Python提供了必要的函数和方法进行默认情况下的文件基本操作
文件打开方式:
open(name[,mode[buf]]) name:文件路径 mode:打开方式 buf:缓冲buffering大小
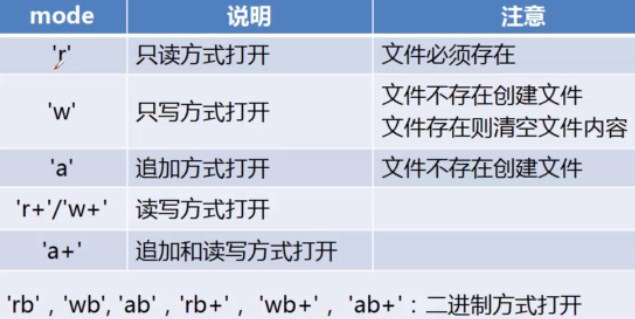
文件读取方式:
read([size]):读取文件(读取size字节,默认读取全部)
readline([size]):读取一行
readline([size]) :读取缓冲buf(io.DEFAULT_SET_BUFFER),返回每一行所组成的列表
iter:使用迭代器遍历读取文件 f.open(name);iter_f = iter(f);用for line in iter_f循环迭代器
with open('pi_digits.txt') as f: # 默认模式为‘r’,只读模式
contents = f.read() # 读取文件全部内容
文件写入方式:
write(str):将字符串写入文件
writelines(sequence_of_strings):写多行到文件,参数为可迭代的对象
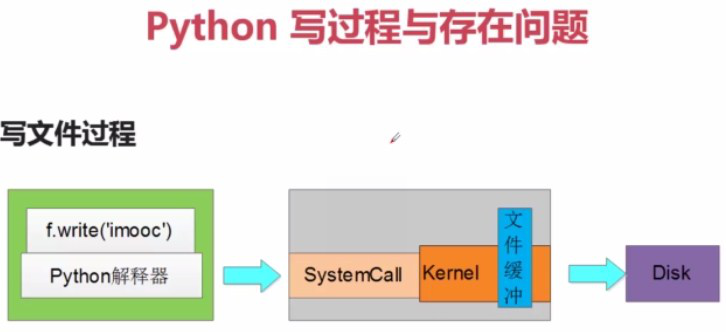
当调用write(str)时,python解释器调用系统调用想把把内容写到磁盘,但是linux内核有文件缓存机制,所以缓存到内核的缓存区,当调用close()或flush()时才会真正的把内容写到文件
或者写入数据量大于或者等于写缓存,写缓存也会同步到磁盘上
关闭文件的目的
1:写缓存同步到磁盘
2:linux系统中每个进程打开文件的个数是有限的
3:如果打开文件数到了系统限制,在打开文件就会失败
python文件指针的操作:
seek(offset[,whence])移动文件指针
offset:偏移量,可以为负数
whence:偏移相对位置
python文件指针的定位方式:
os.SEEK_SET 相对于文件的起始位置 0
os.SEEK_CUR 相对于文件的当前位置 1
os.SEEK_END 相对于文件的结尾位置 2
Python 文件属性:
file.fileno(): 文件描述符;
file.mode: 文件打开权限;
file.encoding: 文件编码方式;
file.closed: 文件是否关闭;
Python 标准文件:
标准输入文件:sys.stdin; 只读 描述符为0
标准输出文件:sys.stdout; 只写 描述符为1
标准错误文件:sys.stderr; 只写 描述符为2
Python 命令行参数:
sys模块提供sys.argv属性,通过该属性可以得到命令行参数。sys.argv是一个字符串序列,保存着命令行的参数,其中sys.argv[0]是文件名,1~n是真正的参数
Python 文件编码方式
Python文件默认的编码格式是ASCII格式,要写入中文可以将编码格式进行转换
1. a = unicode.encode(u'你好', 'utf-8') 转换, 一个汉字在ASCII码中占3字节,在unicode中占2字节。
2. 直接创建utf-8格式的文件。使用codecs模块提供的方法创建指定编码格式文件:
codecs.open(fname, mode, encoding, errors, buffering): 使用指定编码格式打开文件
3. 使用系统提供的open()函数也可以创建指定编码格式的文件:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
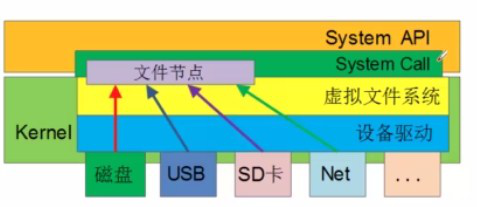
Linux文件系统简单示意图
下面是python操作文件的流程
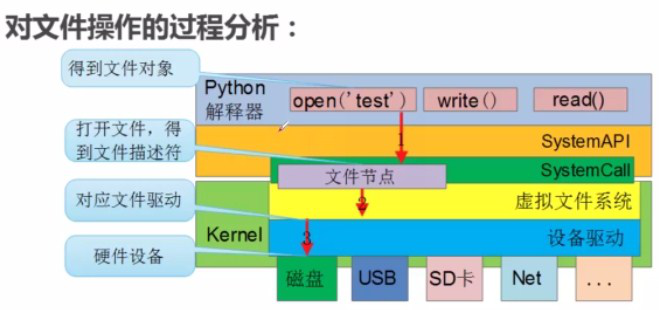
python基础 3.0 file 读取文件
当然,这种方法是普通的写入和读取,我们通常还有这样的问题,那就是字典啊,元祖啊,集合啊等对象,需要写入,但是读取的时候还是要按照原来的形式读取,并非上述方法中的字符串方式读取。那我们就可以使用pickle这个工具了:
首先要导入包
|
1
|
import pickle |
然后要进行代码的编写,这里要记住,写入文件模式是wb,读取时rb(b一般都是二进制,想必大家应该知道了,它的存储方式):
|
1
|
pick_file = open("pick.pick",'wb') |
如果此时,我们有一个集合:
|
1
|
list1 = [1,2,3,4,5,'abd',['a',4,'g','d']] |
则,我么可以这样存储:
|
1
2
|
pickle.dump(list1,pick_file)pickle.close() |
如果读取时候,我们可以这样做:
|
1
2
3
|
pick_file = open("pick.pick",'wb')list2 = pickle.load(pick_file)pickle.close() |