AI Studio社区
AI Studio是一个基于paddlepaddle的集成了大量数据集、经典样例项目及比赛项目的云计算建模平台,也是一个机器学习、深度学习的交流社区。AI Studio最大限度地解放了数据科学家需要环境配置的烦恼,在云端集成计算资源、项目管理、代码管理、比赛等多种功能,形成一站式兼顾学习和工作的建模平台。而且AI Studio提供计算资源、空间资源、视频公开课全部免费开放。
AI Studio强化了工程项目的概念,一大亮点就是AI学习项目版块,包括大量真实场景的工程项目(图像识别、情感分析、个性化推荐等)。

AI Studio主要功能项目包括项目、数据集、课程、比赛、认证等五大部分。

- 项目:此部分集成百度积累的的经典的AI学习项目、自我项目管理及共享项目列表。在此,我fork了一个关于人脸识别的项目,截图如下
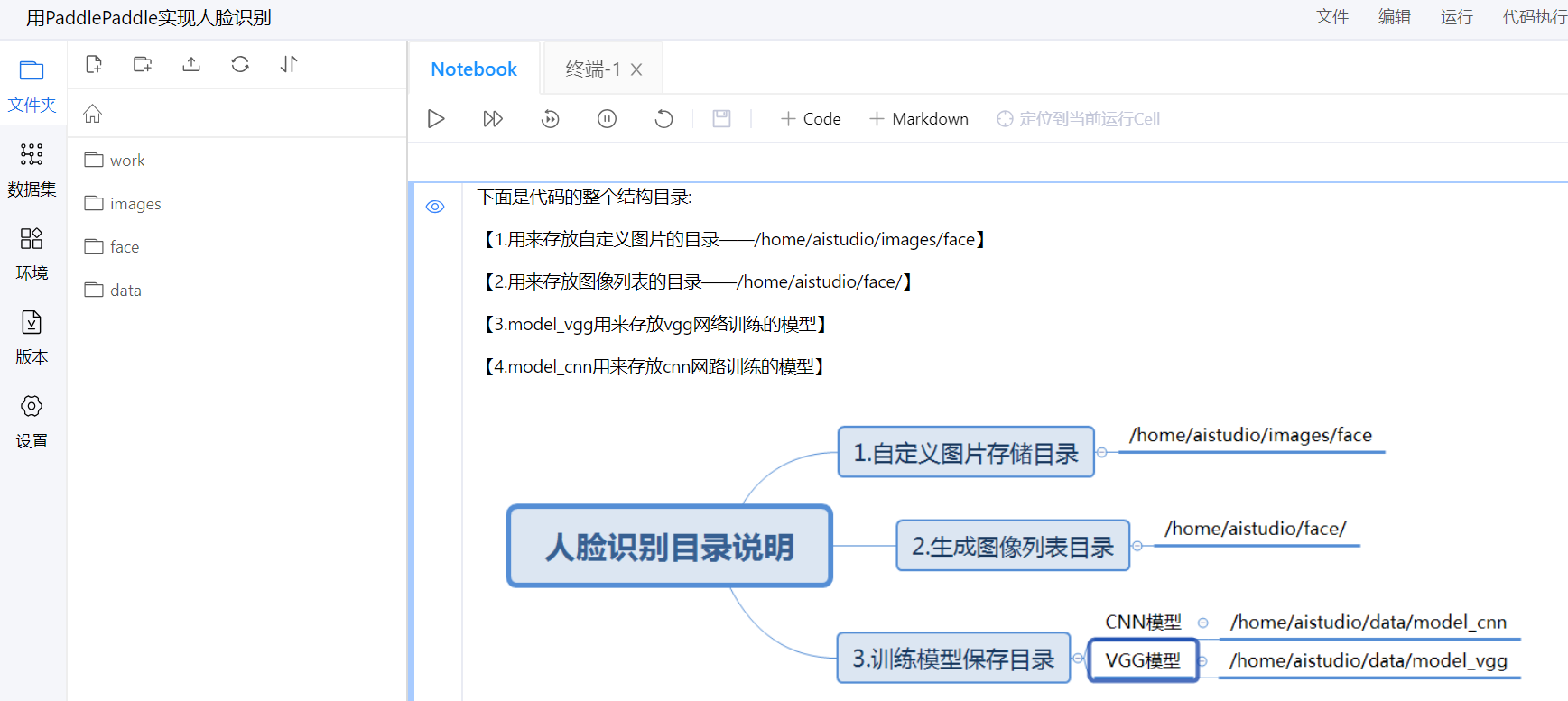
-
数据集:包括MNIST、IMDB、CIFAR10、PennTreebank、MovieLens等一些经典的公开的数据集;也包括一些开放的百度数据(中文短文本预料、信息抽取数据);同时,用户也可以上传自定义数据进行模型开发。
-
课程:此部分包括大量免费的视频公开课,为用户提供了在线实训的课程环境,利用实践项目、视频、文档打造沉浸式学习体验。
-
比赛:AI Studio提供云端训练平台,为参与者提供相对平衡的武器库,能够更公平的进行竞赛。
-
认证:AI Studio为用户提供了深度学习工程师的各级认证考试平台,并配有相关学习课程以供参与者学习考究。
Python基础语法
fork一个Python基础语法项目

Python基础语法总结:
1、标识符
- 在 Python 里,标识符有字母、数字、下划线组成。
- 在 Python 中,所有标识符可以包括英文、数字以及下划线(_),但不能以数字开头。
- Python 中的标识符是区分大小写的。
