来自论文:GENIA corpus—a semantically annotated corpus for bio-textmining 2003
1.介绍
GENIA corpus, a semantically annotated corpus of biological literature, is being compiled and annotated in the scope of GENIA project. It is aiming at providing high quality reference materials to let NLP techniques work for bioinformatics and at providing the gold standard for the evaluation of text mining systems.
GENIA语料库,一个语义标注的生物文献语料库,在GENIA项目的范围内被编译和标注。它旨在提供高质量的参考材料,让NLP技术为生物信息学服务,并为文本挖掘系统的评估提供黄金标准。
we released GENIA corpus version 3.0. It consists of 2000 abstracts taken from MEDLINE database, and contains more than 400 000 words and almost 100 000 annotations that have been hand-coded for biological terms.
我们发布了GENIA语料库3.0版。它由MEDLINE数据库中的2000篇摘要组成,包含超过400000个单词和近100000个注释,这些注释是针对生物术语手工编码的。
PubMed 是一个免费的搜寻引擎,提供生物医学方面的论文搜寻以及摘要。它的数据库来源为MEDLINE。其核心主题为医学,但亦包括其他与医学相关的领域,像是护理学或者其他健康学科。它同时也提供对于相关生物医学资讯上相当全面的支援,像是生化学与细胞生物学。该搜寻引擎是由美国国立医学图书馆提供,作为 Entrez 资讯检索系统的一部分。PubMed 的资讯并不包括期刊论文的全文,但可能提供指向全文提供者(付费或免费)的连结。
2.GENIA CORPUS
Since we wanted our annotation work to converge on biological reactions concerning transcription factors in human blood cells, we selected articles with the MeSH terms, human, blood cell and transcription factor.
因为我们希望我们的注释工作能够集中在与人类血细胞转录因子相关的生物反应上,所以我们选择了包含MeSH术语、人类、血细胞和转录因子的文章。

每一个article都有medlineID,title,abstract等属性,并且abstract中的句子都被分为了sentence。
3.GENIA 本体 ONTOLOGY
GENIA ontology is a taxonomy of, currently, 47 biologically relevant nominal categories.
GENIA本体是目前47个生物学相关的命名类别的分类。
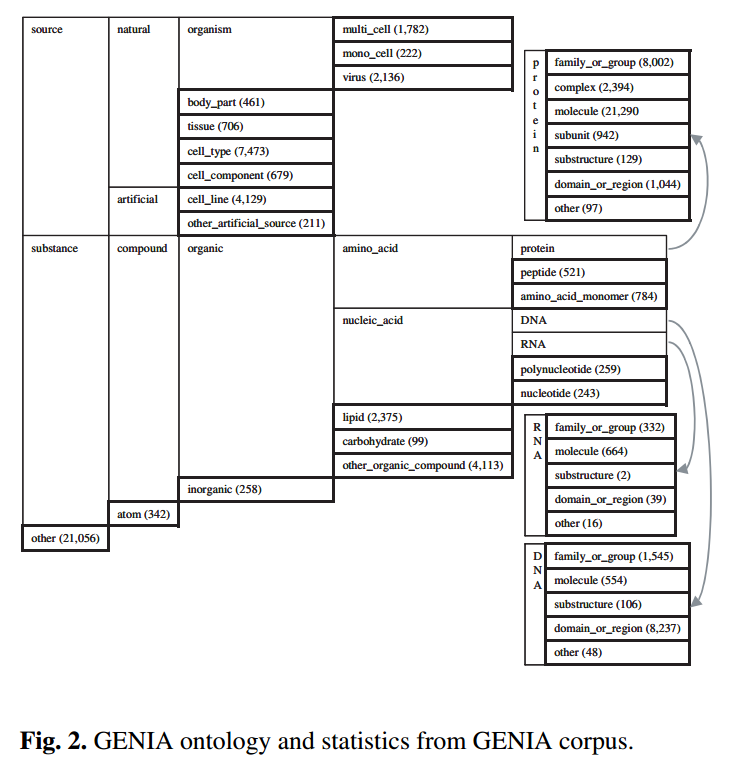
图表中最左侧的三个概念:biological source,biological substance,other.
the other is not actually a biological concept but is prepared for the terms that are regarded as biological concepts but are not identified with any other concepts in the ontology.
另一个概念实际上不是生物概念,而是为被视为生物概念但不与本体中的任何其他概念相一致的术语而准备的。
在粗黑体框中的 终端概念terminal,它们形成语义注释的实际标签集。4. LINGUISTIC ANNOTATION

术语的语法定义:
<术语>:=<修饰语>*<中心名词>
<修饰语>:=<形容词>|<名词修饰语>
*在这里可能是连接,|是或。
Mostly, terms can be annotated by simply inserting mark-ups around them as exemplified in Figure 4。
大多数情况下,术语可以通过简单地在它们周围插入标记来注释,例如图4.
图4中,IL-2gene,IL-2gene transcription,T cells,这三个术语,被cons标签所包含。
注意到:IL-2 gene是被递归地标注在IL-2gene transcription标签中的。

However, when terms appear in coordinated clauses involving ellipsis, the annotation is not simply achieved, since we cannot find all the terms fully spelled at the surface of the text.
然而,当术语出现在涉及省略的协调子句中时,注释并不简单,因为我们无法在文本表面找到所有拼写完整的术语。
图5中表现的名词是:CD2 and CD 25 receptors ,实际上是两个概念,不过前面一个省略了一个receptors,没有完整的CD2 receptors出现。
receptors 不仅是CD25的中心名词,而且是CD2的中心名词。

极度省略的协调字句例子。//很明显标签存在的是并列关系。
B and T lymphocyte activation and mitogenesis中lymphocyte是B和T的中心名词;activation and mitogenesis 是B lymphocyte和T lymphocyte的中心名词。
We, however, see that there may be high demand for simple annotations that reveal just the terms appearing at the surface of text.
然而,我们看到对简单注释的需求可能很高,这些注释只显示文本表面出现的术语。
图6的简化结果见图7:

//不太明白这个简化结果,那还能表达原来的含义嘛?
5.STATISTICS 统计
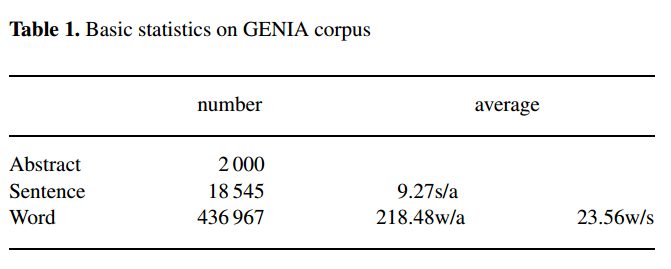
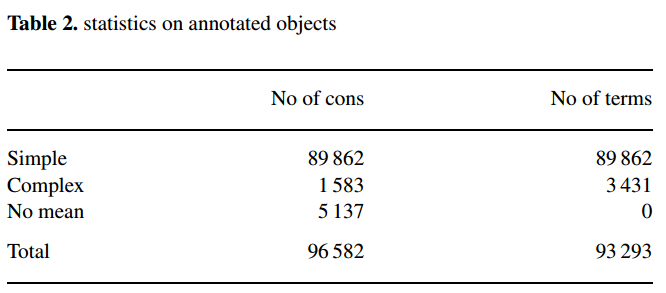
No of cons是标记数量。
表2中simple是surface level terms ,complex是higher level annotations 。