团队作业第六次—团队Github实战训练
团队名称: 云打印
作业要求: 团队作业第六次—团队Github实战训练
作业目标:搭建一个相对公平公正的抽奖系统,根据QQ聊天记录,完成从统计参与抽奖人员颁布抽奖结果的基本流程。
Github地址:Github地址
团队队员
| 队员学号 | 队员姓名 | 个人博客地址 | 备注 |
|---|---|---|---|
| 221600412 | 陈宇 | http://www.cnblogs.com/chenyuu/ | 队长 |
| 221600411 | 陈迎仁 | https://www.cnblogs.com/yinen/ | |
| 221600409 | 蔡森林 | https://www.cnblogs.com/csl8013/ | |
| 221600401 | 陈诗娴 | https://www.cnblogs.com/orangepoem/ | |
| 221600408 | 蔡鸿键 | https://www.cnblogs.com/jichiwoyaochi/ |
组员分工及组员贡献
| 队员学号 | 队员姓名 | 此次作业任务 | 贡献比例 |
|---|---|---|---|
| 221600412 | 陈宇 | 项目管理、后端代码的编写,服务器的部署 | 23% |
| 221600411 | 陈迎仁 | 后端逻辑模块的编写,聊天记录过滤的处理,博客文档的编写 | 21% |
| 221600401 | 陈诗娴 | 编写博客文档结构,前端美工设计 | 15% |
| 221600409 | 蔡森林 | 附加功能的实现,数据处理与挖掘、编写附加功能部分的博客文档 | 21% |
| 221600408 | 蔡鸿键 | 前端代码的编写与设计 | 20% |
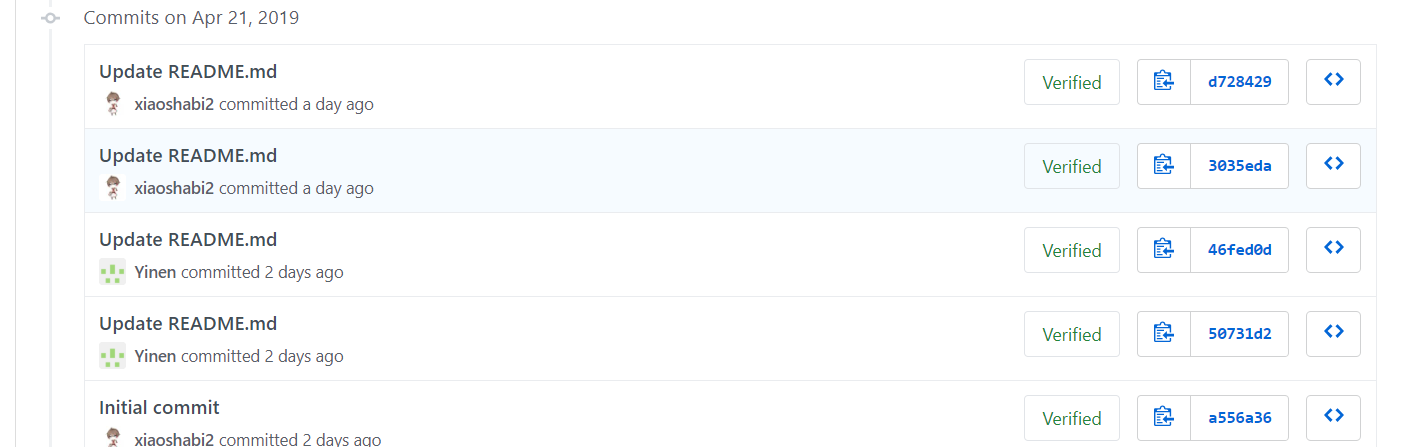
github 的提交日志截图
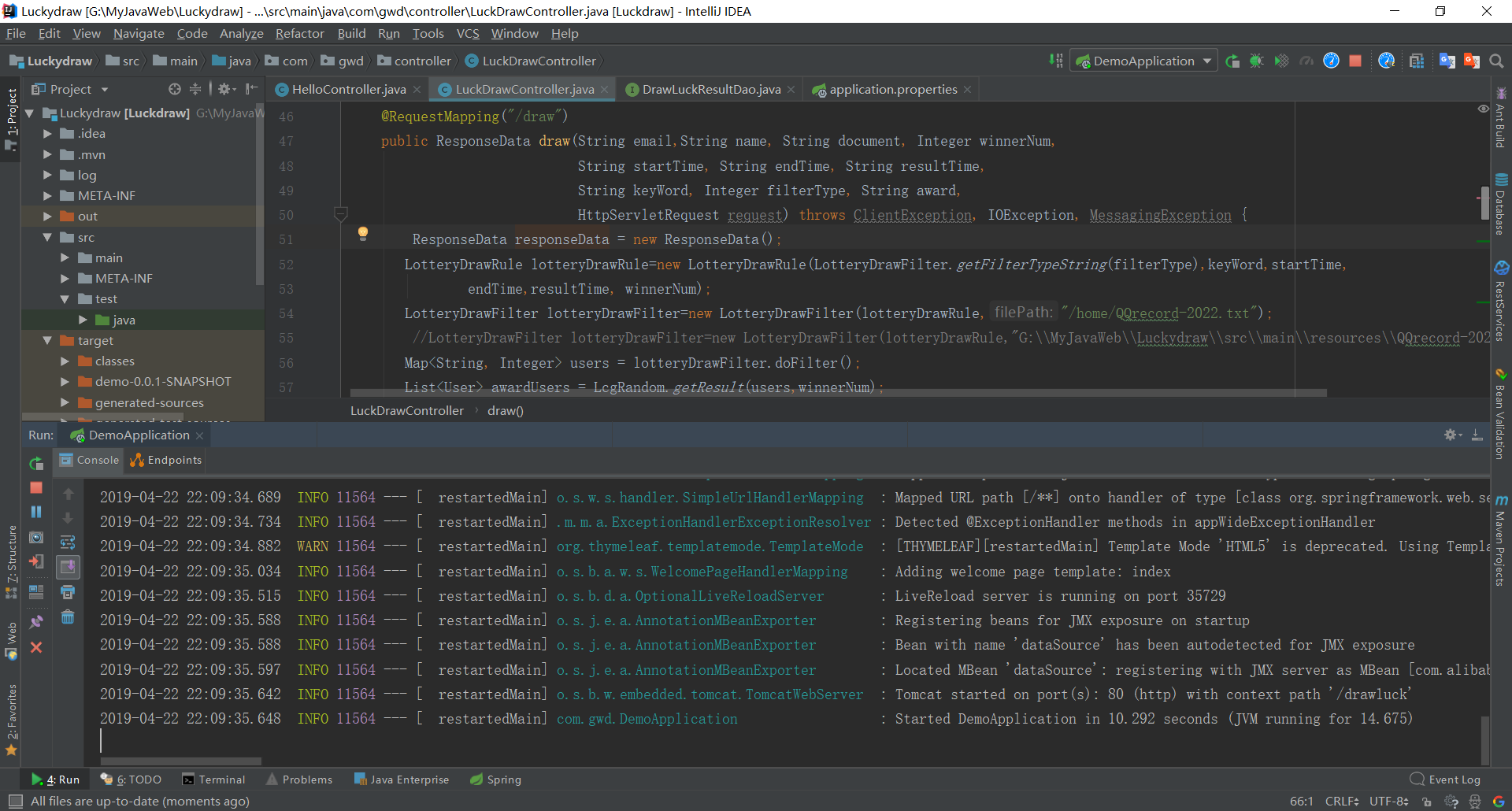
程序运行截图

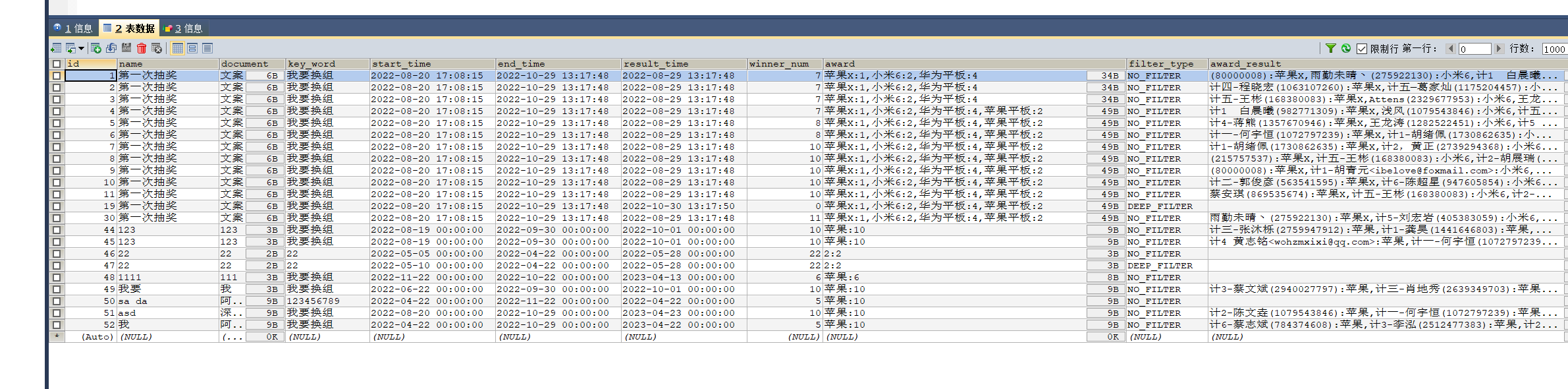
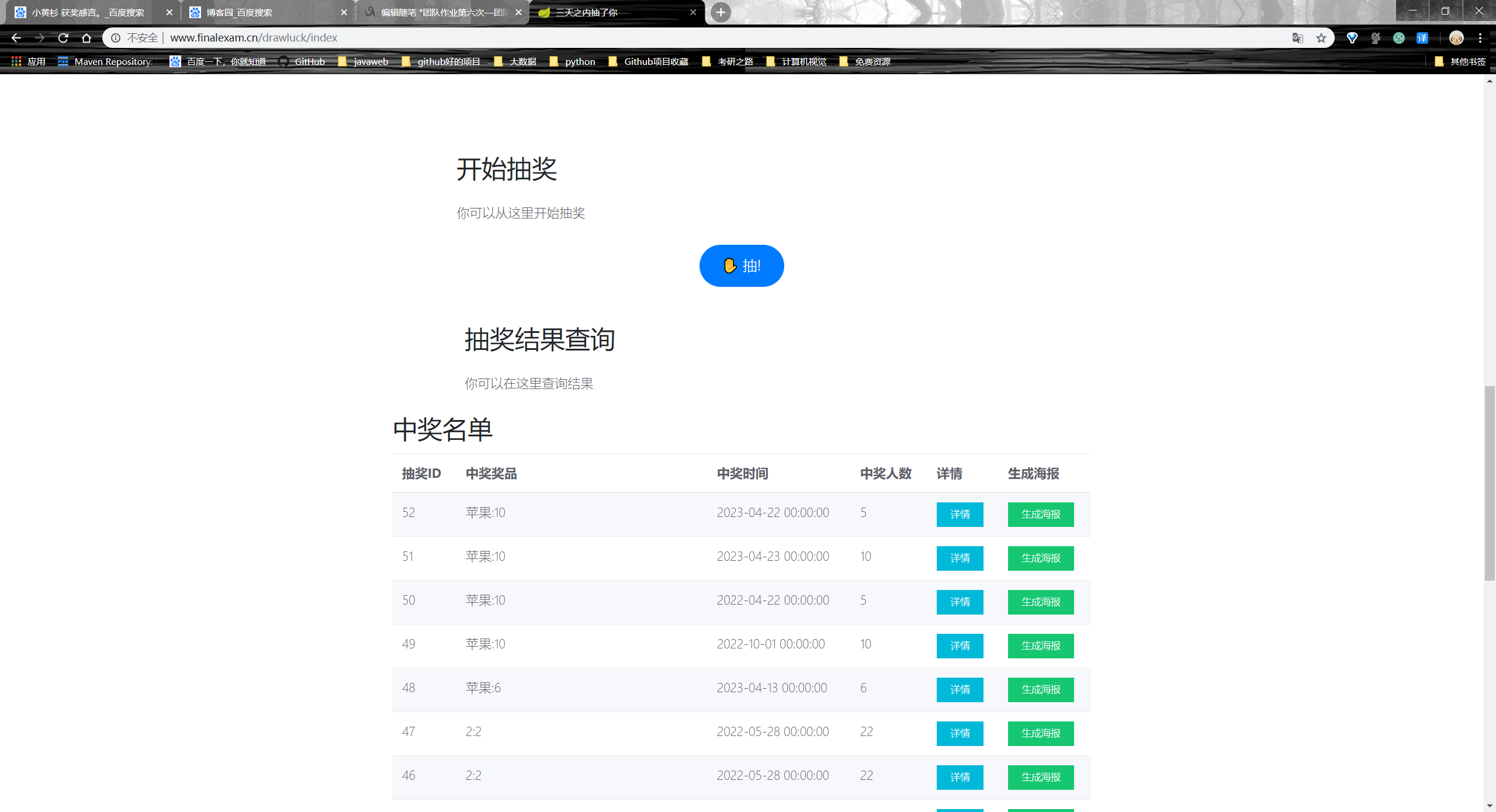
程序运行环境
-
本项目为web项目,搭载在阿里云服务器上,web访问链接为: 项目运行地址
-
前端:
开发工具为PhpStorm,开发语言为Ajax、js、css、HTML,框架为boostrap;运行环境为各类浏览器(谷歌浏览器、火狐浏览器、IE6以上的IE浏览器等)
- 后端
开发工具为IntelliJ IDEA Ultimate,开发语言为java,框架为boostrap;运行环境为java环境
GUI界面

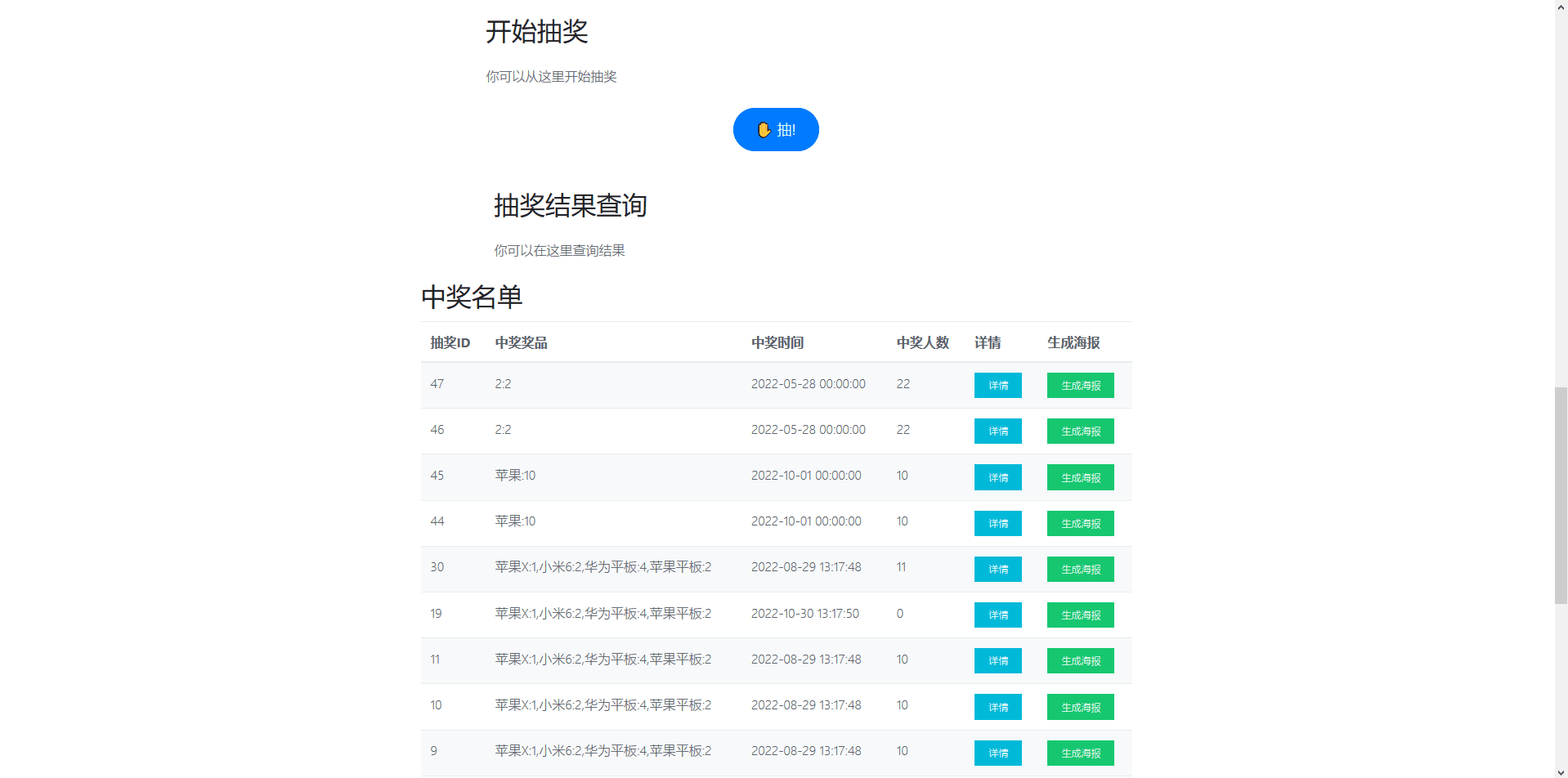
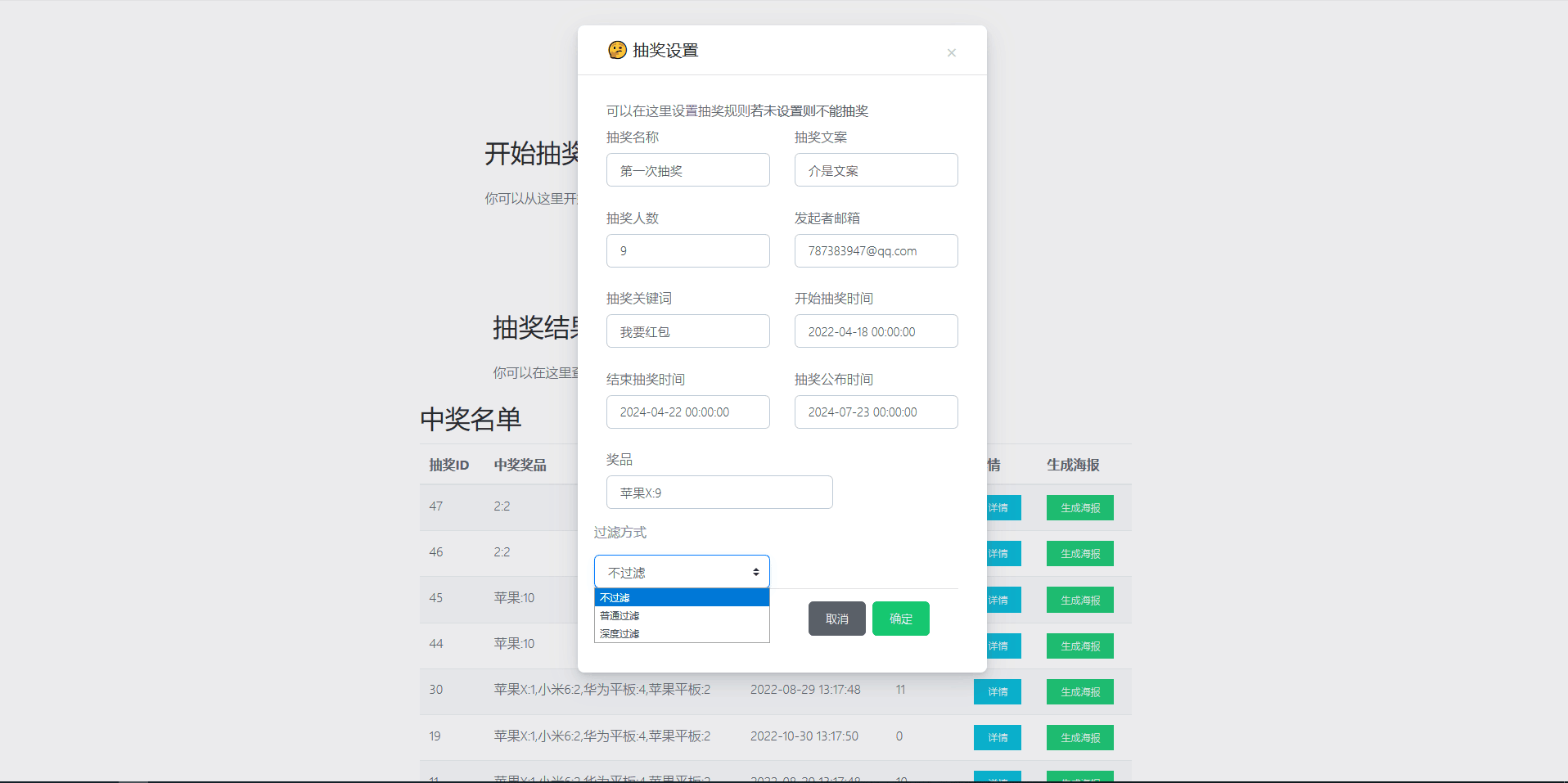
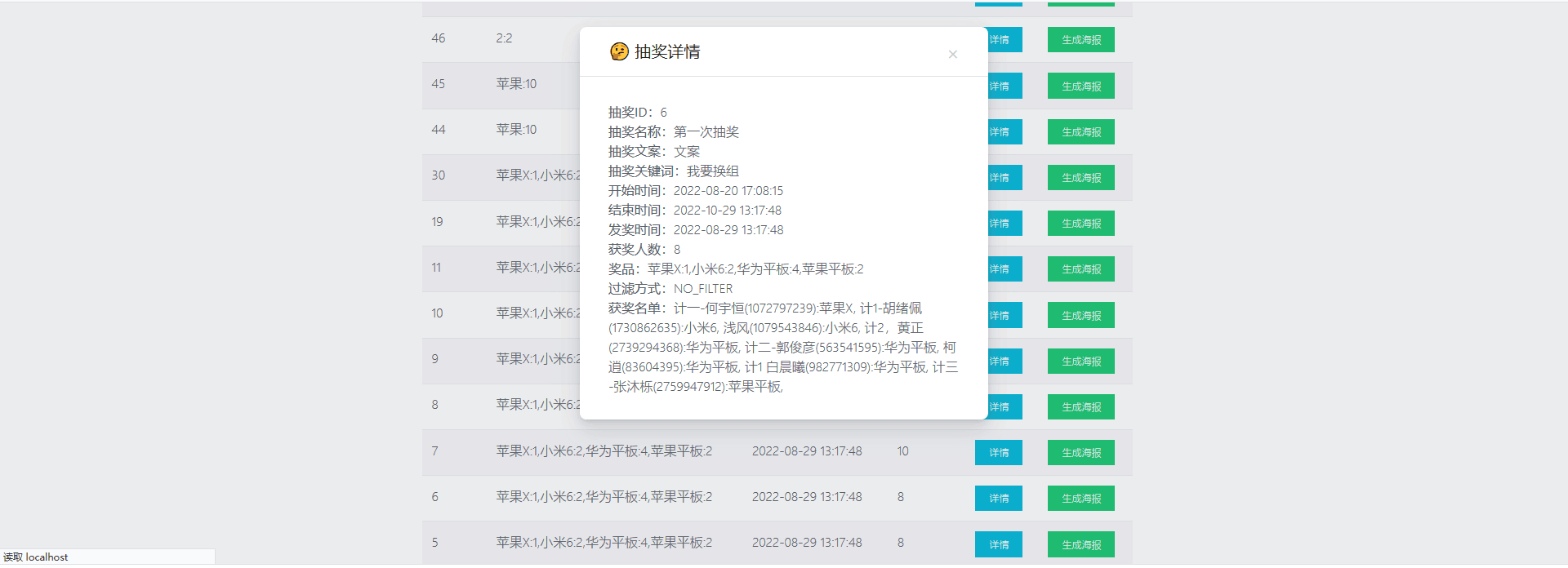

基础功能实现
基本功能实现的核心代码
