一.什么是模块(一组功能的集合)
1.你要和某个东西打交道,而这个东西本身和python没有关系,这个东西本身就存在python提供了一个功能的集合 专门负责和这个东西打交道
2.模块实际上就是给我们提供功能
3.模块只不过是python提供给我们去操作这个内容的方法
二.模块的类型
1.内置模块: 不需要我们自己安装的 解释器自带的
2.第三方模块: 需要我们自己去安装的模块
3.自定义模块: 我们自己写的模块
三常用的模块:
1.re模块 在Python中使用正则表达式的规则时所调用的方法
1.1在python中使用正则表达式的特点和问题
1.1.1查找;


(1)findall:匹配所有 每一项都是列表中的元素 ret = re.findall("d", 'sjkhk172按实际花费928') #参数: 正则表达式,带匹配的字符串,flag print(ret)
search: 只匹配从左到右的第一个,得到的不是直接的结果,而是一个变量,通过这个变量的group方法获取结果. 如果没有匹配到,会返回None,使用group会报错 ret = re. search("d",'sjkhk172按实际花费928') print(ret) #内存地址,这是一个正则匹配的结果 print(ret.group()) #通过ret.group()获取真正的结果 ret = re. search("d","sjsdnvJHUIGdskd") print(ret) #ret 是None print(ret.group()) # 会报错 #search的常用方式 ret = re. search("d",'172sjkhk按实际花费928') if ret: #ret.内存地址,这是一个正则匹配的结果 print(ret.group()) #通过ret.group()来获取真正的结果
match: 从头开始匹配,相当search中的正则表达式加一个^ ret =re. match("d",'172sjkhk按实际花费928') print(ret) #内存地址
1.1.2字符串的扩展:替换,切割(使用正则表达式)
s = 'alex83taibai40egon25' ret = re.split("d+",s) print(ret)
sub #旧的 新的 谁 替换的次数 ret = re.sub("d","H","alex83taibai40egon25") print(ret) ret = re.sub("d","H","alex83taibai40egon25",1) print(ret)
subn:返回一个元祖,第二个元素是替换的次数 ret = re.subn("d","H","alex83taibai40egon25") print(ret)
1.2 re模块的进阶:时间,空间
compile 节省你使用正则表达式解决问题的时间
编译 把正则表达式 编译成 字节码
优点: 在多次使用的过程中,不会多次编译
ret= re.compile("d+") #已经编译完了 print(ret) res = ret.findall('alex83taibai40egon25') print(res) res = ret.search('alex83taibai40egon25') print(res.group())
finditer :节省你是用正则表达式解决问题的空间/内存
ret = re. finditer("d",'alex83taibai40egon25')
# ret :返回一个迭代器,所有的结果都在这个迭代器中,需要通过循环+group的形式取值 能够节省内存
for i in ret:
print(i.group())
1.3分组在re模块中的使用
1.3.1分组在search中的应用
import re s = '<a>wahaha</a>' # 标签语言 html 网页 ret = re.search('<(w+)>(w+)</(w+)>',s) print(ret.group())#没有参数或者参数是零时,取所有结果 print(ret.group(1))#数字参数所代表的结果是取对应分组中的内容 print(ret.group(2)) print(ret.group(3))
1.3.2为了findall也可以顺利取到分组中的内容,有一个特殊的语法,就是优先显示分组中的内容
import re s = '<a>wahaha</a>' ret = re.findall("(w+)",s) print(ret) ret = re.findall(">(w+)<",s) print(ret) #取消分组优先(?:正则表达式)#当想成为一组集合而不想优先选择时 ret = re.findall("d+(?:.d+)?", "1.234*4") print(ret)
注意:分组在正则表达式中形成一组集合,在Python中表示优先显示
关于分组
对于正则表达式来说 有些时候我们需要进行分组,来整体约束某一组字符出现的次数
(.[w]+)?
对于python语言来说 分组可以帮助你更好更精准的找到你真正需要的内容
<(w+)>(w+)</(w+)>
1.3.3分组在split的应用
#分组可以让用来切割的数据保留下来 ret = re.split('d+','alex83taibai40egon25') print(ret) #['alex', 'taibai', 'egon', ''] ret = re.split('(d+)','alex83taibai40egon25') print(ret) #['alex', '83', 'taibai', '40', 'egon', '25', '']
1.4分组命名(?P<组名>正则表达式)
s = '<a>wahaha</a>' ret= re. search(">(?p<con>w+)<",s) print(ret.group(1)) print(ret.group("con"))
#判断标签是否是一对标签,如<a>...</a>,<b>...</b> import re s = '<a>wahaha</a>' pattern = "<(w)+>(w+)</(w+)>" ret = search(pattern,s) print(ret.group(1)==ret.group(3)) #当是一对标签时输出True,当不是一对标签时输出False
#使用前面的分组 要求使用这个名字的分组和前面同名分组中的内容匹配的必须一致 pattern = '<(?P<tab>w+)>(w+)</(?P=tab)>' ret = re.search(pattern,s) print(ret)
2.常用模块:random模块(取随机数)
import random #导入模块 #随机取小数 random.random()#取大于0小于1的小数 0.7664338.. random.uniform(1,3)#取大于1小于3的小数 1.62758.. #随机取整数 random.randint(1,5)取大于等于1小于等于5之间的整数(顾头顾尾) random.randrange(1,10,2)#取大于等于1,小于10之间的奇数(顾头不顾尾) #随机取列表中的元素(1个返回值) random.choice([1,"23",[4,5]])#1或者23或者[4,5]
#随机取列表中的元素多个(多个返回值)
random.sample([1,'23',[4,5]],2)#列表中的元素任意两个组合
#打乱列表的顺序(打乱一个列表的顺序,在原列表的基础上直接进行修改,节省空间) item = [1,3,5,7,9] random.shuffle(item)#打乱次序 print(item) [5,1,3,7,9]
3.时间模块
和时间有关的我们就要用时间模块.
