操作系统---内存管理(上) 概念 覆盖交换技术 连续分配管理方式
内存管理学习笔记 :
操作系统---内存管理(上) 概念 覆盖交换技术 连续分配管理方式
操作系统---内存管理(下) 分段存储 段页式存储 虚拟内存 请求分页管理方式
大纲#
什么是内存#
内存是用于存放数据的硬件
程序执行前需要先放到内存中才能被cpu处理
存储单元#
如果计算机"按字节编址", 每个存储单元大小为8 bit
如果计算机"按字编址", 每个存储单元大小为16 bit
逻辑地址和物理地址#
指令的编指一般采用逻辑地址, 即相对地址
物理地址 = 起始地址 + 逻辑地址 (理解)
编译, 链接, 装入#
编译 : 由编译程序将用户源代码编译成若干个目标模块
链接 : 由连接程序将编译后形成的一组目标模块以及所需函数连接在一起, 形成一个完整的装入模块
链接的三种方式 :
- 静态链接-----装入模块不再拆开
- 装入时动态链接-----将各目标模块装入内存时, 边装入边链接的连接方式
- 运行时动态链接-----在程序执行中需要该目标模块时才对它进行链接
装入 : 由装入程序将装入模块装入内存运行
装入的三种方式:
- 绝对装入
- 静态重定位
- 动态重定位
绝对装入 : 在编译时, 如果知道程序将放到内存的哪个位置, 编译程序将产生绝对地址的目标代码, 装入程序按照装入模块中的地址, 将程序和数据装入内存 ------灵活性低, 只适合单道程序环境
静态重定位 : 又称为可重定位装入. 编译, 链接后的装入模块地址都是从0开始的, 指令中使用的地址和数据存放的地址都是相对于起始地址而言的逻辑地址. 可以根据内存的当前状况将装入模块装入到内存的适当位置. 装入时对地址进行"重定位", 逻辑地址变换为物理地址(地址变换是在装入时一次完成的).
动态重定位 : 装入程序把装入模块装入内存后不会立即把逻辑地址转换为物理地址, 而是把地址转换推迟到程序真正要执行时才进行. 因此装入内存后所有的地址依然是逻辑地址. 这种方式需要一个重定位寄存器(存放装入模块的起始位置)的支持
内存管理的概念#
进程应该放在内存的哪里?
操作系统如何记录哪些内存区域已经被分配了, 哪些还空闲?
当进程运行结束之后, 如何将进程占用的内存空间释放?
-
操作系统负责内存空间的分配与回收
-
操作系统需要提供某种技术从逻辑上对内存空间进行扩充
-
操作系统需要实现地址转换功能, 负责程序的逻辑地址和物理地址的转换
-
操作系统需要提供内存保护功能, 保证各进程在各自存储空间内运行, 互不干扰
实现内存保护的两种方法:- 在CPU设置一对上, 下限寄存器, 存放进程的上, 下限地址. 进程的指令要访问某个地址时, CPU检查是否越界
- 采用重定位寄存器(又叫基地址寄存器) 和界地址寄存器(又叫限长寄存器) 进行越界检查. 重定位寄存器中存放的是进程的起始物理地址, 界地址寄存器中存放的是进程的最大逻辑地址.
内存空间的扩充#
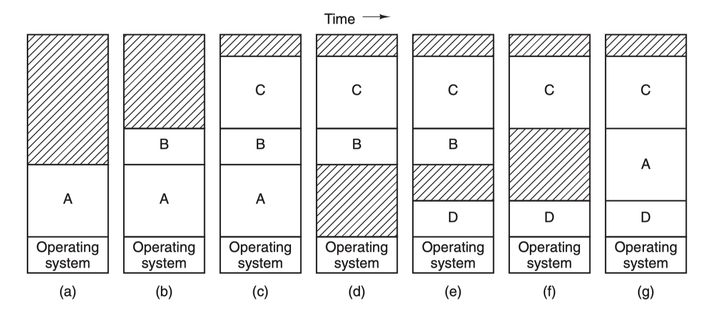
覆盖与交换#
覆盖, 交换, 虚拟存储技术常用于实现内存空间的扩充
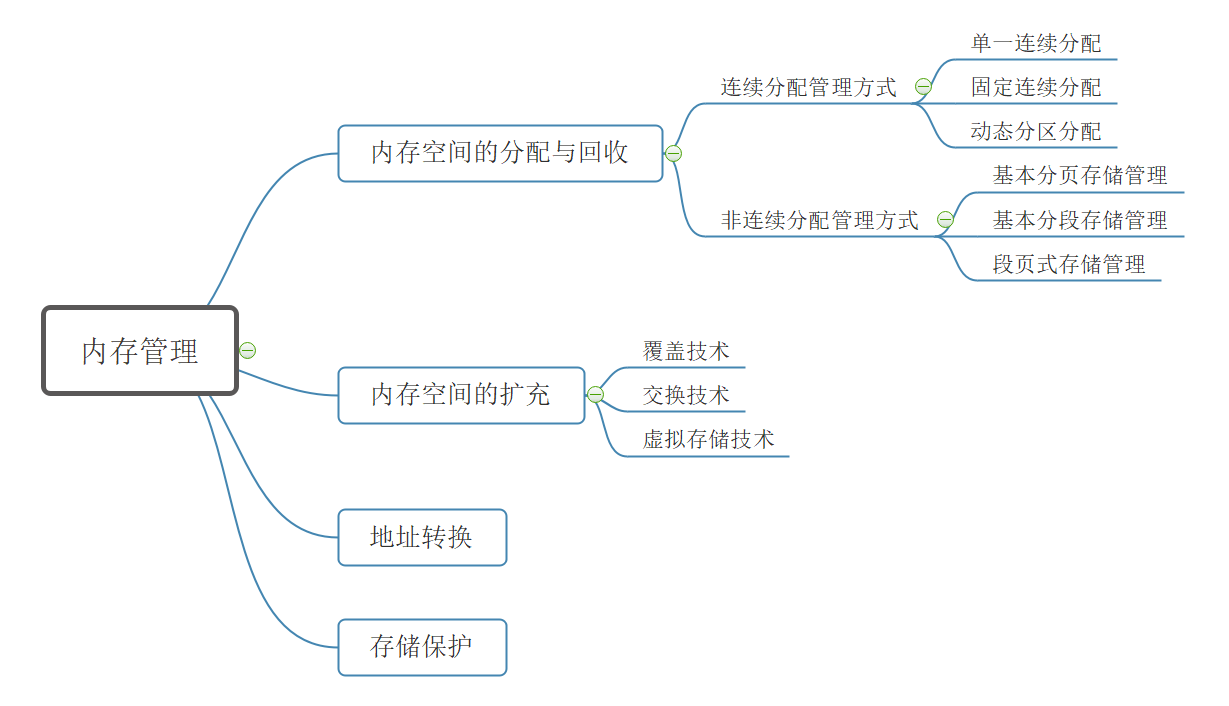
覆盖技术#
覆盖技术的思想 : 将程序分为多个段, 常用的段常驻内存, 不常用的段在需要的时候调入内存
内存中分为一个"固定区" 和若干个"覆盖区", 常用的段放在固定区, 不常用的段放在覆盖区
缺点 : 必须由程序员声明覆盖结构, 对用户不透明, 增加了用户的编程负担, 覆盖技术只用于早期的操作系统中.
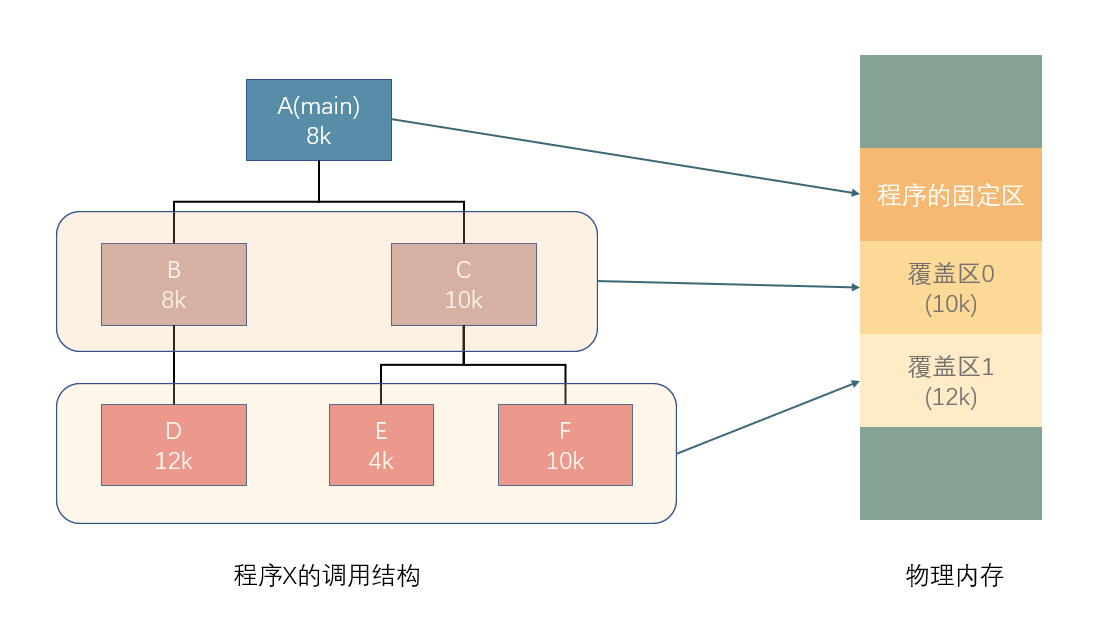
交换技术#
交换技术的思想 : 内存空间紧张时, 系统将内存中某些进程暂时换出外存, 把外存中某些已具备运行条件的进程换入内存(即进程在内存与磁盘间动态调度)
内存空间的分配和回收#
连续分配管理方式#
单一连续分配#
在单一连续分配的方式中, 内存被分为系统区和用户区, 系统区用于存放操作系统的相关数据, 用户区用于存放用户进程的相关数据, 内存中只能有一道用户程序, 用户程序独占整个用户区空间.
-
优点 : 实现简单, 无外部碎片; 可以采用覆盖技术扩充内存; 不一定需要采取内存保护
-
缺点 : 只能用于单用户, 单任务的操作系统中; 有内部碎片; 存储器利用率极低
内部碎片 : 分配给某进程的内存区域有一部分没有用上, 即存在" 内部碎片 ".
外部碎片 : 内存中的某些空闲分区由于太小而难以利用

固定分区分配#
在产生了支持多道程序的系统后, 为了能在内存中装入多道程序而互相之间不产生干扰, 将整个用户区划分为若干个固定大小的分区(分区大小可以相等也可以不相等), 在每个分区中只能装入一道作业, 形成了最早的可运行多道程序的内存管理方式.