- 抽奖
@RequestMapping("/draw")
public ResponseData draw(String email,String name, String document, Integer winnerNum,
String startTime, String endTime, String resultTime,
String keyWord, Integer filterType, String award,
HttpServletRequest request) throws ClientException, IOException, MessagingException {
ResponseData responseData = new ResponseData();
LotteryDrawRule lotteryDrawRule=new LotteryDrawRule(LotteryDrawFilter.getFilterTypeString(filterType),keyWord,startTime,
endTime,resultTime, winnerNum);
//LotteryDrawFilter lotteryDrawFilter=new LotteryDrawFilter(lotteryDrawRule,"/home/QQrecord-2022.txt");
LotteryDrawFilter lotteryDrawFilter=new LotteryDrawFilter(lotteryDrawRule,"G:\MyJavaWeb\Luckydraw\src\main\resources\QQrecord-2022.txt");
Map<String, Integer> users = lotteryDrawFilter.doFilter();
List<User> awardUsers = LcgRandom.getResult(users,winnerNum);
String str[] = award.split("\,");
int j = 0;
for(String s : str){
String awardName = s.split(":")[0];
Integer awardNum = Integer.valueOf(s.split(":")[1]);
for (int i = 0; i<awardNum;i++){
if(j<awardUsers.size()){
awardUsers.get(j).setAward(awardName);
j++;
}
}
}
StringBuilder awardString = new StringBuilder();
for (User u: awardUsers) {
awardString.append(u.toString()+"
");
}
awardString.append(" ");
