扫码关注下方公众号:"Python编程与深度学习",领取配套学习资源,并有不定时深度学习相关文章及代码分享。

今天分享一篇发表在MICCAI 2020上的论文:Multi-scale Microaneurysms Segmentation Using Embedding Triplet Loss (原文链接:[1])。
1 研究背景
微动脉瘤是糖尿病视网膜病变进展的重要指标。这篇文章提出了一种用于小动脉瘤分割的两阶段深度学习方法,其特点是采用了多尺度的选择性采样作为输入以及embedding triplet loss来提高模型性能。
2 方法
2.1 整体流程
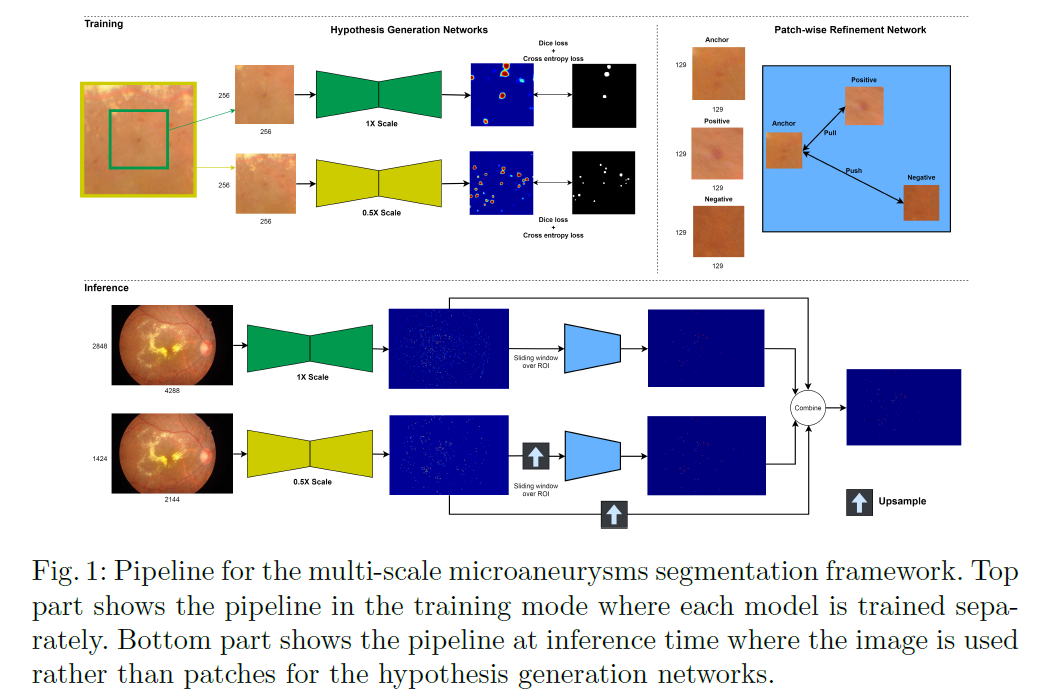
如上图 (Fig.1)所示,文中提出的方法包含了两个阶段:假设生成网络 (hypothesis generation network, HGN)和基于patch的再确认网络 (patch-wise refinement network, PRN)。其中HGN采用用多尺度全卷积网络 (multi-scale fully convolutional networks, FCNs)来提取感兴趣区域 (region of interest, ROI),PRN是一个分类器,对HGN提取的ROI进行再确认。
接下来将对上述两个阶段进行详细的介绍。
2.2 假设生成网络 (HGN)
在高分辨率眼底图像中,微动脉瘤只占图像的很小一部分,因此微动脉瘤分割任务常常是基于patch来解决的。但是基于patch的方法存在如下问题:
- 如果使用放大后 (zoomed-in)的patch,虽然可以获得较高的空间分辨率(更清晰),但是会丢失掉一些上下文的语义信息
- 如果使用缩小后 (zoomed-out)的patch,虽然可以获得更丰富的语义信息,但是会丢失空间分辨率
为了在zoomed-in和zoomed-out之间进行权衡,HGN采用了两个尺度 (1X scale和0.5X scale)的$256 imes 256$图像作为FCNs的输入。多尺度的输入允许提取与尺度相关的特征,同时保留完整分辨率的图像信息。
关于训练过程中的patch选择,作者将没有包含糖尿病性视网膜病变 (Diabetic retinopathy, DR)的图像作为健康图像 (healthy|negative images),将有微动脉瘤的图像作为病变图像 (lesion|position images)。健康的patch只从健康病人的扫描图中提取,病变的patch从微动脉瘤的微动脉瘤位置提取。由于采用上述的提取方法会导致正负样本不均衡,文中采用了加权交叉熵损失函数 (weighted cross entropy loss)和dice损失函数一起计算损失。
