看到这个题目,可能有些人会觉得奇怪——Object不是JS的基本数据类型么,有什么实现不实现的呢?如果你这么想的话,说明你没有接触过其它语言,一直都是在和JS打交道,编程世界那么大,你没有出去看一看。C/C++/Java等语言是没有这种json的数据类型的,其它一些有的:如在Pthyon里面叫做字典,在Ruby/Perl里面叫散列表,当然这只是个名称而已,本质上可以当作json类型。而C是“万物之母”,C里面没有的,就得通过某种方式实现。
并且JS里面的Object是如何查找属性的,这个问题有人说是通过遍历key的字符串查找的,也有人说是通过哈希查找的。究竟它是怎么存储和查找的,能不能把Object当作一个map来使用?如果无法从源码的角度实际地看一下浏览器的实现,你的观点可能就站不住脚,只能人云亦云。
Chrome自行开发了V8引擎,并被Node拿去当解析器。本文将通过V8的源码尝试分析Object的实现。
1. V8的代码结构
v8的源码位于src/v8/src/,代码层级相对比较简单,但是实现比较复杂,为了能看懂,需要找到一个切入点,通过打断点、加log等方式确定这个切入点是对的,如果这个点并不是关键的点,进行到某一步的时候就断了,那么由这个点出发尝试去找其它的点。不断验证,最后找到一个最关键的地方,由这个地方由浅入深地扩展到其它地方,最后形成一个体系。
以下,先说明JS Object的类图。
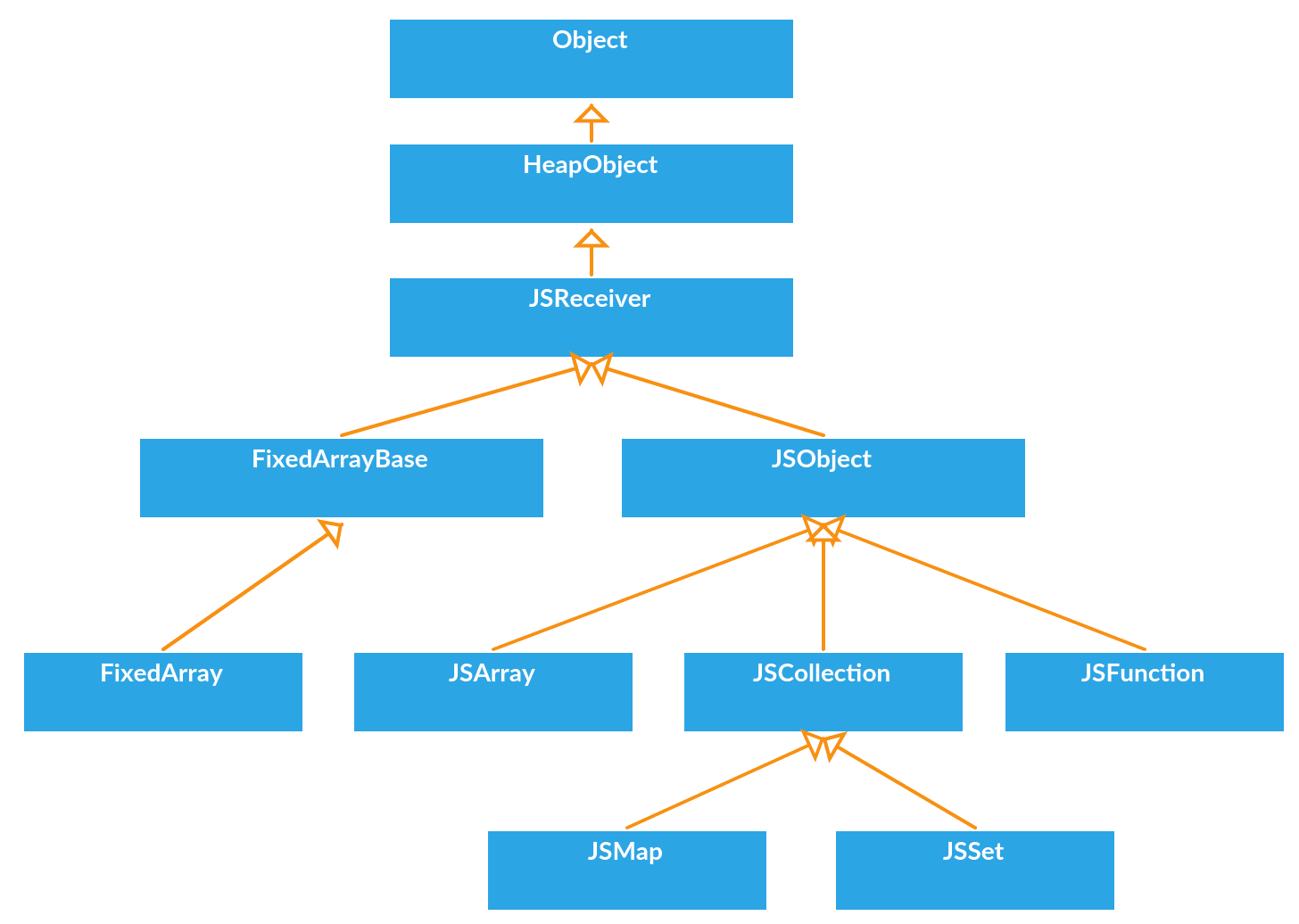
2. JS Object类图
V8里面所有的数据类型的根父类都是Object,Object派生HeapObject,提供存储基本功能,往下的JSReceiver用于原型查找,再往下的JSObject就是JS里面的Object,Array/Function/Date等继承于JSObject。左边的FixedArray是实际存储数据的地方。
3. 创建JSObject
在创建一个JSObject之前,会先把读到的Object的文本属性序列化成constant_properties,如下的data:
var data = {
name: "yin",
age: 18,
"-school-": "high school"
};
会被序列成:
../../v8/src/runtime/http://runtime-literals.cc 72 constant_properties:
0xdf9ed2aed19: [FixedArray]
– length: 6
[0]: 0x1b5ec69833d1 <String[4]: name>
[1]: 0xdf9ed2aec51 <String[3]: yin>
[2]: 0xdf9ed2aec71 <String[3]: age>
[3]: 18
[4]: 0xdf9ed2aec91 <String[8]: -school->
[5]: 0xdf9ed2aecb1 <String[11]: high school>
它是一个FixedArray,一共有6个元素,由于data总共是有3个属性,每个属性有一个key和一个value,所以Array就有6个。第一个元素是第一个key,第二个元素是第一个value,第三个元素是第二个key,第四个元素是第二个key,依次类推。Object提供了一个Print()的函数,把它用来打印对象的信息非常有帮助。上面的输出有两种类型的数据,一种是String类型,第二种是整型类型的。
FixedArray是V8实现的一个类似于数组的类,它表示一段连续的内存,上面的FixedArray的length = 6,那么它占的内存大小将是:
length * kPointerSize
因为它存的都是对象的指针(或者直接是整型数据类型,如上面的18),在64位的操作系统上,一个指针为8个字节,它的大小将是48个字节。它记录了一个初始的内存开始地址,使用元素index乘以指针大小作为偏移,加上开始地址,就可以取到相应index的元素,这和数组是一样的道理。只是V8自己封装了一个,方便添加一些自定义的函数。
FixedArray主要用于表示数据的存储位置,在它上面还有一个Map,这个Map用于表示数据的结构。这里的Map并不是哈希的意思,更接近于地图的意义,用来操作FixedArray表示的这段内存。V8根据constant_properties的length,去开辟相应大小空间的Map:
Handle<Map> map = ComputeObjectLiteralMap(context, constant_properties,
&is_result_from_cache);
把这个申请后的Map打印出来:
../../v8/src/heap/http://heap.cc 3472 map is
0x21528af9cb39: [Map]
– type: JS_OBJECT_TYPE
– instance size: 48
– inobject properties: 3
– back pointer: 0x3e2ca8902311 <undefined>
– instance descriptors (own) #0: 0x3e2ca8902231 <FixedArray[0]>
从第4行加粗字体可以看到,它的大小确实和我们算的一样。并且它还有一个叫做descriptors表示它的数据结构。descriptor记录了每个key-value对,以及它们在FixedArray里面的index. 后续对properties的操作基本上通过descriptor进行。
有了这个map的对象之后,用它来创建一个JSObect:
Handle<JSObject> boilerplate =
isolate->factory()->NewJSObjectFromMap(map, pretenure_flag);
重新开辟一段内存,把map的内容拷过去。
由于map只是一段相应大小的内存空间,它的内容是空的,所以接下来要设置它的properties:
for (int index = 0; index < length; index += 2) {
Handle<Object> key(constant_properties->get(index + 0));
Handle<Object> value(constant_properties->get(index + 1));
Handle<String> name = Handle<String>::cast(key);
JSObject::SetOwnPropertyIgnoreAttributes(boilerplate, name,
value, NONE);
}
通过上面的代码,把properties设置到map的FixedArray里面,并且可以通过index用descriptors迅速地取出key-value。由于这个过程比较复杂,细节不展开讨论。
在设置properties的同时,会初始化一个searchCache,这个cache支持哈希查找某个属性。
4. 字符串哈希查找
在设置cache的时候,会先进行查找是否已存在相同的属性名,如果已经有了就把它的value值覆盖掉,否则把它添加到cache里面:
int DescriptorArray::SearchWithCache(Isolate* isolate, Name* name, Map* map) {
DescriptorLookupCache* cache = isolate->descriptor_lookup_cache();
//找到它的index
int number = cache->Lookup(map, name);
//如果没有的话
if (number == DescriptorLookupCache::kAbsent) {
//通过遍历找到它的index
number = Search(name, number_of_own_descriptors);
//更新cache
cache->Update(map, name, number);
}
return number;
}
如上代码的注释,我们先来看一下这个Search函数是怎么进行的:
template <SearchMode search_mode, typename T>
int Search(T* array, Name* name, int valid_entries, int* out_insertion_index) {
// Fast case: do linear search for small arrays.
const int kMaxElementsForLinearSearch = 8;
if (valid_entries <= kMaxElementsForLinearSearch) {
return LinearSearch<search_mode>(array, name, valid_entries,
out_insertion_index);
}
// Slow case: perform binary search.
return BinarySearch<search_mode>(array, name, valid_entries,
out_insertion_index);
}
如果属性少于等于8个时,则直接线性查找即依次遍历,否则进行二分查找,在线性查找里面判断是否相等,是用的内存地址比较:
for (int number = 0; number < valid_entries; number++) {
if (array->GetKey(number) == name) return number;
}
因为name都是用的上面第三点设置Map的时候传进来的name,因此初始化的时候相同的name都指向同一个对象。所以可以直接用内存地址进行比较,得到FixedArray的索引number。然后用key和number去update cache:
cache->Update(map, name, number);
重点在于这个update cache。这个cache的数据结构是这样的:
static const int kLength = 64;
struct Key {
Map* source;
Name* name;
};
Key keys_[kLength];
int results_[kLength];
它有一个数组keys_的成员变量存放key,这个数组的大小是64,数组的索引用哈希算出来,不同的key有不同的哈希,这个哈希就是它在数组里面的索引。它还有一个results_,存放上面线性查找出来的number,这个number就是内存里面的偏移,有了这个偏移就可以很快地定位到它的内容,所以放到results里面.
