防火墙(底层实际还是iptable)
介绍
Linux 内核包括Netfilter子系统,用于操作或决定进入或通过服务器的网络流量的命运。所有现代 Linux 防火墙解决方案都使用此系统进行数据包筛选。
如果没有用户空间接口来管理内核的数据包筛选系统,内核的数据包筛选系统将没有什么用。这是 iptables 的目的:当数据包到达您的服务器时,它将被发送到 Netfilter 子系统,以便根据通过 iptable 从用户空间提供给它的规则进行接受、操作或拒绝。因此,如果您熟悉 iptable,则是管理防火墙所需的全部功能,但许多前端可用于简化任务。
ufw - 简单的防火墙
Ubuntu 的默认防火墙配置工具是 ufw。ufw 专为简化 iptables 防火墙配置而开发,它提供了一种用户友好的方式来创建基于 IPv4 或 IPv6 主机的防火墙。
ufw 默认情况下最初处于禁用状态。从 ufw 人页面:
"ufw 不是打算通过其命令界面提供完整的防火墙功能,而是提供了一种添加或删除简单规则的简单方法。它目前主要用于基于主机的防火墙。
以下是如何使用 ufw 的一些示例:
-
首先,需要启用 ufw。从终端提示输入:
sudo ufw enable -
要打开端口(在此示例中为 SSH):
sudo ufw allow 22 -
还可以使用编号格式添加规则:
sudo ufw insert 1 allow 80 -
同样,要关闭打开的端口:
sudo ufw deny 22 -
若要删除规则,请使用删除后跟规则:
sudo ufw delete deny 22 -
还可以允许从特定主机或网络访问端口。以下示例允许从主机 192.168.0.2 访问此主机上的任何 IP 地址:
sudo ufw allow proto tcp from 192.168.0.2 to any port 22将 192.168.0.2 替换为 192.168.0.0/24,以允许从整个子网进行 SSH 访问。
-
将+dry-run选项添加到ufw命令将输出生成的规则,但不适用于它们。例如,在打开 HTTP 端口时将应用以下内容:
sudo ufw --dry-run allow http*filter :ufw-user-input - [0:0] :ufw-user-output - [0:0] :ufw-user-forward - [0:0] :ufw-user-limit - [0:0] :ufw-user-limit-accept - [0:0] ### RULES ### ### tuple ### allow tcp 80 0.0.0.0/0 any 0.0.0.0/0 -A ufw-user-input -p tcp --dport 80 -j ACCEPT ### END RULES ### -A ufw-user-input -j RETURN -A ufw-user-output -j RETURN -A ufw-user-forward -j RETURN -A ufw-user-limit -m limit --limit 3/minute -j LOG --log-prefix "[UFW LIMIT]: " -A ufw-user-limit -j REJECT -A ufw-user-limit-accept -j ACCEPT COMMIT Rules updated -
ufw 可以通过:
sudo ufw disable -
要查看防火墙状态,请输入:
sudo ufw status -
对于更详细的状态信息,请使用:
sudo ufw status verbose -
要查看编号格式:
sudo ufw status numbered
注意
如果要打开或关闭的端口在 中定义,可以使用端口名称而不是数字。在上面的示例中,将22替换为ssh。
/etc/services
这是使用 ufw 的快速介绍。有关详细信息,请参阅 ufw 曼页面。
ufw 应用程序集成
打开端口的应用程序可以包括 ufw 配置文件,该配置文件详细介绍了应用程序正常运行所需的端口。配置文件保留在 中,如果默认端口已更改,则可以编辑配置文件。/etc/ufw/applications.d
-
要查看哪些应用程序安装了配置文件,请在终端中输入以下内容:
sudo ufw app list -
与允许流量到端口类似,使用应用程序配置文件可以通过输入:
sudo ufw allow Samba -
扩展语法也可用:
ufw allow from 192.168.0.0/24 to any app Samba将Samba和192.168.0.0.24替换为您使用的应用程序配置文件以及网络的 IP 范围。
注意
无需为应用程序指定协议,因为该信息在配置文件中详细介绍。此外,请注意应用名称将替换端口号。
-
若要查看有关为应用程序定义的端口、协议等的详细信息,请输入:
sudo ufw app info Samba
并非所有需要打开网络端口的应用程序都具有 ufw 配置文件,但如果已分析应用程序,希望文件包含在包中,请针对启动板中的包提交错误。
ubuntu-bug nameofpackage
IP 伪装
IP 伪装的目的是允许网络上具有专用、不可路由 IP 地址的计算机通过计算机进行伪装访问 Internet。必须操作来自专用网络的流量,以便回复可路由回发出请求的机器。为此,内核必须修改每个数据包的源 IP 地址,以便将答复路由回它,而不是路由到发出请求的专用 IP 地址,这在 Internet 上是不可能的。Linux使用连接跟踪(conntrack)来跟踪哪些连接属于哪些计算机,并相应地重新路由每个返回数据包。因此,离开您的专用网络的流量被"伪装"为源自您的 Ubuntu 网关计算机。此过程在 Microsoft 文档中称为互联网连接共享。