- 以下划线开头的标识符是有特殊意义的。以单下划线开头 _foo 的代表不能直接访问的类属性,需通过类提供的接口进行访问,不能用 from xxx import * 而导入;
- 以双下划线开头的 foo 代表类的私有成员;以双下划线开头和结尾的 foo 代表 Python 里特殊方法专用的标识,如 init__() 代表类的构造函数。
2、五个标准数据类型
Numbers(数字)、String(字符串)、List(列表)、Tuple(元组)、Dictionary(字典)
- Python支持四种不同的数字类型:
int(有符号整型)、long(长整型[也可以代表八进制和十六进制])、float(浮点型)、complex(复数) - python的字串列表有2种取值顺序:
从左到右索引默认0开始的,最大范围是字符串长度少1、从右到左索引默认-1开始的,最大范围是字符串开头 - List(列表) 是 Python 中使用最频繁的数据类型。列表可以完成大多数集合类的数据结构实现。它支持字符,数字,字符串甚至可以包含列表(即嵌套)。列表用 [ ] 标识,是 python 最通用的复合数据类型。列表中值的切割也可以用到变量 [头下标:尾下标] ,就可以截取相应的列表,从左到右索引默认 0 开始,从右到左索引默认 -1 开始,下标可以为空表示取到头或尾。加号 + 是列表连接运算符,星号 * 是重复操作。
- 元组是另一个数据类型,类似于List(列表)。元组用”()”标识。内部元素用逗号隔开。但是元组不能二次赋值,相当于只读列表。
- 字典(dictionary)是除列表以外python之中最灵活的内置数据结构类型。
- 列表是有序的对象结合,字典是无序的对象集合。两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
字典用”{ }”标识。字典由索引(key)和它对应的值value组成。
3、数据类型转换
有时候,我们需要对数据内置的类型进行转换,数据类型的转换,你只需要将数据类型作为函数名即可。
