------------恢复内容开始------------
1.安装pytorch
https://pytorch.org/get-started/locally/
在这个网站上根据cuda版本选择命令:
conda install pytorch torchvision cudatoolkit=10.0 -c pytorch
安装过程中出现了:
CondaError: Downloaded bytes did not match Content-Length
解决办法:https://blog.csdn.net/feifei3211/article/details/80361227
其实我之前已经添加了清华源,但是最后两个没有添加:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/pro/
2.查看是否可用gpu
https://blog.csdn.net/nima1994/article/details/83001910
torch.cuda.is_available() cuda是否可用 torch.cuda.device_count() 返回gpu数量 torch.cuda.get_device_name(0) 返回gpu名字,设备索引默认从0开始 torch.cuda.current_device() 返回当前设备索引
发现返回的是False,然后用conda list查看,发现没有cudnn,所以尝试安装一下,

3.安装cudnn
通过如下命令:
https://blog.csdn.net/lihe4151021/article/details/90237681
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2
查看版本,发现报错没有这个目录,
https://developer.nvidia.com/rdp/cudnn-archive,cudnn的官网,下载文件需要登陆。
tar -xvf cudnn-10.0-linux-x64-v7.3.1.20.tgz sudo cp cuda/include/cudnn.h /usr/local/cuda/include/ sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64/ sudo chmod a+r /usr/local/cuda/include/cudnn.h sudo chmod a+r /usr/local/cuda/lib64/libcudnn*
再查看版本就可以查到cudnn了:

但是通过conda list为什么查看不到cudnn呢?有可能是我当前的conda的python环境使用的是cuda9.2,因为我是在安装10.0的cuda之前创建的环境,所以我决定将这个conda环境删除,再重新建一个conda的python环境,又重新安装torch,还是不行。
4.conda list 查看不到cudnn
https://blog.csdn.net/dlhlsc/article/details/88943047,这里的方法是说:
import torch
print(torch.backends.cudnn.enabled)

似乎是可以的,但是我看了一下安装的内容:
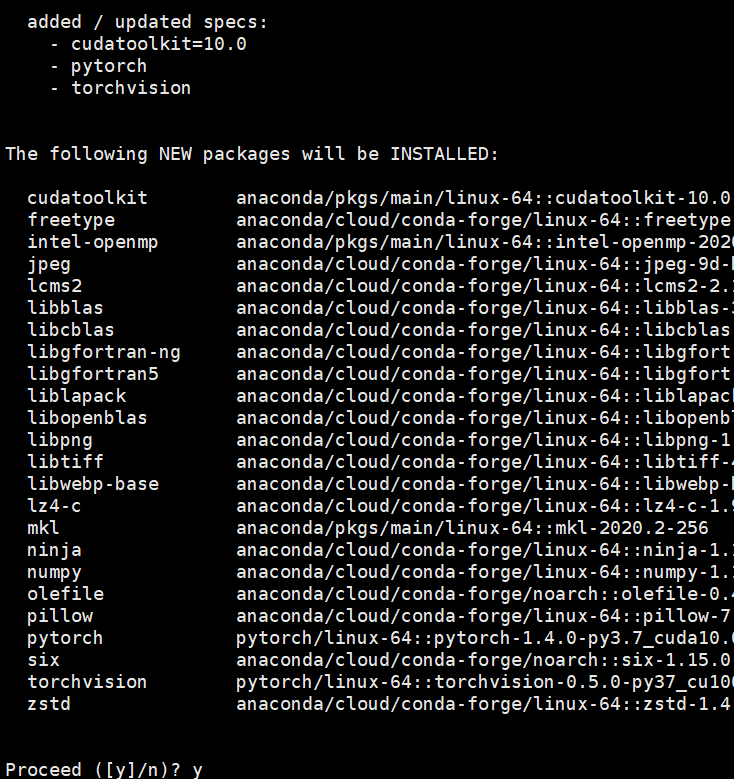
并没有自带安装cudnn啊。
上面这个命令只是查看说是否使用cudnn,https://www.cnblogs.com/wanghui-garcia/p/11514502.html。
中间又查看了一下版本:
>>> torch.__version__ '1.4.0' >>> torch.version.cuda '10.0' >>> torch.backends.cudnn.version() 7603
解决办法,因为之前cudnn下载下来我是用root用户安装的,是否然后我就没有权限?所以我用我自己的账户在所用的conda的python环境下安装:
运行如下命令:
tar -xvf cudnn-10.0-linux-x64-v7.6.3.30.tgz #重新解压
sudo cp cuda/include/cudnn.h /usr/local/cuda/include/ sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64/ sudo chmod a+r /usr/local/cuda/include/cudnn.h sudo chmod a+r /usr/local/cuda/lib64/libcudnn*
还是不行,而且上面的文件所有者还是root,我不知道这对我是否会有影响,应该不会啊,cuda都是root的,也是可以用的吧。
应该也不是版本的问题,我cuda是10.0.130,cudnn的版本是7.6.3,完全是可以对的上的,我也是按照版本来下载的啊。
5.torch.cuda.is_available() 为False
https://blog.csdn.net/u013685264/article/details/106925290/
import os import torch os.environ["CUDA_VISIBLE_DEVICES"] = "0"
还是不行,不可用GPU
6.是否是驱动版本的问题
cat /proc/driver/nvidia/version
上述命令查看驱动版本,
![]()
和查看显卡得出的是一样的:

https://www.nvidia.cn/Download/driverResults.aspx/165210/cn,https://www.nvidia.cn/drivers/results/165210/,都一样,重装了
在使用命令安装的时候遇到了问题:
sudo service lightdm stop sudo sh ./NVIDIA-Linux-x86_64-430.14.run sudo service lightdm start
首先是第一条关闭在桌面的命令:
Failed to stop lightdm.service: Unit lightdm.service not loaded.
这一条忽略了,然后运行第二条run的命令,错误信息在cat /var/log/nvidia-installer.log中:
ERROR: An NVIDIA kernel module 'nvidia-drm' appears to already be loaded in your kernel.
This may be because it is in use (for example, by an X server, a CUDA program, or the NVIDIA Persistence Daemon),
but this may also happen if your kernel was configured without support for module unloading.
Please be sure to exit any programs that may be using the GPU(s) before attempting to upgrade your driver.
If no GPU-based programs are running, you know that your kernel supports module unloading, and you still receive this message,
then an error may have occured that has corrupted an NVIDIA kernel module's usage count, for which the simplest remedy is to reboot your computer. 错误:NVIDIA内核模块“ nvidia-drm”似乎已加载到您的内核中。 这可能是因为正在使用它(例如,X服务器,CUDA程序或NVIDIA Persistence Daemon),
但是如果您的内核配置为不支持模块卸载,则也可能会发生这种情况。 在尝试升级驱动程序之前,请确保退出所有可能正在使用GPU的程序。 如果没有基于GPU的程序正在运行
,则说明您的内核支持模块卸载,并且您仍然收到此消息,则可能发生了一个错误,该错误已损坏了NVIDIA内核模块的使用计数,最简单的解决方法是重新启动您的NVIDIA内核模块。 电脑。
其实是有Xorg程序占用GPU的:
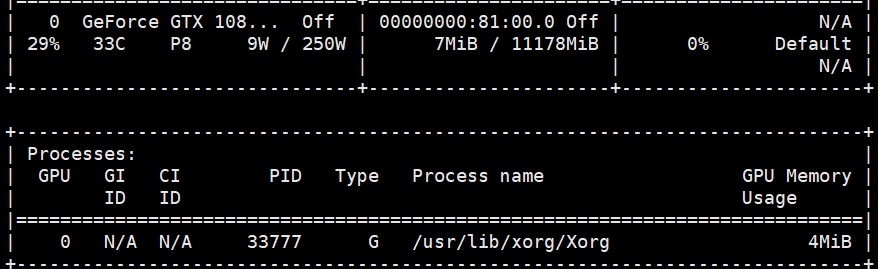
所以目前还是陷入了一个循环中,想重装一下驱动,需要关掉这个进程,或者是需要关掉上面的桌面,就需要reboot,不知道reboot了之后还能不能连上?就需要再开机试试。
------------恢复内容结束------------