关键在于这个哈希是怎么算的。来看一下update的函数:
void DescriptorLookupCache::Update(Map* source, Name* name, int result) {
int index = Hash(source, name);
Key& key = keys_[index];
key.source = source;
key.name = name;
results_[index] = result;
}
先计算哈希索引index,然后把数据存到results_和keys_这两个数组的index位置。这个Hash函数是这样的:
int DescriptorLookupCache::Hash(Object* source, Name* name) {
// Uses only lower 32 bits if pointers are larger.
uint32_t source_hash =
static_cast<uint32_t>(reinterpret_cast<uintptr_t>(source)) >>
kPointerSizeLog2;
uint32_t name_hash = name->hash_field();
return (source_hash ^ name_hash) % kLength;
}
先计算map和key的hash,map的hash即source_hash是用map的地址的低32位,为了统一不同指针大小的区别,而计算key的hash即name_hash,最核心的代码应该是以下几行:
uint32_t StringHasher::AddCharacterCore(uint32_t running_hash, uint16_t c) {
running_hash += c;
running_hash += (running_hash << 10);
running_hash ^= (running_hash >> 6);
return running_hash;
}
依次循环name的每个字符串做一些位运算,结果累计给running_hash.
source_hash是用map的内存地址,因为这个地址是唯一的,而name_hash是用的字符串的内容,只要字符串一样,那么它的hash值就一定一样,这样保证了同一个object,它的同个key值的索引值就一定一样。source_hash和name_hash最后异或一下,模以kLength = 64得到它在数组里面的索引。
这里自然而然会有一个问题,通过这样的计算不能够保证不同的name计算出来的哈希值一定不一样,好的哈希算法只能让结果尽可能随机,但是无法做到一定不重复,所以这里也有同样的问题。
先来看一下,它是怎么查找的:
int DescriptorLookupCache::Lookup(Map* source, Name* name) {
int index = Hash(source, name);
Key& key = keys_[index];
if ((key.source == source) && (key.name == name)) return results_[index];
return kAbsent;
}
先用同样的哈希算法,算出同样的index,取出key里面的map和name,和存储的map和name进行比较,如果相同则说明找到了,否则的话返回不存在-1的标志。一旦不存在了又会执行上面的update cache,先调Search找到它的偏移index作为result,如果index存在重新update cache。所以上面的问题就可以得到解答了,重复的哈希索引覆盖了第一个,导致查找第一个的时候没找找到,所以又去重新update,把那个索引值的数组元素又改成了第一个的。因此,如果两个重复的元素如果循环轮流访问的话,就会造成不断地查找index,不断地更新搜索cache。但是这种情况还是比较少的。
如何保证传进来的具有相同字符串的name和原始的name是同一个对象,从而才能使它们的内存地址一样?一个办法是维护一个Name的数据池,据有相同字符串的name只能存在一个。
上面的那个data它的三个name的index在笔者电脑上实验计算结果为:
#name hash index = 62
#age hash index = 32
#-school- hash index = 51
有一个比较奇怪的地方是重复实验,它们的哈希值都是一样的。并且具有相同属性且顺序也相同的object,它们的map地址就是一样的。
如果一个元素的属性值超过64个呢?那也是同样的处理,后面设置的会覆盖前面设置的。学过哈希的都知道,当元素的个数大于容器容量的一半时,重复的概率将会大大增加。所以一个object的属性的比较优的最大大小为32。一旦超过32,在一个:
for(var key in obj){
obj[key] //do sth.
}
for循环里面,这种查找的开销将会很大。但是考虑到属性个数并不多。
那为什么它要把长度设置成64呢,如果改大了,不就可以减少重复率?但是这样会造成更多的内存消耗,即使一个Object只有一个属性,它也会初始化一个这么大的数组,对于这种属性比较少的object来说就很浪费。所以取64,应该是一个比较适中的值。
同时另一方面,经常使用的那几个属性还是能够很快通过哈希计算定位到它的内容。并且这种场景还是很常见的,如获取数组元素的lengh.