ufw 伪装
可以使用自定义 ufw 规则实现 IP 伪装。这是可能的,因为 ufw 的当前端是 iptables 恢复,规则文件位于 中。这些文件是添加没有 ufw 使用的旧 iptables 规则以及与网络网关或网桥相关的规则的一个很好的位置。/etc/ufw/*.rules
规则分为两个不同的文件,应在 ufw 命令行规则之前执行的规则,以及在 ufw 命令行规则之后执行的规则。
-
首先,需要在 ufw 中启用数据包转发。需要调整两个配置文件,将配置文件更改为DEFAULT_FORWARD_POLICY"接受":
/etc/default/ufwDEFAULT_FORWARD_POLICY="ACCEPT"然后编辑并取消注释:
/etc/ufw/sysctl.confnet/ipv4/ip_forward=1同样,对于 IPv6 转发未注释:
net/ipv6/conf/default/forwarding=1 -
现在向文件添加规则。默认规则仅配置筛选器表,并且需要配置伪装 nat表。在标题注释之后将以下内容添加到文件顶部:
/etc/ufw/before.rules# nat Table rules *nat :POSTROUTING ACCEPT [0:0] # Forward traffic from eth1 through eth0. -A POSTROUTING -s 192.168.0.0/24 -o eth0 -j MASQUERADE # don't delete the 'COMMIT' line or these nat table rules won't be processed COMMIT注释并非绝对必要,但记录配置被认为是一种好的做法。此外,在 修改 中的任何规则文件时,请确保这些行是修改的每个表的最后一行:
/etc/ufw# don't delete the 'COMMIT' line or these rules won't be processed COMMIT对于每个表,需要相应的 COMMIT语句。在这些示例中,仅显示nat和筛选器表,但还可以为原始表和人为表添加规则。
注意
在上面的示例中,将 eth0、eth1和192.168.0.0.24替换为适用于您的网络的适当接口和 IP 范围。
-
最后,禁用并重新启用 ufw 以应用更改:
sudo ufw disable && sudo ufw enable
现在应启用 IP 伪装。您还可以向 添加任何其他 FORWARD 规则。建议将这些附加规则添加到ufw 前链中。/etc/ufw/before.rules
iptables 伪装
iptables 也可用于启用伪装。
-
与 ufw 类似,第一步是通过编辑和取消注释以下行来启用 IPv4 数据包转发:
/etc/sysctl.confnet.ipv4.ip_forward=1如果您希望启用 IPv6 转发也取消注释:
net.ipv6.conf.default.forwarding=1 -
接下来,执行 sysctl 命令以在配置文件中启用新设置:
sudo sysctl -p -
现在可以使用单个 iptables 规则完成 IP 伪装,该规则可能因网络配置略有不同:
sudo iptables -t nat -A POSTROUTING -s 192.168.0.0/16 -o ppp0 -j MASQUERADE上述命令假定您的私人地址空间为 192.168.0.0/16,并且您的面向 Internet 的设备为 ppp0。语法细分如下:
-
- t nat = 规则是进入 nat 表
-
- 后路由 – 规则将追加到后路由链 (-A)
-
-s 192.168.0.0/16 = 规则适用于来自指定地址空间的流量
-
-o ppp0 = 规则适用于计划通过指定网络设备路由的流量
-
- j Masquerade – 此规则匹配的流量是 "跳转" (- j) 到要操作的 Masquerade 目标, 如上所述
-
-
此外,筛选器表中的每个链(默认表以及发生大多数或所有数据包筛选的位置)都有默认策略"接受",但如果除了网关设备之外,您还要创建防火墙,则可能将策略设置为"删除"或"拒绝",在这种情况下,需要允许伪装的流量通过 FORWARD 链才能使上述规则正常工作:
sudo iptables -A FORWARD -s 192.168.0.0/16 -o ppp0 -j ACCEPT sudo iptables -A FORWARD -d 192.168.0.0/16 -m state --state ESTABLISHED,RELATED -i ppp0 -j ACCEPT上述命令将允许从本地网络到 Internet 的所有连接以及与这些连接相关的所有流量返回到启动这些连接的机器。
-
如果要在重新启动时启用伪装(您可能这样做),请编辑并添加上面使用的任何命令。例如,添加第一个不带筛选的命令:
/etc/rc.localiptables -t nat -A POSTROUTING -s 192.168.0.0/16 -o ppp0 -j MASQUERADE
日志
防火墙日志对于识别攻击、对防火墙规则进行故障排除以及注意到网络上的异常活动至关重要。但是,您必须在防火墙中包含日志记录规则才能生成它们,并且日志记录规则必须先于任何适用的终止规则(具有决定数据包命运的目标的规则,如"接受、删除"或"拒绝")。
如果使用 ufw,可以通过在终端中输入以下内容来打开日志记录:
sudo ufw logging on
若要在 ufw 中关闭日志记录,只需在上述命令中将"关闭"替换。
如果使用 iptables 而不是 ufw,请输入:
sudo iptables -A INPUT -m state --state NEW -p tcp --dport 80
-j LOG --log-prefix "NEW_HTTP_CONN: "
然后,来自本地计算机的端口 80 上的请求将在 dmesg 中生成如下所示的日志(单行拆分为 3 以适合此文档):
[4304885.870000] NEW_HTTP_CONN: IN=lo OUT= MAC=00:00:00:00:00:00:00:00:00:00:00:00:08:00
SRC=127.0.0.1 DST=127.0.0.1 LEN=60 TOS=0x00 PREC=0x00 TTL=64 ID=58288 DF PROTO=TCP
SPT=53981 DPT=80 WINDOW=32767 RES=0x00 SYN URGP=0
上述日志也将显示在 和 中。可以通过适当编辑或安装和配置 ulogd 并使用 ULOG 目标而不是 LOG 来修改此行为。ulogd 守护进程是一个用户空间服务器,它侦听来自内核的专门针对防火墙的日志记录指令,并且可以记录到您喜欢的任何文件,甚至可以记录到 PostgreSQL 或 MySQL 数据库。通过使用日志分析工具(如日志监视、fwanalog、fwlogwatch 或 lire)可以简化防火墙日志的感知。/var/log/messages/var/log/syslog/var/log/kern.log/etc/syslog.conf
其他工具
有许多工具可以帮助您构建一个完整的防火墙,而无需深入了解 iptables。具有纯文本配置文件的命令行工具:
- Shorewall是一个非常强大的解决方案,可帮助您为任何网络配置高级防火墙。
使用ln命令在Linux系统中创建连接文件
| 导读 | 在Linux中ln命令用来为文件创建连接,连接类型分为硬连接(Hard Link)和符号连接(Symbolic Link)两种,默认的连接类型是硬连接。如果要创建符号连接必须使用"-s"选项。 |
硬连接是指通过索引节点来进行连接。在Linux的文件系统中,保存在磁盘分区中的文件不管是什么类型系统都会给它分配一个编号,称为索引节点号(Inode Index)。在Linux中,多个文件名指向同一索引节点是存在的,一般这种连接就是硬连接。硬连接的作用是允许一个文件拥有多个有效路径名,这样用户就可以建立硬连接到重要文件,以防止“误删”的功能。其原因如上所述,因为对应该目录的索引节点有一个以上的连接,所以只删除一个连接并不影响索引节点本身和其它的连接,只有当最后一个硬连接被删除后,文件的数据块及目录的连接才会被释放。也就是说,文件真正删除的条件是与之相关的所有硬连接文件均被删除。
符号连接(Symbolic Link),也叫软连接。软链接文件又类似于Windows的快捷方式。它实际上是一个特殊的文件。在符号连接中,该文件实际上是一个文本文件,其中包含着另一文件的位置信息。
root@Orangepi:~/test# touch file1 #创建一个测试文件 root@Orangepi:~/test# ln file1 file2 #创建file的一个硬连接文件file2 root@Orangepi:~/test# ln -s file1 file3 #创建file的一个符号连接文件file3 root@Orangepi:~/test# ls -li #-l参数以单列格式输出文件信息,-i参数输出文件的inode节点信息 total 0 28125 -rw-r--r-- 2 root root 0 Feb 16 08:29 file1 28125 -rw-r--r-- 2 root root 0 Feb 16 08:29 file2 31463 lrwxrwxrwx 1 root root 5 Feb 16 08:30 file3 -> file1
从上面的结果中可以看出,硬连接文件file2与原文件file1的inode节点相同,均为28125,然而符号连接文件的inode节点不同。
root@Orangepi:~/test# cat >>file1 <<EOF #向文件file1追加内容 > 12345 > EOF root@Orangepi:~/test# cat file1 #输出文件file1内容 12345 root@Orangepi:~/test# cat file2 #输出文件file2内容 12345 root@Orangepi:~/test# cat file3 #输出文件file3内容 12345 root@Orangepi:~/test# rm file1 #删除文件file1 root@Orangepi:~/test# cat file2 12345 root@Orangepi:~/test# cat file3 cat: file3: No such file or directory
通过上面的测试可以看出:当删除原始文件file1后,硬连接文件file2不受影响,但是符号连接文件file1无效。
依此你可以做一些相关的测试,可以得到以下全部结论:
1. 删除符号连接file3,对文件file1,file2无影响;
2. 删除硬连接file2,对文件file1,file3也无影响;
3. 删除原文件file1,对硬连接文件file2没有影响,但是会导致符号连接file3失效;
4. 同时删除原文件file1以及硬连接文件file2,整个文件才会真正的被删除。
ln -s /home/fei/workspace /var/www
注意:源目录和目标目录都必须是绝对路径
Ubuntu 下conda的安装与使用
