IE浏览器真是个坑:从ie6以及以前IE版本,简直就是垃圾,不按照Mozilla国际组织的标准来,乱搞。搞得兼容性很差:
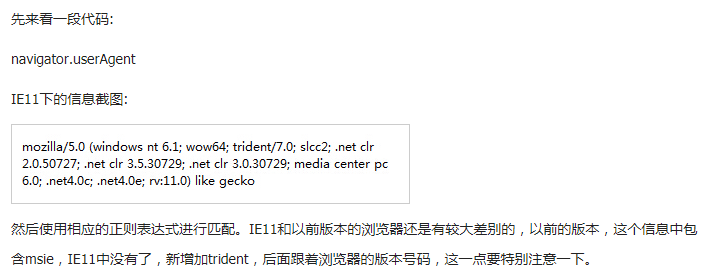
<script type="text/javascript">var userAgent = navigator.userAgent, rMsie = /(msies|trident.*rv:)([w.]+)/, rFirefox = /(firefox)/([w.]+)/, rOpera = /(opera).+version/([w.]+)/, rChrome = /(chrome)/([w.]+)/, rSafari = /version/([w.]+).*(safari)/; var browser; var version; var ua = userAgent.toLowerCase(); function uaMatch(ua){ var match = rMsie.exec(ua); if(match != null){ return { browser : "IE", version : match[2] || "0" }; } var match = rFirefox.exec(ua); if (match != null) { return { browser : match[1] || "", version : match[2] || "0" }; } var match = rOpera.exec(ua); if (match != null) { return { browser : match[1] || "", version : match[2] || "0" }; } var match = rChrome.exec(ua); if (match != null) { return { browser : match[1] || "", version : match[2] || "0" }; } var match = rSafari.exec(ua); if (match != null) { return { browser : match[2] || "", version : match[1] || "0" }; } if (match != null) { return { browser : "", version : "0" }; } } var browserMatch = uaMatch(userAgent.toLowerCase()); if (browserMatch.browser){ browser = browserMatch.browser; version = browserMatch.version; } document.write(browser+version); </script>我这里有个最简单的:
