协方差矩阵——PCA的关键。
PCA的目的就是“降噪”和“去冗余”。“降噪”的目的就是使保留下来的维度间的相关性尽可能小,而“去冗余”的目的就是使保留下来的维度含有的“能量”即方差尽可能大。那首先的首先,我们得需要知道各维度间的相关性以及个维度上的方差!那有什么数据结构能同时表现不同维度间的相关性以及各个维度上的方差呢?自然是非协方差矩阵莫属。回忆下《浅谈协方差矩阵》的内容,协方差矩阵度量的是维度与维度之间的关系,而非样本与样本之间。协方差矩阵的主对角线上的元素是各个维度上的方差(即能量),其他元素是两两维度间的协方差(即相关性)。我们要的东西协方差矩阵都有了,先来看“降噪”,让保留下的不同维度间的相关性尽可能小,也就是说让协方差矩阵中非对角线元素都基本为零。达到这个目的的方式自然不用说,线代中讲的很明确——矩阵对角化。而对角化后得到的矩阵,其对角线上是协方差矩阵的特征值,它还有两个身份:首先,它还是各个维度上的新方差;其次,它是各个维度本身应该拥有的能量(能量的概念伴随特征值而来)。这也就是我们为何在前面称“方差”为“能量”的原因。也许第二点可能存在疑问,但我们应该注意到这个事实,通过对角化后,剩余维度间的相关性已经减到最弱,已经不会再受“噪声”的影响了,故此时拥有的能量应该比先前大了。看完了“降噪”,我们的“去冗余”还没完呢。对角化后的协方差矩阵,对角线上较小的新方差对应的就是那些该去掉的维度。所以我们只取那些含有较大能量(特征值)的维度,其余的就舍掉即可。PCA的本质其实就是对角化协方差矩阵.
PCA的本质是对角化协方差矩阵,目的是让维度之间的相关性最小(降噪),保留下来的维度的能量最大(去冗余)。
PCA简介以及模型
Web的发展产生了大量的数据,尤其是现在的互联网公司,集结了大量的用户信息。,怎样从这些复杂混乱的数据中提取有用的信息才是重点。我们举一个物理模型
如图所示:
当把一个弹簧球沿着X方向进行拉伸的时候,弹簧球会在X方向上进行来往复运动。假设我们有三个相机,用来描述弹簧球的运动轨迹,分别为CameraA(x,y,z),CameraB(x,y,z),CameraC(x,y,z),相机的摆放并不呈现正交。
感官上,如果以小球运动的平面作为XOY平面,我们可以最大限度的描述小球的运动轨迹,毕竟小球只是在X方向上进行往返运动,可是在相机A,B,C中却会对同一时刻的小球位置产生三个不同的描述,这是因为三个相机有不同的坐标系,因此,如何从三个相机中产生的冗余数据进行去除,得到最佳的描述小球运动轨迹的信息,正是PCA的功劳。
线性代数中对PCA这样进行描述:PCA的目标就是用另一组基去重新描述得到的数据空间,而新的基要尽可能的描述原有数据间的关系,简单总结:一方面要体现出最主要的特征,另一方面要区分开主要特征和次要特征的差距。上面的例子中,沿着X轴进行运动无疑是最主要的特征,也就是我们所说的“主元”。那么怎样才能最好的表示原数据呢?无疑是选择最好的基,那怎样的基才是最好的基呢?关于基的概念,线性代数给出这样的描述:
在线性空间V中,如果存在n个元素a1,a2,a3,...,an,满足
(1)a1,a2,a3,...,an线性无关
(2)V中的任何元素都可以用a1,a2,a3,...,an进行描述
PCA进行坐标基变换的原则是:
(1)主元轴拥有最大的方差,次元轴拥有次级大的方差......
(2)坐标基的相关性为0(其实根据基的基本概念,只要是基的话就已经是线性无关的)
1. 去噪声
线性系统中,我们用”信噪比“来描述噪声的大小,通常,变化大的被认为是噪声,而变化小的被认为是信号,而变化的快慢使用方差来描述的。
当坐标轴和椭圆的长短轴平行,那么代表长轴的变量就描述了数据的主要变化,而代表短轴的变量就描述了数据的次要变化。但是,坐标轴通常并不和椭圆的长短轴平行(这点在下面的图C中也有体现)。由于C中的水平坐标和垂直坐标都是以(x1,x2)作为坐标系的,如果我们以x1,x2作为坐标轴,将F1,F2投影到x1,x2坐标轴上并不能获得描述对象的最大方差,。因此,需要寻找椭圆的长短轴,并进变换,使得新变量和椭圆的长短轴平行。这个过程叫做去噪声!
