参考自:https://blog.csdn.net/weixin_42287851/article/details/89055883
https://www.kaggle.com/general/4815
1.一个框架

2.举例
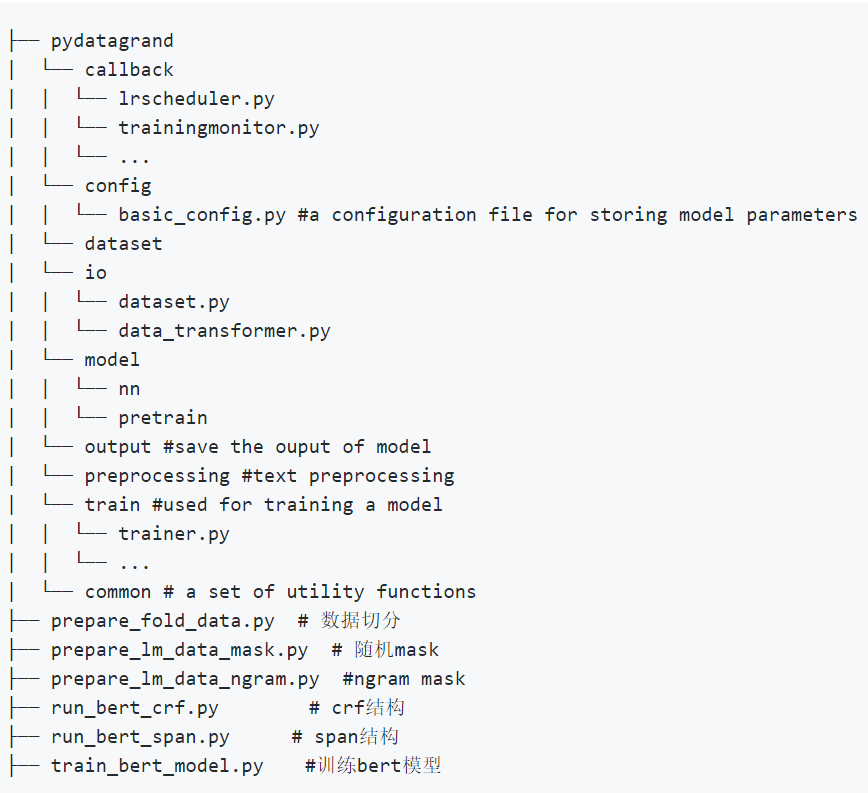
这个代码目录看起来就挺复杂的。
分别包括:外面的对初始数据的处理函数/回调/参数/数据集/io/模型/输出保存/训练。
总之,如何给代码构建目录,是有个大致框架,但也可以根据自己的项目调整。
3.一个讲解
讲解非常好!:http://arkitus.com/patterns-for-research-in-machine-learning/
1.要使用版本控制,以便更好地合作、重复实验结果。
2.要将数据和代码分开存放,能够方便地分享代码、替换数据集。
project_name/code/
project_name/data/
更好的话,可以将两个部分完全分开存放,加强了数据隔离,是向修订控制隐藏数据的一种简单方法。
/path/to/code/ /other/path/to/data/
3.将输入数据、工作数据、输出数据分开。
/path/to/code/ /other/path/to/data/input/ /other/path/to/data/working/ /other/path/to/data/output/
因为输入数据是不变的;工作数据是算法模型产生的,一直在变;输出数据是由模型产生的,它们很少改变。
这样可以安全地删除输出文件,能将输出文件方便地分享给他人。
4.对输入文件有一个说明文件readme;
编写一键式脚本,将原始数据转换为您自己的代码使用的任何格式; 永远不要手工清理数据,如果要清理,则要彻底记录下来,并不断变化。
5.经常将所有内容保存到磁盘。
以适当的时间间隔将模型参数保存到磁盘。
如果图形对于运行时诊断很有用,则可能也应该将其保存到磁盘。
在不同的数据集上运行算法时,请将输出存储在单独的文件夹中。
将每天工作的输出存储在单独的文件夹中。
工作文件夹的例子:
working/18_07_2012/dataset_1/ working/18_07_2012/dataset_2/ working/19_07_2012/dataset_1/ working/19_07_2012/dataset_2/
在上述第一个数据集下,可以看到以下文件:
dataset_1/likelihood_curve_iteration_100.eps dataset_1/likelihood_curve_iteration_200.eps dataset_1/likelihood_curve_iteration_300.eps dataset_1/model_parameters_iteration_100.dat dataset_1/model_parameters_iteration_200.dat dataset_1/model_parameters_iteration_300.dat
6.选项与参数分开。
如下:

这个是选项;
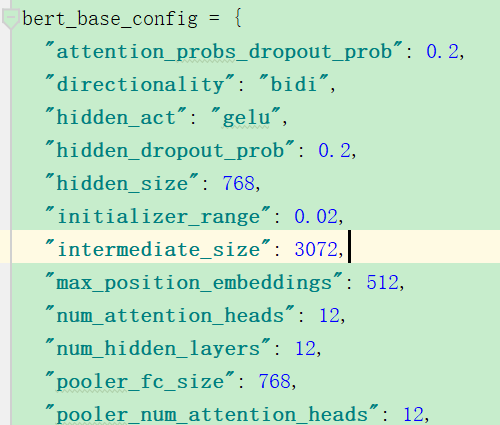
这是模型参数。
7.不要使用全局参数。
而是通过过函数参数进行信息传递。
#好的方法 % set the options options = ... % load the data data = ... % learn the parameters parameters = train_model(options, data); #不好的方法 global options, data; % set the options options = ... % load the data data = ... % learn the parameters parameters = train_model(); % assumes options and data have been set globally
不设置全局参数:
更容易debug代码;更易并行化代码。
8.保留用来产生模型的参数
% set the options options = ... % load the data data = ... % learn the parameters parameters = train_model(options, data); % store the results serialise(options, 'options.dat', options.working_path); serialise(parameters, 'parameters.dat', options.working_path);
