sed编辑器提供的一些更高级的功能;
1、多行命令
sed依据是行来进行数据处理,但是有时候我们需要对多行进行处理,该如何进行呢?
sed有3个命令用于多行处理:N,在数据流中添加下一行以创建用于处理的多行组;D,删除多行组中的单个行;P,打印多行组中的单个行。
1.1、next命令
1、单行next命令
next命令(n)修改了sed数据处理文本的方式(默认是一行一行处理的)

删除 header所在行的,下一行;
$ sed '/^$/d' data1 #删除所有的空白行
2、组合多行文本
N 将文本的下一行添加到已经存在于模式空间的文本中。其效果类似于将数据流中两个文本行合并,添加到同一个模式空间中。

将 回车 替换为 空格字符;
短语跨行出现的时候,如何替换?
1.2、多行删除命令
D用来删除文本内容。但是如果跨行删除,就需要结合 N 命令一起完成;
$ sed ' > N > /System Adminstrator/D > ' data3
删除第一行之前的空行示例:
$ sed '/^$/{ > N > /header/D > }' data5
1.3、多行打印命令
多行打印,N与P结合使用
$ sed -n ' > N > /System Administrator/P > ' data3
2、保留空间
pattern space模式空间是一个活动的缓冲区,它不是存储文本唯一可用空间。
sed编辑器利用另一个称为保留空间(hold space)的缓冲区。5个命令与其相关

