| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/Networkengineering1834 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/Networkengineering1834/homework/11146 |
| 这个作业的目标 | 学会使用PSP表格规划项目开发计划,学习使用Git管理代码,Markdown 基础语法编写文本,学习写博客,学习文本相似度计算算法 |
GitHub 仓库地址
https://github.com/Boyle-Coffee/3118005327
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 20 |
| · Estimate | 估计这个任务需要多少时间 | 30 | 20 |
| Development | 开发 | 720 | 620 |
| · Analysis | 需求分析 (包括学习新技术) | 120 | 90 |
| · Design Spec | 生成设计文档 | 40 | 30 |
| · Design Review | 设计复审 | 30 | 20 |
| · Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 40 | 30 |
| · Design | 具体设计 | 30 | 40 |
| · Coding | 具体编码 | 360 | 320 |
| · Code Review | 代码复审 | 60 | 30 |
| · Test | 测试(自我测试,修改代码,提交修改) | 60 | 60 |
| Reporting | 报告 | 80 | 110 |
| ·Test Report | 测试报告 | 30 | 70 |
| ·Size Measurement | 计算工作量 | 20 | 10 |
| ·Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 30 |
| Total | 合计 | 820 | 750 |
算法设计
算法思路
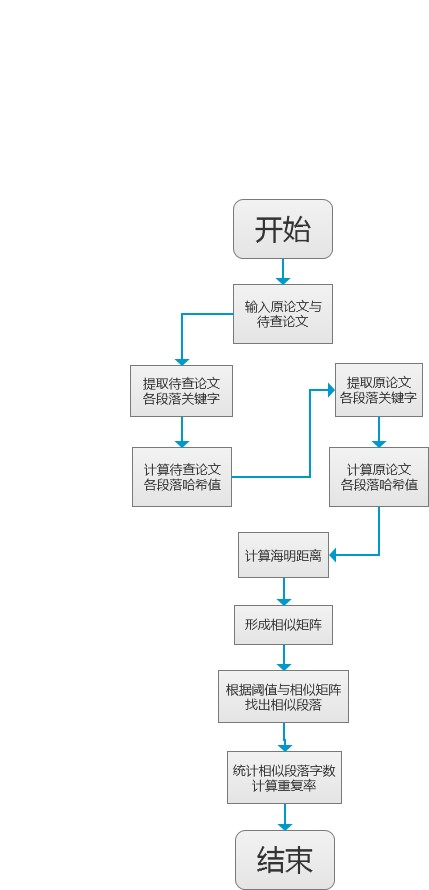
本算法采用 SimHash 值来计算段落的局部敏感哈希值,先采用 jieba 框架提取两篇论文的关键字及其权重,并根据关键字以及权重分别计算两篇论文各个段落的哈希值,并计算各个段落间的哈希值的海明距离,形成相似矩阵,根据相似矩阵以及设定好的阈值,来确定哪些段落比较相似,进而计算出待查论文与原论文的相似度。
SimHash 算法主要参考博客:simhash算法
代码主要参考GitHub库:https://github.com/CuiYongen/DuplicateChecking
算法流程图
接口设计与实现过程
接口及功能的具体设计
该项目主要包括两个模块,文件管理模块与计算模块,文件管理模块主要负责读取与存储文件,计算模块主要负责计算文字的局部敏感哈希值以及论文的重复率,各模块接口的具体设计如下:
文件管理模块方法
file_util.load_file:
功能:加载txt文件内容
输入参数:
- file_path:读取txt文件的路径
返回值:
- parags:文件内容,即包含txt文件的字符序列的列表
file_util.save_file:
功能:保存文件内容,本项目将保存论文的重复率以及相似的段落
输入参数:
- file_path:文件路径
- result:文件内容,即论文查重算法的结果
返回值:
- 无
计算模块方法
cal_util.cal_repeat_rate
功能:采用SimHash算法计算论文的重复率,供主模块调用的方法,是该模块的主方法
输入参数:
- orig_paper:原论文的字符序列
- orig_modify_paper:抄袭论文的字符序列
返回值:
- result:保留计算结果的字典,包括两篇论文的重复率和重复的段落;当返回 -1 时,说明抄袭论文编码读取失败;当返回 -2 时,说明原论文编码读取失败;返回 -3 则是计算汉明距离时发生错误
项目结构体系