这种cache查找只支持属性个数小于等于128的,如果属性个数大于128个,将不采用cache存储和查找的方式。而是直接使用一个hashtable
5. 字符串哈希表查找
如下的判断:
const int kMapCacheSize = 128;
// We do not cache maps for too many properties or when running builtin code.
if (number_of_properties > kMapCacheSize) {
*is_result_from_cache = false;
Handle<Map> map = Map::Create(isolate(), number_of_properties);
return map;
}
如果属性个数大于128时,将按照属性的个数消耗的空间创建和扩展map存储,不再创建cache。同时这个map就会被标记为dictionary_map,即哈希表。
往这个哈希表插入一个元素前,会先检查表的容量是否足够,不够进行扩容,在EnsureCapacity的函数里面:
int capacity = table->Capacity();
int nof = table->NumberOfElements() + n;
if (table->HasSufficientCapacityToAdd(n)) return table;
Handle<Derived> new_table = HashTable::New(
nof * 2,
USE_DEFAULT_MINIMUM_CAPACITY);
table->Rehash(new_table, key);
第二行获取到当前表元素个数加上需要插入的元素的个数得到新表的总元素个数;第7行再乘以2,得到新表的容量,最后再rehash,重新计算每个元素的哈希值,更新哈希表。
插入一个元素的关键是计算它的哈希,这里计算哈希的方式和上面的一样,都是调的name->hash_field函数,不一样的是它不再是覆盖存储,因为上面已经进行扩容了,可以保证空间一定足够。如果哈希值冲突了,那么将一直找到下一个存放它的地方,如下面的FindInsertionEntry函数:
template<typename Derived, typename Shape, typename Key>
uint32_t HashTable<Derived, Shape, Key>::FindInsertionEntry(uint32_t hash) {
uint32_t capacity = Capacity();
uint32_t entry = FirstProbe(hash, capacity);
uint32_t count = 1;
// EnsureCapacity will guarantee the hash table is never full.
Isolate* isolate = GetIsolate();
while (true) {
Object* element = KeyAt(entry);
if (!IsKey(isolate, element)) break;
entry = NextProbe(entry, count++, capacity);
}
return entry;
}
在上面代码第10行找到一个非key元素后,停止循环,返回这个位置。
在所有属性插入完成之后,查找的过程类似于上面的插入,如下面FindEntry的函数:
// Find entry for key otherwise return kNotFound.
template <typename Derived, typename Shape>
int NameDictionaryBase<Derived, Shape>::FindEntry(Handle<Name> key) {
// EnsureCapacity will guarantee the hash table is never full.
uint32_t capacity = this->Capacity();
uint32_t entry = Derived::FirstProbe(key->Hash(), capacity);
uint32_t count = 1;
while (true) {
Object* element = this->KeyAt(entry);
if (element->IsUndefined(isolate)) break; // Empty entry.
if (*key == element) return entry;
entry = Derived::NextProbe(entry, count++, capacity);
}
return Derived::kNotFound;
}
在while循环里,要么找到一个undefined的元素,返回无结果的标志,要么命中元素,返回FixedArray的索引index,然后通过这个数组index就可以很快地取出数据:
property_details_ = dictionary->DetailsAt(entry);
当哈希值冲突时,如何找到下一个插入位置,在哈希算法里面也是一个很重要的部分,因为需要定位到下一个空的元素,才能进行插入,如果定位到的下一个元素又是非空的,又得继续找下一个。源码里面是这样进行的:
inline static uint32_t FirstProbe(uint32_t hash, uint32_t size) {
return hash & (size - 1);
}
inline static uint32_t NextProbe(
uint32_t last, uint32_t number, uint32_t size) {
return (last + number) & (size - 1);
}
所以当属性个数不超过128个时,是用searchCache,大于128时,采用哈希表。源码里面查找的判断是这样的:
if (!map->is_dictionary_map()) {
DescriptorArray* descriptors = map->instance_descriptors();
int number = descriptors->SearchWithCache(isolate_, *name_, map);
//...
} else {
NameDictionary* dict = holder->property_dictionary();
int number = dict->FindEntry(name_);
//...