操作系统建立一个数据结构----分区说明表, 来实现各个分区的分配和回收, 每个表对应一个分区, 通常按分区大小排列. 每个表项包括对应分区的大小, 起始地址, 状态
-
优点 : 实现简单, 无外部碎片;
-
缺点 : 有内部碎片; 存储器利用率不高;
动态分区分配#
动态分区分配又称为可变分区分配, 这种分配方式不会预先划分内存分区. 而是在进程装入内存时根据进程大小动态地建立分区, 并使得分区的大小正好适合进程的需要.
几个问题 :
- 系统用什么数据结构记录内存的使用情况?
- 当多个空闲分区都满足需求应该选择哪个分区进行分配?
- 如何进行分区的分配和回收操作?
常用的数据结构 :
空闲分区表, 空闲分区链
动态分配不会产生内部碎片, 而会产生外部碎片, 外部碎片可以通过" 紧凑"的方式解决(把基地址迁移)
四种动态分配的算法
- 首次适应算法
每次都从低地址开始查找, 找到第一个能满足大小的空闲分区
实现 : 把空闲分区按地址递增的次序排列.
每次分配内存时顺序地查找空闲分区链, 找到大小能满足要求的第一个空闲分区.
- 最佳适应算法
优先使用小的空闲分区
实现 : 空闲分区按容量递增次序链接.
每次分配内存时顺序查找空闲分区链, 找到大小能满足要求的第一个空闲分区
缺点 : 每次都选择最小的分区进行分配, 会留下越来越多的容量很小难以利用的内存块, 即产生很多的外部碎片
- 最坏适应算法
优先使用大的空闲分区
实现 : 空闲分区按容量递减次序链接
缺点 : 每次都选用最大的分区进行分配, 当较大的连续空闲区被小号之后, 如果有大进程到来则没有内存分区可以利用
- 邻近适应算法
在首次适应算法的基础上, 每次都从上次查找结束的位置开始查找空闲分区链(表), 找到大小能满足的第一个空闲分区
缺点 : 邻近适应算法导致无论低地址还是高地址的空闲分区都有相同的概率被使用, 也就导致了高地址部分的大分区更可能被使用划分为小分区, 最后导致没有大分区可用
综合来看, 首次适应算法的性能最好
算法开销大 : 最佳适应法, 最坏适应法 ( 需要经常排序)
算法开销小 : 首次适应算法, 邻近适应算法
ref : https://www.bilibili.com/video/BV1YE411D7nH?p=36
王道考研视频的学习笔记, 顺便重新用ppt画了一下图, 主要是学习一下ppt作图..
操作系统---内存管理(中) 分页存储
内存管理学习笔记 :
操作系统---内存管理(上) 概念 覆盖交换技术 连续分配管理方式
操作系统---内存管理(下) 分段存储 段页式存储 虚拟内存 请求分页管理方式
上一节 : 操作系统---内存管理(上)
大纲 :
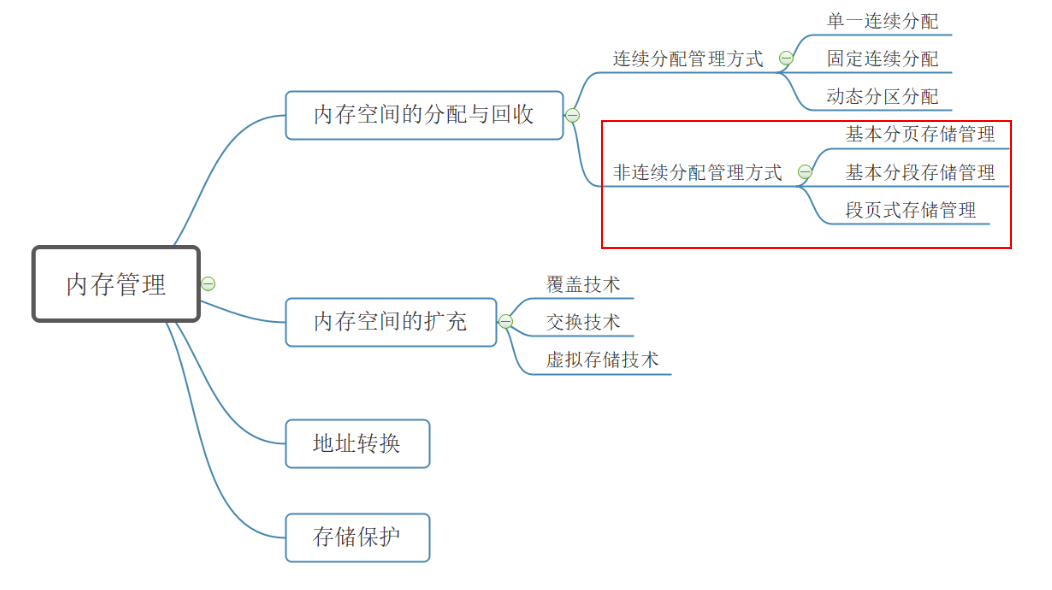
基本分页存储管理#
页框和页面#
思想 : 把内存分为一个个相等的小分区, 再按照分区大小把进程拆分成一个个小部分.
-
页框 :

-
页面 :

注意区分页框和页面的概念, 页框是针对内存的, 页面是针对进程的

地址转换的实现#
- 特点 : 页面离散存放, 但是页面内部连续存放
- 访问逻辑地址A : ( 重点 )
- 确定逻辑地址A的 " 页号 " P
- 找到P号页面在内存中的起始地址 ( 需要查找页表 )
- 确定逻辑地址A的 " 页内偏移 " W
- 逻辑地址 A的物理地址 = P号页面在内存中的起始地址 + 页内偏移量W
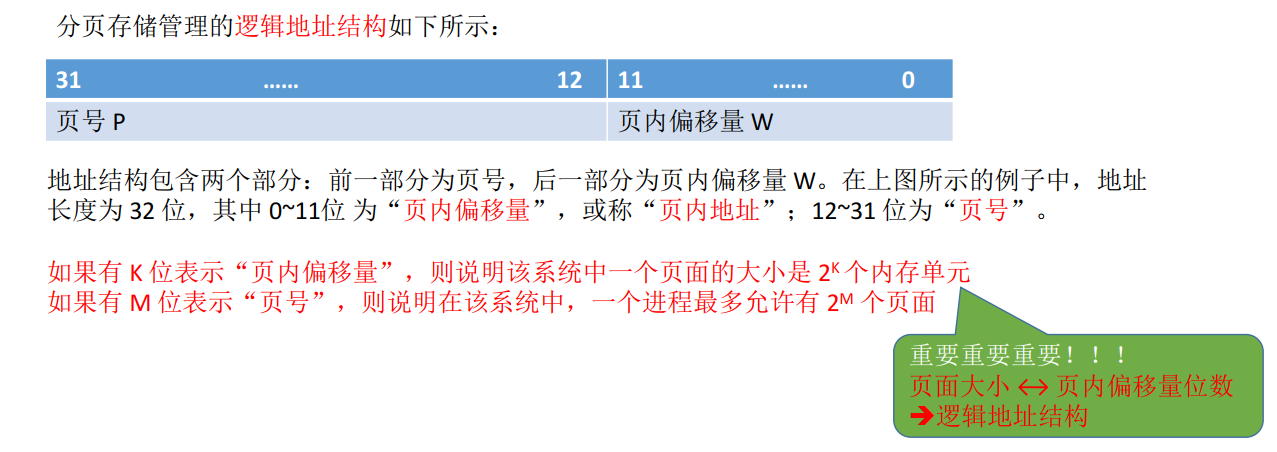
页号和页内偏移量#
e.g.

为了方便计算页号和页内偏移量, 页面大小一般设置为2的整数幂( why ? ) :

( 妙啊 )
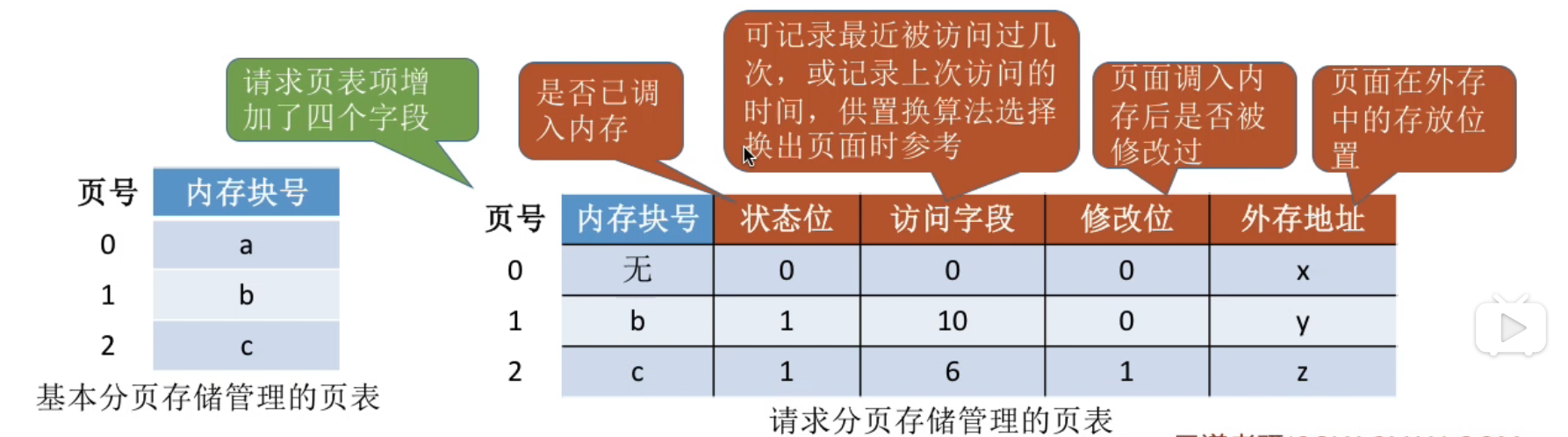
页表#
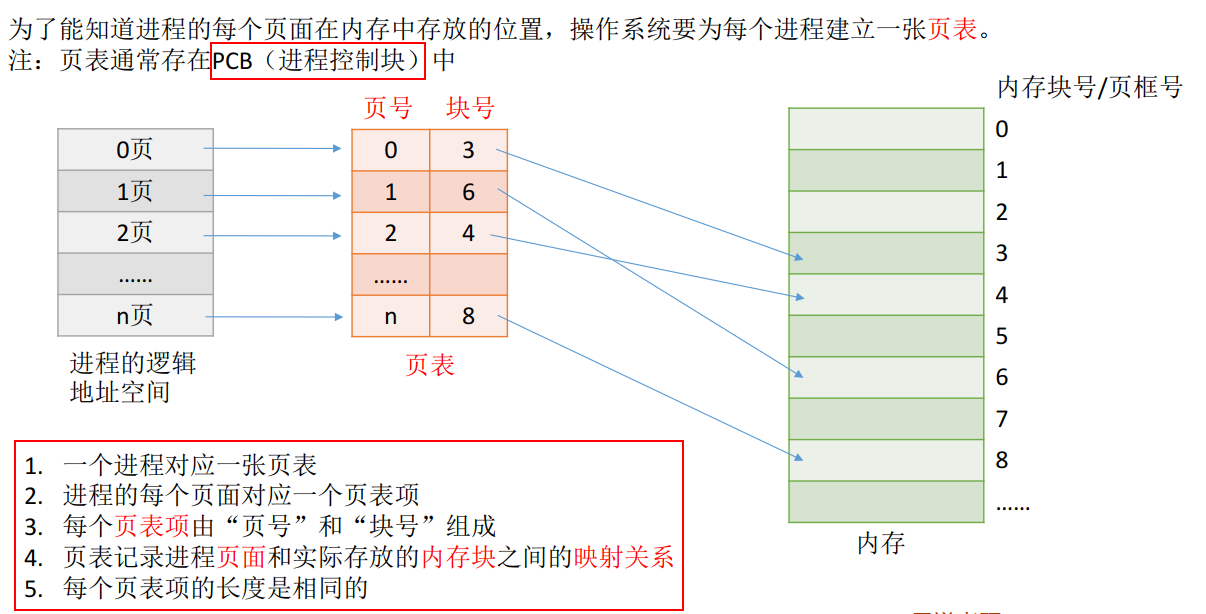
tips : 页表中的页号是"隐含"的, 可以不占用存储空间
e.g.
假设某系统物理内存大小为 4GB, 页面大小为 4KB, 则
每个页表项至少应该为多少字节?
- 内存块大小=页面大小=4KB= 212">
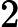 212B
212B - 4GB 的内存总共会被分为232212=220">
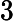
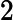
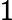

 232212=220个内存块
232212=220个内存块 - 内存块号的范围应该是 0 ~ 220−1">

 220−1
220−1 - 内存块号至少要用 20 bit 来表示
- 至少要用3B来表示块号(3*8=24bit)
(但是, 为了方便页表的查询, 常常会让一个页表项占更多的字节, 使得每个页面恰好可以装得下整数个页表项)
- 如何理解 "页号是隐含的" :

