志先行,也就是所谓的WAL,即在持久化数据文件前,保证之前的redo日志已经写到磁盘。
LSN(log sequence number) 用于记录日志序号,它是一个不断递增的 unsigned long long 类型整数。在 InnoDB 的日志系统中,LSN 无处不在,它既用于表示修改脏页时的日志序号,也用于记录checkpoint,通过LSN,可以具体的定位到其在redo log文件中的位置。
为了管理脏页,在 Buffer Pool 的每个instance上都维持了一个flush list,flush list 上的 page 按照修改这些 page 的LSN号进行排序。因此定期做redo checkpoint点时,选择的 LSN 总是所有 bp instance 的 flush list 上最老的那个page(拥有最小的LSN)。由于采用WAL的策略,每次事务提交时需要持久化 redo log 才能保证事务不丢。而延迟刷脏页则起到了合并多次修改的效果,避免频繁写数据文件造成的性能问题。
缓冲池
在介绍 redo log 之前我们将会先介绍缓冲池 ,方便后续知道 redo log 的动机 .
InnoDB存储引擎是基于磁盘存储的 ,并将其中的记录按照页的方式进行管理 ,这一点有点像超级系统的 page cache ,我们之前也发过这张图片 ,是一个 SQL 语句的执行过程 ,其中可以看到是否命中内存就是命中数据库的记录是否在 page 中 .
那么我们可以想一下 ,假如我们需要读取更改某个页, 就想操作系统一样 ,操作系统当发生缺页的时候 ,操作系统就需要等待数据加载到 page 之后才能进行操作 ,所以 MySQL 采用 WAL (Write Ahead Log) 的方式来加快写 ,先将SQL 操作写入到 redo log ,再修改 page , 也就是说redo log 和 page 里面的数据是最新的数据 ,而磁盘里的数据是最旧 ,那么什么时候把脏数据刷新到磁盘中去呢? MySQL 回刷的时间点称之为 : Checkpoint
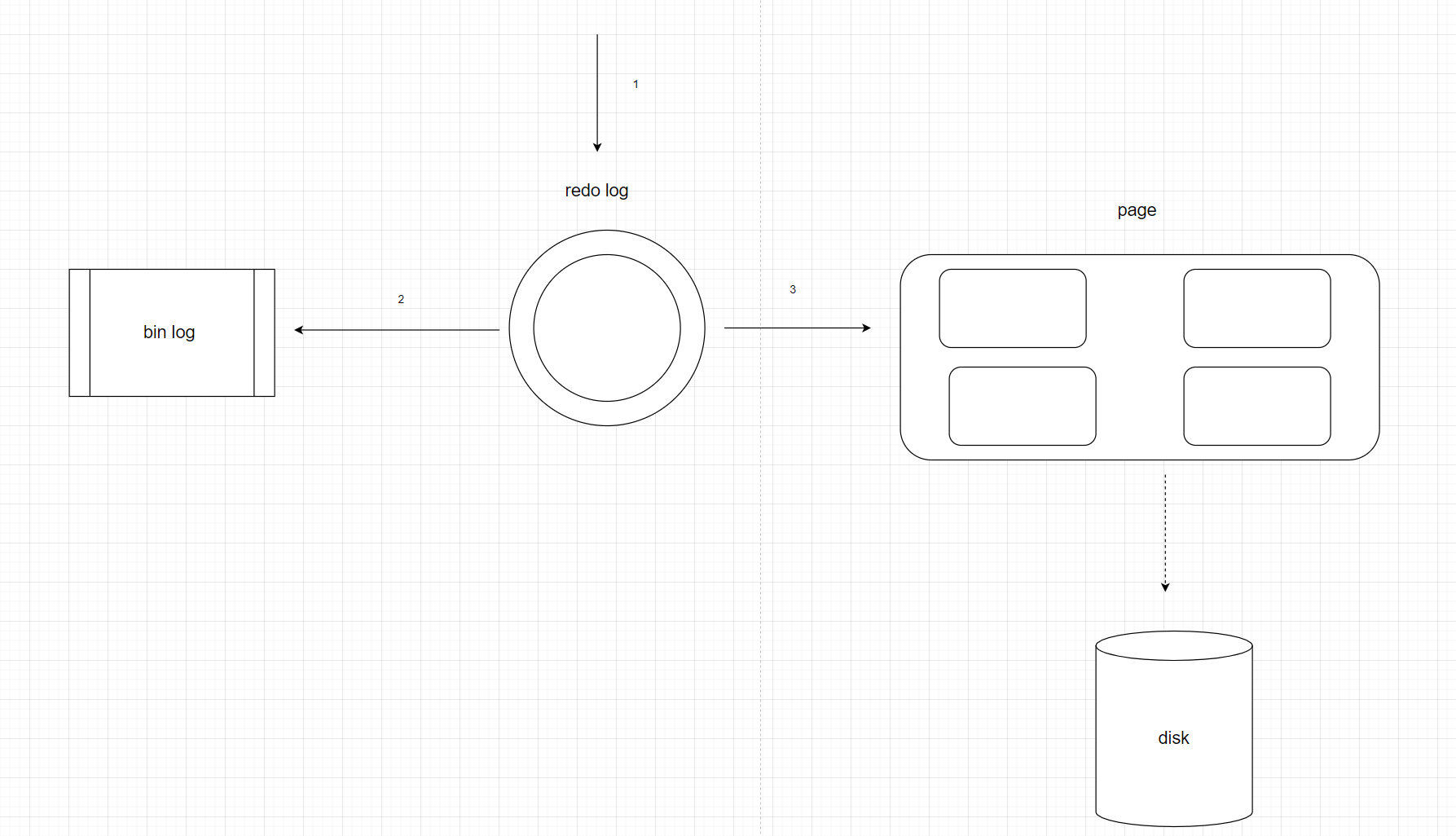
到了 checkpoint 就会将脏页回刷到磁盘 ,回刷的时机 :
(1) InnoDB 的 redo log 写满了,即是 write position 的位置追到了 checkpoint 的位置,这时候系统就会停止所有更新操作,把 checkpoint 往前推进,redo log 留出空间继续写。
(2) 系统内存不足,因为 MySQL 的数据都缓存在内存中,当系统的内存不足,那么就会有一部分数据会刷到磁盘中去