$ cat data2 This is the header line. This is the first data line. This is the second data line. This is the last line. $ sed -n '/first/{ #选出first字符的行 > h #选出行,放入到保留空间中 > p #打印模式空间的内容 > n #检索下一行的内容,并放入到模式空间中 > p #打印模式空间的内容,现在的第二行内容 > g #保留空间的内容返回到模式空间中,替换当前文本 > p #打印模式空间的内容,它现在回到第一行数据 > }' data2 This is the first data line. This is the second data line. This is the first data line.
$ sed -n '/first/{ > h > n > p > g > p > }' data2 This is the second data line. This is the first data line.
3、否定命令
! 感叹号,表示否定。
$ -n '/header/!p' data2 This is the first data line. This is the second data line. This is the last line.
next命令中,sed编辑器不能对数据流中的文本的最后一行执行操作,因为最后一行没有下一行。可以使用感叹号修复这个问题:
$ sed '{ > !N > /System.Administrator/Desktop User/ > }' data4
还可以用于翻转数据文本的行的顺序。工作流程如下:
(1)将第一行放到保留空间中
(2)将文本的下一行放到模式空间中
(3)将保留空间最佳到模式空间中
(4)将模式空间放到保留空间
(5)重复第2步到第4步,直至将所有行以相反的顺序放到保留空间。
(6)检索行并打印它们。
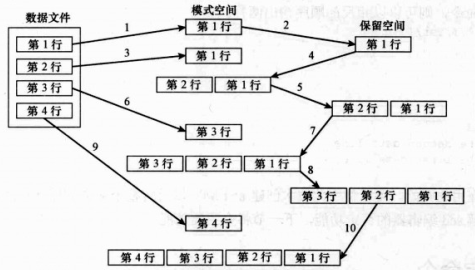
$ sed -n '{ > 1!G > h > $p > }' data2
4、更改命令流
默认sed命令从头运行到尾结束,但是有时候我们需要改变这个运行环境;
4.1、分支
一些命令容许我们只在数据流的特定自己上执行一组命令。分支命令格式:
[address]b [label]
address:决定在哪行或哪些行执行分支命令;
label:参数定义于何处分支。
$ sed '{ > 2,3b #跳过2,3两行为address > s/This is/Is this/ > s/line./test?/ > }' data2
$ sed '{ > /first/b jump1 #出现first字符,则跳转到以jump1为标记的行 > s/ is/ might be/ > s/line/test/ > :jump1 > s/data/text/ > }' data2
sed脚本根据后面标签情况,还可以分支到出现在脚本前面的标签,这样创建一个循环效果:
$ echo "This, is, a, test, to, remove, commas." | sed -n '{ > :start > s/,//1p > b start > }'
4.2、测试
t 命令用作测试。使用格式:
[address]t [label]
与分支类似,如果不指定标签,则测试成功时sed将分支到脚本的最后。
如果在另一个替换成功时不需要再执行替换,则测试命令可以帮忙:
$ sed '{ > s/first/starting/ > t > s/line/test/ > }' data2
通过测试命令改进分支死循环
$ echo "This, is, a, test, to, remove, commas." | sed -n '{ > :start > s/,//1p > t start > }'
5、模式替换
如果想要给一行中匹配上的单词加上双引号。如果只在模式中查找一个单词,name这非常容易
$ echo "The cat sleeps in his hat." | sed 's/cat/"cat"/'
但是如果在模式中使用通配符以匹配多个单词会产生如下结果
$ echo "The cat sleeps in his hat." | sed 's/.at/".at"/g'
这样看起来是行不通的。
5.1、与号
& 号 用于替换命令中的匹配模式。无论什么文本匹配上定义的模式,都可以使用与号在替换模式中调用它。这容许处理与定义的模式匹配的任何单词;
$ echo "The cat sleeps in his hat." | sed 's/.at/"&"/g'
5.2、替换个别单词
sed 编辑器使用圆括号定义替换模式中的子字符串元素。然后再替换模式中使用特定的符号来引用子字符串元素。替换字符由反斜杠和数字组成。数字表示子字符串元素的位置。sed编辑器将第一个元素分配为字符1,第二个元素分配成字符2,以此类推;
$ echo "The System Adminstrator manual" | sed '
> s/(System) Administrator/1 User/'
The System User manual
如果需要以单个单词(短语的子集)替换一个短语,而子字符串有正好使用了通配符,则最好使用子字符串元素:
$ echo "That furry cat is pretty" | sed 's/furry (.at)/1/'
$ echo "That furry cat is pretty" | sed 's/furry (.at)/1/'
在这种情况下,不能使用 与号 ,因为它替换整个匹配的模式。子字符串元素提供了答案,它容许将模式的摸个部分用作替换模式;
这样的话,在需要将文本插入到两个或多个子字符串元素时,这一功能特别有用。下面是使用子字符串元素在长数字中插入逗号的示例脚本;
$ ehco "1234567" | sed '{ > :start > s/(.*[0-9])([0-9]{3})/1,2/ > 5 start > }' 1,234,567
6、脚本中使用sed
6.1、使用包过滤器
我们需要将sed编辑命令放到shell脚本包装器(wrapper)中,包装器就像是sed编辑器脚本和命令行之间的媒介。
#!/bin/bash # shell wrapper for sed editor script to reverse lines sed -n '{ 1!G h $p }' "$1" $
翻转数据流的脚本;
6.2、重定向sed输出
默认情况下,sed编辑器将脚本的结果输出到STDOUT。下面的示例展示了使用sed编辑器为数字计算的结果添加逗号。
#!/bin/bash # add commas to numbers in factorial answer factorial=1 counter=1 number=$1 while [ $counter -le $number ] do factorial=$[ $factorial * $counter ] counter=$[ $counter + 1 ] done result='echo $factorial | sed '{ s/(.*[0-9])([0-9]{3})/1,2/ t start }' ' echo "The result is $result"
$ ./fact 20 The result is 2,432,902,008,176,640,000
7、创建sed工具
这一小节,我们总结一些便利和广泛使用的sed编辑脚本。
7.1、双倍行距
在文件中添加空行
$ sed 'G' data2 #G命令指示单纯的保留空间的内容追加到模式空间的内容。 This is the header line. This is the first data line. This is the second data line. This is the last line.
$
去掉最后一个空行
$ sed '$!G' data2 This is the header line. This is the first data line. This is the second data line. This is the last line. $
7.2、对可能有空行的文件使用双倍行距
如果原本就具有空行了,在都加入空行,原本有空行的依然多一行($!G);
解决方式就是先从数据流中删除空行,然后使用G命令在所有行后插入新的空行;
$ sed '/^$/d;$!G' data6 #/^$/d 删除空行
7.3、对文件中的行计数
$ sed '=' data #显示行号
但是这样行号和内容在不同行,这时候,我们要将它分在一行
$ sed '=' data2 | sed 'N; s/ / /' #s/ / / 替换 换行符,为空格,N表示跨行处理;
7.4、打印最后几行
p为打印命令,如果向查看最后几行,如何查看;
最后一行的查看方法:
$ sed -n '$p' data2 This is the last line.
打印最后几行,通过N和D命令的循环来解决这个问题;
$ sed '{ > :start > $q > N > l1,$D > b start > }' /etc/passwd
7.5、删除行
1、删除连续空行
/./,/^$/!d #范围是/ ./到/^$/。范围中的起始地址匹配任何包含至少一个字符的行。范围中的结束地址匹配一个空行。位于此范围的行不会被删除;
$ cat data6 This is the first line. This is the second line. This is the third line. This is the fourth line. $ sed '/./,/^$/!d' data6 This is the firest line. This is the second line. This is the third line. This is the fourth line.
2、删除开头空行
从数据流的开头删除空行并不是一个困难的任务。
/./,$!d
简单的脚本实例
$ sed '/./,$!d' data7 #删除开头空格行
3、删除结尾的空行
sed '{ :start /^ *$/{$d; N; b start } #找到最后一行,则删除,不是最后一行用N命令追加到其下一行 }'
$ sed '{ :start /^ *${$d ; N; b start} }' data8
这样就可以删除最尾部的空白行
7.6、删除HTML标记
下面是一个标准的HTML页面文件
$ cat data9 <html> <head> <title>This is the page title</title> </head> <body> <p> This is the <b>first</b> line in the Web page. This should provide some <i>useful</i> information for us to use in our shell script. </body> </html>
s/<.*>//g #这样去替换就去掉了<b><i>的作用;
我们可以创建一个字符类,让它否定大于号。
s/<[^>]*>//g
脚本可以正常工作,即显示需要从Web页面HTML代码查看的数据:
$ sed 's/<[^>]*>//g' data9
现在就好多了,要使输出更加简洁,可以添加一个删除命令来删除多余的空行。
$ sed 's/<[^>]*>//g;/^$/d' data9 #删除命令,删除多余行