基本地址变换机构#
框图 : ( 重点 ! )
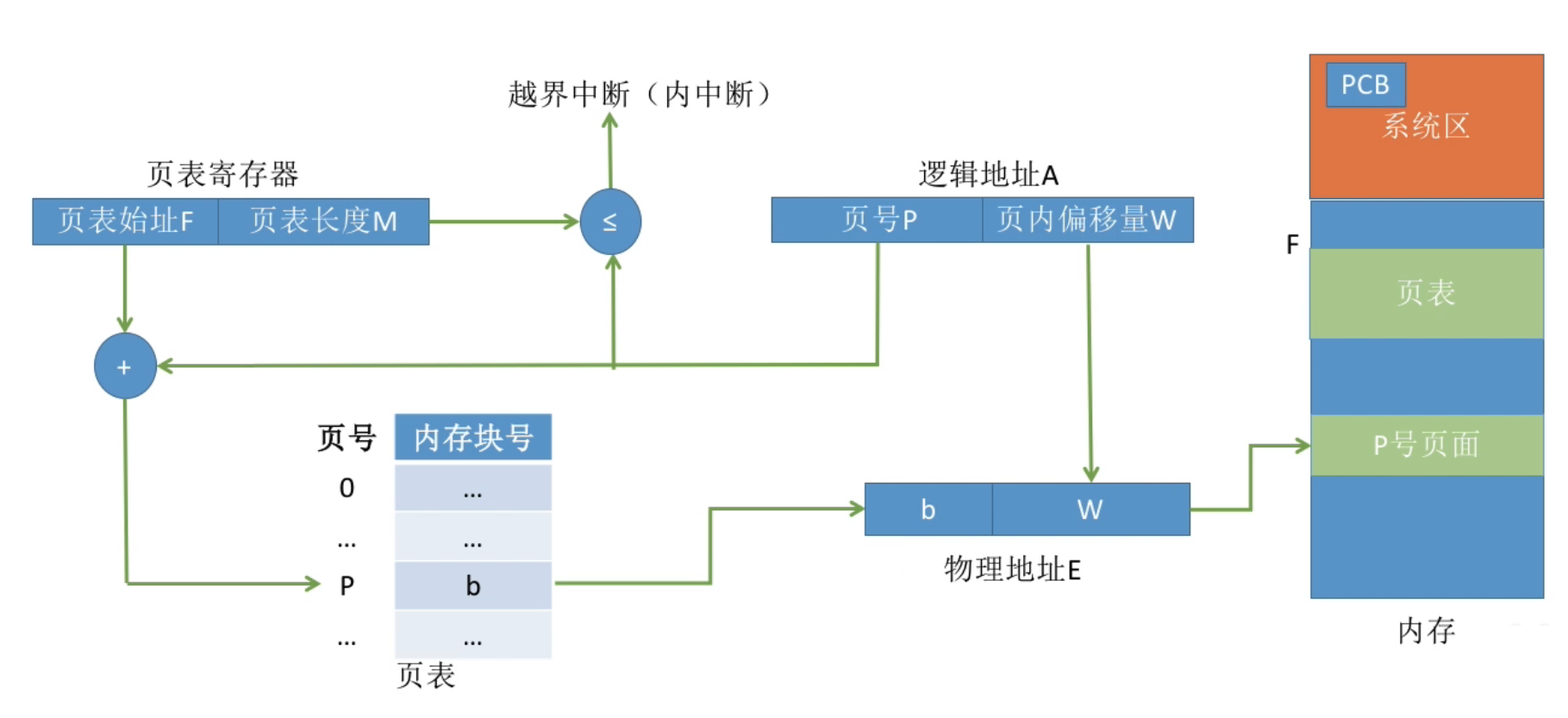
步骤总结 :
-
根据逻辑地址计算出页号和页内偏移量
-
判断页号是否越界
-
查询页表, 找到页号对应的页表项, 确定页面存放的内存块号
-
用内存块号和页内偏移量得到物理地址 ( 页表长度*物理块号 + 页内偏移 = 物理地址 ( 计算机直接采用拼接物理块号和页内偏移的方式得到物理地址 ) )
-
访问目标单元
( 一共需要访问两次内存 : 第一次用来查页表, 第二次用于访问目标内存单元 )
具有快表的地址变换机构#
局部性原理
-
时间局部性
如果执行了程序中的某条指令, 那么不久之后这条指令很有可能再次执行; 如果某个数据被访问过, 不久之后该数据很可能再次被访问
( 程序中存在大量的循环 )
-
空间局部性
一旦程序访问了某个存储单元, 在不久之后, 其附近的存储单元也很有可能被访问到
( 很多数据在内存中连续存放 )
快表(TLB)
快表又成为联想寄存器(TLB), 是一种访问速度比内存块很多的高速缓冲存储器, 用来存放当前访问的若干页表项, 以加速地址变换的过程. 与此对应的, 内存中的页表常称为慢表.
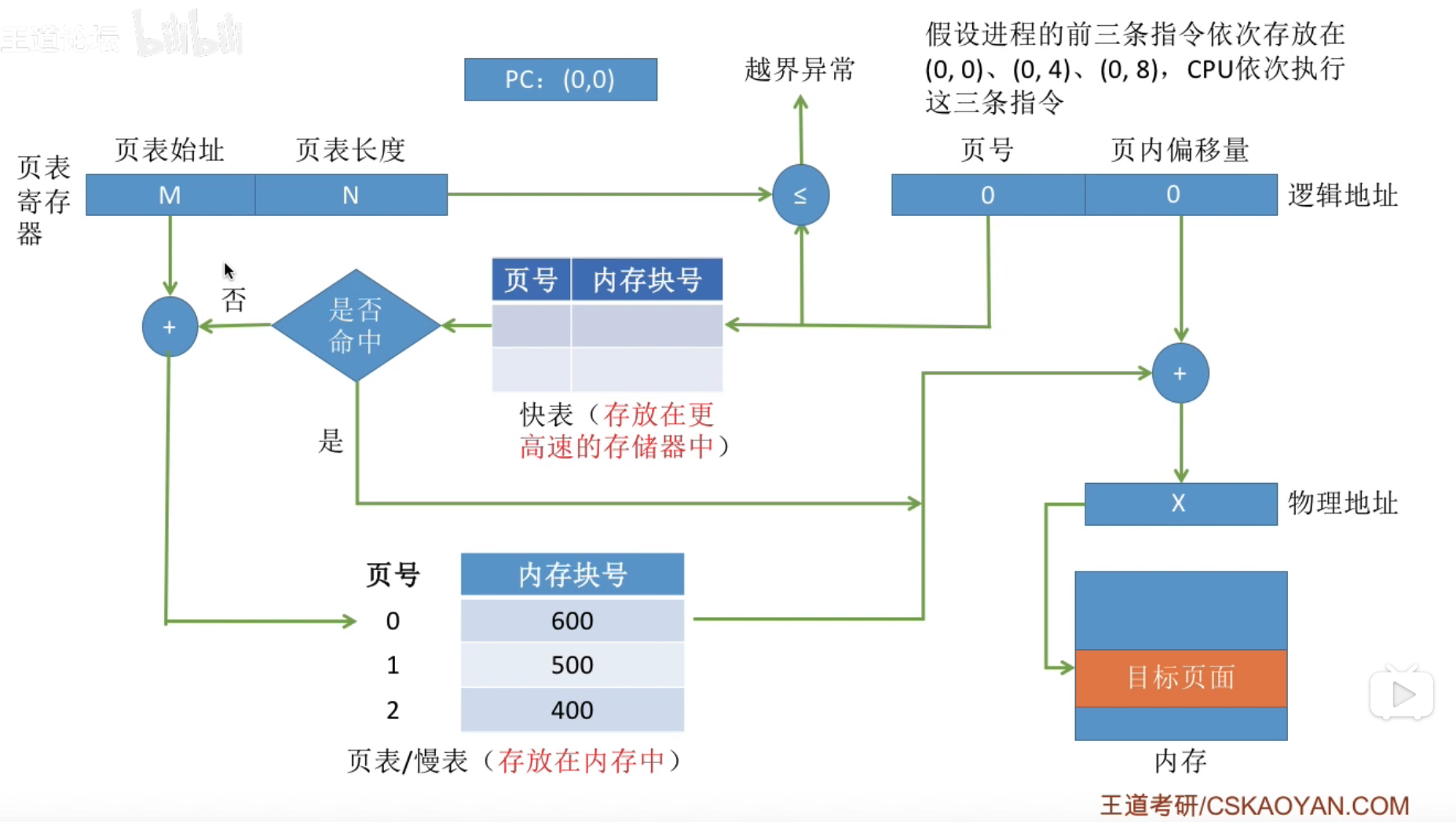
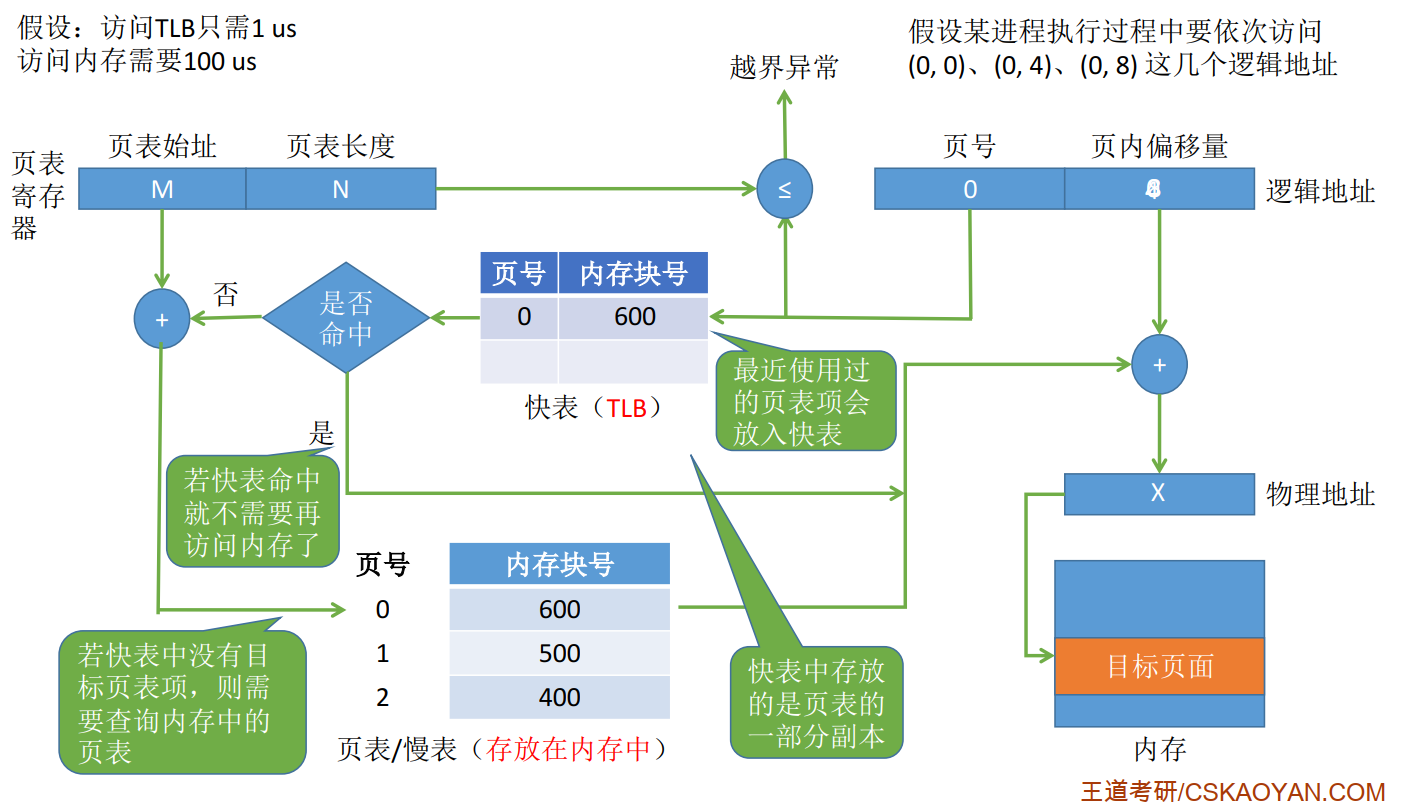
步骤总结 :