更易复现结果。
9.更易扫描选项:
% set the options options.learning_rate = 0.1; options.latent_dimensions = {10, 20}; options.num_iterations = {300, 600}; % load the data data = ... % sweep the options for options_configuration in get_configurations(options) #这里的get_configurations函数就让能使在一个for循环里方便地实现多个模型的训练。 % learn the parameters parameters = train_model(options, data); % store the results serialise(parameters, 'parameters.dat'], ... [options.working_path '_' options_configuration.name]); end
并且通过options中的路径参数不同,则结果可以保存在不同的路径下:
working/latent_dimensions_10_num_iterations_300/ working/latent_dimensions_20_num_iterations_300/ working/latent_dimensions_10_num_iterations_600/ working/latent_dimensions_20_num_iterations_600/
如果您有权访问群集,则可以轻松地使用它来将每次运行分发到另一台计算机。
10.使仅执行部分代码变得容易。
如果您的代码在概念上可以看作是按顺序进行计算的某种管道:
以一种可以指定要执行的计算的方式编写主脚本。 将计算的每个部分的结果存储到磁盘。 例如,以下命令运行preprocess_data,initialise_model和train_model脚本。
>> run_experiment('dataset_1_options', '|preprocess_data|initialise_model|train_model|');
下面的命令是仅运行train_model脚本,并且评估模型:
>> run_experiment('dataset_1_options', '|train_model|evaluate_model|');
通过注释掉代码来模拟执行部分代码,是浪费时间的。
11.使用检查点保存模型。
你的实验可能会失败,尤其是在并行的时候:
以适当的时间间隔将整个状态(计数器等)存储到磁盘。
编写代码,一旦激活,它将从最新的保存状态继续运行算法。
确保清楚可见算法从保存状态开始。
% set the options options = ... % load the data data = ... if saved_state_exists(options) % load from disk [parameters, state] = deserialize_latest_params_state(options.working_path); % command line output disp(['Starting from iteration ' state.iteration]); else % initialize parameters = init_parameters(); state = init_state(); end % learn the parameters parameters = train_model(options, data, parameters, state);
12.编写演示和测试。
那么项目结构如下:
project/ code/ data/ demos/ tests/
13.其他想法
务必估算您希望实验进行多长时间。
保留一份日记,说明您进行每个实验的原因以及发现的结果。
使用大约10秒钟或更短的时间来处理大多数数据集,进行编码和调试。
轻松交换不同的型号和适用性指标。