一、Jaeger是什么
Uber开发的一个受Dapper和Zipkin启发的分布式跟踪系统.后端用Go实现,前端用React实现。
官方地址:https://www.jaegertracing.io
适用于以下场景:
- 分布式跟踪信息传递
- 分布式事务监控
- 服务依赖性分析
- 展示跨进程调用链
- 定位问题
- 性能优化
Ps:关于分布式追踪系统可以看这篇文章 分布式追踪系统概述及主流开源系统对比
二、Jaeger架构
1. 术语
OpenTracing
为了解决不同的分布式追踪系统 API 不兼容的问题,诞生了 OpenTracing 规范。OpenTracing 是一个轻量级的标准化层,它位于应用程序/类库和追踪或日志分析程序之间。
一句话总结,OpenTracing是一套标准,它通过提供平台无关、厂商无关的API,使得开发人员能够方便的添加(或更换)追踪系统的实现(我们在测试使用中是基本上通过两行代码的更改就可以在Zipkin和Jaeger之间切换)。OpenTracing提供了用于运营支撑系统的和针对特定平台的辅助程序库。程序库的具体信息请参考详细的规范。OpenTracing 已进入 CNCF(云原生计算基金会,著名的Kubernetes、gRPC和Prometheus等均孵化于此),正在为全球的分布式追踪,提供统一的概念和数据标准。