}
如果是一个字典,则执行else里面的逻辑,否则执行if里面的逻辑按searchCache查找。
这里自然而然会有一个问题,为什么在不大于128个属性的时候要专门搞一个searchCache呢,是因为searchCache比哈希表快么,快在哪里?我想这两者的区别在于searchCache不会冲突,每次都是直接定位,而hashTable如果冲突了需要不断地找下一个元素,增加了比较次数。当属性比较少,并且有几个属性经常被用到的时候,searchCache应该会有明显的优势。
上面已经介绍了两种字符串的查找方式,当属性是数字的时候有另外两种查找方式。
6. 数字索引哈希查找
假设data变成:
var data = {
name: "yin",
age: 18,
"-school-": "high school",
1: "Monday",
2: "Thuesday",
"3": "Wednesday"
};
把生成的data Object打印出来是这样的:
../../v8/src/runtime/http://runtime-literals.cc 105 boilerplate obj:
0x3930221af3a9: [JS_OBJECT_TYPE]
- map = 0x6712e19cc41 [FastProperties]
- prototype = 0x27d71d20f19
- elements = 0x2e1e1a56b579 <FixedArray[19]> [FAST_HOLEY_ELEMENTS]
- properties = 0x2c2a4d782241 <FixedArray[0]> {
#name: 0x3930221aec51 <String[3]: yin> (data field at offset 0)
#age: 18 (data field at offset 1)
#-school-: 0x3930221aecb1 <String[11]: high school> (data field at offset 2)
}
- elements = {
0: 0x2c2a4d782351 <the hole>
1: 0x3930221aecf9 <String[6]: Monday>
2: 0x3930221aed39 <String[8]: Thuesday>
3: 0x3930221aed79 <String[9]: Wednesday>
4-18: 0x2c2a4d782351 <the hole>
}
那些key为数字的存放在elements的数据结构里面。上面的elements它是一个有序数组,它的key值直接作为它的index。如果data改成:
var data = {
1: "Monday",
2: "Thuesday",
3: "Wednesday",
7: "Sunday"
}
那么elements是这样的:
- elements = {
0: 0x1e74f5702351 <the hole>
1: 0x1745ec52ec71 <String[6]: Monday>
2: 0x1745ec52ecb1 <String[8]: Thuesday>
3: 0x1745ec52ecf1 <String[9]: Wednesday>
4-6: 0x1e74f5702351 <the hole>
7: 0x1745ec52ed39 <String[6]: Sunday>
8-18: 0x1e74f5702351 <the hole>
}
初始化大小仍然是19个元素,空的索引用hole元素填充。这种就跟数组一样,可直接根据索引定位到元素,代价是空间的消耗比较大,可以来看一下,当空间不足时,它是怎么扩容的:
if (index < capacity) {
*new_capacity = capacity;
return false;
}
*new_capacity = JSObject::NewElementsCapacity(index + 1);
由于第一个属性是1: Monday,所以上面的index = 1,执行最后一行计算新容量的元素:
// Computes the new capacity when expanding the elements of a JSObject.
static uint32_t NewElementsCapacity(uint32_t old_capacity) {
// (old_capacity + 50%) + 16
return old_capacity + (old_capacity >> 1) + 16;
}
可以看到,这是用老的空间的一半加上16,上面的计算结果为19,如果本来是2M大小,刚好不够再增加一个元素就成了3M,一个多余的元素就增加了1M的空间。它的好处是不用频繁地开避内存。
这种用数组表示的属性在源码里面叫FastElements,而用哈希表的叫做SlowElements。什么时候会变成slowElements?当hole太多的时候,例如给data增加一个key为2000的属性:
data['2000'] = 'day';
data就会转成慢元素,因为3之后就是2000,hole太多就被转换了,如下面的ShouldConvertToSlowElements函数:
static bool ShouldConvertToSlowElements(JSObject* object, uint32_t capacity,
uint32_t index,
uint32_t* new_capacity) {
if (index < capacity) {
return false;
}
//JSObject::kMaxGap = 1024
if (index - capacity >= JSObject::kMaxGap) return true;
*new_capacity = JSObject::NewElementsCapacity(index + 1);
// If the fast-case backing storage takes up roughly three times as
// much space (in machine words) as a dictionary backing storage
// would, the object should have slow elements.