快表与基本地址变换机构的比较 :

tips : TLB 和 普通 Cache 的区别——TLB 中只有页表项的副本, 而普通 Cache 中可能会有其他各种数据的副本
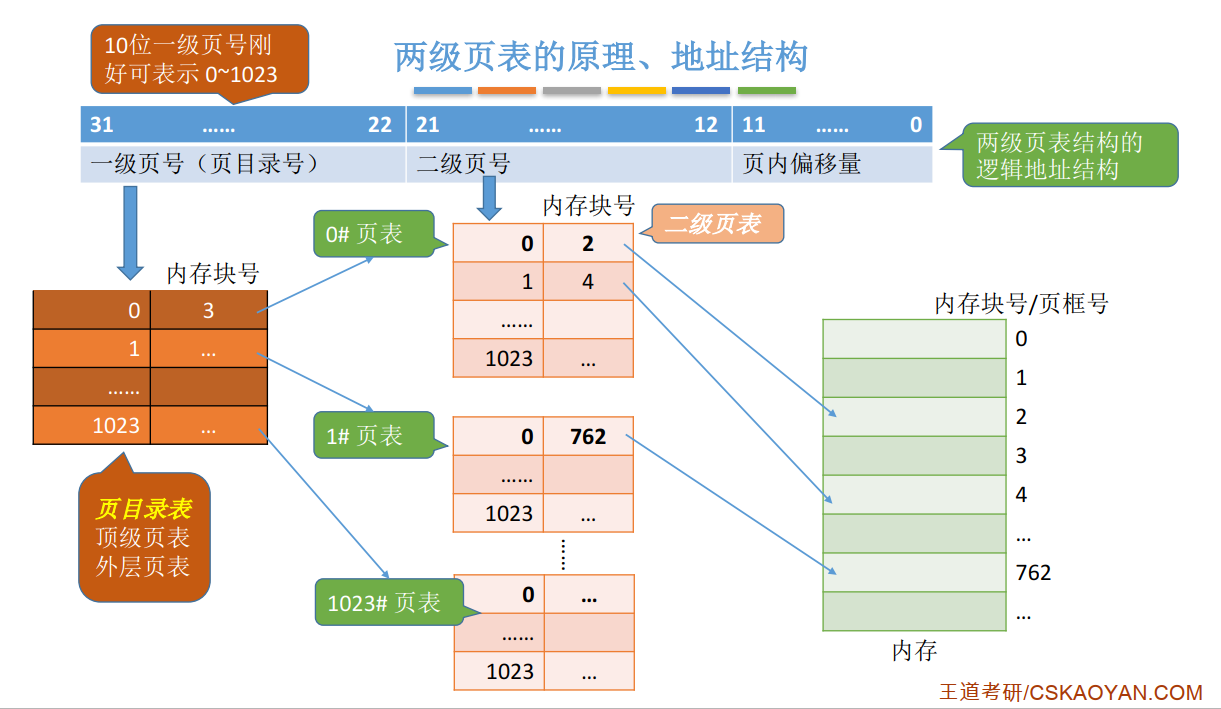
两级页表#
单级页表存在的问题 :
- 由于页号隐式表示, 所以要根据页号查询页表需要 :
K 号页对应的页表项存放位置 = 页表始址 + K * 4
要在所有的页表项都连续存放的基础上才能用这种方法找到页表项
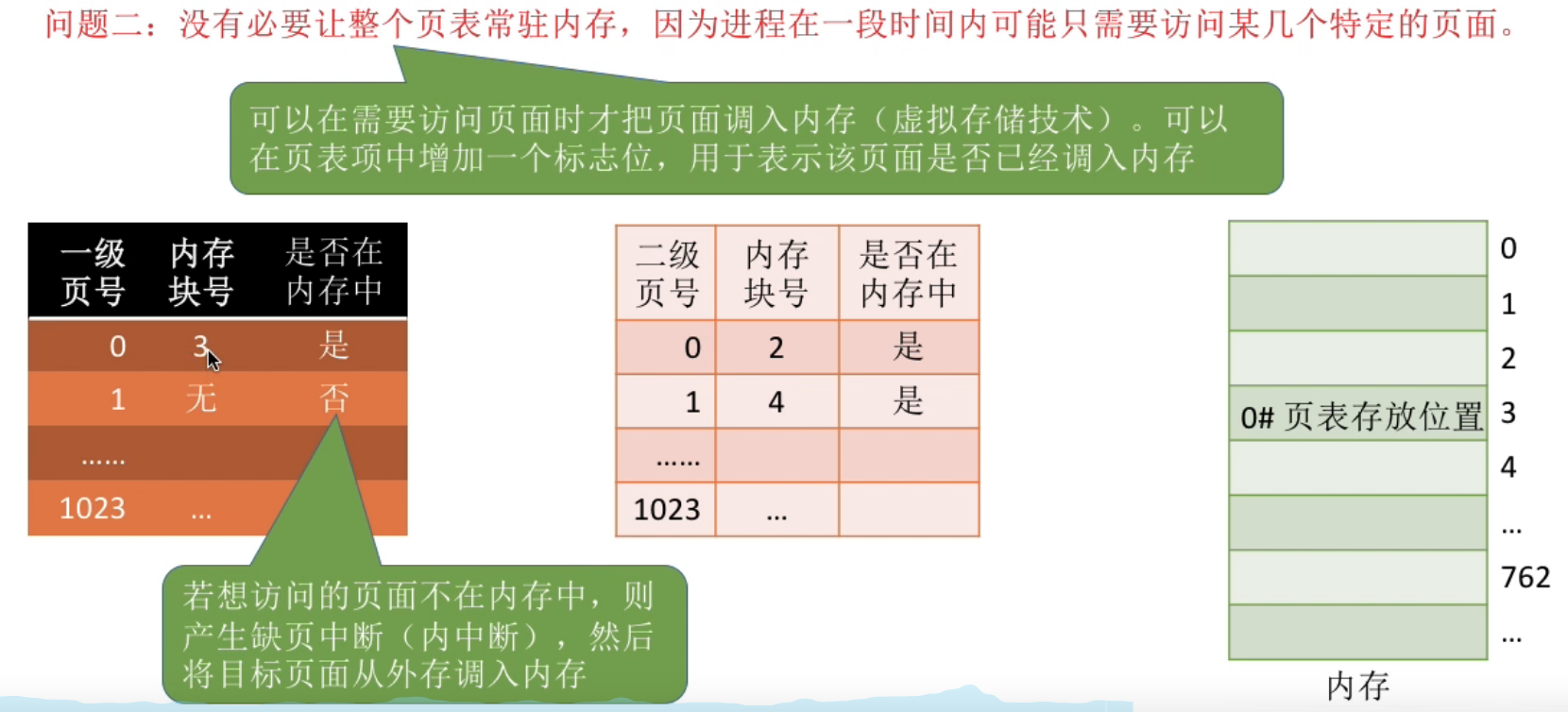
- 同时, 由局部性原理可知, 很多时候, 进程在一段时间内只需要访问某几个页面就可以正常运行了, 因此没有必要让整个页表都常驻内存

解决 : 把页表再分页并离散存储, 然后再建立一张页表记录页表各个部分的存放位置, 称为页目录表, 或称外层页表, 或称顶层页表.
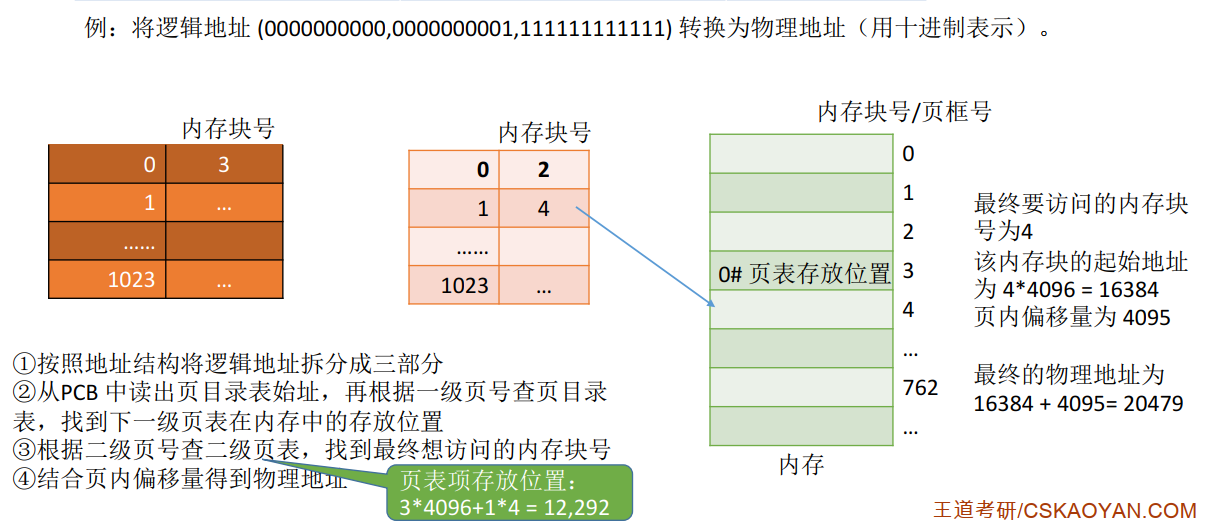
e.g.
关于页表常驻内存的解决 -- ( 虚拟存储技术 ) , 在页表项中增加一个标志位, 用于表示该页面是否已经调入内存
注意:
-
如果采用多级页表机制, 各级页表不能超过一个页面
-
两级页表的访存次数分析 :
n级页表访存次数为n+1次: ( 以2级页表为例 )
- 访问内存中的页目录表 ( 顶级页表 )
- 访问内存中的二级页表
- 访问目标内存单元
ref : https://www.bilibili.com/video/BV1YE411D7nH?p=41
操作系统---内存管理(下) 分段存储 段页式存储 虚拟内存 请求分页管理方式
内存管理学习笔记 :
操作系统---内存管理(上) 概念 覆盖交换技术 连续分配管理方式
操作系统---内存管理(下) 分段存储 段页式存储 虚拟内存 请求分页管理方式
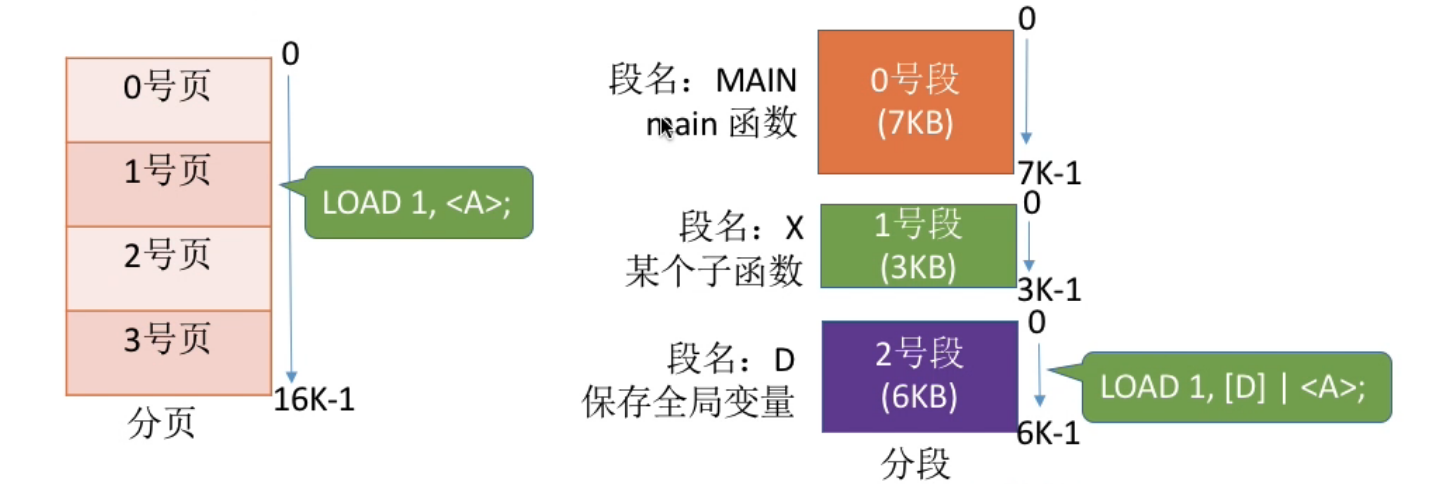
基本分段存储管理方式#
分段 : 进程的地址空间会按照自身的逻辑关系划分为若干个段, 每个段都有一个段名, 每段从0开始编址
内存分配规则 : 以段为单位进行分配, 每个段在内存中占据连续空间, 但各段之间可以不相邻
分段系统的组成:#
- 段号------ 段号的位数决定了每个进程最多可以分为几个段
- 段内地址------段内地址的位数决定了每个段的最大长度是多少