两个核心
-
Span: 记录Trace在执行过程中的信息,如:查询的sql,请求的HTTP地址,RPC调用,开始、结束、间隔时间等。是跟踪的最小逻辑单位,Span间可以是嵌套关系。
-
Trace: 追踪对象,一个Trace代表了一个服务或者流程在系统中的执行过程,如:test.com,redis,mysql等执行过程。一个Trace是由多个Span组成的有向无环图,代表一次完整的跟踪
结合跟踪链来理解这两个术语。
跟踪链
如下图所示:
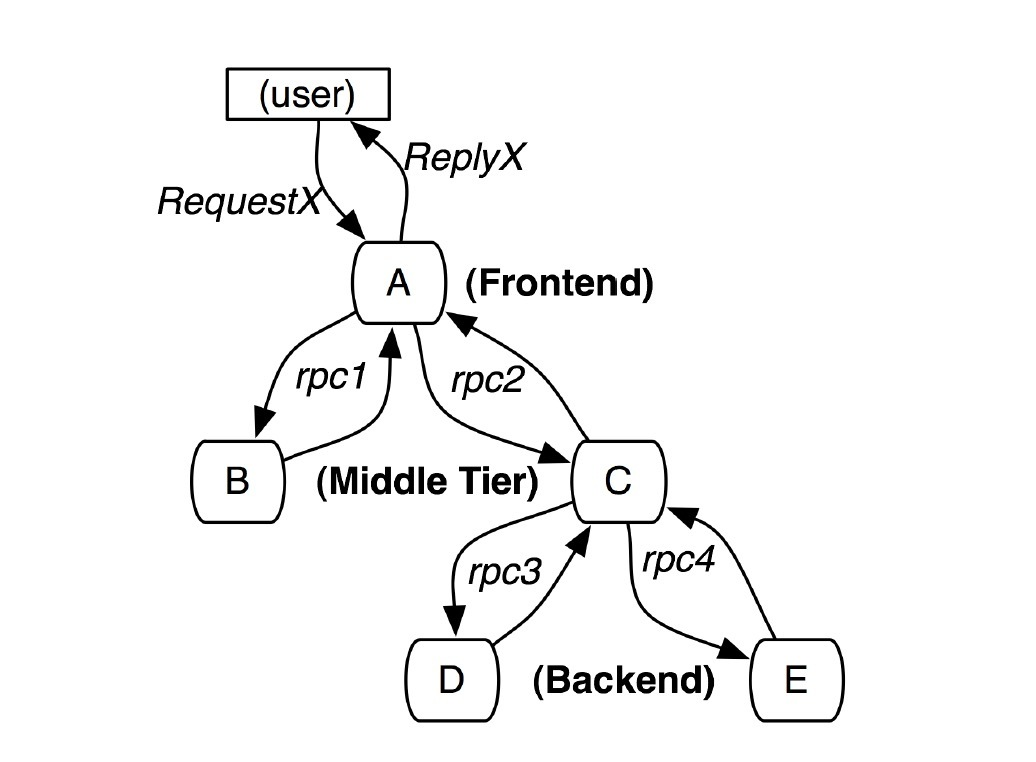
这张图是Google的Dapper论文里的一个例子:图示中,A~E五个节点表示五个服务。用户发起一次请求RequestX到A,同时由于该请求依赖服务B与C,因此A分别发送RPC请求到B和C,B处理完请求后会直接返回到A,但是服务C还依赖服务D和E,因此还要发起两个RPC请求分别到D和E,D和E处理完毕后回到C,C才继续回复到A,最终A会回复用户ReplyX。对于这样一个请求,简单实用的分布式跟踪的实现,就是为服务器上每一次发送和接收动作来收集跟踪标识符和时间戳。