类调用关系
该项目的主函数为 main.py 函数,它负责解析命令行,并根据命令行的参数,调用 file_util 模块的接口读取文件,再调用 cal_util 的方法计算论文的重复率,最后调用 file_util 模块的接口保存结果
计算模块方法的改进
主要改进了方法 cal_util.cal_repeat_rate ,原本的计算方式是利用内外两层 for 循环来分别计算原论文与待查论文各段落的相似度,伪代码如下:
for para_a in ori_paper:
for para_b in ori_add_paper:
conter_dis(para_a, para_b)
当这样的计算效率低下,测试1中所用的时间高达33秒,所以我改进了算法,采用两个并列的 for 循环分别计算SimHash,并将结果保存在两个数组中,最后利用 NumPy 的矩阵运算计算相似度矩阵,加快运行速度,计算相似度,伪代码如下:
a_list = []
for para_a in ori_paper:
a_list.append(simhash(para_a))
b_list = []
for para_b in ori_add_paper:
b_list.append(simhash(para_b))
conter_dis_with_numpy_mat(a_list, b_list) # 利用 NumPy 的矩阵运算计算相似度矩阵
这样的改进,测试1所用时间为0.388秒,速度提升了将近一百倍。
计算模块部分异常处理说明
对于计算不同部分的错误,通过返回不同数值的负数来反馈,当 cal_util.cal_repeat_rate 返回的值不是字典,而是负值时,说明计算过程中出现异常,这里采用伪代码表述:
def cal_repeat_rate(orig_paper, orig_modif_paper):
try:
cal_hash(orig_paper) # 计算原论文哈希值
except:
return -1
try:
cal_hash(orig_modify_paper) # 计算待查论文哈希值
except:
return -2
try:
cal_hamming_dis() # 计算海明距离
result = save_sim_parag() # 保存计算结果
except:
return -3
return result
可以看到,当返回 -1 时,说明抄袭论文编码读取失败;当返回 -2 时,说明原论文编码读取失败;返回 -3 则是计算汉明距离或者保存计算结果时发生错误,这样外部接收到返回值后,就能及时知道是哪里出现错误。
计算模块部分单元测试展示
测试一
测试内容:输入正常txt文件 orig_0.8_add.txt 的路径
输入:
# 在项目根目录输入命令行
$ python main.py dataset/orig.txt dataset/orig_0.8_add.txt dataset/ans.txt
结果:
成功计算出重复率,并将结果保存到 ans.txt 文件中,耗时大约 0.388s , 部分结果如下:

测试二
测试内容:当输入的原论文文件不存在时,进行测试
输入:
# 在项目根目录输入命令行
$ python main.py dataset/not_exist.txt dataset/orig_0.8_add.txt dataset/ans.txt
结果:
提示文件不存在,并打印一下错误内容

测试三
测试内容:当输入的待查论文文件不存在时,进行测试
输入:
# 在项目根目录输入命令行
$ python main.py dataset/orig.txt dataset/not_exist.txt dataset/ans.txt
结果:
提示文件不存在,并打印一下错误内容

测试四
测试内容:输入正常txt文件 orig_0.8_add.txt 的路径
输入:
# 在项目根目录输入命令行
$ python main.py dataset/orig.txt dataset/orig_0.8_del.txt dataset/ans2.txt
结果:
成功计算出重复率,并将结果保存到 ans2.txt 文件中,耗时大约 0.348s,部分结果如下:

测试五
测试内容:当输入的原论文文件为空时,进行测试
输入:
# 在项目根目录输入命令行
$ python main.py dataset/empty.txt dataset/not_exist.txt dataset/ans.txt
结果:
提示错误结果,打印内容如下:

性能分析
性能统计表
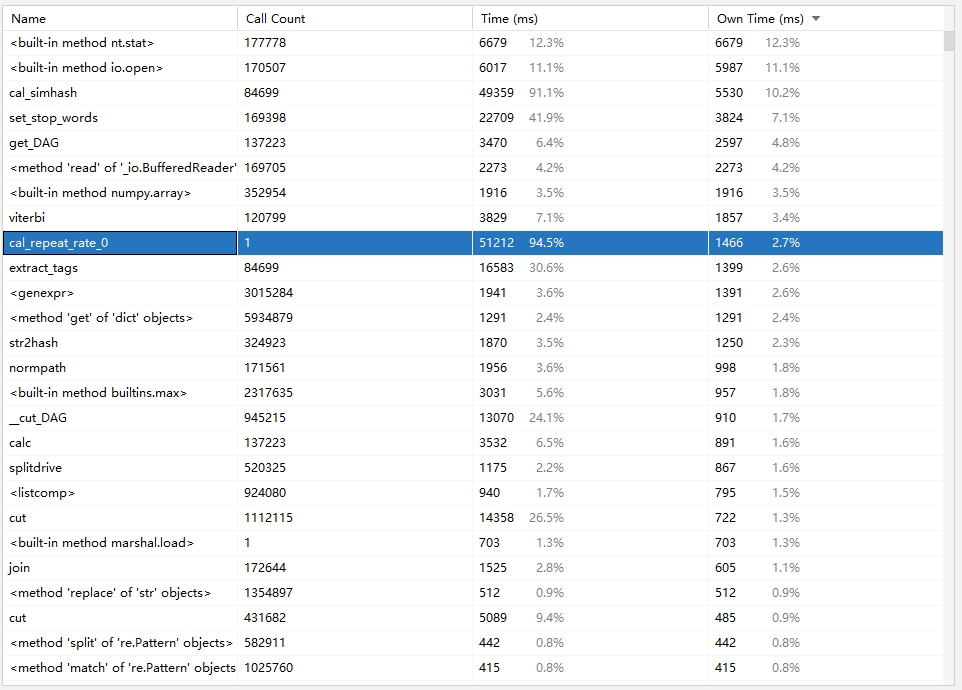
这是改进算法前的性能表
这是改进算法后的性能表
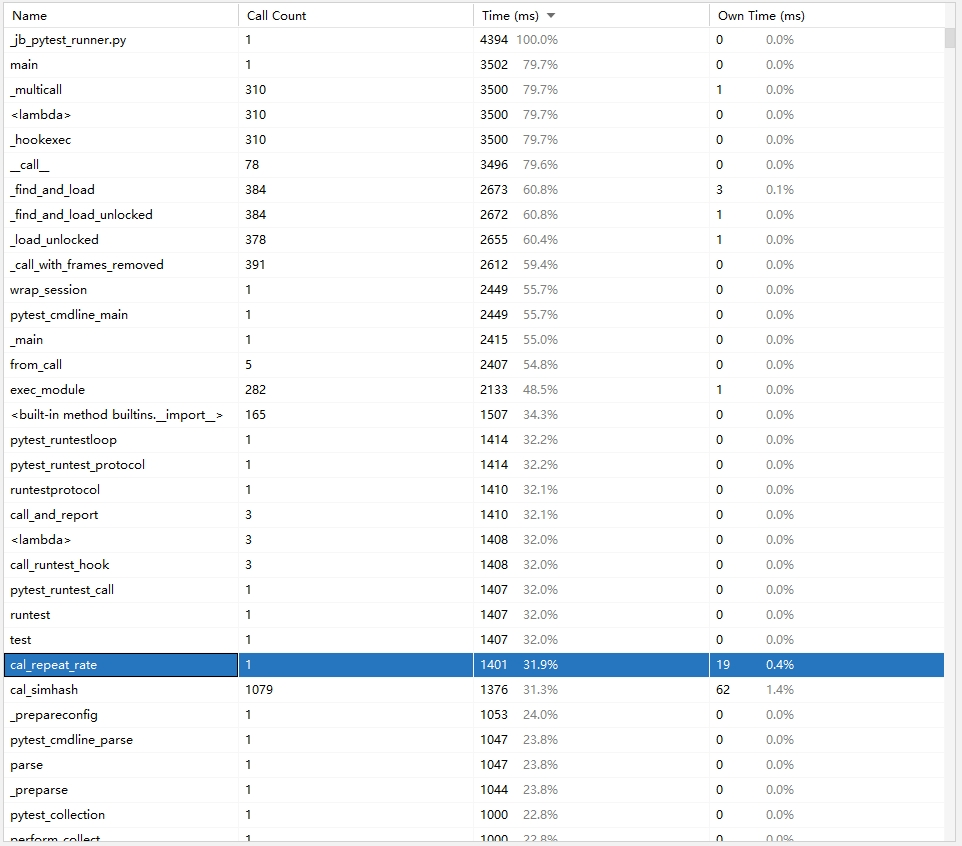
可以看到,改进算法后,性能有了明显的提高,免除了不必要的计算量以及使用矩阵运算后,性能提高了至少一百倍
个人项目总结
学习到的东西
通过本次个人项目,我学习到了一些平时课堂上学不到的东西:
- 文档的编写,作为一个程序员,我们要做好的事情不仅仅是编写代码,还包括写好一份开发文档。在这次项目中,我通过查找网上的资料以及参考 GitHub 上一些比较规范的项目的文档,学习了各种开发文档的规范编写,诸如模块说明文档、接口文档、设计文档、需求文档等,并尝试亲手完成一份规范的开发文档
- Python 代码的规范书写,在 PSP 过程中,有要求对开发代码进行规范,为此,我查找了各种 Python 代码的规范文档。最后参考了 PEP8 编码规范和 Google 的Python 代码规范,并结合自己项目的实际情况,制定了一系列代码规范,并将代码规范写成规范文档
- Git 管理工具的使用,虽然这个工具在之前参与项目的时候有使用过,但这次个人项目中,我通过查找网上的资料,也制定了一系列签入规范(如提交时应该注明本次提交的性质)
- 学习了 SimHash 算法以及如何对算法进行改进
- 代码的测试,通过这次个人项目,我通过对自己项目的各种测试,我也学会了如何使用 Python 和 Pycharm 对代码进行测试,并将部分结果编写成测试文档
可以改进的地方
本次项目也有一些值得思考和改进的地方:
- 在设计方面,一些细节问题还未考虑清楚(如,文件管理模块与计算模块的数据流通形式),在编码过程中才逐步完善,主要原因还是编程经验上的不足,改进的方法如下:
- 通过以后的一些编程练习,增强代码的熟练程度
- 通过建立问题跟踪文档,将暂时解决不了的问题记录下来,通过后期与他人讨论或者查阅资料解决问题
- 在测试方面,做得还不够规范,对一些性能方面的细节还没有过多测试,改进方法:
- 可以通过查阅一些资料以及书籍来学习一些测试方法
- 可以学习一些 Python 语言的测试工具,来做到更好的测试