2.3 基于patch的再确认网络 (PRN)
PRN是接在HGN后面的分类器,其作用是对于HGN的输出做进一步的再确认,判断对应的感兴趣区域是否包含微动脉瘤。具体地,PRH的输入是patch图像,输出是patch的中心存在微动脉瘤与否的概率。由于分类网络相比于分割任务中的全卷积网络结构更加简单(没有上采样以及跳层连接使得参数和计算量更少),因此PRN可以设计为具有更大的感受野,从而利用更多的空间上下文信息。文中PRN是在Resnet-50上做了一些适应性的修改。其输入的patch与HGN中的1X scale分支的patch选取方法一致,区别是PRN采用了$129 imes 129$的输入分辨率。
为了使得PRN对于不同类别的patch所提取到的特征具有更好的区别性,文中采用了triplet loss+cross entropy loss作为PRN的损失函数。对于triplet loss,以分类网络中在全局平均池化层 (global average pooling, GAP)之后的最后一层卷积层的输出特征作为patch图像的嵌入空间表达,优化目为拉近ancoder patch ($x^a$)和positive patch ($x^p$)的嵌入表示距离,拉开positive patch ($x^p$)和negative patch ($x^n$)的嵌入表达距离。上述表达可以形式化为:
$$mathcal{L}_{triplet}=sum_{i}^N[d(f(x_i^a),f(x_i^p))-d(f(x_i^a),f(x_i^n))+a]_+$$
其中$a$是一个边界参数,用于保证positive和negative的嵌入表示之间的距离,$d(cdot,cdot)inmathbb{R}^1$是嵌入空间中的距离度量(文中采用的是angular cosine distance),$N$表示全部可能的triplets数量。
3 实验结果
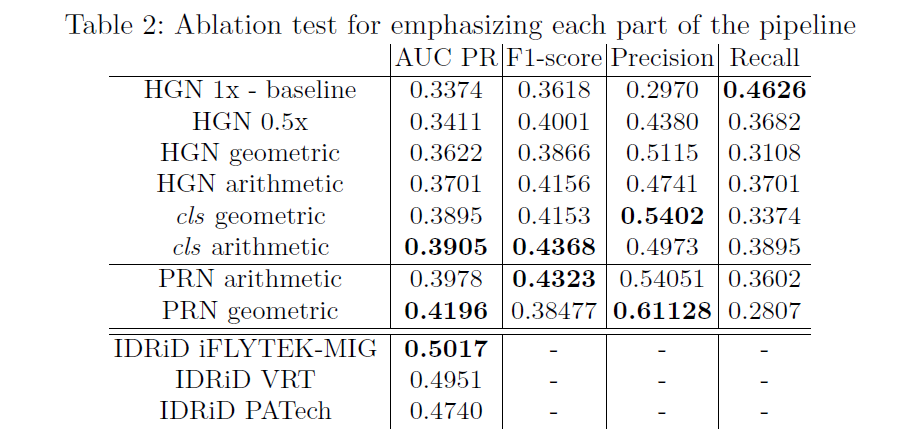
这里我只给出论文中的部分实验结果,具体的实验结果分析以及实验和参数的设置请看原文。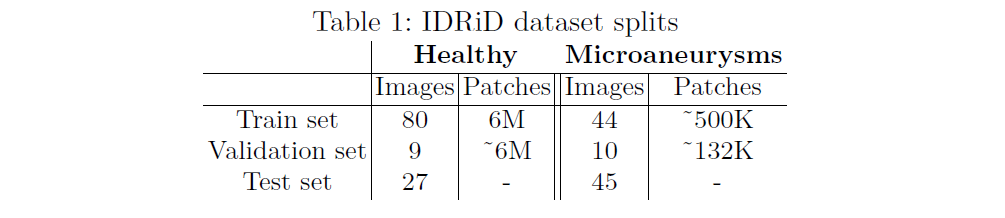
4 参考资料
[1] https://arxiv.org/pdf/1904.12732