(3) MySQL 空闲的时候把数据进行刷盘
(4) 关闭数据库的时候,回刷数据回磁盘
而当要读入的数据页没有在内存的时候,就必须到缓冲池中申请一个数据页。这时候只能把最久不使用的数据页从内存中淘汰掉:
- 如果要淘汰的是一个干净页,就直接释放出来复用;
- 但如果是脏页呢,就必须将脏页先刷到磁盘,变成干净页后才能复用。
从上面我们可以看到redo log 的数据结构是一个环形的 ,这样 WAL 就变成了顺序写 ,提升了性能 .
redo 底层写了什么内容
下面图片和描述来自参考资料 ,非原创
redo 记录物理日志,记录的是“在某个数据页上做了什么修改”
例如下面的语句 :
update table set a = 1 where id = 1;
那么翻译成物理日志类似于这样 :
把第10表空间的第90号页面的偏移量为1024处的值更新为1
下面是大部分类型的redo log的通用结构:

- type:redo log的类型,目前redo log的类型很多
- Space ID:表空间ID
- page number:页号
- data:一条redo log的内容
展示一下源码的数据结构的样子
struct alignas(INNOBASE_CACHE_LINE_SIZE) log_t {
atomic_sn_t sn; // 目前log buffer申请的空间大小
aligned_array_pointer<byte, OS_FILE_LOG_BLOCK_SIZE> buf; // log buffer的内存区
Link_buf<lsn_t> recent_written; // 解决并发插入Redo Log Buffer后刷入ib_logfile存在空洞的问题
Link_buf<lsn_t> recent_closed; // 解决并发插入flush_list后确认checkpoint_lsn的问题
atomic_lsn_t write_lsn; // write_lsn之前的数据已经写入系统的Cache, 但不保证已经Flush
atomic_lsn_t flushed_to_disk_lsn; // 已经被flush到磁盘的数据
size_t buf_size; // log buffer缓冲区的大小
lsn_t available_for_checkpoint_lsn; // 在此lsn之前的所有被添加到buffer pool的flush list的log数据已经被flsuh, 下一次checkpoint可以make在这个lsn. 与last_checkpoint_lsn的区别是该lsn尚未被真正的checkpoint.