int used_elements = object->GetFastElementsUsage();
int dictionary_size = SeededNumberDictionary::ComputeCapacity(used_elements) *
SeededNumberDictionary::kEntrySize;
return 3 * static_cast<uint32_t>(dictionary_size) <= *new_capacity;
}
如果当前的index比容量capacity大了1024,就转成慢元素,或者是如上面的代码注释,如果快元素占的空间为慢元素的3倍之多时,也会被转成慢元素。
转成慢元素之后,它就和字符串的哈希表一样了,不一样的是,它计算哈希的方式不一样,字符串的需要一个个字符串循环计算计算hash,而数字的key,不需要循环,如下计算(第二个参数是随机化种子seed):
inline uint32_t ComputeIntegerHash(uint32_t key, uint32_t seed) {
uint32_t hash = key;
hash = hash ^ seed;
hash = ~hash + (hash << 15); // hash = (hash << 15) - hash - 1;
hash = hash ^ (hash >> 12);
hash = hash + (hash << 2);
hash = hash ^ (hash >> 4);
hash = hash * 2057; // hash = (hash + (hash << 3)) + (hash << 11);
hash = hash ^ (hash >> 16);
return hash & 0x3fffffff;
}
然后再来简单看一下ES6的Map的实现
7. ES6 Map的实现
这里有一个比较有趣的事情,就是V8的Map的核心逻辑是用JS实现的,具体文件是在v8/src/js/collection.js,用JS来实现JS,比写C++要高效多了,但是执行效率可能就没有直接写C++的高,可以来看一下set函数的实现:
function MapSet(key, value) {
//添加一个log
%LOG("MapSet", key);
var table = %_JSCollectionGetTable(this);
var numBuckets = ORDERED_HASH_TABLE_BUCKET_COUNT(table);
var hash = GetHash(key);
var entry = MapFindEntry(table, numBuckets, key, hash);
if (entry !== NOT_FOUND) return ...//return代码省略
//如果个数大于capacity的二分之一,则执行%MapGrow(this)代码略
FIXED_ARRAY_SET(table, index, key);
FIXED_ARRAY_SET(table, index + 1, value);
}
第三行添加一个log函数,确认确实是执行这里的代码。%开头的LOG,表示它是一个C++的函数,这个代码写在runtime.h和http://runtime.cc里面。这些JS代码最后会被组装成native code。在V8里,除了Map/Set之外,很多ES6新加的功能,都是用的JS实现的,如数组新加的很多函数。
8. Object和ES 6 Map的速度比较
Object和ES 6的map主要都是用的哈希,那么它们运行效率比较起来怎么样呢?
