邻接表是图论中常用的一种数据结构。
邻接表与邻接矩阵有相似的作用:用于储存一个图中所有的节点,但是邻接矩阵比较浪费内存,当数据较小时,邻接矩阵还可以计算
但是一旦数据较大,用邻接矩阵往往就会超时或者超内存,这时就要使用邻接表来存图了;为方便理解邻接矩阵与邻接表的储存方式。
我们先规定一组数据
1 10
3 5
8 9
我们将所给的点标记为1,其余为0
(1)邻接矩阵(适合小数据点稠密型图)
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
我们可以看到虽然只有三个点我们却不得不开一个10x10的二维数组来存放数据这极大的浪费了空间
当遍历图时如果数据过大还可能会超时;那么邻接表呢?
(2)邻接表:(适合大数据点稀疏型图)
还是以上三个点
V1————>V10
V3————>V5
V8————>V9
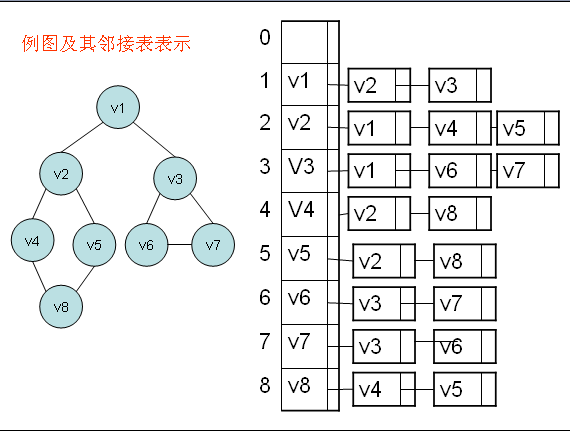
只需要一个链即可完成 大大的节省了内存 ;详情如下图:
下边附上构建邻接表的通用模板:
#include<stdio.h>
#include<string.h>
int n,m;
int head[10010];//表头,head[i]代表起点是i的边的编号
int headcnt;//代表边的总编号
struct List {
int u,v,w;//分别为边的起边、终点、权值
int next;//代表调用时下一条边的编号
//也就是当前边的上一条边的编号
} edge[10010];//结构体记录边
void add(int u,int v,int w) {
edge[headcnt].u=u;
edge[headcnt].v=v;
edge[headcnt].w=w;
//把u、v、w、存入边的信息中
edge[headcnt].next=head[u];
//把这条边的上一条(调用时的下一条边)存入信息
head[u]=headcnt++;
//记录这条以u为顶点的边的编号
//并使总编号+1
}
int main() {
while(scanf("%d %d",&n,&m)!=EOF) {
headcnt=0;
memset(head,-1,sizeof(head));
while(m--) {
int u,v,w;
scanf("%d %d %d",&u,&v,&w);
add(u,v,w);//读取u、v、w存入表中
}
int t;
scanf("%d",&t);
//找到以t为顶点的最大编号边并一直向前寻找
//直到当前边之前无边
for(int i=head[t]; i!=-1; i=edge[i].next) {
printf("%d %d
",edge[i].v,edge[i].w);
}
}
return 0;
}