2.卷积核的个数如何确定?
我终于也想到了这个宝藏问题啊,https://www.zhihu.com/question/38098038
不同卷积核的个数对模型性能有什么影响呢?是要根据具体任务来调试吗?那调试的话有个大体的路子吗?
看了三个回答后基本有了了解。
总结:对于cnn来说,选择的是小而深,这样的话参数少,计算复杂度低。
卷积核的大小,卷积核也可以称为特征提取器,一瓣选择奇数?因为偶数的话比如2会丢失掉视野,原因如下:

可以看出如果要保持输入和输出维度一致,那么就需要卷积核宽度为基数。
所以选择什么大小和个数都不一定,最优的话还是要调试了。
关于大小和深度的权衡,下面这张图非常好:

对于第二层的卷积层它的这个红色的视野,其实是对应到input中的5*5的,所以你可以发现,3*3 stack了两层,最终层的视野可以扩大;相同的,如果是3个3*3,那么到input的视野就是7*7了,而前者的参数更少、非线性关系更多More nonlinearity、计算量更小,这就非常有优势了!
//我觉得还是要看经典模型中参数是怎么设置的,就先搬过来应该就效果比较好吧。

上面这个图就挺有意思的,分别比较了卷积核大小、卷积核个数、激活函数、全连接层个数、有无预处理、有无dropout、不同学习率、不同bsz、有无归一化,这么多因素对模型性能的影响。比较影响的因素有:每层的卷积核个数、激活函数、有无预处理,当然这个都是在确定了网络深度为3层的时候的实验结果,说不定增加模型深度就很能提升效果呢。
3.如果训练集和测试集分布不同怎么办?
https://zhuanlan.zhihu.com/p/72503153,这个总结的还蛮不错的。
https://www.zhihu.com/question/264241478/answer/280545256,这个也有一收获。
协变量偏移, 也就是说训练数据和测试集分布并不相同,

下面这张图有助于理解:
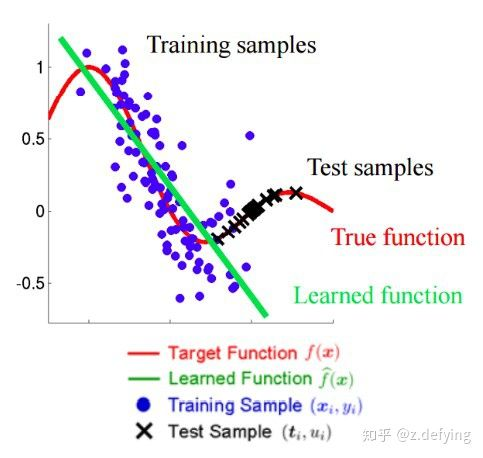
蓝色和黑色就表示了不同分布的训练和测试集。
文中提到的一种数据不平衡是对于分类问题,各类别数目不同,“训练集中30%的车、40%的人和30%的树,而测试集中有10%的车、20%的人和70%的树”。
然后提出了一些方法,让我眼前一亮的是,桥集,通过它来判断是方差原因,还是数据不匹配(分布不同)的原因:
桥集是从训练集中取出的一部分,所以它的分布和训练集是保持一致的,那么它们之间的误差只能是来自过拟合,过拟合:

桥集与训练集7%是由于过拟合造成的,桥集和验证集1%是由数据不匹配造成的(那是不是说明,这个数据挺匹配的?)。
不匹配现像:

桥集和训练集1%由过拟合造成,桥集和验证集7%由数据不匹配造成,说明是数据分布不一致吧。
下面这个我感觉还蛮有启发的:
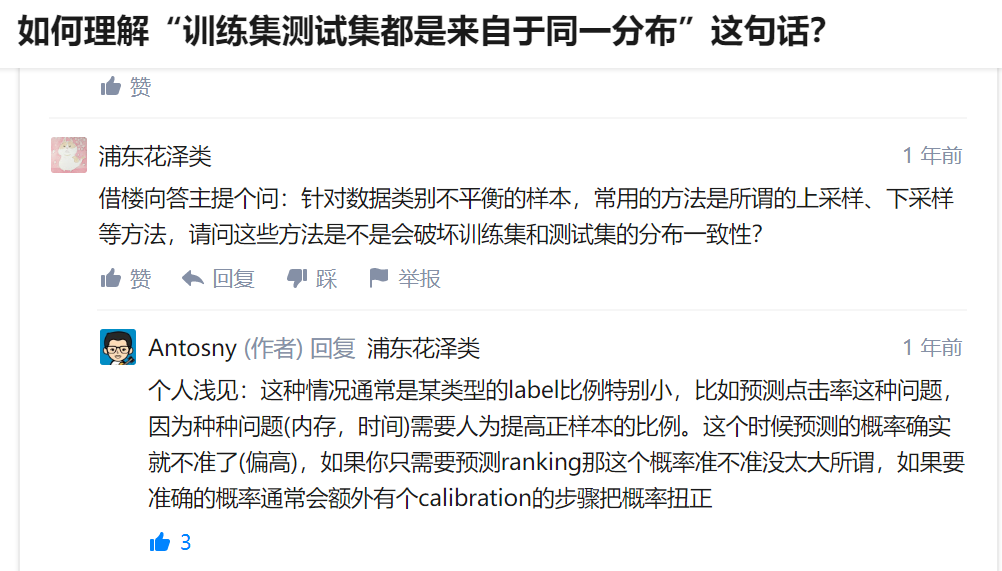
如果通过上/下采样,那可能就会破坏分布,可能会发生协变量偏移问题,回复中提到的是,需要一个calibration的步骤(我当然是不懂了。)