DrawLuckResult dr = new DrawLuckResult(name,document,keyWord,startTime,endTime,resultTime,winnerNum,award,
LotteryDrawFilter.getFilterTypeString(filterType),awardString.toString());
drawLuckResultDao.insert(dr);
responseData.setData(dr);
Thread t = new Thread(new Runnable() {
@Override
public void run() {
try {
StringBuilder sb = new StringBuilder();
for (User u: awardUsers) {
sb.append(u.toString()+"</br>");
}
sb.append(" ");
EmailUtil.send465("中奖结果","<h1>中奖结果通知</h1></br>" + sb.toString(),email);
} catch (MessagingException e) {
e.printStackTrace();
}
for (User u: awardUsers) {
try {
String name = u.getName();
String email = null;
if(name.contains("(")){
email = name.substring(name.indexOf("(") +1 ,name.lastIndexOf(")"));
if (!email.contains("@qq.com")){
email += "@qq.com";
}
}else if(name.contains("<")){
email = name.substring(name.indexOf("<") +1 ,name.lastIndexOf(">"));
}
// System.out.println(email);
// 为了不打扰其他人只通知自己
if (email.contains("947205926")){
EmailUtil.send465("中奖通知","恭喜" + u.getName() + "获得" + u.getAward(),"947205926@qq.com");
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
});
t.start();
return responseData;
}
- Lgc随机数
public static List<User> getResult(Map<String, Integer> users, Integer awardNum) {
Iterator it = users.entrySet().iterator();
List<User> listUser = new ArrayList<>();
while (it.hasNext()) {