conda是一个开源的软件包管理系统和环境管理系统,用于安装多个版本的软件包及其依赖关系,并在它们之间轻松切换。 conda是为 Python 程序创建的,适用于 Linux,OS X 和Windows,也可以打包和分发其他软件。conda分为anaconda和miniconda,anaconda是包含一些常用包的版本,miniconda则是精简版,只包含 conda 和其依赖,所以推荐使用miniconda。本文以Ubuntu 16.04 LTS系统为例,介绍miniconda的安装与使用。
1 用wget命令下载
wget -c https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh

2 安装命令
添加权限并运行
chmod 777 Miniconda3-latest-Linux-x86_64.sh
sh Miniconda3-latest-Linux-x86_64.sh
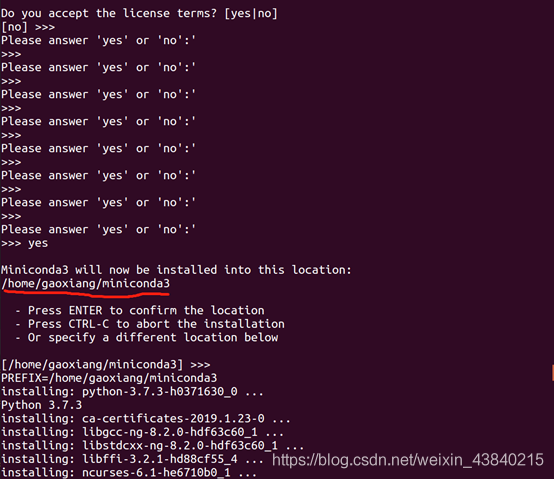
安装过程中,提示阅读用户许可协议,需要按“Enter”继续,并输入 “yes”继续安装,并列出conda安装的具体路径,这个路径保存一下。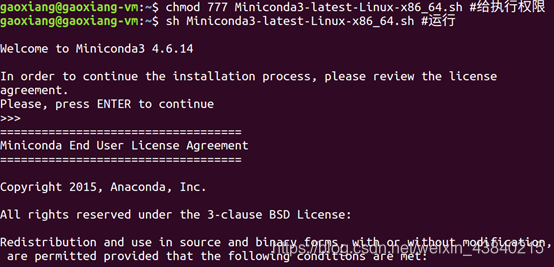
最后询问是否初始化Miniconda3时,选“no”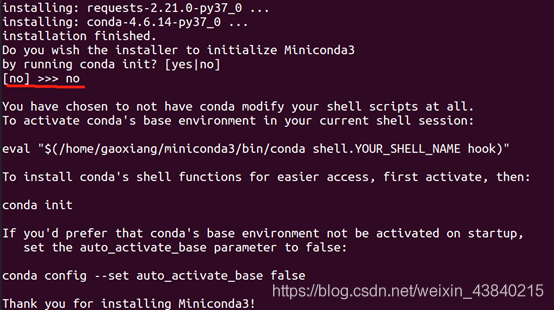
3 验证conda是否安装成功
输入conda命令,如未成功输出,见下图
conda
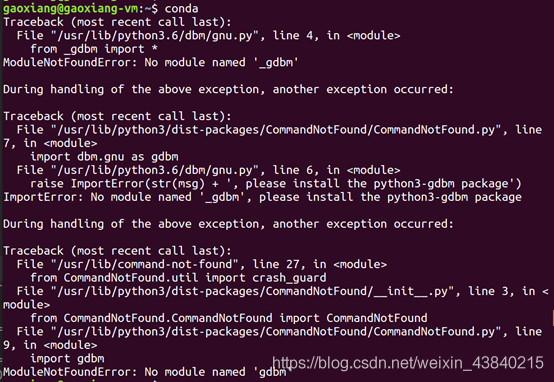
使用vim工具,编辑.bashrc文件
vim ~/.bashrc
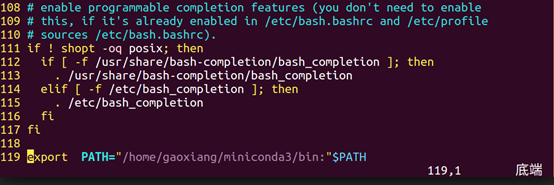
在最下行输入miniconda3的安装目录作为环境变量,与上面保存的安装目录相同,本文是“/home/gaoxiang/miniconda3”
export PATH="/home/gaoxiang/miniconda3/bin:"$PATH
输入命令使.bashrc文件生效
source ~/.bashrc
输入conda命令,如正常返回,说明conda安装成功
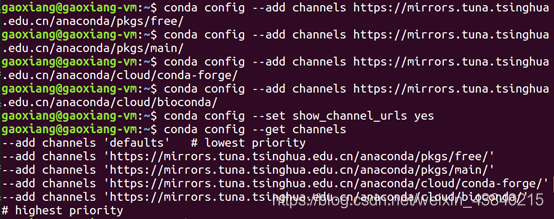
4 添加清华大学的镜像源
这样安装其他包的时候,下载速度会很快
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda/
conda config --set show_channel_urls yes
conda config --get channels
5 环境管理命令
可使用如下命令查看已有环境列表,*表示当前环境,base表示默认环境
conda env list

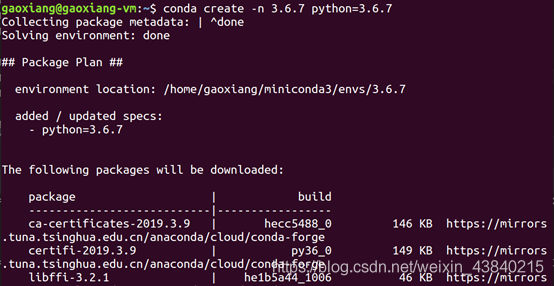
使用命令“conda create -n 环境名称 python=版本号”创建环境,这里创建了名称为3.6.7(名称不是很好)的python版本号为3.6.7的虚拟环境,稍微等待,过程中输入“y”。
conda create -n 3.6.7 python=3.6.7
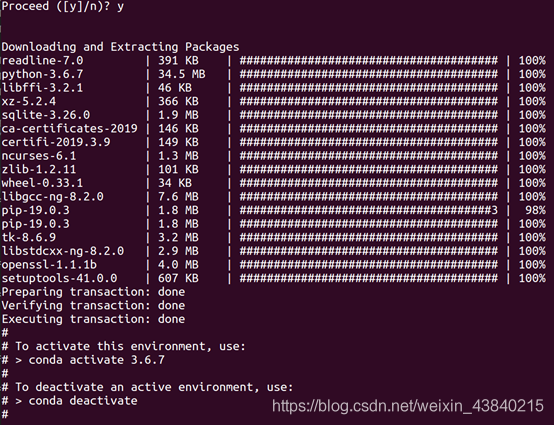
查看环境列表,新环境已经创建好
激活环境,默认处于base环境,进入其他环境需要使用source activate手动切换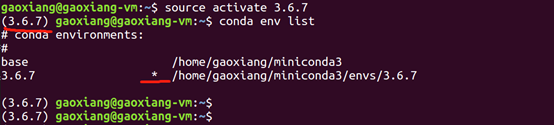
若要退出当前环境,使用source deactivate,默认回到base 环境
这里提示命令“source deactivate”已经废弃了,使用“conda deactivate”
6 进入环境安装依赖包
进入环境后,可使用如下命令安装依赖的包,使用的是已经配置好的清华的源,这里以“opencv-python”包为例,由于使用了清华大学的镜像源,下载速度很快。
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple opencv-python
pytorch已发布1.1.0版本,升级至pytorch最新版本命令。
pip install --upgrade -i https://pypi.tuna.tsinghua.edu.cn/simple torch torchvision
清华的镜像源已经恢复如果要换回conda默认的源,访问起来可能有些慢:conda config --remove-key channels
ImportError: cannot import name 'MNIST'
Note that python-mnist and mnist are two different packages, and they both have a module called mnist. The package you want is python-mnist. So do this:
pip install python-mnist
It might be necessary to uninstall the mnist package with:
pip uninstall mnist手写数字数据库: https://pypi.org/project/python-mnist/0.3/
解决ModuleNotFoundError: No module named 'numpy.core._multiarray_umath' 错误
一、错误原因分析
程序和数据都是正确的,一开始也是可以正常运行的,后面服务器卡死,无法正常操作,就只能强制关机!,所以问题就是强制关机导致模型没有正确保存,因而导致了保存的模型破损,当再次重启的时候加载之前的模型就报了上面的错误!