3.1常用方法
1.time.sleep(sece) (线程)推迟指定的时间运行.单位为秒 2.time.time() 获取当前时间戳
3.2表示时间的三种方式
(1)时间戳(timestamp):通常来说,时间戳表示是从1970年1月1日00:00:00开始按秒计算的偏移量,我们运行type(time.time()),返回的是float类型
(2)格式化时间字符串(Format String):"199-12-6"
%y:两位数的年份 %Y:四位数的年份 %m:月份 %d:日 %H 24小时制小时数 %I 12小时制小时数 %M 分钟数 %S 秒
(3)元组(struct_time):struct_time元组共有九个元素(年,月,日,时,分,秒,一周中的第几天,一年中的第几天)
| 索引(Index) | 属性(Attribute) | 值(Values) |
| 0 | tm_year(年) | 2011 |
| 1 | tm_mon(月) | 1-12 |
| 2 | tm_mday(日) | 1-31 |
| 3 | tm_hour(时) | 0-23 |
| 4 | tm_min(分) | 0-59 |
| 5 | tm_sec(秒) | 0-60 |
| 6 | tm_wday(weekday) | 0-6(0表示周一) |
| 7 | tm_yday(一年中的第几天) | 1-366 |
| 8 | tm_isdst(是否夏令时) | 默认为0 |
#导入时间模块 >>>import time #时间戳 >>>time.time() 1500875844.800804 #时间字符串 >>>time.strftime("%Y-%m-%d %X") '2017-07-24 13:54:37' >>>time.strftime("%Y-%m-%d %H-%M-%S") '2017-07-24 13-55-04' #时间元组:localtime将一个时间戳转换为当前时区的struct_time time.localtime() time.struct_time(tm_year=2017, tm_mon=7, tm_mday=24, tm_hour=13, tm_min=59, tm_sec=37, tm_wday=0, tm_yday=205, tm_isdst=0)
小结:时间戳是计算机能够识别的时间;时间字符串是人能够看懂的时间;元组则是用来操作时间的
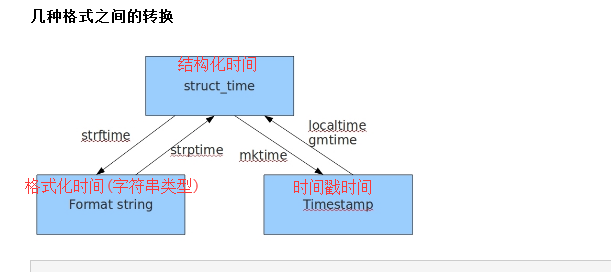
#时间戳-->结构化时间 #time.gmtime(时间戳) #UTC时间,与英国伦敦当地时间一致 #time.localtime(时间戳) #当地时间。例如我们现在在北京执行这个方法:与UTC时间相差8小时,UTC时间+8小时 = 北京时间 >>>time.gmtime(1500000000) time.struct_time(tm_year=2017, tm_mon=7, tm_mday=14, tm_hour=2, tm_min=40, tm_sec=0, tm_wday=4, tm_yday=195, tm_isdst=0) >>>time.localtime(1500000000) time.struct_time(tm_year=2017, tm_mon=7, tm_mday=14, tm_hour=10, tm_min=40, tm_sec=0, tm_wday=4, tm_yday=195, tm_isdst=0) #结构化时间-->时间戳 #time.mktime(结构化时间) >>>time_tuple = time.localtime(1500000000) >>>time.mktime(time_tuple) 1500000000.0
#结构化时间-->字符串时间 #time.strftime("格式定义","结构化时间") 结构化时间参数若不传,则显示当前时间 >>>time.strftime("%Y-%m-%d %X") '2017-07-24 14:55:36' >>>time.strftime("%Y-%m-%d",time.localtime(1500000000)) '2017-07-14' #字符串时间-->结构化时间 #time.strptime(时间字符串,字符串对应格式) >>>time.strptime("2017-03-16","%Y-%m-%d") time.struct_time(tm_year=2017, tm_mon=3, tm_mday=16, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=3, tm_yday=75, tm_isdst=-1) >>>time.strptime("07/24/2017","%m/%d/%Y") time.struct_time(tm_year=2017, tm_mon=7, tm_mday=24, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=0, tm_yday=205, tm_isdst=-1)
注意: 求时间差时,要注意伦敦和北京的时间差
求时间差: import time true_time=time.mktime(time.strptime('2017-09-11 08:30:00','%Y-%m-%d %H:%M:%S')) time_now=time.mktime(time.strptime('2017-09-12 11:00:00','%Y-%m-%d %H:%M:%S')) dif_time=time_now-true_time struct_time=time.gmtime(dif_time) print('过去了%d年%d月%d天%d小时%d分钟%d秒'%(struct_time.tm_year-1970,struct_time.tm_mon-1, struct_time.tm_mday-1,struct_time.tm_hour, struct_time.tm_min,struct_time.tm_sec))