lsn_t requested_checkpoint_lsn; // 下次需要进行checkpoint的lsn
atomic_lsn_t last_checkpoint_lsn; // 目前最新的checkpoint的lsn
uint32_t write_ahead_buf_size; // write ahead的Buffer大小
lsn_t current_file_lsn; //
uint64_t current_file_real_offset; //
uint64_t current_file_end_offset; // 当前ib_logfile文件末尾的offset
uint64_t file_size; // 当前ib_logfile的文件大小
}
Redo log类型
先看一下 redo log 的基础类型
redo log类型主要是通过上面记录中的type体现的。比较基础的有以下几个(基础的类似于java里面的基本类型):
- MLOG_1BYTE:type字段对应的十进制为1,表示在页面的某个偏移量处写入一个字节
- MLOG_2BYTES:type字段对应的十进制为2,表示在页面的某个偏移量处写入两个字节
- MLOG_4BYTES:type字段对应的十进制为4,表示在页面的某个偏移量处写入四个字节
- MLOG_8BYTES:type字段对应的十进制为8,表示在页面的某个偏移量处写入八个字节
- MLOG_WRITE_STRING::type字段对应的十进制为30,表示在页面的某个偏移量处写入一串数据
现在举一个例子。我们大部分情况下用的自增主键id都是int型或者是long型的,int为四个字节,long为八个字节,现在如果插入一条数据的话,这条数据实际是修改在buffer pool中的,然后通过redo log记录下当前的修改情况。那么这个时候,插入一条id(int)为9的数据的redo log应该是这样子的。

插入数据后 , 含义: 在90表空间,编号为10页面,偏移量为1000处,写入四个字节,具体数据为0000 0000 0000 1001
其他类型的 redo log 这里不再深入 ,这里仅做抛砖引玉 ,方便大家理解 redo log 记录的内容是什么
其他
MySQL 的 master 线程执行事件
MySQL 的 master 线程执行事件如下 :
图例
问题
脏页 和 redo log 的关系 ?
当客户端第一次开始查询数据的时候,数据由于不存在 buffer pool ,那么数据会从磁盘加载数据到
buffer pool ,然后返回给客户端; 当客户端第二条语句是更改语句,那么MySQL 此时会
- 更新内存中的数据
- 写 redo log 日志
这样就形成了脏页,那么脏页和磁盘中的干净页是不一致的,脏页需要flush回磁盘才能达到持久化,flush 的过程必定会导致 - 脏页变成了干净页
- checkpoint 向前一步推进
redo log 和 bin log 的区别
-
redo log是InnoDB引擎特有的;binlog是MySQL的Server层实现的,所有引擎都可以使用。
-
redo log是物理日志,记录的是“在某个数据页上做了什么修改”;binlog是逻辑日志,记录的是这个语句的原始逻辑,比如“给ID=2这一行的c字段加1 ”。
-
redo log是循环写的,空间固定会用完;binlog是可以追加写入的。“追加写”是指binlog文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。
小结
使用 redo log 是利用WAL(先写日志)技术,数据库将随机写转换成了顺序写,大大提升了数据库的性能。同事也可以保证事务的持久性, 保证事务持久性并不单单只有redo log,其实还有mysql的重要机制——double write,见这一篇文章
参考资料
- 《MySQL技术内幕:InnoDB存储引擎》(checkpoint 章节)
- https://www.jianshu.com/p/fdae2e30b9fa ( Redo Log——第一篇 - 推荐一读)
- http://mysql.taobao.org/monthly/2015/05/01/ (关于 redo log 的源码分析 ,有兴趣的可以看看)