特征融合的目的,是把从图像中提取的特征,合并成一个比输入特征更具有判别能力的特征。如何正确融合特征是一个难题。
在很多工作中,融合不同尺度的特征是提高分割性能的一个重要手段。低层特征分辨率更高,包含更多位置、细节信息,但是由于经过的卷积更少,其语义性更低,噪声更多。高层特征具有更强的语义信息,但是分辨率很低,对细节的感知能力较差。如何将两者高效融合,取其长处,弃之糟泊,是改善分割模型的关键。
很多工作通过融合多层来提升检测和分割的性能,按照融合与预测的先后顺序,分类为早融合(Early fusion)和晚融合(Late fusion)。
关于深度特征融合—高低层特征融合,归纳起来共讨论了4类方法:
(1)早融合:用经典的特征融合方法:在现有的网络(如VGG19)中,用concat或add融合 其中的某几层;
FCN、Hypercolumns—>add
Inside-Outside Net(ION)、 ParseNet 、HyperNet—>concat
变种:用DCA特征融合方法代替concat和add操作;
(2)晚融合:
(2.1)采用类似特征金字塔网络(FPN)的思想,对特征融合后进行预测。 (FPN一般用于目标检测,提高小目标检测能力) 三个变种:
1.YOLO2的方法,只在金字塔的top-down路径的最后一层进行预测,此外还有 U-Net [31] and SharpMask for segmentation, Recombinator networks for face detection, and Stacked Hourglass networks for keypoint estimation.
2.YOLO3的方法,在金字塔的每一层都进行预测
3.FSSD的方法,对 FPN进行细微改造
(2.2)feature不融合,多尺度的feture分别进行预测,然后对预测结果进行综合,如Single Shot MultiBox Detector (SSD) , Multi-scale CNN(MS-CNN)
(3)用一个具有高低特征融合能力的网络替代普通的网络,如Densenet;
(4)不进行高低层特征融合,而是在高层特征预测的基础上,再用底层特征进行预测结果的调整
两个经典的特征融合方法:
(1)concat:系列特征融合[35],直接将两个特征进行连接。两个输入特征x和y的维数若为p和q,输出特征z的维数为p+q;
(2)add:并行策略[36],[37],将这两个特征向量组合成复向量,对于输入特征x和y,z = x + iy,其中i是虚数单位。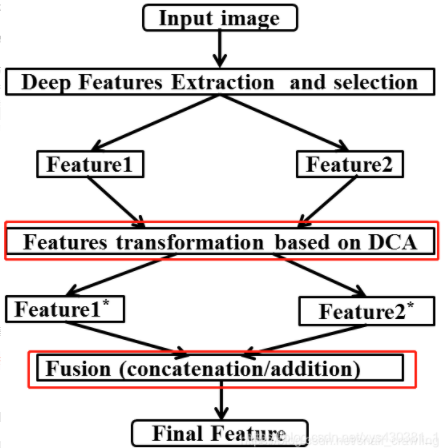
FPN(feature pyramid networks)
特征金字塔是识别不同尺度的目标时常用的结构,但是特征金字塔需要较大的计算量和显存,所以最近研发的一些探测器都不再使用这种结构。
作者开发出的一种构建特征金字塔的新方法,可以减少额外的对计算量和显存的消耗。


YOLOv3——引入:FPN+多尺度检测 (目标检测)(one-stage)(深度学习)(CVPR 2018)
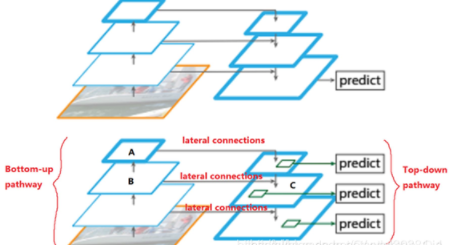
YOLOv2网络结构中有一个特殊的转换层(Passthrough Layer),假设最后提取的特征图的大小是1313,转换层的作用就是将前面的2626的特征图和本层的1313的特征图进行堆积(扩充特征维数据量),而后进行融合,再用融合后的特征图进行检测。这么做是为了加强算法对小目标检测的精确度。为达更好效果,YOLOv3将这一思想进行了加强和改进。
**YOLO v3采用(类似FPN)上采样(Upsample)和融合做法,融合了3个尺度(1313、2626和5252),在多个尺度的融合特征图上分别独立做检测**,最终对于小目标的检测效果提升明显。(有些算法采用多尺度特征融合的方式,但是一般是采用融合后的单一特征图做预测,比如YOLOv2,FPN不一样的地方在于其预测是在不同特征层进行的。)
融合特征的SSD:对小目标的快速检测
FSSD: Feature Fusion Single Shot Multibox Detector
https://blog.csdn.net/wangxujin666/article/details/83065261
https://blog.csdn.net/Dlyldxwl/article/details/79324944
本文是以SSD为基底进行“改造”的一篇文章。SSD是从网络的不同层中抽取不同scale的feature直接做predict,所以没有充分融合不同scale的feature。后续有提出DSSD,RSSD等改进方法,但是因为模型的complexity导致速度变慢很多。**本文借鉴了FPN的思想,重构了一组pyramid feature map,**使得算法的精度有了明显的提升,速度也没有太降。先看一张图直观感受一下FSSD对比其它算法的效果。
利用多层卷积神经网络(CNN)特征的互补优势 进行图像检索
高层特征用于度量语义相似度,低层特征用于度量细粒度相似度。给出一个简单易懂的例子,当查询图像是一个建筑物时,高层相似性捕捉到的图像包含一个建筑物,而低层相似性则捕获同一个从属同类实体的建筑物。显然,低层和高层特征的互补性可以提高查询图像与其他候选图像之间的相似性度量。一些现有的方法试图利用多尺度无序汇集来进行CNN激活。例如,CNN特征分别从不同层次提取和编码,然后将这些不同层次的聚合特征进行连接以测量图像。但直接拼接不能充分利用高层和低层特征的互补性。高层特征可以搜索具有相似语义的候选图像的集合作为查询图像,但是它不足以描述细粒度的细节。因此,高层相似性会削弱低层相似性的有效性,当最近邻居之间的细粒度差别被区分时,语义相似。
在本文中,我们建议以一种简单而有效的方式利用不同层次的CNN特征的更多互补优势。我们的方法试图突出低层相似性的有效性,当查询图像和最近的邻居之间的细粒度的相似性与相似的语义。换句话说,低层特征用于细化高层特征的排序结果,而不是直接连接多个层。如图2所示,高层特征不足以描述细节信息,而低层特征则来自背景混乱和语义歧义。以直接拼接的方式,由于高层相似度的影响,低层相似度在区分细粒度差异方面不起重要作用。使用映射函数,我们的方法利用低层特征来测量查询图像与具有相同语义的最近邻居之间的细粒度相似性。在实验中,我们证明了我们的方法比单层功能,多层连接以及其他基于手工特征的方法更好。