Map.Entry entry = (Map.Entry) it.next();
String name = (String) entry.getKey();
Integer weight = (Integer) entry.getValue();
// System.out.println(name + " " + weight);
listUser.add(new User(name, weight));
}
Random random = new Random();
// 对所有参与的用户进行随机排序
Collections.sort(listUser, new Comparator<User>() {
@Override
public int compare(User o1, User o2) {
return random.nextInt(2) - 1;
}
});
int i = 0;
int size = listUser.size();
LcgRandom lcg = new LcgRandom();
List<User> awardList = new ArrayList<>();
if (size > 0) {
while (i < awardNum) {
int ran = lcg.nextInt(size);
// 对水群的用户降低获奖权重
if (listUser.get(ran).getWeight() > 0) {
listUser.get(ran).setWeight(listUser.get(ran).getWeight() - 1);
} else {
awardList.add(listUser.get(ran));
listUser.remove(ran);
size = listUser.size();
i++;
}
}
}
return awardList;
}
LCG算法
LCG(linear congruential generator)线性同余算法,是一个古老的产生随机数的算法。由以下参数组成:
| 参数 | m | a | c | X |
|---|---|---|---|---|
| 性质 | 模数 | 乘数 | 加数 | 随机数 |
| 作用 | 取模 | 移位 | 偏移 | 作为结果 |
LCG算法是如下的一个递推公式,每下一个随机数是当前随机数向左移动 log2 a 位,加上一个 c,最后对 m 取余,使随机数限制在 0 ~ m-1 内
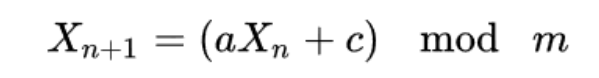
- 从该式可以看出,该算法由于构成简单,具有以下优点
- 计算速度快
- 易于实现
- 易于写入硬件
二、伪随机数算法
伪随机数产生的方法有个逼格挺高的名字---伪随机数发生器。伪随机数产生器中最最最基础的思想是均匀分布(当然这不是唯一的思路)。一般来说,只敢说"一般来说",因为我也不敢百分百肯定,如今主流的编程语言中使用的随机数函数基本采用这种均匀分布思想,而其中最常用的算法就是"线性同余法"。
1. 什么是线性同余法?