以下几个内置的函数可以执行数据类型之间的转换。这些函数返回一个新的对象,表示转换的值。
- int(x [,base]) 将x转换为一个整数
- long(x [,base] ) 将x转换为一个长整数
- float(x) 将x转换到一个浮点数
- complex(real [,imag]) 创建一个复数
- str(x) 将对象 x 转换为字符串
- repr(x) 将对象 x 转换为表达式字符串
- eval(str) 用来计算在字符串中的有效Python表达式,并返回一个对象
- tuple(s) 将序列 s 转换为一个元组
- list(s) 将序列 s 转换为一个列表
- set(s) 转换为可变集合
- dict(d) 创建一个字典。d 必须是一个序列 (key,value)元组。
- frozenset(s) 转换为不可变集合
- chr(x) 将一个整数转换为一个字符
- unichr(x) 将一个整数转换为Unicode字符
- ord(x) 将一个字符转换为它的整数值
- hex(x) 将一个整数转换为一个十六进制字符串
- oct(x) 将一个整数转换为一个八进制字符串
jupyter notebook
简介
jupyter notebook是一种 Web 应用,能让用户将说明文本、数学方程、代码和可视化内容全部组合到一个易于共享的文档中。它可以直接在代码旁写出叙述性文档,而不是另外编写单独的文档。也就是它可以能将代码、文档等这一切集中到一处,让用户一目了然。
功能
- 极其适合数据分析:它可以将使用者在终端运行的程序、可视化分析的结果显示、包含函数和类的脚本以及说明程序的执行及结果的文档等内容收归到一处,使使用者的思路更加清晰,方便用户进行数据分析等的相关使用。
- 支持多种语言:它支持以网络的形式分享,支持Notebook展示,也可以通过nbviewer分享文档,同时还可以导出成HTML、Markdown、PDF等多种格式的文档。