段表#
程序分为多个段, 各个段离散地装入内存, 为了保证程序能正常运行, 就必须能从物理内存中找到各个逻辑段的存放位置. 为此, 需为每个进程建立一张段映射表, 简称 " 段表 " .
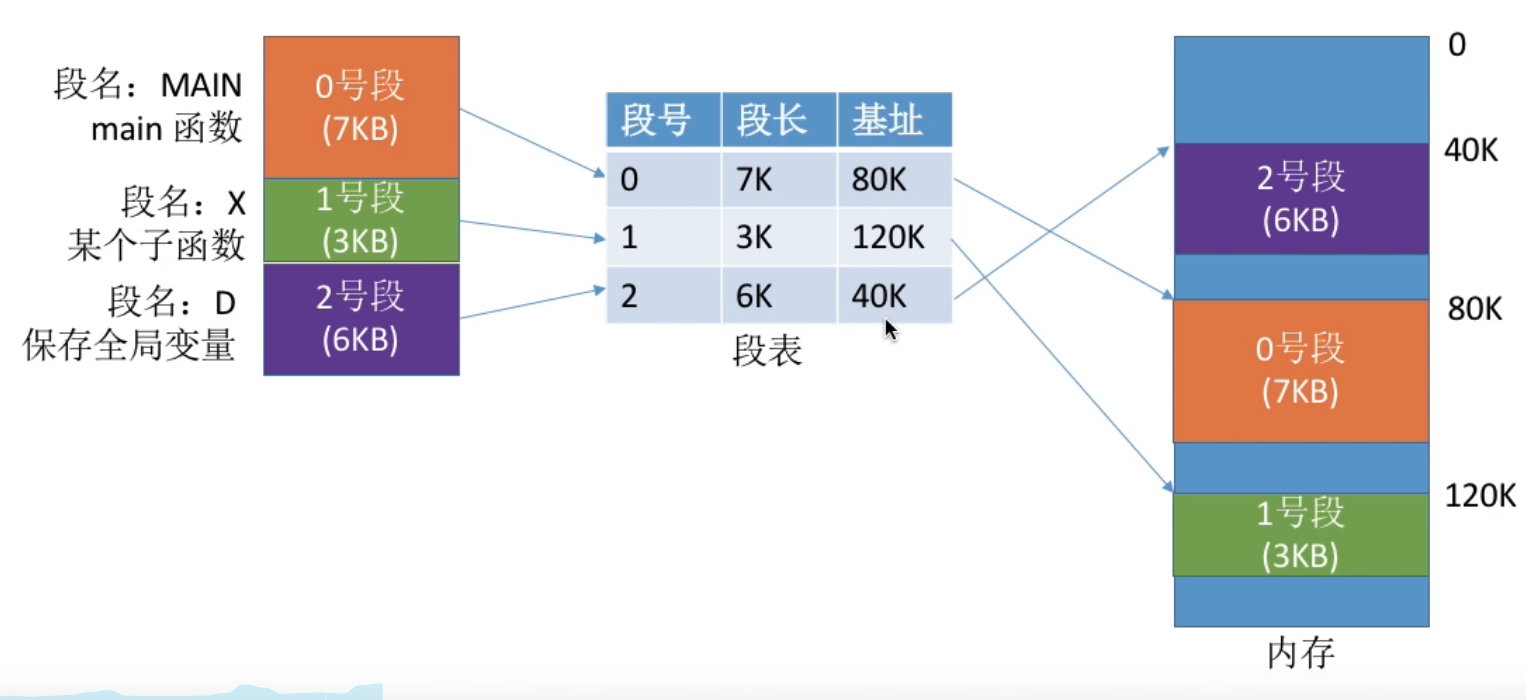
关于段表 :
- 每个段对应一个段表项, 记录着该段在内存中的起始位置 ( 基址 ) 和 段长
- 各个段表项的长度是相同的, 因此和页号一样, 段号是" 隐含 "的, 不占据存储空间
查找过程#
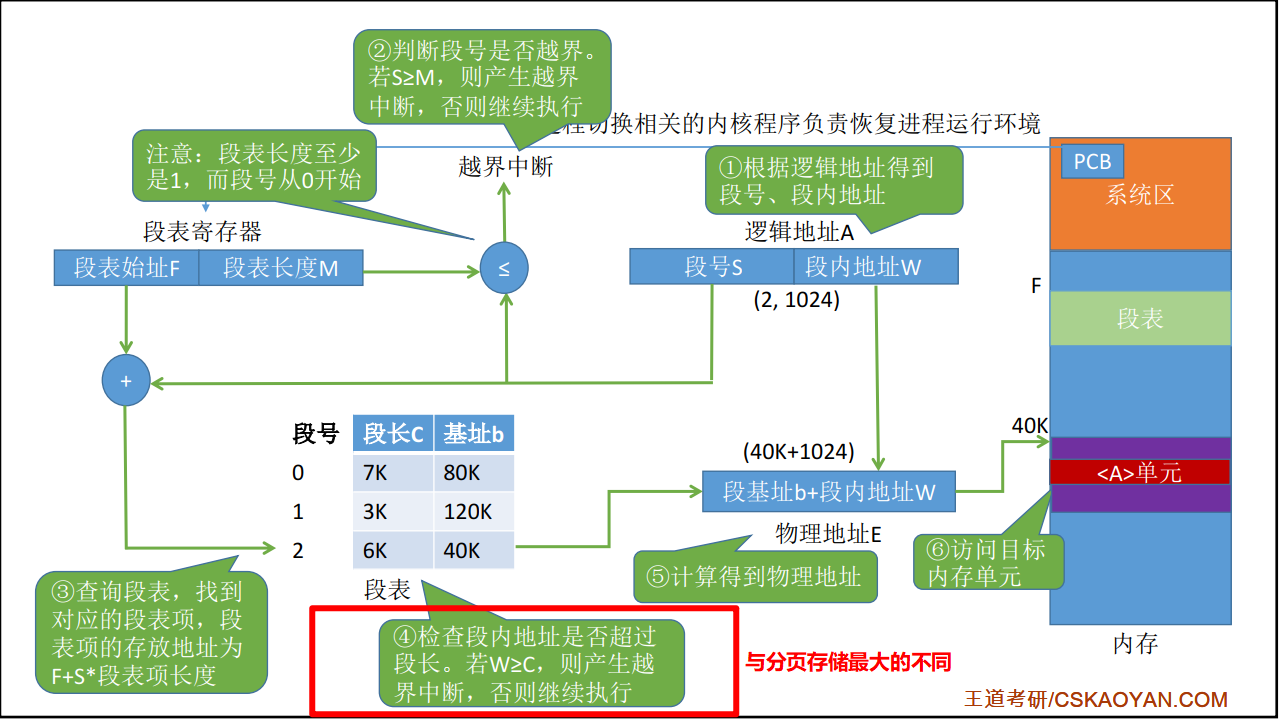
分段和分页的对比#
-
页是信息的物理单位, 分页的主要目的是为了实现离散分配, 提高内存利用率. 分页仅仅是系统管理上的需要, 完全是系统行为, 对用户是不可见的
-
段是信息的逻辑单位, 分段的主要目的是更好地满足用户需求. 一个段通常包含着一组属于一个逻辑模块的信息, 分段对用户是可见的, 用户编程时需要显式地给出段名
-
页的大小是固定且由系统决定, 段的长度却不固定, 决定于用户编写的程序
-
分页的用户进程地址空间是一维的, 分段的用户进程是二维的.
- 分段比分页更容易实现信息的共享和保护
段页式内存管理方式#
分页, 分段管理的优缺点分析#
| 优点 | 缺点 | |
|---|---|---|
| 分页管理 | 内存空间利用率高. 不会产生外部碎片, 只有少量的内部碎片 | 不方便逻辑模块实现信息的共享与保护 |
| 分段管理 | 方便实现逻辑模块信息的共享与保护 | 如果段长过大, 为其分配很大的连续空间会很不方便, 并且段式管理会产生外部碎片 |
段页式管理的结构#
先分段 , 再分页
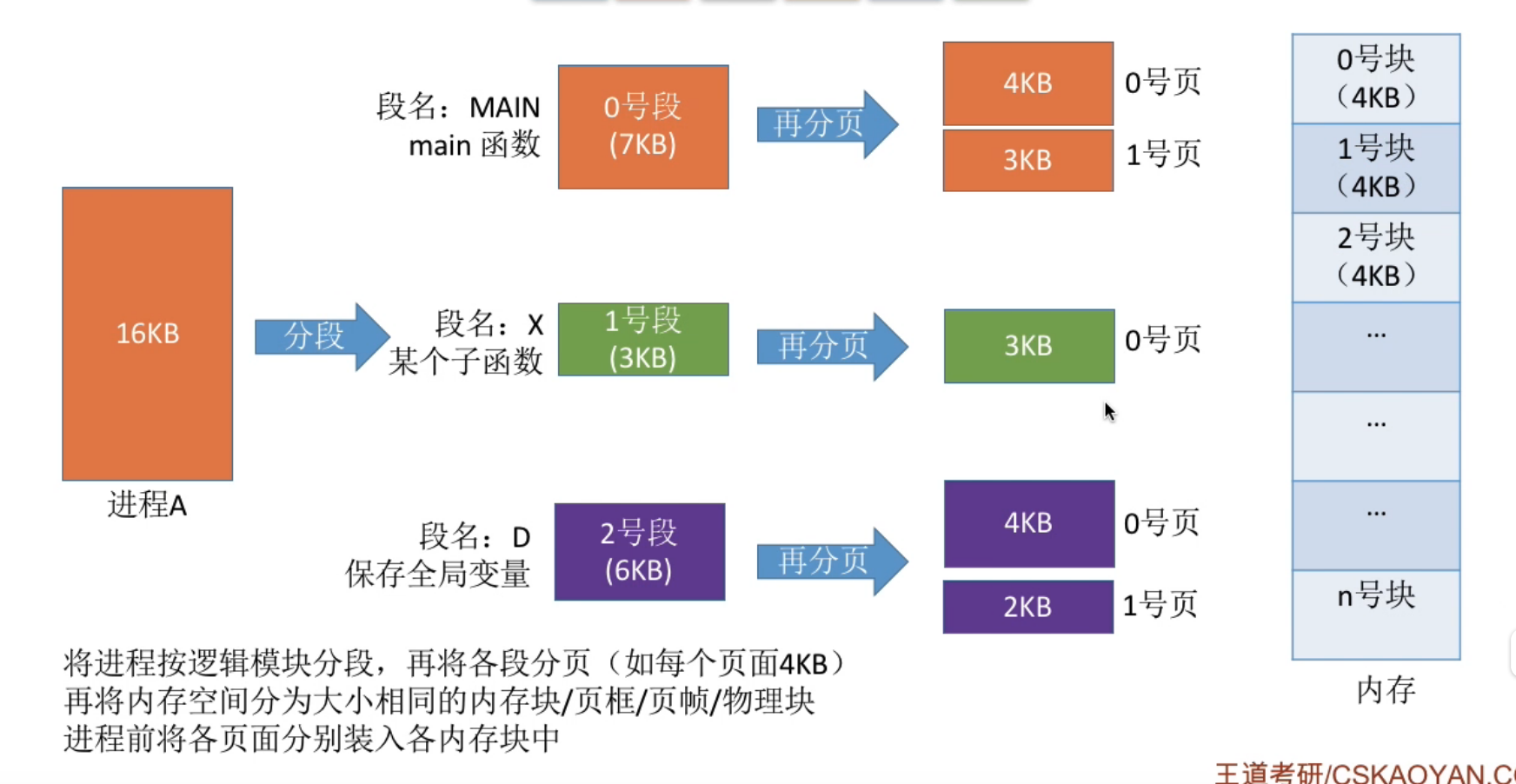
段页式管理的逻辑地址结构 :
由段号, 页号, 页内偏移 组成