线性同余法基于如下线性同余方程组
用于产生均匀型伪随机数的线性同余产生器(与上面的方程符号没有对应关系)
其中,a为"乘数",b为"增量",m为"模数",x0为"种子数"。
如果产生的是区间实在(0,1)之间的,则只需要每个数都除以m即可,即取
2. 线性同余法产生均匀型伪随机数需要注意什么?
2.1)种子数是在计算时随机给出的。比如C语言中用srand(time(NULL))函数进行随机数种子初始化。
2.2)决定伪随机数质量的是其余的三个参数,即a,b,m决定生成伪随机数的质量(质量指的是伪随机数序列的周期性)
2.3)一般b不为0。如果b为零,线性同余法变成了乘同余法,也是最常用的均匀型伪随机数发生器。
3. 高性能线性同余法参数取值要求?
3.1)一般选取方法:乘数a满足a=4p+1;增量b满足b=2q+1。其中p,q为正整数。 PS:不要问我为什么,我只是搬运工,没有深入研究过这个问题。
3.2)m值得话最好是选择大的,因为m值直接影响伪随机数序列的周期长短。记得Java中是取得32位2进制数吧。
3.3)a和b的值越大,产生的伪随机数越均匀
3.4)a和m如果互质,产生随机数效果比不互质好。
反正这图我没有发现明显的规律。因此这种伪随机数在一定条件下是可以满足随机性性质的。

聊天记录过滤思路
- 基本过滤:
首先通过正则表达式进行聊天记录的切割,分为用户信息和用户聊天内容;通过用户信息获取用户的ID(昵称+账号);根据用户ID的开头进行判断是否是系统消息、助教、教师,对这三类的对象进行过滤,不参与后续的抽奖活动,实现基本过滤。
```
if (Pattern.matches("系统消息\([0-9]+\)", userID) || Pattern.matches("教师_.*\(.*\)", userID)|| Pattern.matches("助教_.*\(.*\)", userID))
{
userID = null;
}
```
三种过滤选择:
- 不过滤
针对抽奖名单的过滤,只实现基本过滤,并不对名单进一步的进行筛选,即只去除系统消息、教师、助教这三类对象。
- 普通过滤
针对抽奖名单的过滤,首先实现基本过滤,去除系统消息、教师、助教这三类用户;其次针对只发表抽奖关键字的对象,也进行过滤。主要通过去除聊天记录中的关键字后,如果为空,则这条消息对应的说话人则不加入待抽奖名单。
- 深度过滤
针对抽奖名单的过滤,首先实现基本过滤,去除系统消息、教师、助教这三类用户;其次针对只发表抽奖关键字的对象,也进行过滤;并且对于聊天内容只有图片和抽奖关键字的对象也进行一定抽奖概率的降低,但不进行过滤。
基本实现:
- 读取文件,基本过滤处理
BufferedReader bufferedReader = openFile();
//读取文件
String talkContent = null;
String temp = null;
while ((temp = bufferedReader.readLine()) != null) {
if (textType.equals("USER_TALK_CONTENT")) {
if (!(isUserInfo(temp))) {
talkContent += temp;
} else{
//判断发言是否有抽奖关键字
if (hasKeyWord(lotteryDrawRule.getKeyWord(), talkContent) && userID != null) {
talkContentFilter(talkContent);
}
talkContent = null;
userID = null;
textType = "USER_INFO";
}
}
if (textType.equals("USER_INFO")) {
userID = getUser(temp);
if (userID != null) {
//去除系统消息、教师、助教
if (Pattern.matches("系统消息\([0-9]+\)", userID)
|| Pattern.matches("教师_.*\(.*\)", userID)
|| Pattern.matches("助教_.*\(.*\)", userID)) {
userID = null;
}
}
textType = "USER_TALK_CONTENT";
}
}
//测试
for (String key : users.keySet()) {
System.out.println(key + ":" + users.get(key));
}
read.close();
return users;
- 三种过滤的处理
*
过滤函数
filterType=NO_FILTER:表示不过滤;所有人参与抽奖
filterType=NORMAL_FILTER:表示普通过滤;过滤只有抽奖关键字的用户
filterType=DEEP_FILTER:表示深度过滤;过滤只有抽奖关键字的用户或降低只有图片+抽奖关键字的用户的获奖概率
*/
public void talkContentFilter(String talkContent) {
boolean flag = true; //判断其需不需要被过滤
int deepNum = 0; //满足深度过滤的次数
//如果为NO_FILTER;不执行任何过滤
if ((lotteryDrawRule.getFilterType().equals("NO_FILTER"))) {
}
else if((lotteryDrawRule.getFilterType().equals("NORMAL_FILTER"))){
//去除抽奖关键关键字
talkContent = talkContent.substring(talkContent.lastIndexOf('#')+1);
//符合NORMAL_FILTER
if (talkContent == null || talkContent.equals("")) {
flag = false;
}
}
else{
//去除抽奖关键关键字
