Named Entity Recognition in Biomedical Texts using an HMM Model 2004年,引用79
1.摘要
Although there exists a huge number of biomedical texts online, there is a lack of tools good enough to help people get information or knowledge from them. Named entity Recognition (NER) becomes very important for further processing like information retrieval, information extraction and knowledge discovery. We introduce a Hidden Markov Model (HMM) for NER, with a word
similarity-based smoothing. Our experiment shows that the word similarity-based smoothing can improve the performance by using huge unlabeled data. While many systems have laboriously hand-coded rules for all kinds of word features, we show that word similarity is a potential method to automatically get word formation, prefix, suffix and abbreviation information automatically from biomedical texts, as well as useful word distribution information.
虽然网上有大量生物医学文本,但是缺乏足够好的工具还帮助人们从中获取信息和知识。NER对进一步的处理,像信息检索、信息提取和知识发现变得非常重要。我们引入了对NER的HMM模型,包括基于单词相似度的平滑。实验表明,通过使用大量无标签数据,基于单词相似度的平滑能够提高效果。尽管许多系统对于各种文字特征都有费力的手工编码规则,但我们表明,单词相似度是一个潜在方法,可以从生物文本中自动获取单词格式、前缀、后缀和缩写信息,以及有用的单词分布信息。
2.使用数据
标记数据是:GENIA 3.02
无标记数据:17G XML abstract data from MEDLINE, which contains 1,381,132 abstracts.
3.分布单词相似性
Proximity-based Similarity
上下文的单词具有依赖关系,那么这个依赖关系可以通过一个小窗口的共存来表示,根据这个定义了如何去给word单词定特征。
We define the features of the word w to be the first non-stop word on either side of w and the intervening stop words。
例如:
“He got a job from this company.” (Considering a, from and this to be stop words.)
什么是停止stop单词?就是:which can be defined as the top-k most frequent words in the corpus.在语料库种出现次数多的(很明显是在标记的数据集中。)

//有一个疑问,如果是对每个单词都有一个独特的Feature(根据其寻找的规则,那么应该是不同的),那么很明显单词之间的特征向量维度是不同的啊。那么本论文里的特征向量一般是几维左右的?并没有提及。
计算单词相似度
既然单词可以用特征向量来表示了,那么两个单词之间的相似度也可以计算了,是使用余弦相似度。但是并不是特征向量的余弦相似度。
The point-wise mutual information (PMI) between a feature fi and a word u measures the strength association between them.
特征fi和单词u之间的点方向互信息( PMI )测量它们之间的强度关联。
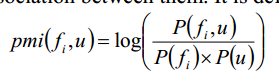

那么,其实只要一旦有了特征(可能是我现在NLP知识还太贫乏,不知道这个特征是依据这么来找的),就可以计算了所有的pmi(fi,u)了,并且计算sim(u,v)。
//想看它们的代码是怎么写的,我还是有点想知道这个特征向量长什么样子。
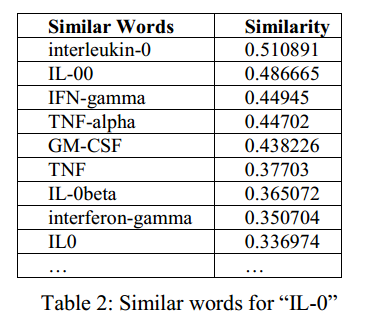
比如图2中的计算结果,是IL-0的相似单词。
Only a subset of the similarity information is useful, because the similarity of words outside of the training data and test data vocabulary is not used.
但是计算出来的相似信息,只有相似性信息的子集是有用的,因为不使用训练数据和测试数据词汇之外的单词的相似性。(这里是说交集?)
//也就是最终模型的验证还是得用标记数据。大量的非标记数据只是用来计算相似单词的。
并且从上图中可以发现摘要中关于能够自动获取单词的更多格式信息。
4.将平滑运用到隐马模型中
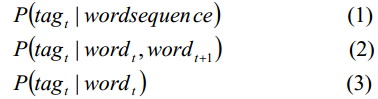
1式是正常的隐马模型,但是计算困难;使用2式进行近似计算;如果训练数据中没有这个二元模型,那么使用3式;如果没有这个一元模型,那么就是用从训练集中获取的低频率单词。
//最后一句不太明白。为什么,要用低频的呢?忽然明白,因为这个词都没有再训练集中出现,那么肯定是概率比较低的,那就用其他的低频替代了?后面它的方法的意思是直接忽略,这样模型的F值更高。

//这个4式是怎么计算的?sim是从无标签数据中得到的,但是分子上的P(tagt|w't)是怎么计算的?这就比较奇怪了。
S(w)是候选相似单词集和(为什么说时候选呢?因为之后会根据这个单词的频率进行筛选,较低的不计算在内),sim(w,w’) is the similarity between word w and w’. sim是相似值。
For each word w, we define p as the distribution of w’s tags, which are annotated in the training data.
![]()
使用KL散度来计算两个单词标签分布函数(概率模型)P的差距。
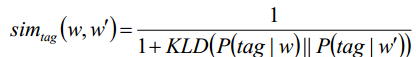
那么单词w和w'的标签分布相似度被定义为如上。
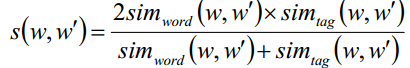
上式是一个调和平均值,是单词相似度和标签分布相似性,这个值来作为单词的相似度。
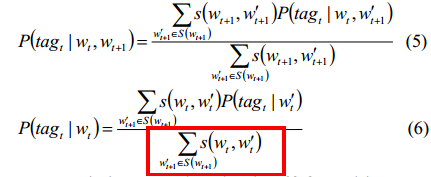
所以5式和6式分别用来平滑二元模型和一元模型。
//第6式的分布不太理解,为什么是w't+1呢?是它的下一个? 不太明白。
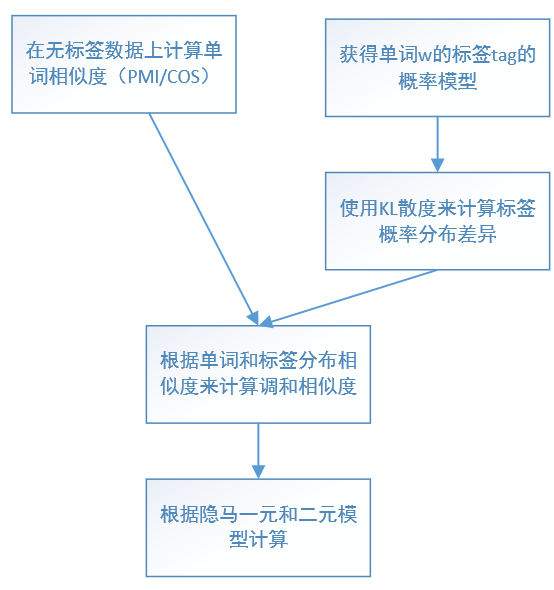
5.计算流程

//5和6不太明白。明明二元模型都没有,为什么还要用2?
1.检查二元模型(wt,wt+1)出现的频率,也就是两个单词连着出现的次数。
2.检测wt出现的次数
3.使用5进行二元平滑,并且对相似单词进行检查,如果出现次数>10。
4.使用6式进行单词平滑,
最终表现:

2比1表现好,因为它屏蔽了低频率的一元模型,我们的系统比1和2好,因为是没有使用低频率的一元和二元模型。
//其实不是很明白啊。什么意思呢?