在Dapper这篇论文中,Trace和Span是两个很重要的名词。我们使用Trace表示对一次请求完整调用链的跟踪,而将两个服务例如上面的服务A和服务B的请求/响应过程叫做一次Span,trace是通过span来体现的, 通过一句话总结,我们可以将一次trace,看成是span的有向图,而这个有向图的边即为span。而分布式跟踪系统要做的,就是记录每次发送和接受动作的标识符和时间戳,将一次请求涉及到的所有服务串联起来,只有这样才能搞清楚一次请求的完整调用链。
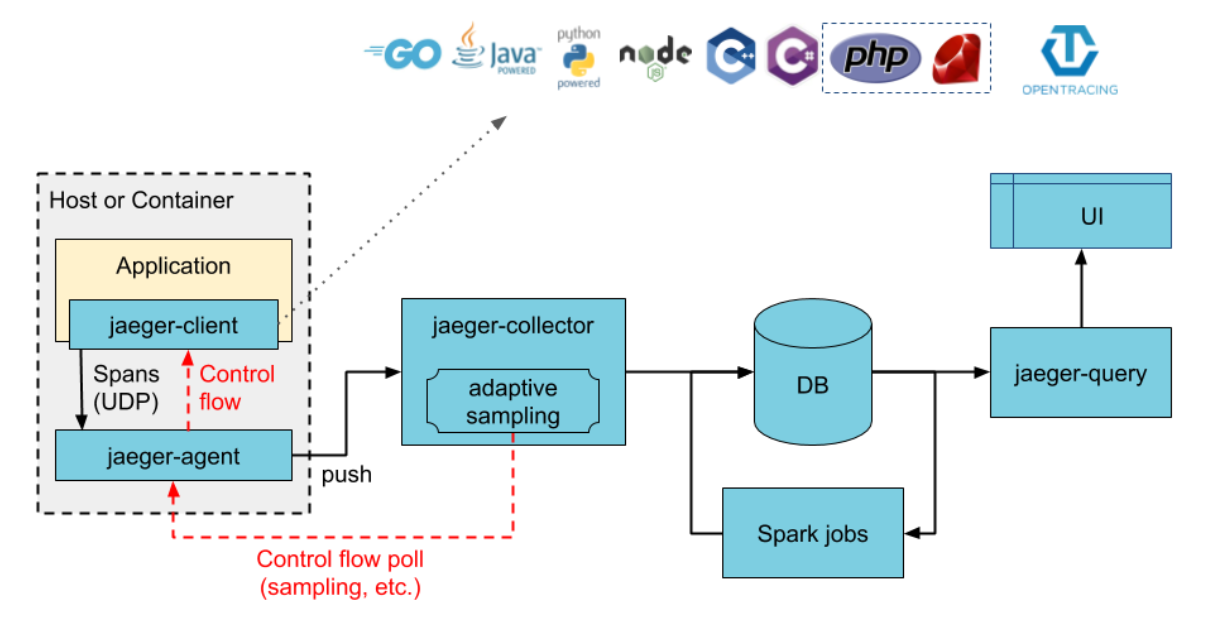
2. 架构图
第一种:直接将数据写入存储
第二种:使用Kafka作为缓冲
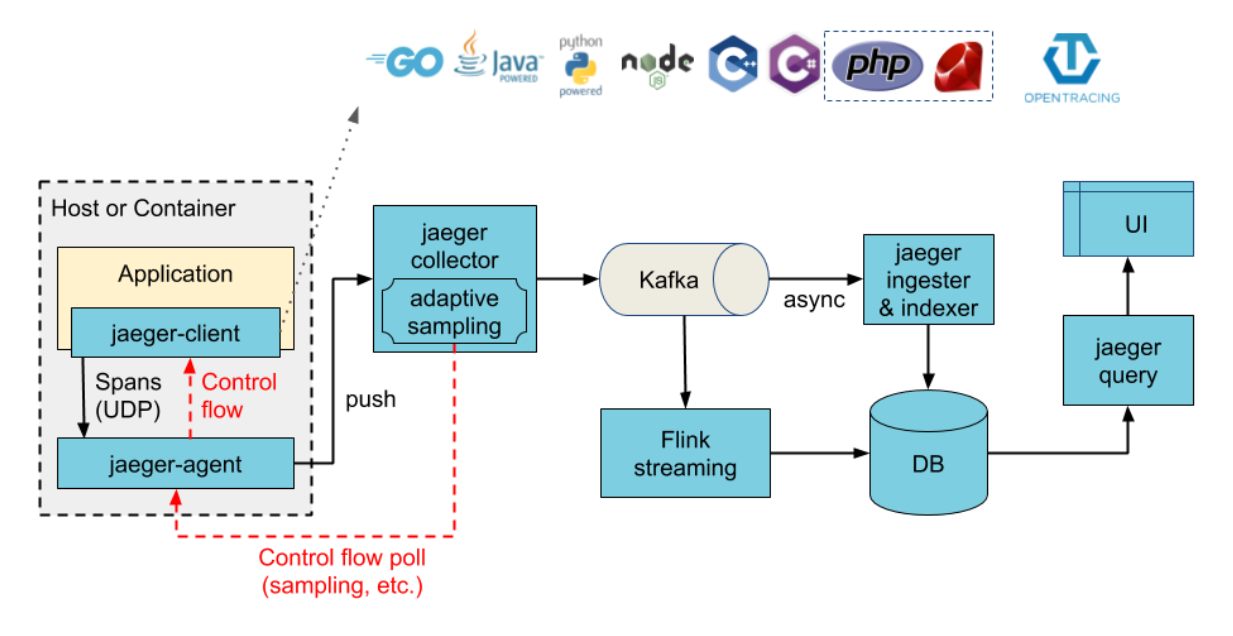
在上图,我们看到Jaeger系统中:黄色部分是我们的应用程序代码;红色部门表示instrument操作,即把我们应用程序与jaeger-client装载起来,从而开始了应用程序到Jaeger的的数据交互操作。将该部分放大来看,我们可以参考下图,了解详细的数据交互方式:
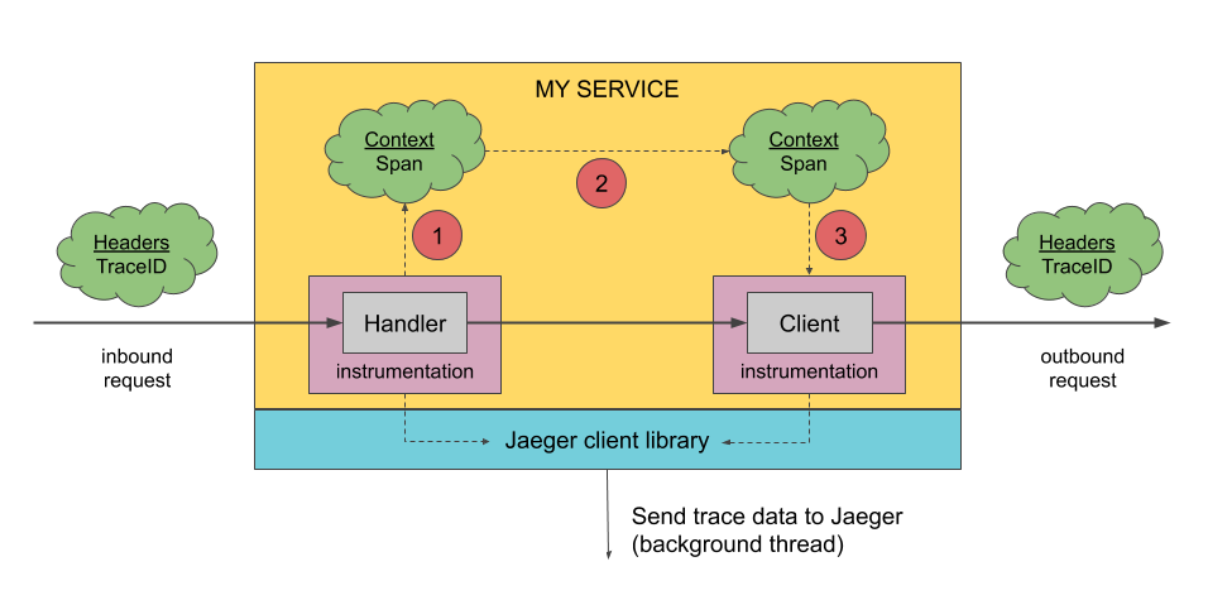
Jaeger有5个模块元素,列表如下,接下来我们来分别解释这五个模块的作用:
1.Jaeger-client
2.Agent
3.Collector
4.Data Store
5.UI