- 段号的位数决定了每个进程最多可以分为几个段
- 页号位数决定了每个段最大有多少页
- 页内偏移量决定了页面大小和内存块的大小
注意 :
"分段"对用户是可见的, 而将各段"分页"对用户是不可见的, 系统会根据段内地址自动划分页号和段内偏移量, 因此段页式管理的地址结构是"二维"的.
段表, 页表#
每一个进程对应一个段表, 每一个段又对应一个页表, 因此一个进程可能对应多个页表.
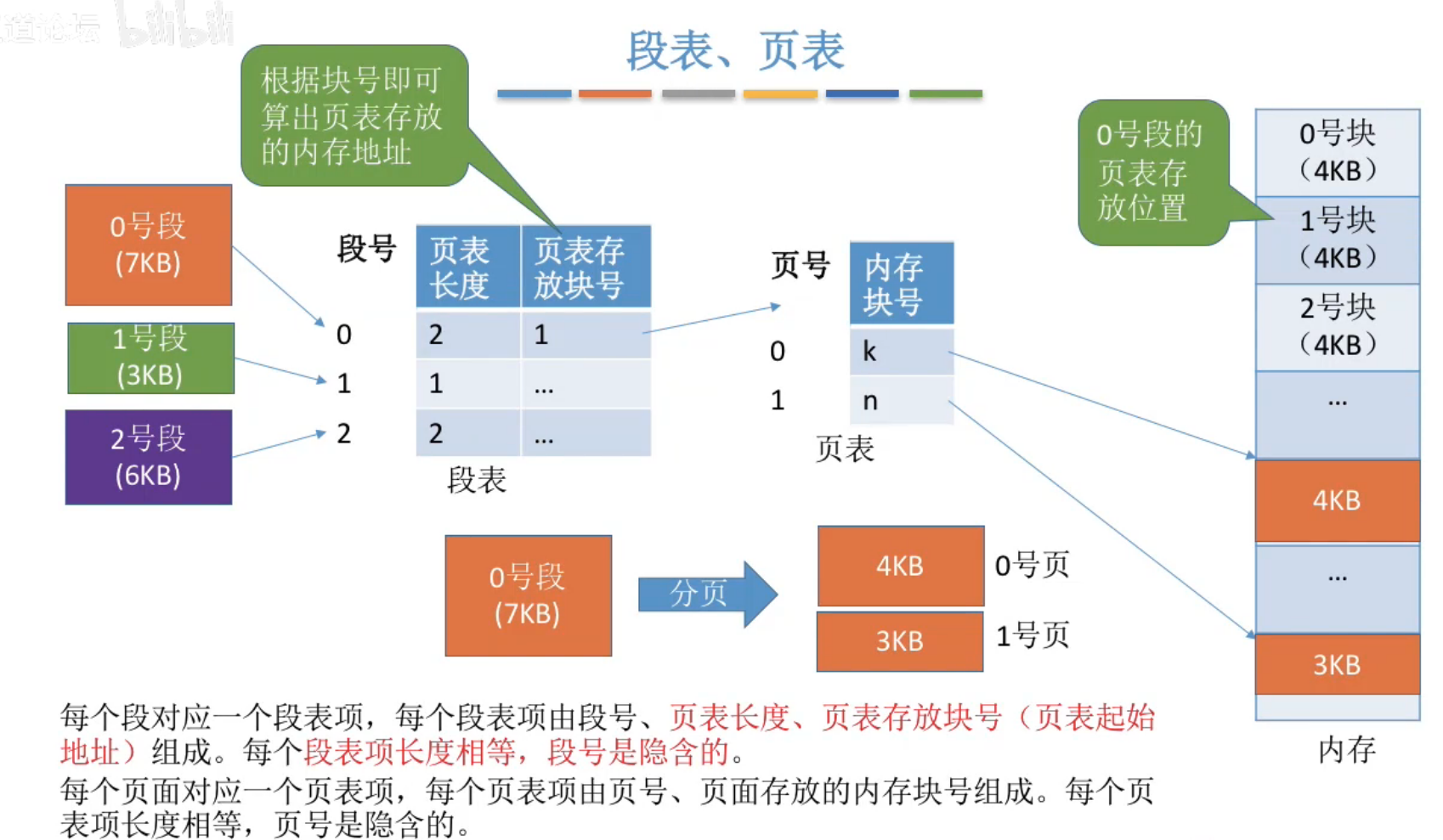
查找过程#

- 由逻辑地址得到段号, 页号, 页内偏移
- 段号与段表寄存器的段长度比较, 检查是否越界
- 由段表始址, 段号找到对应段表项 ---- ( 一次访存)
- 根据段表中记录的页表长度, 检查页号是否越界
- 由段表中的页表地址, 页号得到查询页表, 找到相应页表项 ---- ( 二次访存)
- 由页面存放的内存块号, 页内偏移得到最终的物理地址
- 访问目标单元 ---- ( 三次访存)
虚拟内存#
传统存储管理方式的特征, 缺点#
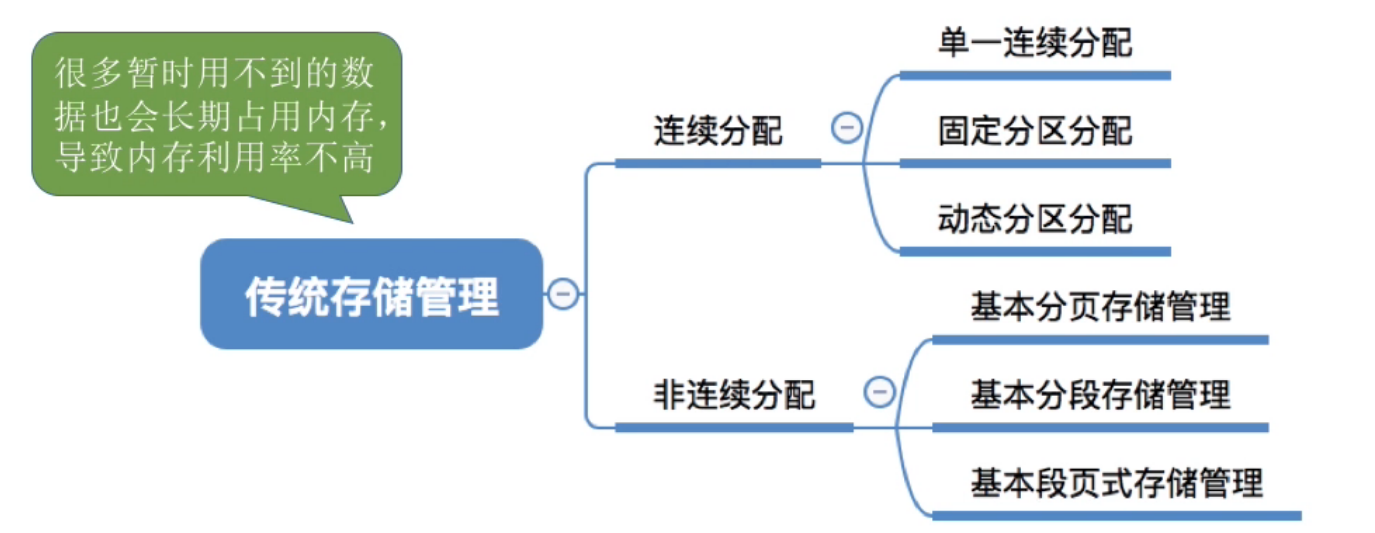
- 一次性 : 作业必须一次性全部装入内存才能开始运行
- 作业很大时, 无法装入导致大作业无法运行
- 大量作业要求运行时内存无法容纳所有作业, 导致多道程序并发度下降
- 驻留性 : 一旦作业被装入内存, 就会一直驻留在内存中, 直到作业运行结束, 这样会导致内存中驻留大量的, 暂时用不到的数据, 浪费内存资源
虚拟内存---基于局部性原理
-
在程序装入时, 将程序中很快会用到的部分装入内存, 暂时用不到的部分留在外存, 就可以让程序开始执行.
-
在程序执行过程中, 当所访问的信息不在内存时, 由操作系统负责将所需信息由外存调入内存, 然后继续执行程序.
-
内存空间不够时, 操作系统负责将内存中暂时用不到的信息换出到外存
-
在用户看来, 就有一个比实际内存大很多的内存, 这就叫虚拟内存
注意 :
虚拟内存的最大容量是由计算机的地址结构 ( CPU的寻址范围 ) 确定的, 虚拟内存的实际容量 = min(内存容量+外存容量,CPU寻址范围)">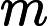
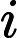
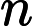
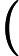 内存容量
内存容量 外存容量
外存容量
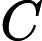
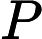
 寻址范围
寻址范围 min(内存容量+外存容量,CPU寻址范围)
min(内存容量+外存容量,CPU寻址范围)