如以下代码,初始化一个map和一个object:
var map = new Map(),
obj = {};
var size = 100000;
for(var i = 0; i < size; i++){
map.set('key' + i , i);
obj['key' + i] = i;
}
再准备一个keys数组,用来存储查找的key,如下,分成三种情况分别测验:1. keys都能查到;2. 只有一半的keys能找到;3. 全部的keys都查找不到:
var keys = [];
for(var i = 0; i < 100; i++){
//1. keys都找得到
keys.push('key' + parseInt(Math.random() * size));
//2. 约一半的keys找不到
//keys.push('key' + parseInt(Math.random() * size * 2));
//3. 全部的keys都找不到
//keys.push('key' + parseInt(Math.random() * size) + size);
}
然后进行查找,重复多次,并打印时间:
var count = 100000;
console.time("map time");
for(var i = 0; i < count; i++){
for(var j = 0; j < keys.length; j++){
let x = map.get(keys[j]);
}
}
console.timeEnd("map time");
console.time("obj time");
for(var i = 0; i < count; i++){
for(var j = 0; j < keys.length; j++){
let x = obj[keys[j]];
}
}
console.timeEnd("obj time");
最后的结果如下:

可以看到,当查找的keys找不到时,object更加地消耗时间(在实际的使用中,一半找得到一半找不到的情况应该会比较多一点)。这很可能是因为object里面每个key需要实例化一个全局唯一的name,如果name已经存在了,那么它已经实例化好了,包括它的哈希值计算已经缓存起来了,如果未知的name越多,那么需要实例化的name也就越多,而map不存在这种情况,每次都是重新计算哈希。另一方面还可能和它们的哈希算法有关。
综上,Object存储和查找一个属性时,可通过以下方式: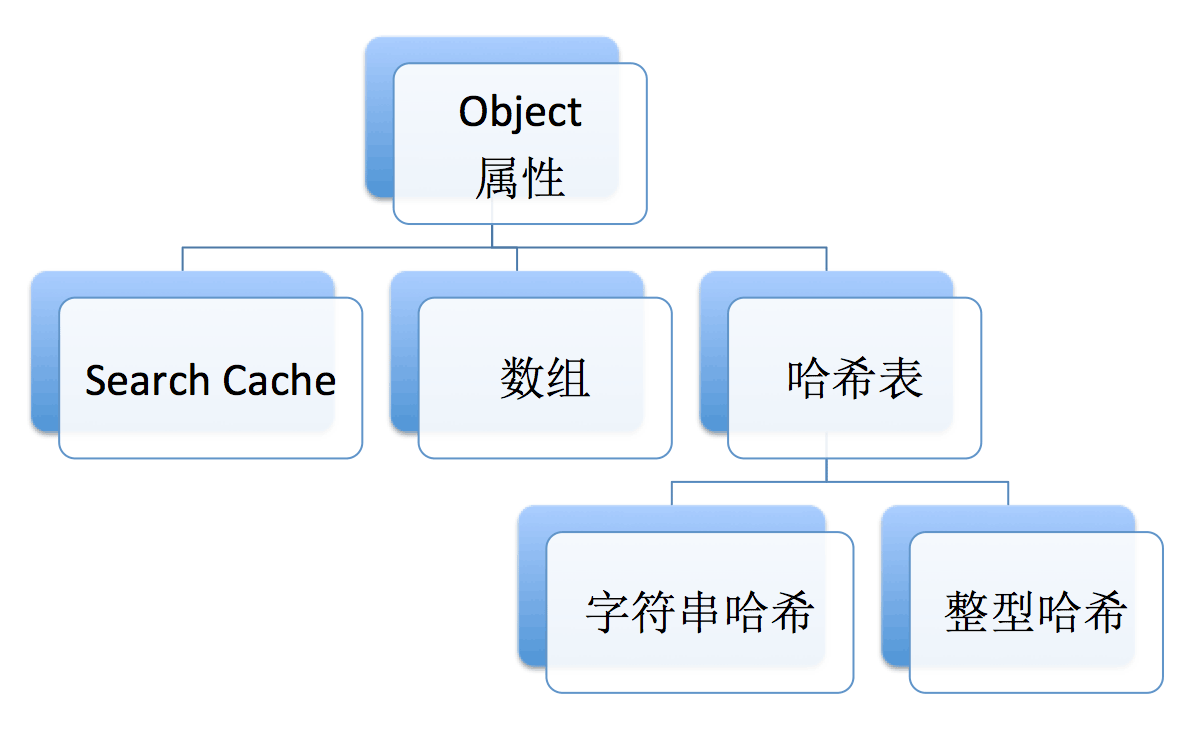
属性不超过128个,使用Search Cache,当属性是较为连续的数字时,使用数组,此种方式最快。其它情况使用哈希表,并且数字和字符串的哈希不一样。
可以把Object当成哈希map使用,但是在效率上可能会比不上ES6的Map,并且还有Object原型查找的问题。