2. 去冗余
(从左向右分别为a,b,c)
如图所示:(a)的长轴和短轴方向上的方差基本大小一致,因此,相关性越低,冗余度越小,(c)次之,而(b)的短轴方向上数据分布高度集中,因此方差非常小,短轴上的坐标可以用长轴进行线性表示(考虑一下y = kx+b,我们可以将坐标表示为(x,kx+b),此时,长轴包含了数据的大部分信息,可以用长轴代替原先用长轴和短轴这两个轴进行描述。这已经就是将二维降低到一维!椭圆的长短轴差距越大,我们就越有把握说长轴代表了大部分的信息)。对于高维的情况,和二维的情况一致,如果是一个N维的椭球(抱歉我们大脑中无法构建出这个场景),我们首先找到描述它的N个正交基,保留下最能代表其特征的前N个正交基作为变量,这样就完成了降低维度的过程。
正如二维椭圆有2个主轴,3维椭球有3个主轴,N维椭形有N个主轴,有几个变量,就有几个主成分,另外,通常情况下所选的主轴的数目是所有主轴数目的85%。
数学建模
假设有N个样本,每个样本用X中的列表示,其中,P代表的是特征的数目,我们的目的是降低P的数目,以便用较少的特征数目来描述X的特征。
(1)协方差:
整个PCA里面,为什么要用协方差矩阵来计算PCA,这才是PCA计算的关键。
协方差(Covariance)在概率论和统计学中用于衡量两个变量的总体误差。而方差是协方差的一种特殊情况,即当两个变量是相同的情况。
-
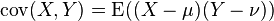 ,
, -
 ,
, - 当X与Y相互独立时
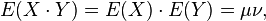
(2)协方差矩阵
在统计学与概率论中,协方差矩阵是一个矩阵,其每个元素是各个向量元素之间的协方差。这是从标量随机变量到高维度随机向量的自然推广。
假设 是以
是以 个标量随机变量组成的列向量,
个标量随机变量组成的列向量,
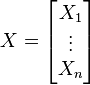
并且 是其第i个元素的期望值,即,
是其第i个元素的期望值,即, 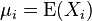 。协方差矩阵被定义的第i,j项是如下:
。协方差矩阵被定义的第i,j项是如下:

即:
![\Sigma=\mathrm{E}
\left[
\left(
\textbf{X} - \mathrm{E}[\textbf{X}]
\right)
\left(
\textbf{X} - \mathrm{E}[\textbf{X}]
\right)^\top
\right]](http://upload.wikimedia.org/math/1/8/1/1811f942680a72974597be42c28d31d2.png)
![=
\begin{bmatrix}
\mathrm{E}[(X_1 - \mu_1)(X_1 - \mu_1)] & \mathrm{E}[(X_1 - \mu_1)(X_2 - \mu_2)] & \cdots & \mathrm{E}[(X_1 - \mu_1)(X_n - \mu_n)] \\ \\
\mathrm{E}[(X_2 - \mu_2)(X_1 - \mu_1)] & \mathrm{E}[(X_2 - \mu_2)(X_2 - \mu_2)] & \cdots & \mathrm{E}[(X_2 - \mu_2)(X_n - \mu_n)] \\ \\
\vdots & \vdots & \ddots & \vdots \\ \\
\mathrm{E}[(X_n - \mu_n)(X_1 - \mu_1)] & \mathrm{E}[(X_n - \mu_n)(X_2 - \mu_2)] & \cdots & \mathrm{E}[(X_n - \mu_n)(X_n - \mu_n)]
\end{bmatrix}](http://upload.wikimedia.org/math/a/1/2/a12a573ecd1d853abd8c01fab9fccfbe.png)
所以协方差矩阵一定是对角阵。维度为元素对象的个数
(考虑一下:Matlab里面怎么计算两个矩阵的相关性?)
代码实现
实现过程如下:
(1)去除平均值,计算协方差
(2)根据协方差矩阵计算特征值和特征向量
(3)将特征值进行有大到小排列,保留所有特征值中的前N个特征值,并或者其对应的特征向量
(4)将获得的N个特征向量映射到新的空间
Matlab代码实现http://www.cnblogs.com/tornadomeet/archive/2012/12/30/2839615.html:
function [Y,V,E,D] = pca(X) % do PCA on image patches % % INPUT variables: % X matrix with image patches as columns % % OUTPUT variables: % Y the project matrix of the input data X without whiting % V whitening matrix % E principal component transformation (orthogonal) % D variances of the principal components %去除直流成分 X = X-ones(size(X,1),1)*mean(X); % Calculate the eigenvalues and eigenvectors of the new covariance matrix. covarianceMatrix = X*X'/size(X,2); %求出其协方差矩阵 %E是特征向量构成,它的每一列是特征向量,D是特征值构成的对角矩阵 %这些特征值和特征向量都没有经过排序 [E, D] = eig(covarianceMatrix); % Sort the eigenvalues and recompute matrices % 因为sort函数是升序排列,而需要的是降序排列,所以先取负号,diag(a)是取出a的对角元素构成 % 一个列向量,这里的dummy是降序排列后的向量,order是其排列顺序 [dummy,order] = sort(diag(-D)); E = E(:,order);%将特征向量按照特征值大小进行降序排列,每一列是一个特征向量 Y = E'*X; d = diag(D); %d是一个列向量 %dsqrtinv是列向量,特征值开根号后取倒,仍然是与特征值有关的列向量 %其实就是求开根号后的逆矩阵 dsqrtinv = real(d.^(-0.5)); Dsqrtinv = diag(dsqrtinv(order));%是一个对角矩阵,矩阵中的元素时按降序排列好了的特征值(经过取根号倒后) D = diag(d(order));%D是一个对角矩阵,其对角元素由特征值从大到小构成 V = Dsqrtinv*E';%特征值矩阵乘以特征向量矩阵
Python代码:
参考:文件