编译过程概述
-
词法分析
-
语法分析
-
语义分析
-
中间代码生成
-
中间代码优化
-
目标代码生成
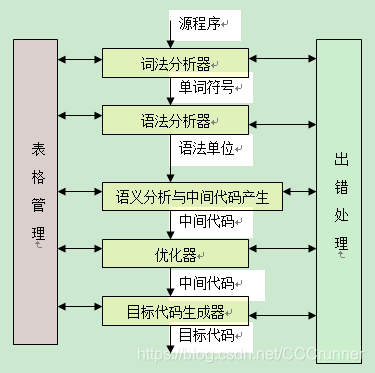
源程序–>前端–>中间代码–>后端–>目标代码
单词,具有语义的最小字符串
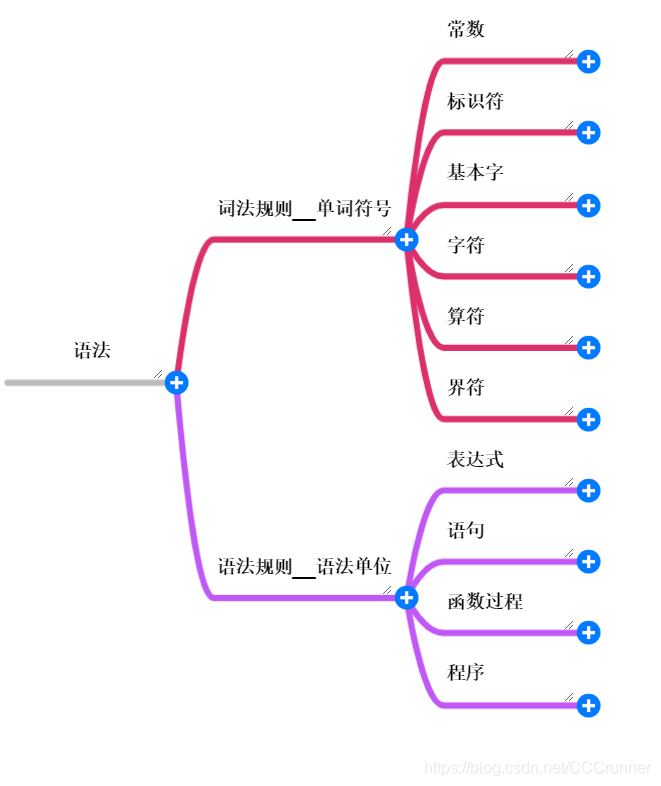
概念: 词法分析器、语法分析器、正则表达式、NFA、DFA、词法单元、语法树算法:
-
正则表达式 转 NFA (词法分析)
-
NFA 转 DFA (词法分析)
-
最小化DFA状态数 (词法分析)
-
构造 LR0 语法 (语法分析)
-
构造 LR1 语法 (这一步只需要看,可以不用实现) (语法分析)
-
构造 LALR1 语法 (语法分析)
-
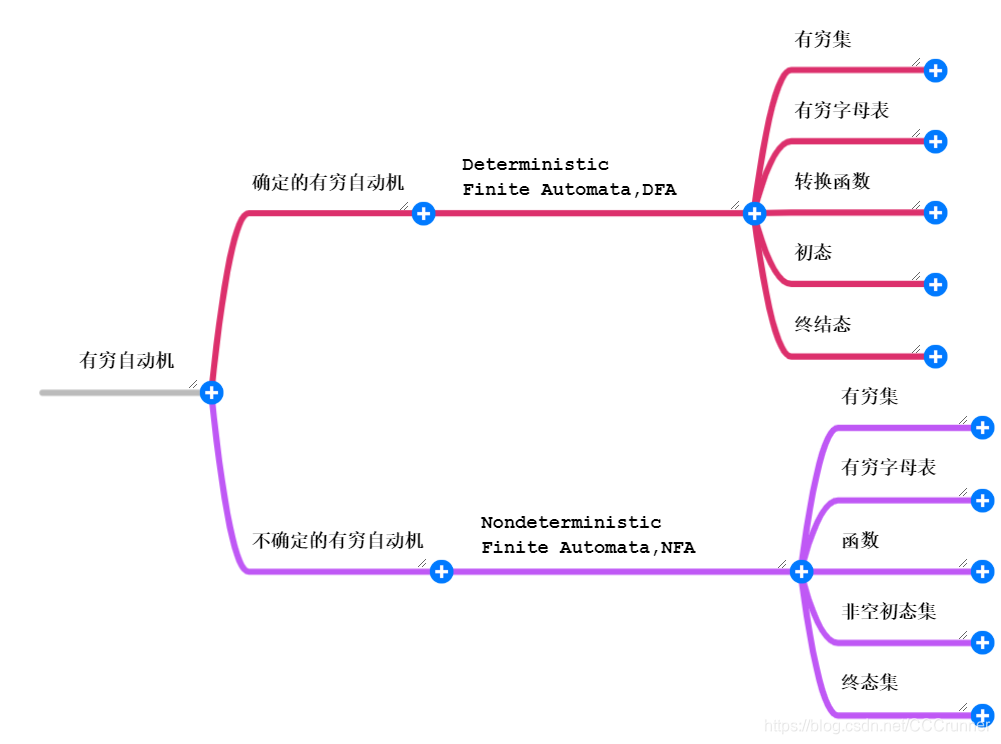
DFA与NFA特点比较
DFA特点:
-
初态唯一
-
输入字符不包括空符号串
-
有向边上只有一个字符
-
一个状态对某个字符最多只有一条出边
NFA特点:
-
初态不唯一
-
输入字符包括空符号串
-
有向边上可以为字符串
-
一个状态对某个字符可能有多条输出边,即状态的后继不唯一
- 文法:判断句子结构合法与否的依据
- 符号串:由字母表中的符号构成的任何有穷序列
- 空串:长度为0的符号串
- V*:V上所有符号串的集合
- 句子只由终结符构成
- 句型包含句子
- 若L(G)1=L(G2),则称文法G1和G2是等价的
0型文法 短语文法 图灵文法 α–>β ,α至少有非终结符
1型或上下文有关的文法 |α|<=|β|,S–>ε ,S不在右
2型或上下文无关的文法 α只能有一个非终结符
3型或正规文法 词法分析
如果再推导的任何一步α➜β,其中 α,β是句型,都是对α中最左(右)非终结符进行替换,则这种推导为最左(右)推导,最右推导被称为规范推导,由规范推导所得的句型成为右句型或规范句型 - 二义性:如果一个文法存在某个句子对应两颗不同的语法树,则说这个文法是二义的
- 回溯,发现有错误,就回退回去
- 句柄:一个右句型的直接短语
- 二元式:(单词种别,属性值)
LL1文法
L:从左向右扫描输入,
L: 产生最左推导
1:在每一步中需要向前看一个输入符号来决定语法分析动作
SDD是关于语言翻译的高层次规格说明,屏蔽了许多具体实现细节,使用户不必显式的说明翻译发生的顺序
SDT:可以看做对SDD的一种补充,是SDD的具体实施方案,显式的指明了语义规则的计算顺序,以便说明某些实现
中间代码
- 形式简单
- 语义明确
- 便于翻译
- 独立与目标语言