talkContent = talkContent.substring(talkContent.lastIndexOf('#')+1);
//符合NORMAL_FILTER
if (talkContent == null || talkContent.equals("")) {
flag = false;
}
//符合DEEP_FILTER
if (talkContent.equals("[图片]") && lotteryDrawRule.getFilterType().equals("DEEP_FILTER")) {
deepNum = 1;
}
}
if (!users.containsKey(userID) && flag) { // 如果该用户id未出现过且不需要过滤
users.put(userID, deepNum); // 存入map
}
else if (deepNum > 0) { //如果该用户满足深度过滤的要求,就保存他的言论次数,用于计算概率时降低它的获奖权值
deepNum = (int) users.get(userID) + 1;
users.put(userID, deepNum);
}
}
附加功能实现
附加需求功能
一、聊天记录数据分析
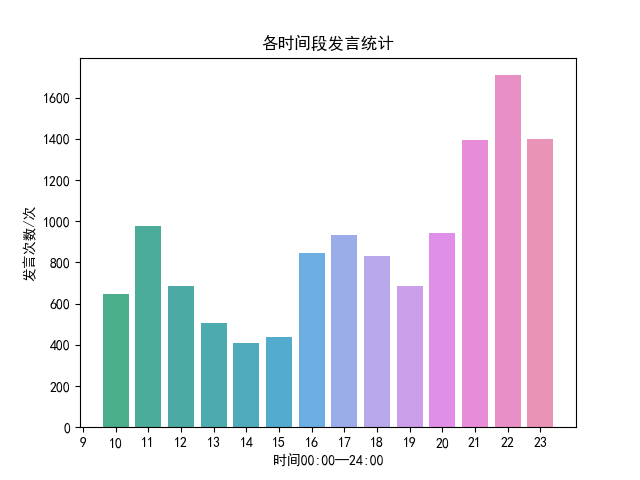
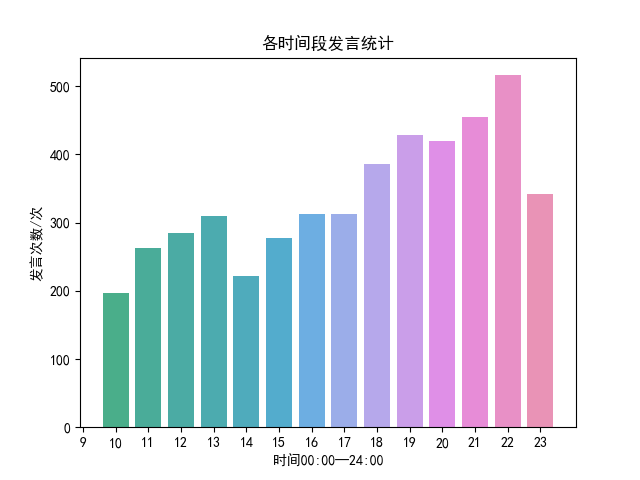
用户各时间段发言统计
整体分析用户各时间段的发言情况,统计每个用户各个时间段的发言次数,然后以柱形图形式展现,通过柱状图我们很容易得出用户在哪些时间段发言频率较高。
def get_time(self):
times = re.findall(r'd{2}:d{2}:d{2}', self.data)#提取用户发言时间哪小时
Xi = [time.split(":")[0] for time in times]
sns.countplot(Xi, order=[str(i) for i in range(0, 24)])
plt.plot()
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.title("各时间段发言统计")
plt.xlabel("时间00:00—24:00")
plt.ylabel("发言次数/次")
plt.savefig(r"imghour.png", format='png')
plt.close()
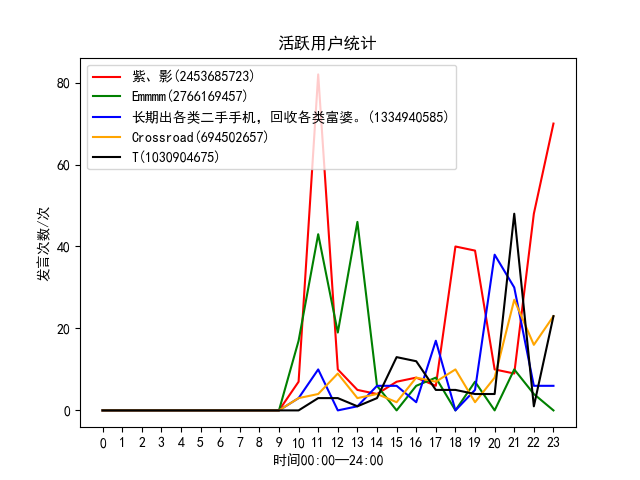
活跃用户的发言情况
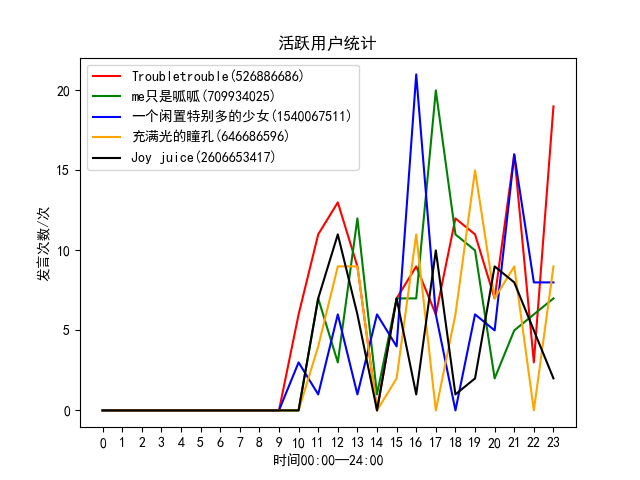
局部分析前五名活跃用户的发言情况,统计每个用户的发言次数,然后进行排序提取前五个活跃用户的发言情况,然后以折线图的形式展现,通过折线图我们很容易发现这五个用户在哪些时间段发言频率较高。
def get_active(self):
str_list = re.findall(r'd{2}:d{2}:d{2} .*?
', self.data)
chat = {}
i = 0
for string in str_list:#提取用户昵称及其发言的时间段分布
size = len(string) - 1
dict2 = {}
if string[9:size] != "系统消息(10000)":
if not chat.__contains__(string[9:size]):
i = i + 1
dict2[string[0:2]] = 1
chat[string[9:size]] = dict2
else:
if not chat[string[9:size]].__contains__(string[0:2]):
chat[string[9:size]][string[0:2]] = 1
else:
chat[string[9:size]][string[0:2]] = chat[string[9:size]][string[0:2]] + 1
dict3 = {}
for key, dic in chat.items():#降序排序统计用户活跃情况
count = 0
for val in dic.values():
count += val
dict3[key] = count
result = dict(sorted(dict3.items(), key=operator.itemgetter(1), reverse=True))
colors = ['red', 'green', 'blue', 'orange', 'black']
Xi = [str(k) for k in range(0, 24)]
i = 0
for key in result.keys():#遍历前五名活跃用户的发言情况
if i >= 5:
break
Yi = []
for j in range(0, 24):
Yi.append(0)
for key2 in chat[key].keys():
Yi[int(key2)] = chat[key][key2]
plt.plot(Xi, Yi, color=colors[i], label=key)
i = i + 1
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.xticks(range(len(Xi)))
plt.legend()
plt.title("活跃用户统计")
plt.xlabel("时间00:00—24:00")
plt.ylabel("发言次数/次")
plt.savefig(r"imgactive.png", format='png')
plt.close()
分析聊天记录有效关键词
对用户聊天记录进行有效关键词提取与分析,然后对这些关键词进行整合分析,绘出词云图,通过词云图我们很容易得出,聊天记录中哪些关键词使用频率较高。
def get_wordcloud(self):
pattern = re.compile(r'd{4}-d{2}-d{2} d{2}:d{2}:d{2} .*?(d+)
(.*?)