虚拟内存的实现 :
-
请求分页存储管理
-
请求分段存储管理
-
请求段页式存储管理
操作系统需要提供的功能 :
- 请求调页 ( 段 )
- 页面置换 ( 段置换 )
缺页时请求掉页不一定页面置换, 若还有可用的内存块, 就不用进行页面置换
请求分页管理方式#
页表机制#
缺页中断机构#
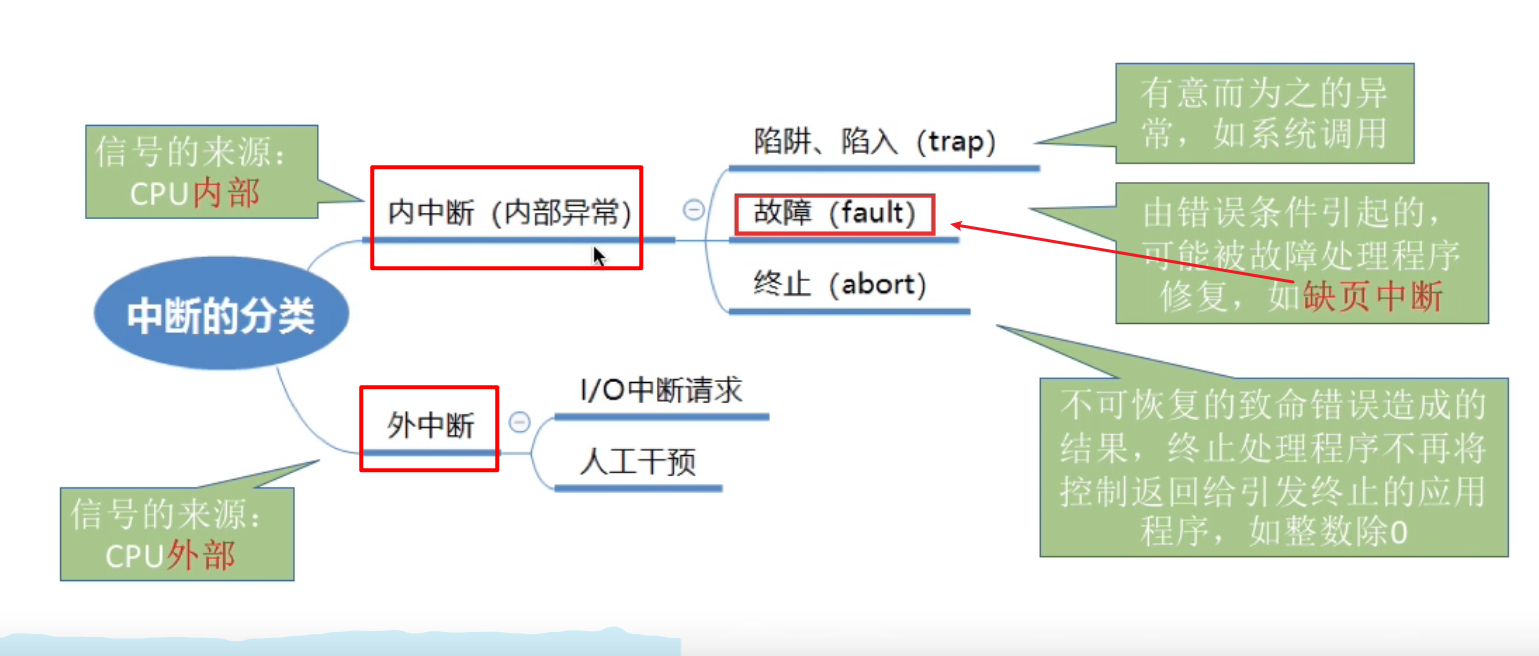
在请求分页操作系统中, 每当要访问的页面不在内存时, 便产生一个缺页中断, 然后由操作系统的缺页中断处理程序处理中断
此时缺页的进程阻塞, 放入阻塞队列, 调页完成后再将其唤醒, 放回就绪队列
-
如果内存中有空闲块, 则为进程分配一个空闲块, 将所缺页面装入该块, 并修改页表中相应的页表项
-
如果内存中没有空闲块, 则由页面置换算法选择一个页面淘汰, 若该页面在内存期间被修改过, 则要将其写回外存, 未修改过的页面不用写回外存
缺页中断是因为当前执行的指令想要访问目标页面未调入内存而产生的, 因此属于内中断 :
页面置换算法#
最佳置换算法OPT#
每次选择淘汰的页面是以后永不使用或者在最长时间内不会使用的页面, 保证最低的缺页率 . 但是操作系统无法预判页面访问序列, 这种算法是无法实现的
先进先出置换算法 FIFO#
每次淘汰的页面是最早进入内存的页面
实现 : 将调入内存的页面根据调入的先后顺序排成一个队列, 需要置换页面的时候选择队首的页面.
实现简单, 算法性能差, 不适应进程实际运行时的规律
最近最久未使用算法 LRU#
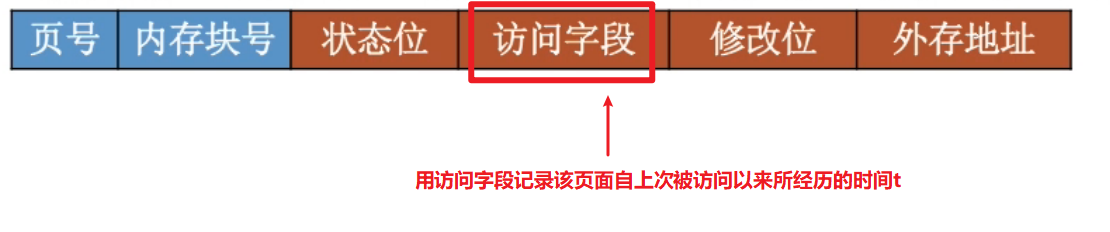
当需要淘汰一个页面的时候, 选择现有页面中t值最大的, 即最近最久未使用的页面.
做题时的方法 : 需要淘汰页面时, 逆向检查此时在内存中的几个页面号, 最后一个出现的页号就是需要被淘汰的
LRU算法的特点 : 性能好, 但实现起来需要专门的硬件支持, 算法开销大
时钟置换算法 ( CLOCK ) / 最近未用算法 ( NRU )#
他们是同一种算法.
简单的CLOCK算法的实现方法 :
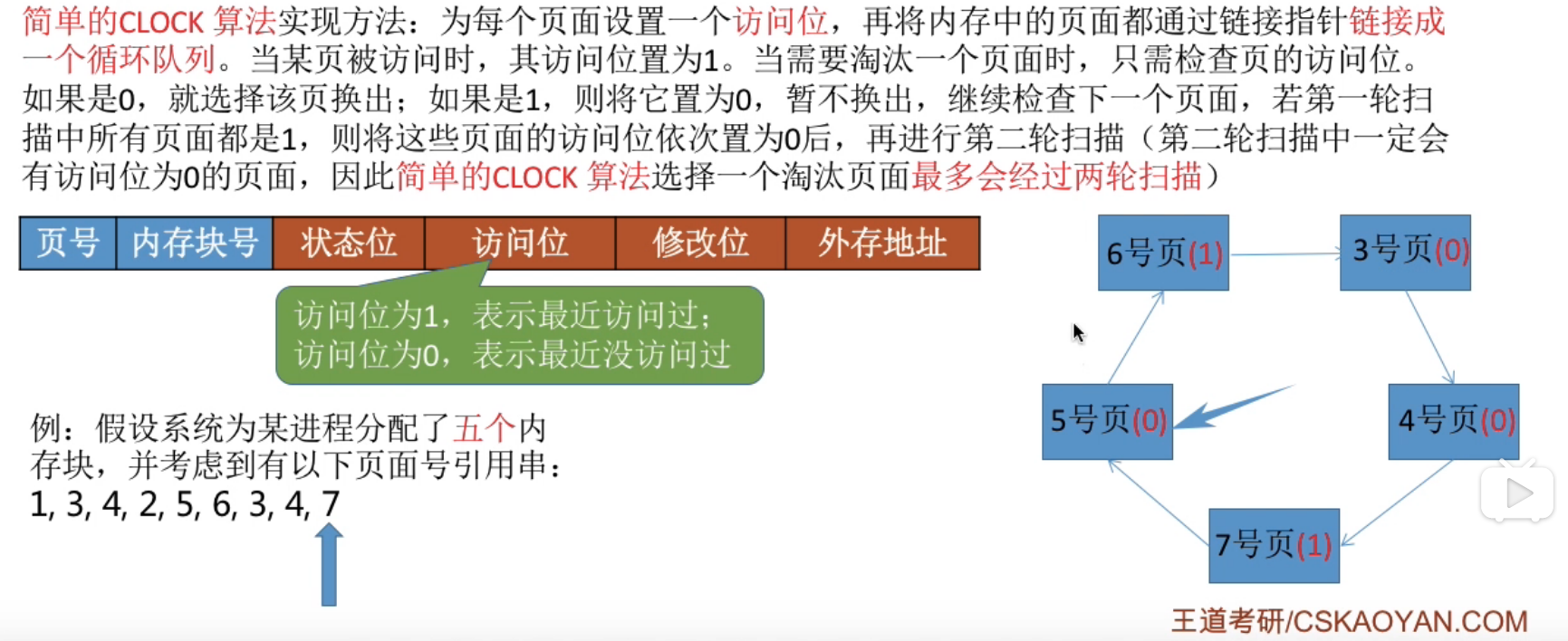
简单的时钟置换算法仅考虑到了一个页面最近是否被访问过, 但是事实上, 如果被淘汰的页面没有被修改过, 就不需要执行I/O操作写回外存. 只有被淘汰的页面被修改过时, 才需要写回外存------因此, 除了考虑一个页面最近有没有被访问过之外, 操作系统还应该考虑页面有没有被修改过. 在其他条件都相同时, 应该优先淘汰没有修改过的页面, 避免I/O操作, 这就是改进型的时钟置换算法的思想.
利用 (访问位, 修改位) 的形式表示各页面状态
| 对应页面 | |
|---|---|
| 第一轮 : 找第一个 (0, 0)的帧用于替换 ( 不修改标志位 ) | 最近没访问且没修改 |
| 第二轮 : 找第一个 (0, 1)的帧用于替换 ( 将所有扫描过的帧访问位设为0) | 最近没访问但修改过 |
| 第三轮 : 找第一个 (0, 0)的帧用于替换 ( 不修改标志位 ) | 最近访问过但没修改 |
| 第四轮 : 找第一个 (0, 1)的帧用于替换 | 最近访问过也修改过 |
特点 : 开销小, 性能也不错
页面分配策略#
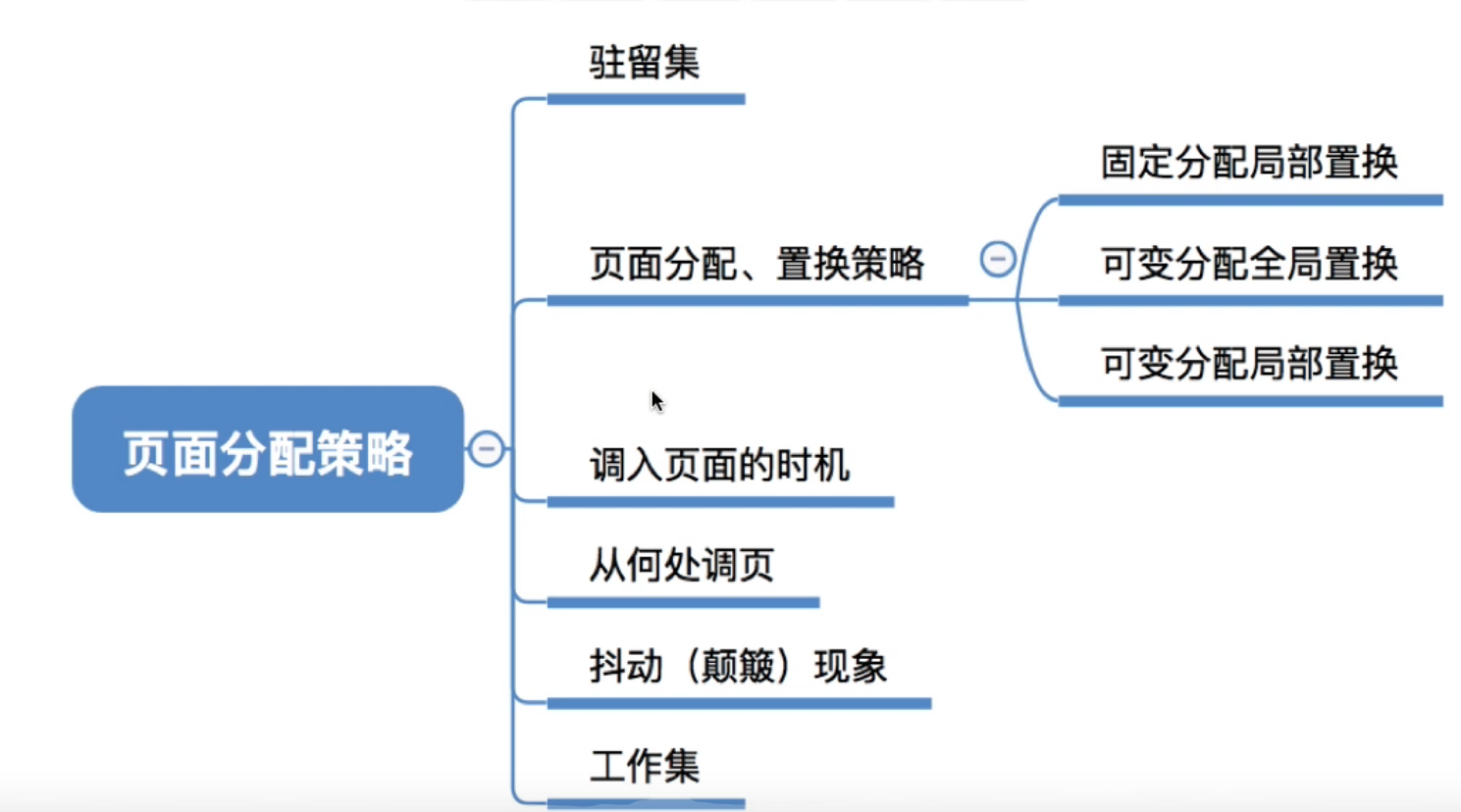
驻留集#
请求分页存储管理器中给进程分配的物理块的集合. ( 系统给进程分配了n各物理块 ----的另一种表述 : 驻留集大小为n)
在采用虚拟存储技术的系统中, 驻留集的大小一般小于进程的总大小
- 如果驻留集太小, 会导致缺页频繁, 系统要花大量的时间来处理缺页, 实际用于进程推进的时间很少
- 如果驻留集太大, 会导致多道程序并发度下降, 资源利用率降低
几种分配策略#
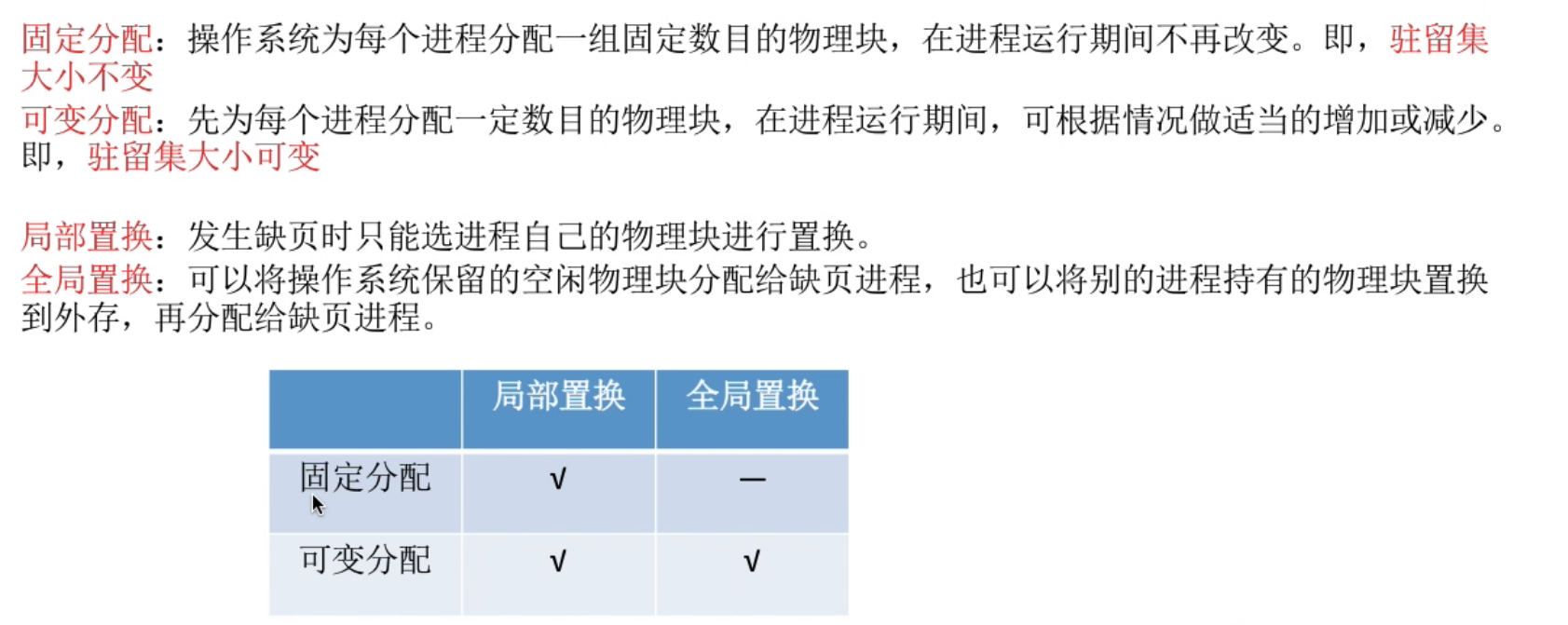
固定分配全局置换不存在, 因为进程物理块固定后不会再分配给别人