二、解决方式
把之前的模型删除即可(如果有之前备份的模型放进去也可以)。
其他相关错误解决方式:
当然有人可能遇到的不是这个问题,那就请你自行升级一下numpy的版本,可能是因为你的numpy版本太低
查看numpy的当前版本
conda list numpy
或
pip show numpy
更新numpy的版本
pip install --upgrade numpy
或
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple --upgrade numpy导入tensorflow 因numpy报错:ModuleNotFoundError: No module named 'numpy.core._multiarray_umath'
卸载numpy,然后重新安装。pip uninstall numpypip install numpy
jupyter notebook connecting to kernel problem
显示的是无法连接到python,不知道为什么,帮他们装的notebook居然都是中文,后来发现是 no connection to kernel
具体操作
pip install tornado==4.5.3
这是版本问题,现在直接 pip install jupyter notebook 时,附带安装的 tornado 是6.0版本的,而能操作的是4.5.3版本。
控制台安全性
禁用 Ctrl+Alt+DEL
任何对键盘具有物理访问权限的人只需使用Ctrl+Alt+Delete键组合即可重新启动服务器,而无需登录。虽然有人可以简单地拔下电源插头,但您仍应防止在生产服务器上使用此键组合。这迫使攻击者采取更严厉的措施重新启动服务器,并将同时防止意外重新启动。
要禁用按Ctrl+Alt+删除键组合执行的重新启动操作,请运行以下两个命令:
sudo systemctl mask ctrl-alt-del.target
sudo systemctl daemon-reloadFtp:https://ubuntu.com/server/docs/service-ftp
Ubuntu安装v 2ray client图形客户端
Snap方式安装Qv 2ray

下载v 2ray core
Qv 2ray只是图形界面,它需要v 2ray core通信核心支持,才可以正常工作。到下载页面下载v 2ray core内核:
https://github.com/v 2ray/v 2ray-core/releases下载对应的版本,比如,我下载的 v 2ray-linux-64.zip 。解压后,复制到qv 2ray的安装目录下(其实,复制任何目录下都可以,只要在配置里填对就行)
# 复制到默认目录下
cp -r ./v 2ray-linux-64/ /home/${USER}/snap/qv 2ray/提示:也可以复制到默认目录下(不推荐这么做,因为qv 2ray自动更新时,内核会被删除)。默认 /home/${USER}/snap/qv 2ray/77/.config/qv 2ray/ 目录(snap安装方式的默认目录):
# 复制到默认目录下
cp -r ./v 2ray-linux-64/ /home/${USER}/snap/qv 2ray/2951/.config/qv 2ray/# 修改成默认名称
mv /home/${USER}/snap/qv 2ray/2951/.config/qv 2ray/v 2ray-linux-64/home/${USER}/snap/qv 2ray/2951/.config/qv 2ray/vcore
其中 2951是版本号。
配置 Qv 2ray
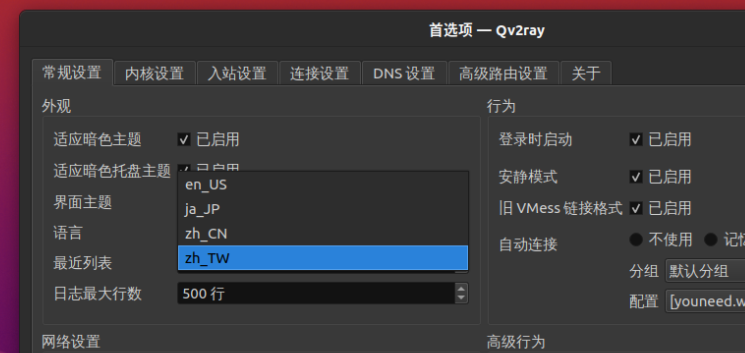
设置语言
将其设置为中文,依次点击 Preferences(首选项) -> General Settings(常规设置),将 Language 设置为 zh-CN ,点击 OK 即可:
配置核心
点击 首选项 -> 常规设置, 填写上面核心的存放路径(${USER} 是你当前登陆电脑的用户名,你下载的core的路径):
核心可执行文件路径: /home/${USER}/snap/qv 2ray/v 2ray-linux-64/v 2ray
v 2ray资源目录: /home/${USER}/snap/qv 2ray/v 2ray-linux-64/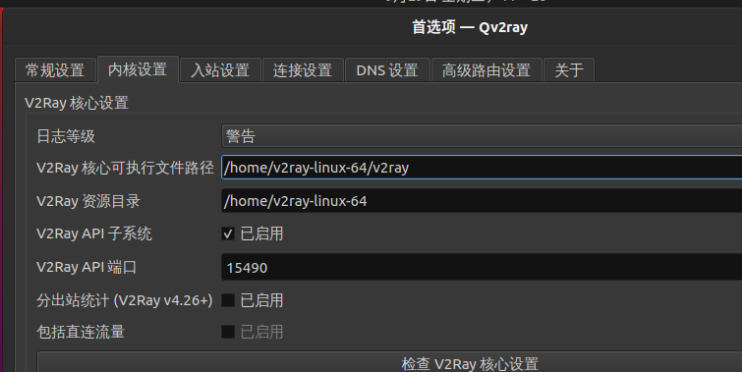
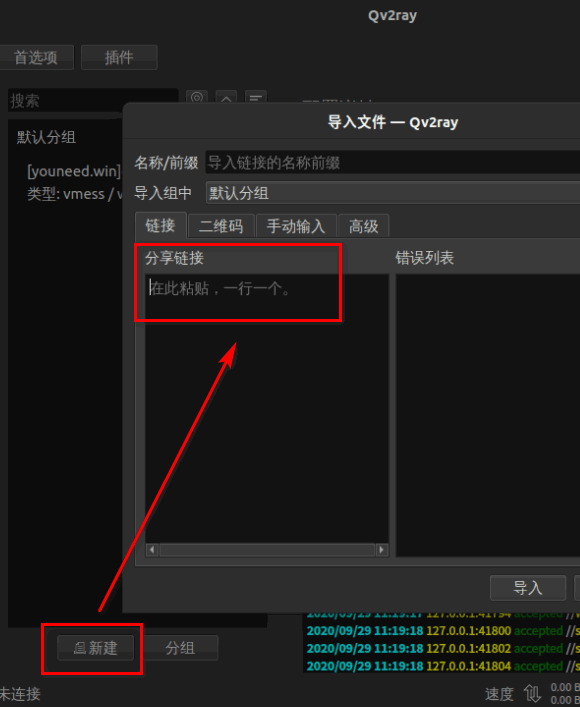
添加订阅节点或vmess链接
入站设置
设置响应端口,比如,我这里设置端口为 1088 和 8888 :

同时,电脑系统的代理,设置为自动:
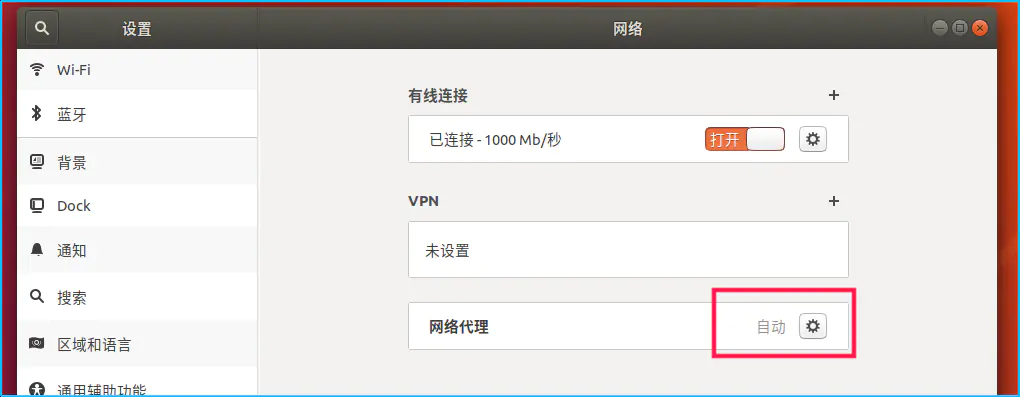
至此,安装配置完成,尝试在浏览器中打开代理的网站 :
https://qv 2ray.net/getting-started/
时间同步: https://ubuntu.com/server/docs/network-ntp
网络配置:https://ubuntu.com/server/docs/network-configuration
Ubuntu 常用查找文件与文件内容指令
查找文件
locate
作用相当于find -name,但是locate速度会比find快很多,因为locate命令也是用数据库查找的。
因为该数据库默认是一天更新一次的,所有使用locate命令有可能找不到最近新建的文件。这时就需要手动更新数据库,命令很简单,直接在终端中输入sudo updatedb就可以进行更新,更新速度还是比较快的,所以在搜索文件的时候建议使用locate命令。
示例:
locate main.c
find
该命令直接查找硬盘,所以花费时间比较长。该命令可以找到你想要的任何文件,下边是一些比较好用的命令。
| 格式 | 含义 |
|---|---|