', re.DOTALL)
contents = re.findall(pattern, self.data)
word_list = []
for sentence in contents:
sentence = sentence.replace("[表情]", "").replace("[图片]", "").replace("@全体成员", "")
if sentence != "" and not sentence.__contains__("撤回了一条消息") and not sentence.__contains__("加入本群。") and
not sentence.__contains__('长按复制此消息,打开最新版支付宝就能领取!') and not sentence.__contains__('请使用新版手机QQ查收红.'):
word_list.append(" ".join(jieba.cut(sentence.strip())))
new_text = " ".join(word_list)
wordcloud = WordCloud(background_color="white",
width=1200,
height=1000,
min_font_size=50,
font_path="simhei.ttf",
random_state=50,
)
my_wordcloud = wordcloud.generate(new_text)
plt.imshow(my_wordcloud)
plt.axis("off")
wordcloud.to_file(r'imgwordcloud.png')
实验结果如下
-
PlusA.txt聊天记录数据分析

-
PlusB.txt聊天记录数据分析

二、绘画获奖名单海报
1、思路分析
通过接受服务器传来的获奖名单json数据,然后对json字符串进行相应的处理,提取出获奖者的昵称,QQ号或邮箱和奖品名称,然后对相应的模块进行绘画,生成海报图。
header = '[云打印抽奖] QQ互动'
title = '2019年4月QQ互动获奖名单'
chapter = ['昵称', 'QQ号', '奖品']
string = '恭喜以上获奖的同学,我们将在近期发出本次活动的奖励,请有获奖的同学注意关注本平台抽奖动态,感谢您的参与,谢谢!'
n = 19
foot = [string[i:i + n] for i in range(0, len(string), n)]
# 设置字体和颜色
font_type = r'fontmy_font.ttc'
header_font = ImageFont.truetype(font_type, 40)
title_font = ImageFont.truetype(font_type, 23)
chapter_font = ImageFont.truetype(font_type, 25)
email_font = ImageFont.truetype(font_type, 18)
list_font = ImageFont.truetype(font_type, 24)
foot_font = ImageFont.truetype(font_type, 20)
header_color = '#FFFFFF'
title_color = '#EE0000'
chapter_color = '#CD3333'
list_color = '#EE2C2C'
foot_color = '#EE3B3B'
# 设置图片
img = 'img/mode.png'
new_img = 'img/scholarship.png'
image = Image.open(img)
draw = ImageDraw.Draw(image)
width, height = image.size
# header
header_x = 38
header_y = 880
draw.text((header_x, height - header_y), u'%s' % header, header_color, header_font)
# title
title_x = header_x + 30
title_y = header_y - 140
draw.text((title_x, height - title_y), u'%s' % title, title_color, title_font)
# chapter
chapter_x = title_x - 20
chapter_y = title_y - 40
draw.text((chapter_x, height - chapter_y), u'%s' % chapter[0], chapter_color, chapter_font)
draw.text((chapter_x + 140, height - chapter_y), u'%s' % chapter[1], chapter_color, chapter_font)
draw.text((chapter_x + 270, height - chapter_y), u'%s' % chapter[2], chapter_color, chapter_font)
# 获取student_list
data = sys.argv[1]
contents = data.split('\r\n')
student_list = []
size = len(contents) - 1
for i in range(0, size):
item = []
if contents[i].__contains__('):'):
nick_name = re.findall(r'(.*?)(', contents[i])
elif contents[i].__contains__('>:'):
nick_name = re.findall(r'(.*?)<', contents[i])
if contents[i].__contains__('):'):
qq = re.findall(r'((.*?))', contents[i])
elif contents[i].__contains__('>:'):
qq = re.findall(r'<(.*?)>', contents[i])
reward = re.findall(r':(.*?),', contents[i])
item.append(nick_name[0])
item.append(qq[0])
item.append(reward[0])
student_list.append(item)
list_x = chapter_x - 20
list_y = chapter_y - 40
for student in student_list:
for i in range(0, len(student)):
if student[i].__contains__('@'):
draw.text((list_x + i * 140, height - list_y), u'%s' % student[i], list_color, email_font)
else:
draw.text((list_x + i * 140, height - list_y), u'%s' % student[i], list_color, list_font)
list_y = list_y - 40
#footer
foot_x = chapter_x - 30
foot_y = list_y - 40
for i in range(0, len(foot)):
foot_y = foot_y - 40
draw.text((foot_x, height - foot_y), u'%s' % foot[i], foot_color, foot_font)
draw.text((chapter_x + 30, height - (foot_y - 40)), u'%s(云打印)' % time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()), foot_color, foot_font)
image.save(new_img, 'png')
2、实验结果如下

增加功能
邮件提醒
增加了对中奖学生的邮件提醒,通过处理聊天记录中的用户信息,获取用户的邮箱信息比如qq邮箱,实现对中奖用户的邮件提醒,提高用户的体验。
- 基本实现
public class EmailUtil {
// 发件人 账号和密码
public static final String MY_EMAIL_ACCOUNT = "cy947205926@163.com";
public static final String MY_EMAIL_PASSWORD = "**********";// 密码,是你自己的设置的授权码
public static void send465(String subject,String content,String receiveEmail) throws AddressException, MessagingException {
Properties p = new Properties();
p.put("mail.smtp.ssl.enable", true);
p.setProperty("mail.smtp.host", MEAIL_163_SMTP_HOST);
p.setProperty("mail.smtp.port", "465");
p.setProperty("mail.smtp.socketFactory.port", SMTP_163_PORT);
p.setProperty("mail.smtp.auth", "true");
p.setProperty("mail.smtp.socketFactory.class", "SSL_FACTORY");
Session session = Session.getInstance(p, new Authenticator() {
// 设置认证账户信息
@Override
protected PasswordAuthentication getPasswordAuthentication() {
return new PasswordAuthentication(MY_EMAIL_ACCOUNT, MY_EMAIL_PASSWORD);
}
});