1. Jaeger-client
是Jaeger客户端代码库,便于不同语言的项目来介入到Jaeger中,当我们的应用程序装载上之后,client会负责收集并发送数据到Agent。当前Jaeger的SDK支持有如下:
--官方
1.Go
2.Java
3.Node
4.Python
5.C++
--非官方
1.PHP
3.Others
- 实现了OpenTracing API接口
- 当应用建立Span并发出请求到下游的服务时,它会附带跟踪信息(Trace ID, Span ID, baggage)。其他信息比如请求的名字,请求的参数,日志不会发给下游服务,而会被取样并异步的通过Jaeger-client发送到Jaeger-agent。
- 因为创建跟踪信息的代价很小,跟踪功能是默认开启的。
- 虽然跟踪功能是默认开启,但只有一部分的跟踪会被记录下来。默认比例是0.1%的取样
这里再次放上这张图片结合上面的几点方便理解收集发送数据的操作:
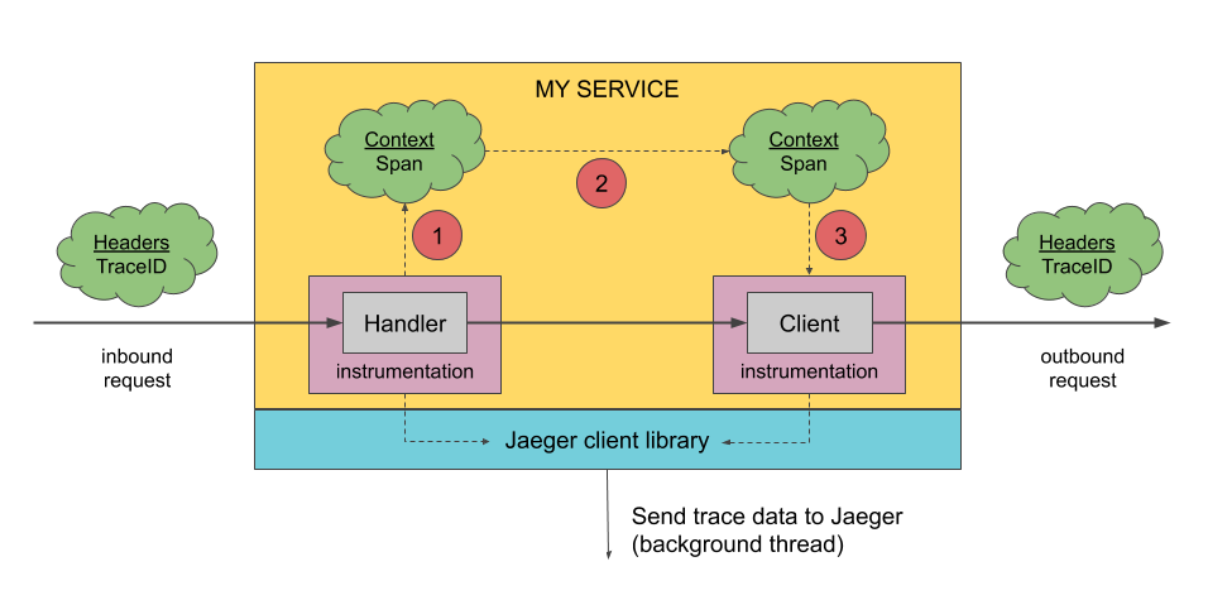
2. Jaeger-agent:
是Jaeger客户端代理,jaeger的agent,是一个监听在 UDP 端口上接收 span 数据的网络守护进程。 如同大多数分布式系统都拥有一个Agent一样,Jaeger的Agent有以下几类特点:
- agent收集并汇聚这些span信息到collector;
- agent的被设计成一个基础组件,旨在作为基础架构组件部署到所有宿主机;
- agent将client library 和 collector 解耦,为 client library 屏蔽了路由和发现 collector 的细节;
总结如下:
- 与应用运行在同一个机器里
- 负责接受从客户端通过UDP发来的Trace/Span信息
- 批量上传到Jaeger收集器
3. Jaeger-collector
collector,顾名思义,从agent收集traces信息,并通过处理管道处理他们,再写入后端存储(backends)。
当前的collector工作主要是管理trace,建立索引,执行相关转换,并最终存储它们。
Collector中运行着sampling逻辑,根据我们设定的sampling方式对数据进行收集和处理。
总结如下:
- 接受从agent发来的Trace/Span信息
- 进行信息校验,索引和存储到后台的数据库
4. DB
即数据存储。Jaeger的存储是一个可插拔的组件,目前支持Cassandra,Elasticsearch和Kafka(当然也支持纯内存方式,但是不适用于生产环境)
5. Query & UI
数据查询与前端界面展示。Query查询是一种从存储中检索trace,并提供UI以显示它们的服务。上图中就展示了一次Trace的数据流向,作为一次系统作用的数据传播/执行图,即可以在Jaeger UI上展示出来。
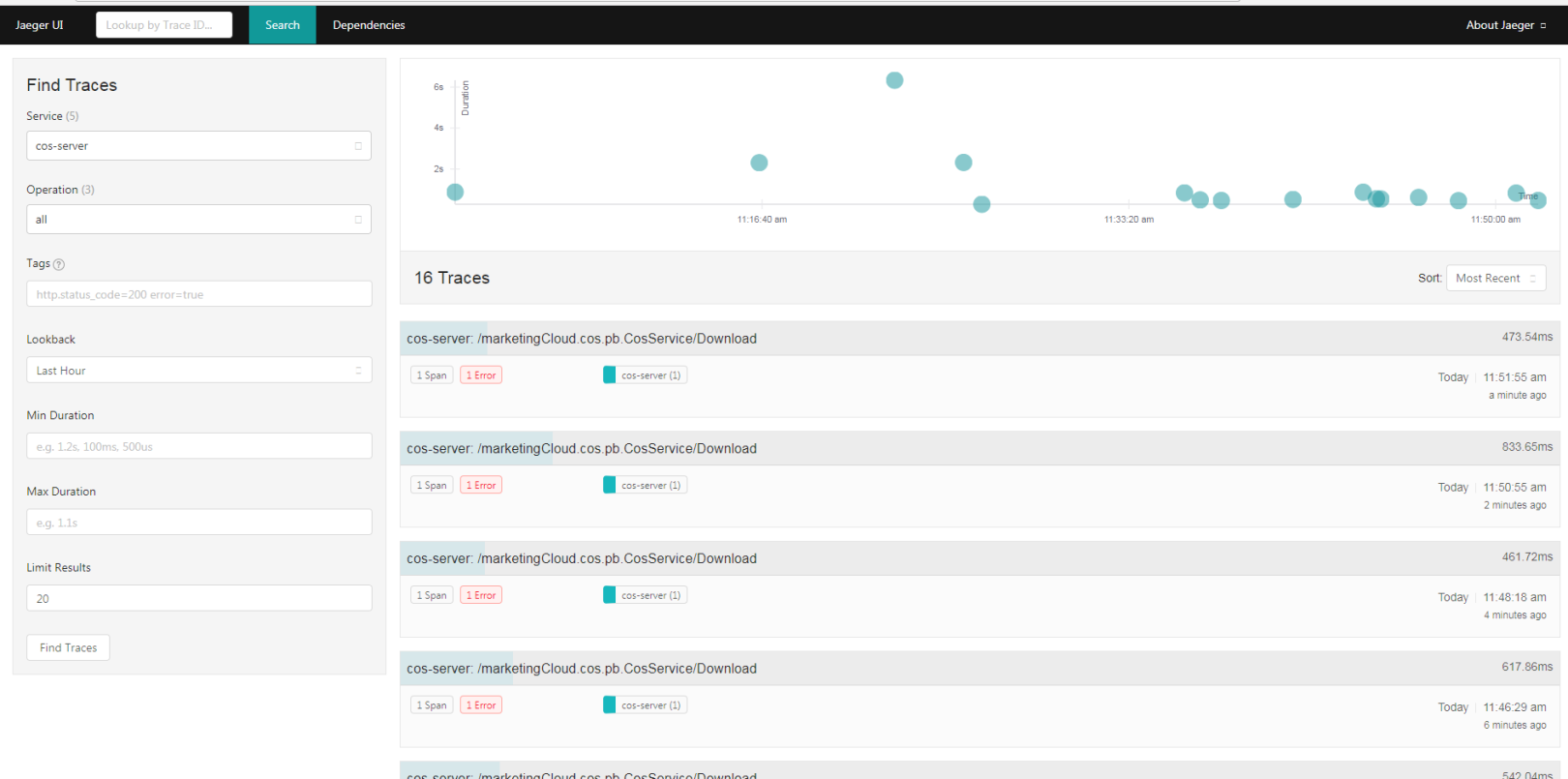
这里放两张UI图:
jaeger ui 首页:

jaeger 查询结果:
三、关于采样率
分布式追踪系统本身也会造成一定的性能低损耗,如果完整记录每次请求,对于生产环境可能会有极大的性能损耗,一般需要进行采样设置。
当前支持四种采样率设置:
-
固定采样(sampler.type=const)sampler.param=1 全采样, sampler.param=0 不采样;
-
按百分比采样(sampler.type=probabilistic)sampler.param=0.1 则随机采十分之一的样本;
-
采样速度限制(sampler.type=ratelimiting)sampler.param=2.0 每秒采样两个traces;
-
动态获取采样率 (sampler.type=remote) 这个是默认配置,可以通过配置从 Agent 中获取采样率的动态设置。
自适应采样(Adaptive Sampling)也已经在开发计划中。