| find -name filename | 在根目录中寻找名字为filename的文件 |
| find -name s | 在目录里面搜索带有s的文件 |
| find -name *s | 在目录里面搜索以s结尾的文件 |
| find -name s* | 在目录里面搜索以s开头的文件 |
| find -amin -10 | 在系统中搜索最后10分钟访问的文件 |
| find -atime -2 | 查找在系统中最后48小时访问的文件 |
| find -mmin -5 | 查找在系统中最后5分钟修改过的文件 |
| find -mtime -1 | 查找在系统中最后24小时修改过的文件 |
查找文件中的关键字
grep
有些时候我们不仅仅是想找我们需要的文件,还想找到文件中的某些关键字,这个时候我们就需要借助Ubuntu自带的强大的搜索工具——grep
grep(global search regular expression(RE) and print out the line,全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。
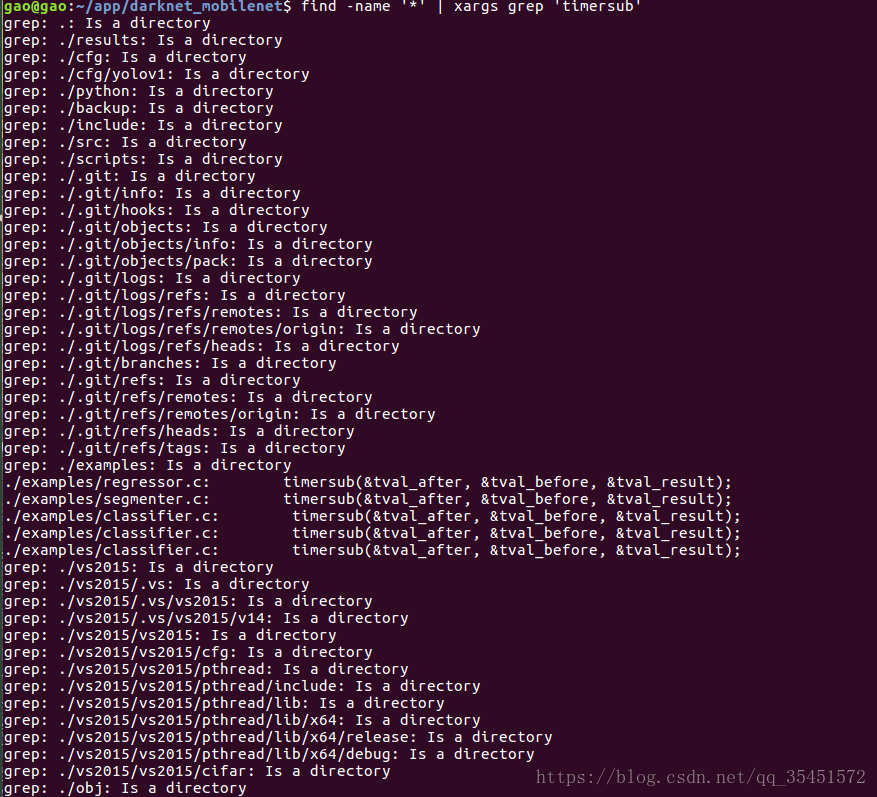
find / -name '*' | xargs grep 'timersub'
通过使用find与grep使我们能够更好地找到文件中的关键字。
上边的指令就是通过find与grep相结合查找所有子文件中包含timersub关键字的文件,如果文件中包含该关键字,在终端中就会打印出来。
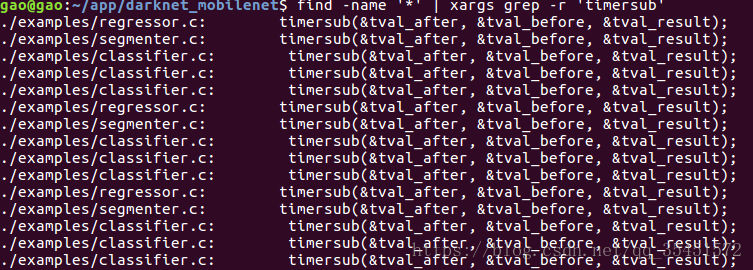
直接使用上边的指令进行搜索的时候,会出现很多的Is a directory无关紧要的提示信息,我们可以借助grep -r只搜索子目录的内容就能够避免提示。将上边的命令改为:
find / -name '*' | xargs grep -r 'timersub'
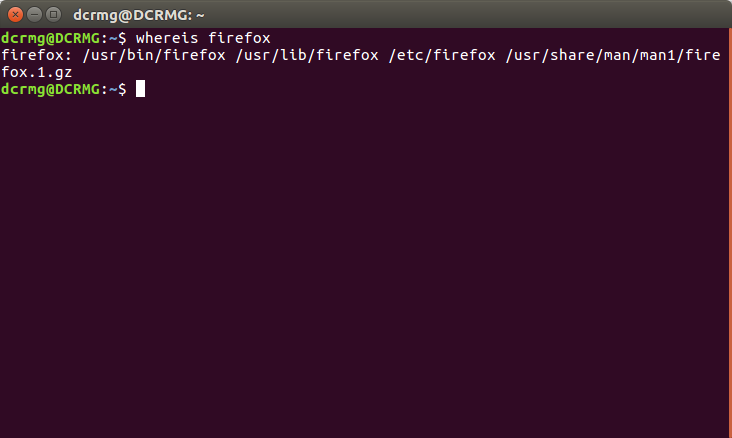
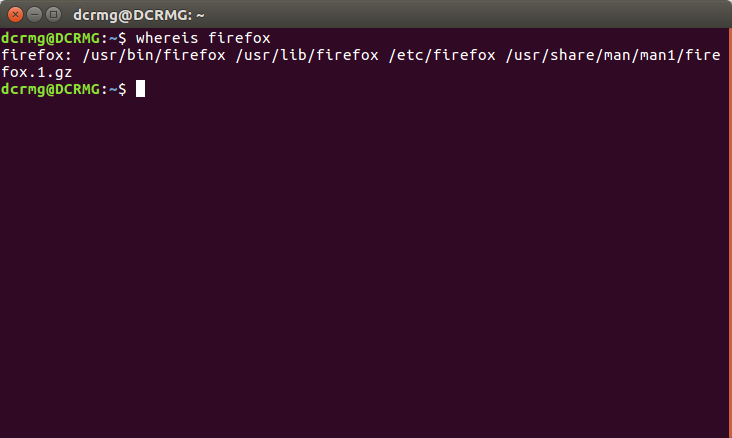
1. whereis+文件名
用于程序名的搜索,搜索结果只限于二进制文件(参数-b)、man说明文件(参数-m)和源代码文件(参数-s),如果省略参数,则返回所有信息。
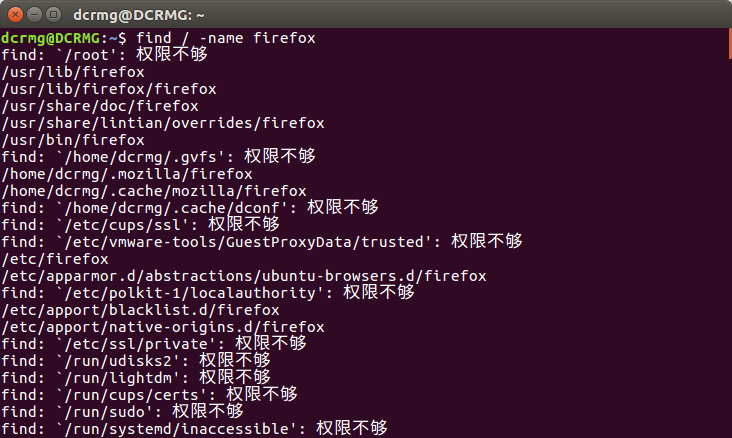
2. find / -name +文件名
find是在指定的目录下遍历查找,如果目录使用 / 则表示在所有目录下查找,find方式查找文件消耗资源比较大,速度也慢一点。
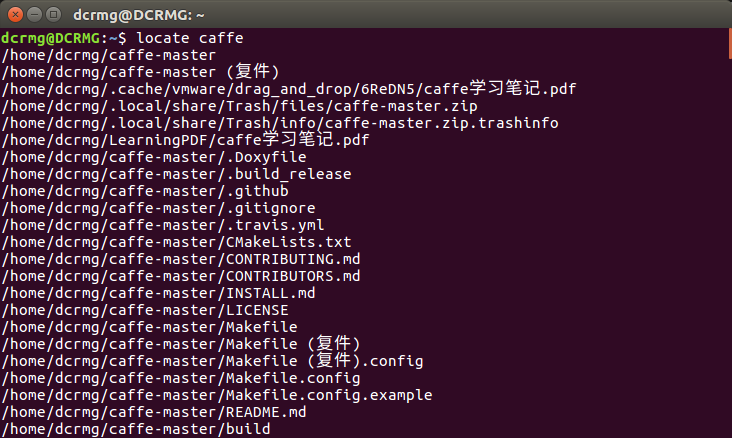
3. locate+文件名
linux会把系统内所有的文件都记录在一个数据库文件中,使用locate+文件名的方法会在linux系统维护的这个数据库中去查找目标,相比find命令去遍历磁盘查找的方式,效率会高很多,比较推荐使用这种方法。