session.setDebug(true);
MimeMessage message = new MimeMessage(session);
// 发件人
message.setFrom(new InternetAddress(MY_EMAIL_ACCOUNT));
// 收件人和抄送人
message.setRecipients(Message.RecipientType.TO, receiveEmail);
// 内容(这个内容还不能乱写,有可能会被SMTP拒绝掉;多试几次吧)
message.setSubject(subject);
message.setContent("<h1>"+ content +"</h1>", "text/html;charset=UTF-8");
message.setSentDate(new Date());
message.saveChanges();
Transport.send(message);
}
}
遇到的困难及解决方法
- 陈宇
- 遇到的困难:java和python对接后端的时候出现了一些问题,部署服务器的时候遇到了一些浪费了比较多的时间。java调用shell命令出了点问题
- 解决办法:查询相关资料。团队成员一起努力一起解决了。
- 陈迎仁
- 遇到的困难:
- 正则表达式应用不熟悉,在对于文档的切割过程中,经常遇到一些切割错误;花费了较多的时间在对聊天记录的切割。
- 解决办法:
- 通过查询百度文档,学习郑重地表达式的基本语法,根据具体格式去寻找正则表达式的书写;与团队队友进行商量。
- 通过查询百度文档,学习郑重地表达式的基本语法,根据具体格式去寻找正则表达式的书写;与团队队友进行商量。
- 遇到的困难:
- 陈诗娴
- 遇到的困难:
- 编程方面比较弱,算法单一,有很多不懂的
- 解决办法:
- 做力所能及的部分
- 做力所能及的部分
- 遇到的困难:
- 蔡森林
- 遇到的困难:对于数据分析,自己从未接触过,不知道怎么使用python绘制图表;对前后端交互不是很懂;bug调试不是很熟练。
- 解决办法:通过网上搜索有关python绘图知识,边模仿边践行,一步一步实现聊天记录的可视化图表,如柱形图,折线图,词云图和海报图;对于前后端的交互,主要通过接口实现,以json数据格式进行数据处理;慢慢积累调bug经验,培养独立解决问题的能力。
- 蔡鸿键
- 遇到的困难:
- git bash使用不便,前后端数据传输不顺,JS参数传输遇到困难
- 解决办法:
- 依靠队友指导,大家一起测试寻找BUG,使用搜索引擎查询,多实践
- 依靠队友指导,大家一起测试寻找BUG,使用搜索引擎查询,多实践
- 遇到的困难:
马后炮
-
陈宇
- 如果我能力能在强一点,那么队友就能轻松一点
- 如果我能力能在强一点,那么队友就能轻松一点
-
陈迎仁
- 如果我学java后端的进度能更快一点,那么这次我就能独自实践Java后端开发以及服务器的搭建了,实现我所渴望的技术。
- 如果我学java后端的进度能更快一点,那么这次我就能独自实践Java后端开发以及服务器的搭建了,实现我所渴望的技术。
-
陈诗娴
- 如果我的代码能力能强一点,那么就能为团队做更多事。
- 如果我的代码能力能强一点,那么就能为团队做更多事。
-
蔡森林
- 如果我能提前好好学python,那么我将能为我的团队做得更多
- 如果我能提前好好学python,那么我将能为我的团队做得更多
-
蔡鸿键
- 如果好好学习,那么就没什么BUG要解决了
- 如果好好学习,那么就没什么BUG要解决了
PSP表格
陈宇
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 20 |
| Estimate | 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 200 | 320 |
| Analysis | 需求分析 (包括学习新技术) | 60 | 120 |
| Design Spec | 生成设计文档 | 0 | 0 |
| Design Review | 设计复审 | 0 | 0 |
| Coding Standard | 代码规范(为目前的开发制定合适的规范) | 20 | 30 |
| Design | 具体设计 | 0 | 0 |
| Coding | 具体编码 | 160 | 210 |
| Code Review | 代码复审 | 20 | 60 |
| Test | 测试(自我测试,修改代码,提交修改) | 30 | 120 |
| Reporting | 报告 | 30 | 40 |
| Test Repor | 测试报告 | 0 | 0 |
| Size Measurement | 计算工作量 | 10 | 10 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 15 | 20 |
| 合计 | 575 | 960 |
陈迎仁
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 10 |
| Estimate | 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 160 | 220 |
| Analysis | 需求分析 (包括学习新技术) | 60 | 150 |
| Design Spec | 生成设计文档 | 0 | 0 |
| Design Review | 设计复审 | 0 | 0 |
| Coding Standard | 代码规范(为目前的开发制定合适的规范) | 5 | 5 |
| Design | 具体设计 | 0 | 0 |
| Coding | 具体编码 | 120 | 160 |
| Code Review | 代码复审 | 30 | 80 |
| Test | 测试(自我测试,修改代码,提交修改) | 40 | 140 |
| Reporting | 报告 | 40 | 120 |
| Test Repor | 测试报告 | 0 | 0 |
| Size Measurement | 计算工作量 | 10 | 10 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 15 | 20 |
| 合计 | 500 | 925 |
陈诗娴
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 5 | 10 |
| Estimate | 估计这个任务需要多少时间 | 0 | 0 |
| Development | 开发 | 60 | 60 |
| Analysis | 需求分析 (包括学习新技术) | 20 | 40 |
| Design Spec | 生成设计文档 | 0 | 0 |
| Design Review | 设计复审 | 0 | 0 |
| Coding Standard | 代码规范(为目前的开发制定合适的规范) | 0 | 0 |
| Design | 具体设计 | 60 | 60 |
| Coding | 具体编码 | 60 | 60 |
| Code Review | 代码复审 | 10 | 10 |
| Test | 测试(自我测试,修改代码,提交修改) | 10 | 15 |
| Reporting | 报告 | 10 | 15 |
| Test Repor | 测试报告 | 0 | 0 |
| Size Measurement | 计算工作量 | 0 | 0 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 10 | 10 |
| 合计 | 245 | 280 |
蔡森林
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 60 |
| Estimate | 估计这个任务需要多少时间 | 150 | 300 |
| Development | 开发 | 120 | 300 |
| Analysis | 需求分析 (包括学习新技术) | 40 | 100 |
| Design Spec | 生成设计文档 | 20 | 40 |
| Design Review | 设计复审 | 30 | 100 |
| Coding Standard | 代码规范(为目前的开发制定合适的规范) | 10 | 20 |
| Design | 具体设计 | 40 | 80 |
| Coding | 具体编码 | 120 | 300 |
| Code Review | 代码复审 | 30 | 150 |
| Test | 测试(自我测试,修改代码,提交修改) | 30 | 90 |
| Reporting | 报告 | 20 | 20 |
| Test Repor | 测试报告 | 20 | 10 |
| Size Measurement | 计算工作量 | 15 | 30 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计 | 775 | 1640 |
蔡鸿键
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 30 |
| Estimate | 估计这个任务需要多少时间 | 120 | 300 |
| Development | 开发 | 120 | 300 |
| Analysis | 需求分析 (包括学习新技术) | 40 | 80 |
| Design Spec | 生成设计文档 | 20 | 20 |
| Design Review | 设计复审 | 20 | 120 |
| Coding Standard | 代码规范(为目前的开发制定合适的规范) | 10 | 20 |
| Design | 具体设计 | 30 | 60 |
| Coding | 具体编码 | 120 | 300 |
| Code Review | 代码复审 | 30 | 120 |
| Test | 测试(自我测试,修改代码,提交修改) | 30 | 60 |
| Reporting | 报告 | 20 | 20 |
| Test Repor | 测试报告 | 20 | 10 |
| Size Measurement | 计算工作量 | 15 | 30 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 20 | 40 |
| 合计 | 645 | 1510 |