- 远程运行:在任何地点都可以通过网络链接远程服务器来实现运算。
- 交互式展现:不仅可以输出图片、视频、数学公式,甚至可以呈现一些互动的可视化内容,比如可以缩放的地图或者是可以旋转的三维模型。这就需要交互式插件(Interactive widgets)来支持。
Linux基础命令
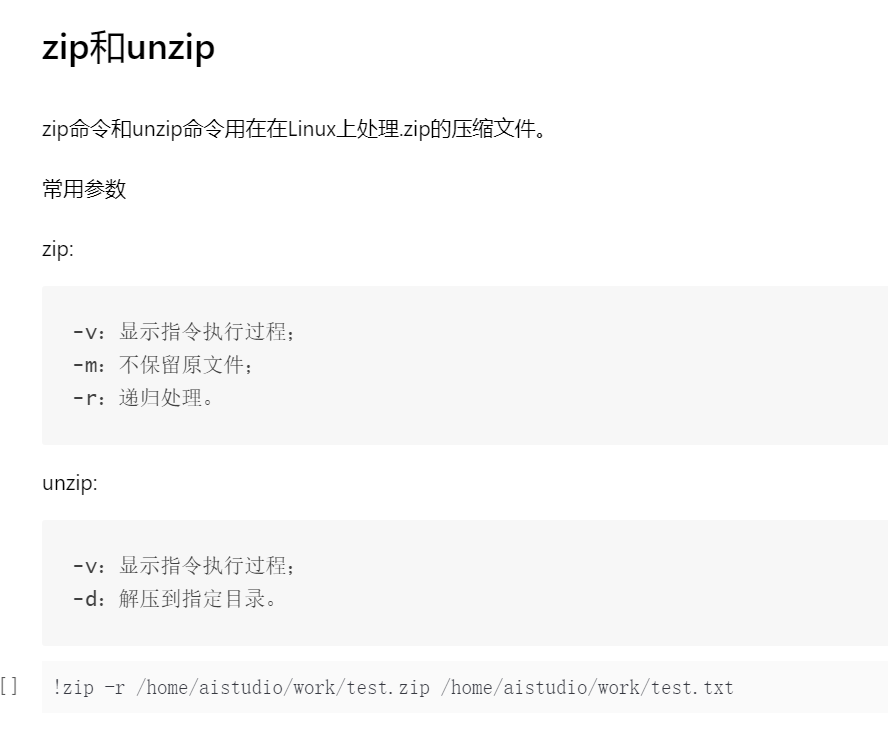
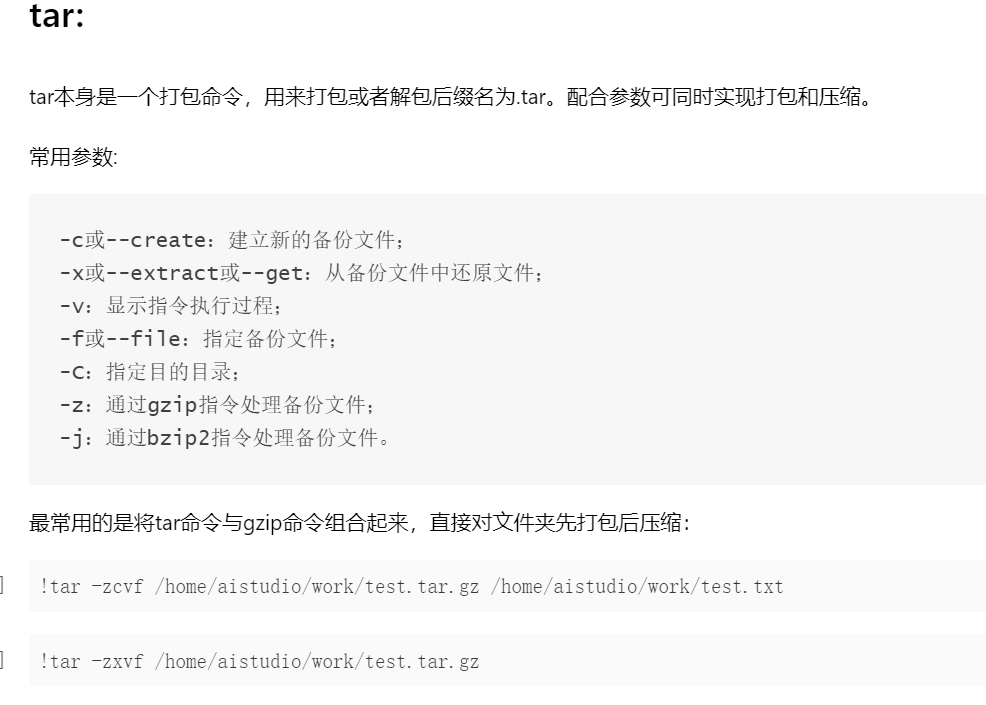
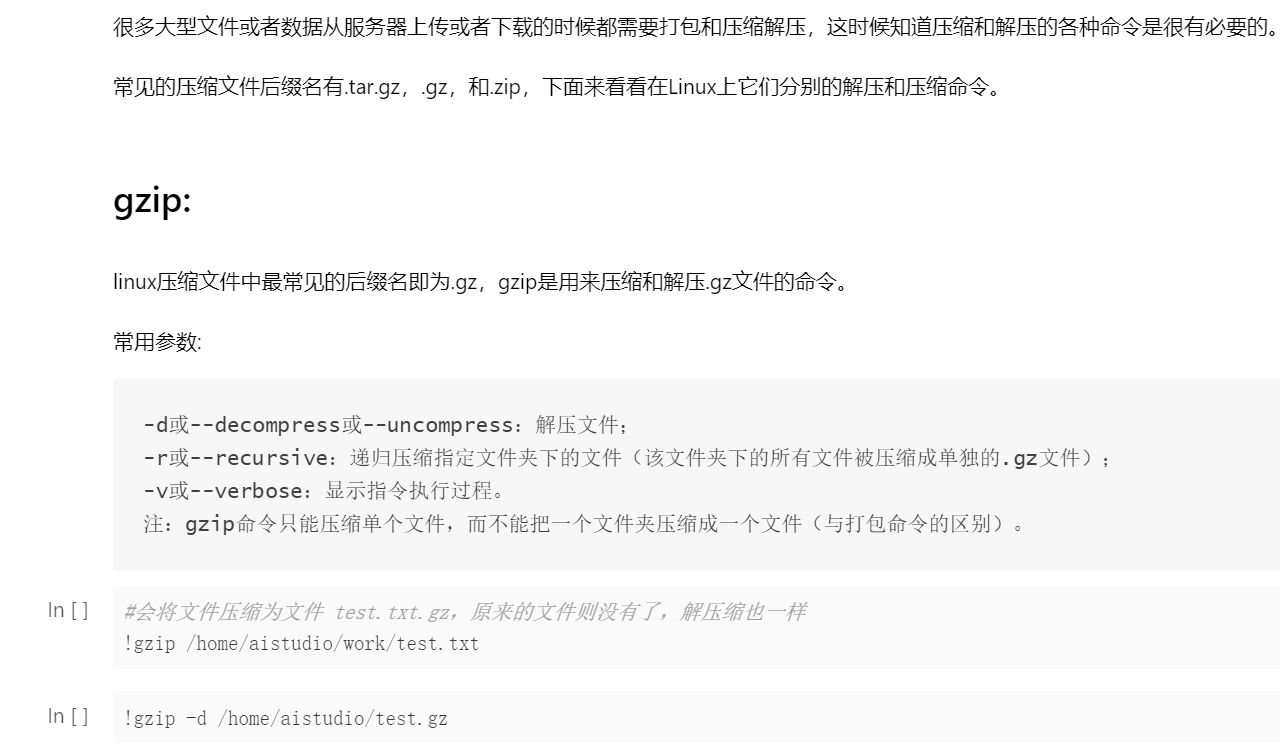
fork的项目
PaddleHub一键OCR(Optical Character Recognition,光学字符识别)中文识别
光学字符识别(Optical Character Recognition, OCR)是指对文本材料的图像文件进行分析识别处理,以获取文字和版本信息的过程。也就是说将图象中的文字进行识别,并返回文本形式的内容。PaddleHub现已开源OCR文字识别的预训练模型,该 Module 用于识别图片当中的汉字、数字、字母。如果仅需要检测,也可单独使用chinese_text_detection_db_server或者chinese_text_detection_db_mobile得到检测结果的文本框。开发者可以基于PaddleHub提供的OCR中文识别Module,实现一键文字识别,适用于常见的OCR应用场景中。
该项目的进行经历了以下过程:首先,在进行一个项目之前,我们需要了解该项目可创建的原因,即原理所在,要了解项目可能运用到的知识及技术;其次,我们需要有一定的数据支持我们项目的运行及模型的选择需要有一定的考虑,即需要定义待预测数据及加载预训练模型,这里的模型我们可以在PaddleHub中寻找可使用的已有模型作为项目的模型进行训练;接下来,我们需要调用module的相应预测API,完成预测功能;最后,进行效果展示并进行服务器的部署。