1.双曲正切函数 tanh
https://www.jiqizhixin.com/graph/technologies/9e8895bd-d540-43c0-8dc6-dc9e24e6bfd7,这个讲的挺全面的。
https://www.cnblogs.com/charlesblc/p/8660733.html
原来也就是tanh函数啊,tan是正切的表示。
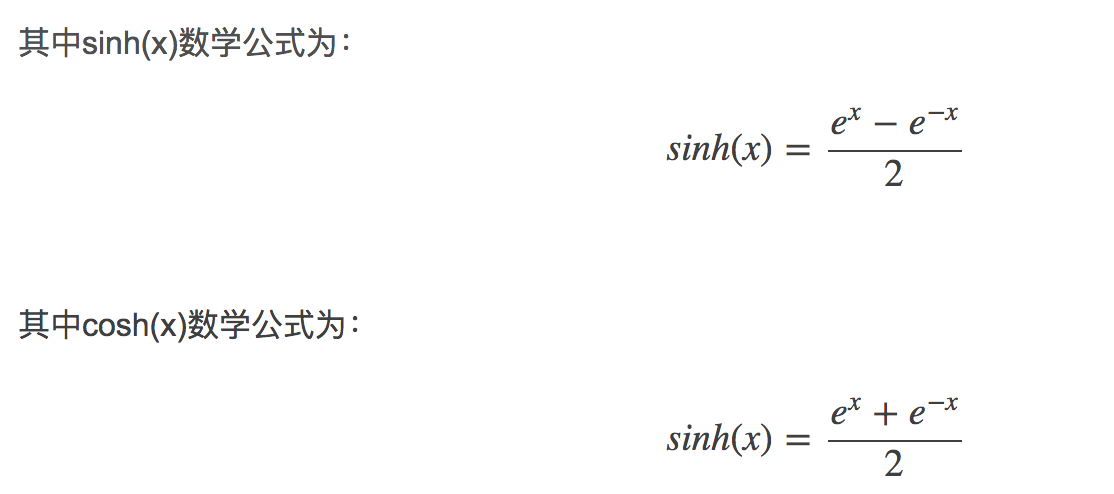
双曲正切函数是双曲函数的一种,它也是双曲正弦函数(sinh)与双曲余弦函数(cosh)的商。

对应的函数图像:
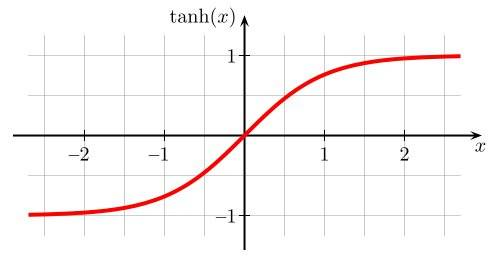
值域为(-1,1)。作为激活函数:“在特征相差明显时的效果会很好,在循环过程中会不断扩大特征效果”。这个结论从哪里来?因该是2011年的那篇专门研究的论文,但是具体使用的时候我还没体会过它的差别。它也会有梯度消失的情况,并且看公式里有幂运算,所以就计算速度慢,收敛速度慢。
2.bert初始化参数的方法
首先先来学习一下bert中是如何初始化参数的,以BertForSequenceClassification类为例:
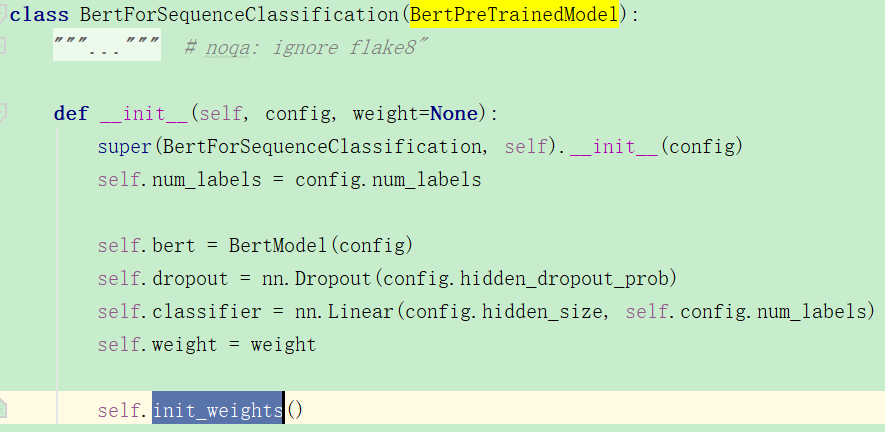
在初始化函数中,而父类BertPreTrainedModel并没有实现init_weights函数,而是在父父类中PreTrainedModel中的:
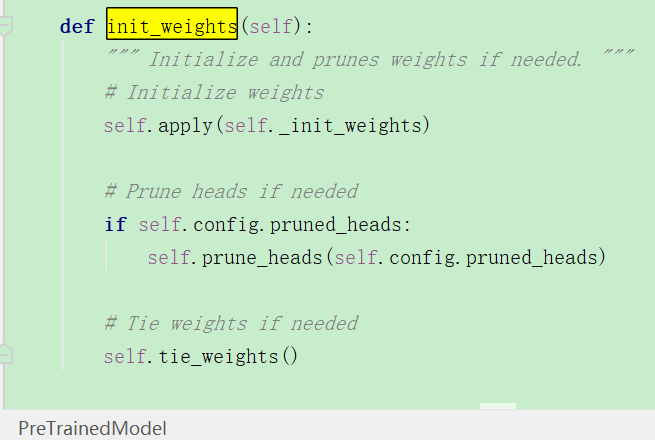
当然这个初始化方法是对BertForSequenceClassification类的?里面需要初始化的也只是self.classifier这个线性分类层吧?
但是上面这个初始化参数的函数具体的策略是什么呢?
搜索了PreTrainedModel self.apply(self._init_weights),也没有搜到,但是我明白了。这个_init_weights是在BertPreTrainedModel中实现的,又再它的父类中调用了,就整个整的挺麻烦的。
那么这就是pytorch中针对bert的初始化方法:

可以看到对线性层和嵌入层它初始化为均值为0,方差为std的正态分布,在roberta中设置的为:0.02.
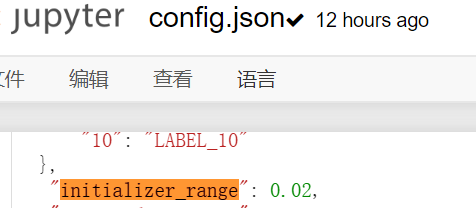
那如果是其它类型的就不初始化了?
3.GRU默认的初始化参数方法

这里是RNNBase类中的初始化参数方法,可以看到是均匀分布。
但是这个函数和初始化参数有关系吗?
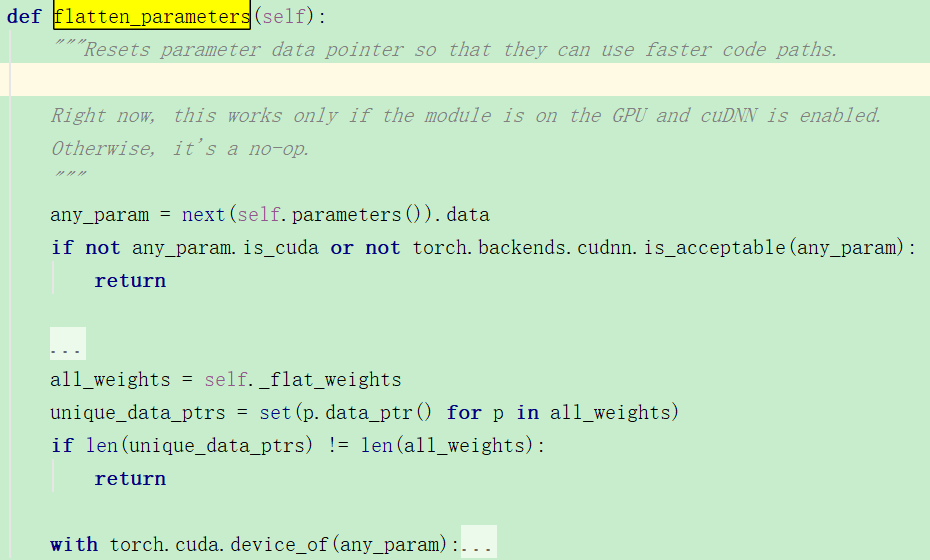
翻译:重置参数数据指针,以便它们可以使用更快的代码路径。看来是没有关系的,只是关于内存的问题,而且它只在使用GPU的时候才有效。
我有一点疑问的是,既然GRU的初始化方法nn里已经给了,那么https://www.cnblogs.com/jfdwd/p/11269622.html提到的那么多的初始化方法该怎么用呢?只能说是自己再写个函数使用了吧。
flatten_parameters函数作用:重置数据指针的作用。https://stackoverflow.com/questions/53231571/what-does-flatten-parameters-do,这个回答的非常好:

用户警告:RNN模块权重不是单个连续内存块的一部分。 这意味着它们需要在每次调用时进行压缩,从而可能极大地增加内存使用量。 要再次压缩权重,请调用flatten_parameters()。
主要是压缩权重,保持内存优化的作用,我认为。和参数初始化是没有什么关系的。
4.正交初始化
https://www.zhihu.com/question/57828011,RNN初始化的tricks。这里的两个回答都提到了正交初始化,orthogonal初始化,它到底是什么神仙?
https://discuss.pytorch.org/t/initializing-rnn-gru-and-lstm-correctly/23605,这里给出了使用方法:
def init_weights(self): for m in self.modules(): if type(m) in [nn.GRU, nn.LSTM, nn.RNN]: for name, param in m.named_parameters(): if 'weight_ih' in name: torch.nn.init.xavier_uniform_(param.data) elif 'weight_hh' in name: torch.nn.init.orthogonal_(param.data) elif 'bias' in name: param.data.fill_(0)
理论讲解:https://smerity.com/articles/2016/orthogonal_init.html,https://zhuanlan.zhihu.com/p/28981495,我还没有学习。
但是似乎这个正交初始化还非常复杂?需要单个单个的正交初始化?
https://gist.github.com/kaniblu/81828dfcf5cca60ae93f4d7bd19aeac5,https://gist.github.com/jeasinema/ed9236ce743c8efaf30fa2ff732749f5
看了这两个之后我还是不确定,我就按照上面的直接初始化了,就不分那么细了。
5.如何初始化GRU中的权重?
https://discuss.pytorch.org/t/how-to-initialize-weights-bias-of-rnn-lstm-gru/2879/6,这个给的讲的不错,我可以利用利用。

可以看到,参数有这些,上面是LSTM的,GRU的有所不同,上面所有的4改为3:
import torch import torch.nn as nn a = nn.GRU(5, 5, num_layers=1) from torch.nn import init for layer_p in a._all_weights: for p in layer_p: if 'weight' in p or 'bias' in p: #对权重和偏置进行初始化 init.normal_(a.__getattr__(p), 0.0, 0.02) print(p, a.__getattr__(p),a.__getattr__(p).shape) #输出: weight_ih_l0 Parameter containing: tensor([[ 1.9472e-02, 1.7127e-02, 4.8454e-03, 1.2877e-02, -1.1276e-02], [。。。省略]], requires_grad=True) torch.Size([15, 5]) weight_hh_l0 Parameter containing: tensor([[-3.9420e-03, -2.5489e-02, -1.7880e-03, 2.2714e-02, -2.0984e-02], [省略。。。]], requires_grad=True) torch.Size([15, 5]) bias_ih_l0 Parameter containing: tensor([-0.0120, -0.0162, 0.0206, 0.0172, -0.0066, -0.0238, -0.0291, 0.0145, 0.0132, -0.0099, -0.0299, 0.0352, 0.0289, -0.0345, 0.0046], requires_grad=True) torch.Size([15]) bias_hh_l0 Parameter containing: tensor([-0.0378, -0.0178, 0.0059, 0.0404, 0.0010, -0.0124, 0.0138, -0.0143, 0.0182, 0.0207, -0.0114, -0.0074, 0.0349, 0.0105, -0.0145], requires_grad=True) torch.Size([15])
6.如何初始化全连接层的权重和偏置?
https://discuss.pytorch.org/t/how-are-layer-weights-and-biases-initialized-by-default/13073/4
stdv = 1. / math.sqrt(self.weight.size(1)) self.weight.data.uniform_(-stdv, stdv) if self.bias is not None: self.bias.data.uniform_(-stdv, stdv)
因为全连接层它的权重和参数名字是知道的,但在GRU中可以用上面的循环就很ok。
https://stackoverflow.com/questions/49433936/how-to-initialize-weights-in-pytorch,这个讲的也很清晰啊。
初始化单层的网络:
conv1 = torch.nn.Conv2d(...)
torch.nn.init.xavier_uniform(conv1.weight)
初始化多层的网络:
def init_weights(m): if type(m) == nn.Linear: torch.nn.init.xavier_uniform(m.weight) m.bias.data.fill_(0.01) net = nn.Sequential(nn.Linear(2, 2), nn.Linear(2, 2)) net.apply(init_weights)
也就是说会调用init_weights到每个线性网络层。
下面的那个回答也很有意思,初始化参数的方法:All Zeros or Ones、Uniform Initialization、General rule for setting weights、normal distribution to initialize the weights。
四种方案分别是:权重都初始化为1或0、权重用0-1之间的均匀分布初始化、
y = 1.0/np.sqrt(n) m.weight.data.uniform_(-y, y) m.bias.data.fill_(0)
这样general的均匀分布初始化,因为nn里给的默认初始化是这样的。
正态分布:
y = m.in_features # m.weight.data shoud be taken from a normal distribution m.weight.data.normal_(0.0,1/np.sqrt(y)) # m.bias.data should be 0 m.bias.data.fill_(0)
最终就还是发现,人家nn默认的效果最好。
7.TypeError: init_weights() takes 1 positional argument but 2 were given
https://github.com/lonePatient/Bert-Multi-Label-Text-Classification/issues/19,这里说因为版本的问题,所以要修改self.apply(self.init_weights) 为 self.init_weights()。