但有一个问题是数据库文件不是实时更新的,一般会每周更新一次,所以使用locate命令查找到的结果不一定是准确的。当然可以在使用locate之前通过 updatedb 命令更新一次数据库,保证结果的性。
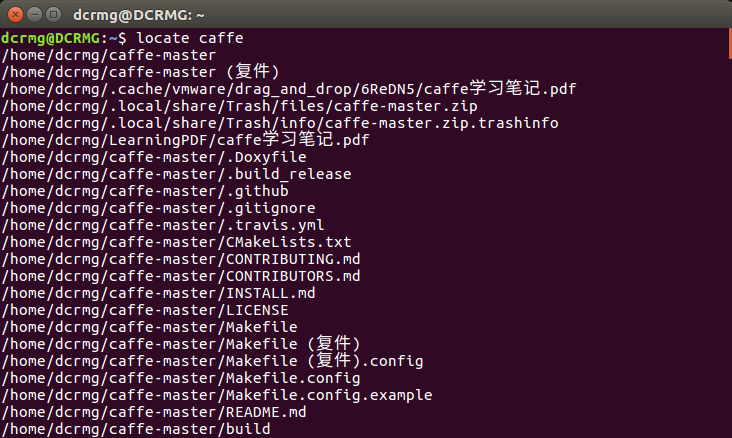
4. which+可执行文件名
which的作用是在PATH变量指定的路径中,搜索某个系统命令的位置,并且返回第一个搜索结果。
使用which命令,就可以看到某个系统命令是否存在,以及执行的到底是哪一个位置的命令。
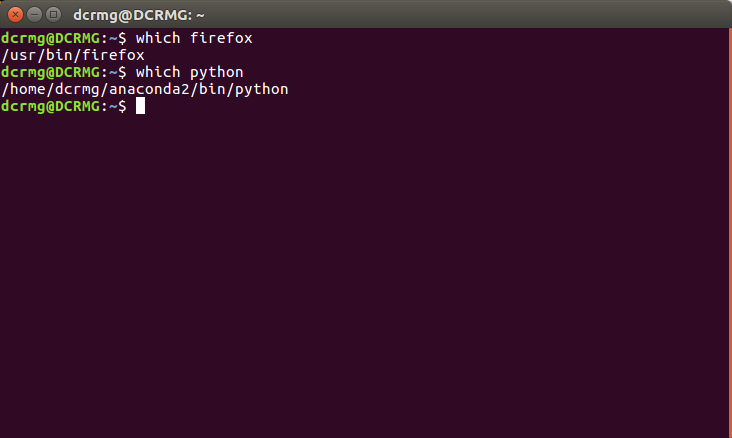
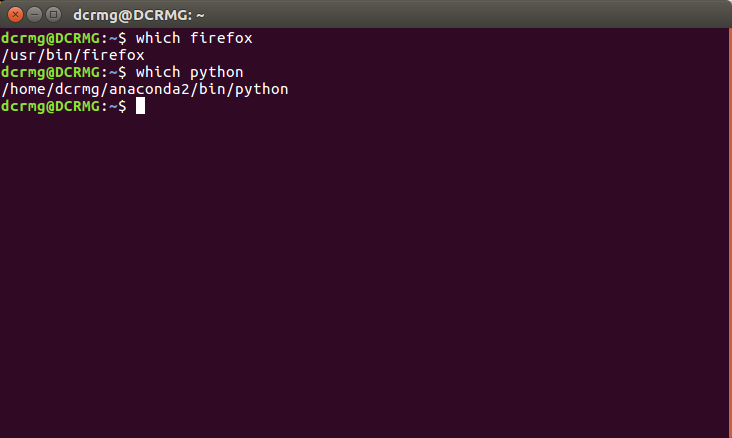
which指令会在环境变量$PATH设置的目录里查找符合条件的文件,所以基本的功能是寻找可执行文件。
适合初学者的网络配置教程
https://linuxconfig.org/netplan-network-configuration-tutorial-for-beginners
https://linuxconfig.org/ubuntu
教你vim如何自动格式化代码
在vim中其实也有自动格式化代码的操作,尽管非常强大,但是通常会破坏代码的原有的缩进,
所以不建议在python这样缩进代替括号的语言中和源程序已经缩进过的代码中使用,下面说步骤:
1,gg 跳转到第一行
2,shift+v(V) 转到可视模式
3,shift+g(G) 全选
4,按下神奇的 =
格式化全文: gg=G
自动缩进当前行: ==
格式化当前光标接下来的10行: 10=
格式化选定的行: v (向上下选择)=
官方解释:http://vimdoc.sourceforge.net/cgi-bin/vimfaq2html3.pl#14.6
Ubuntu 重启GUI
1.第一种方法是销毁最少的方法,但是,它可能不会提供预期的结果。
ALT + F2
Enter a Command
r
2.另一种替代的进行GUI重新启动技巧可能是最明显的,只是重新登录。
3.重新启动作为非特权用户。gnome-shell
打开终端并输入命令。gnome-shell --replace
4.重新启动 GUI 解决方案保证在系统仍然正常运行时,即使您的 GUI 冻结,也可重新启动桌面。但是,它需要管理权限。sudo
在 GUI 中,要么直接将命令输入终端。但是,如果您的 GUI 被冻结,您可能需要首先使用 、登录和执行命令来更改 TTY 控制台。
sudo systemctl restart systemd-logind
CTRL + ALT + F2
5.重新启动显示管理器,因此也将重新启动 GNOME 外壳。
CTRL + ALT + F2
sudo systemctl restart gdm
sudo systemctl restart lightdm
https://linuxconfig.org/how-to-restart-gui-on-ubuntu-20-04-focal-fossa