- 可变分配全局置换 : 只要缺页就给分配新物理块
- 可变分配局部置换 : 根据发生缺页的频率来动态地增加或减少进程的物理块
何时调入页面#
-
预调页策略

-
请求调页策略

何处调入页面#
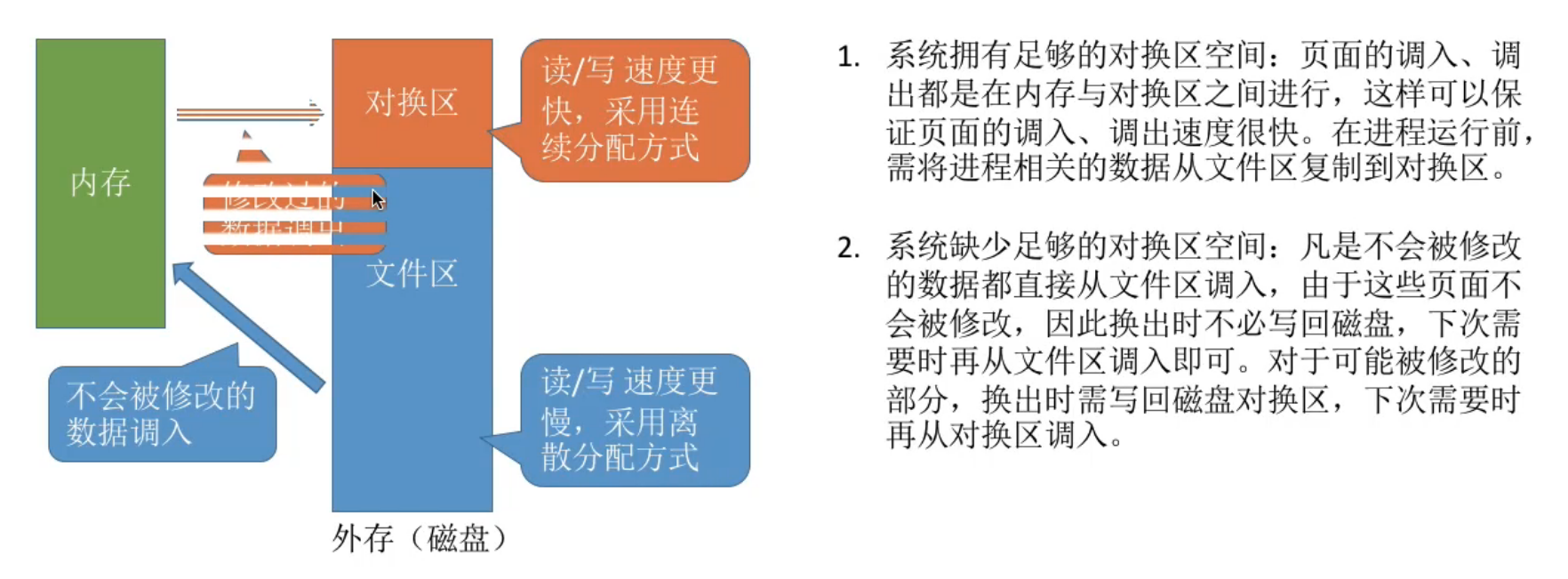
文件区用于调入不会被修改的数据, 对换区用用于调入可能被修改的数据
抖动现象

工作集#

- 一般来说 驻留集的大小不能小于工作集的大小, 否则进程运行过程中将频繁缺页.
ref : https://www.bilibili.com/video/BV1YE411D7nH?p=41
2019-02-03 多进程和多线程的区别【】
在理解进程和线程概念之前首选要对并发有一定的感性认识,如果服务器同一时间内只能服务于一个客户端,其他客户端都再那里傻等的话,可见其性能的低下估计会被客户骂出翔来,因此并发编程应运而生,并发是网络编程中必须考虑的问题。实现并发的方式有多种:比如多进程、多线程、IO多路复用。
多进程
进程是资源(CPU、内存等)分配的基本单位,它是程序执行时的一个实例。程序运行时系统就会创建一个进程,并为它分配资源,然后把该进程放入进程就绪队列,进程调度器选中它的时候就会为它分配CPU时间,程序开始真正运行。
Linux系统函数fork()可以在父进程中创建一个子进程,这样的话,在一个进程接到来自客户端新的请求时就可以复制出一个子进程让其来处理,父进程只需负责监控请求的到来,然后创建子进程让其去处理,这样就能做到并发处理。
-- coding:utf-8 --
import os
print(‘当前进程:%s 启动中 …’ % os.getpid())
pid = os.fork()
if pid == 0:
print(‘子进程:%s,父进程是:%s’ % (os.getpid(), os.getppid()))
else:
print(‘进程:%s 创建了子进程:%s’ % (os.getpid(),pid ))
输出结果:
当前进程:27223 启动中 …
进程:27223 创建了子进程:27224
子进程:27224,父进程是:27223
fork函数会返回两次结果,因为操作系统会把当前进程的数据复制一遍,然后程序就分两个进程继续运行后面的代码,fork分别在父进程和子进程中返回,在子进程返回的值pid永远是0,在父进程返回的是子进程的进程id。
多线程
线程是程序执行时的最小单位,它是进程的一个执行流,是CPU调度和分派的基本单位,一个进程可以由很多个线程组成,线程间共享进程的所有资源,每个线程有自己的堆栈和局部变量。线程由CPU独立调度执行,在多CPU环境下就允许多个线程同时运行。同样多线程也可以实现并发操作,每个请求分配一个线程来处理。
线程和进程各自有什么区别和优劣呢?
进程是资源分配的最小单位,线程是程序执行的最小单位。
进程有自己的独立地址空间,每启动一个进程,系统就会为它分配地址空间,建立数据表来维护代码段、堆栈段和数据段,这种操作非常昂贵。而线程是共享进程中的数据的,使用相同的地址空间,因此CPU切换一个线程的花费远比进程要小很多,同时创建一个线程的开销也比进程要小很多。
线程之间的通信更方便,同一进程下的线程共享全局变量、静态变量等数据,而进程之间的通信需要以通信的方式(IPC)进行。不过如何处理好同步与互斥是编写多线程程序的难点。
但是多进程程序更健壮,多线程程序只要有一个线程死掉,整个进程也死掉了,而一个进程死掉并不会对另外一个进程造成影响,因为进程有自己独立的地址空间。
老外的原话是这么说的 —-《Unix网络编程》:
fork is expensive. Memory is copied from the parent to the child, all descriptors are duplicated in the child, and so on. Current implementations use a technique called copy-on-write, which avoids a copy of the parent’s data space to the child until the child needs its own copy. But, regardless of this optimization, fork is expensive.
IPC is required to pass information between the parent and child after the fork. Passing information from the parent to the child before the fork is easy, since the child starts with a copy of the parent’s data space and with a copy of all the parent’s descriptors. But, returning information from the child to the parent takes more work.
Threads help with both problems. Threads are sometimes called lightweight processes since a thread is “lighter weight” than a process. That is, thread creation can be 10–100 times faster than process creation.
All threads within a process share the same global memory. This makes the sharing of information easy between the threads, but along with this simplicity comes the problem
转 https://www.cnblogs.com/zhehan54/p/6130030.html
一道面试题:说说进程和线程的区别
在理解进程和线程概念之前首选要对并发有一定的感性认识,如果服务器同一时间内只能服务于一个客户端,其他客户端都再那里傻等的话,可见其性能的低下估计会被客户骂出翔来,因此并发编程应运而生,并发是网络编程中必须考虑的问题。实现并发的方式有多种:比如多进程、多线程、IO多路复用。
多进程
进程是资源(CPU、内存等)分配的基本单位,它是程序执行时的一个实例。程序运行时系统就会创建一个进程,并为它分配资源,然后把该进程放入进程就绪队列,进程调度器选中它的时候就会为它分配CPU时间,程序开始真正运行。
Linux系统函数fork()可以在父进程中创建一个子进程,这样的话,在一个进程接到来自客户端新的请求时就可以复制出一个子进程让其来处理,父进程只需负责监控请求的到来,然后创建子进程让其去处理,这样就能做到并发处理。
# -*- coding:utf-8 -*-
import os
print('当前进程:%s 启动中 ....' % os.getpid())
pid = os.fork()
if pid == 0:
print('子进程:%s,父进程是:%s' % (os.getpid(), os.getppid()))
else:
print('进程:%s 创建了子进程:%s' % (os.getpid(),pid ))输出结果:
当前进程:27223 启动中 ....
进程:27223 创建了子进程:27224
子进程:27224,父进程是:27223fork函数会返回两次结果,因为操作系统会把当前进程的数据复制一遍,然后程序就分两个进程继续运行后面的代码,fork分别在父进程和子进程中返回,在子进程返回的值pid永远是0,在父进程返回的是子进程的进程id。
多线程
线程是程序执行时的最小单位,它是进程的一个执行流,是CPU调度和分派的基本单位,一个进程可以由很多个线程组成,线程间共享进程的所有资源,每个线程有自己的堆栈和局部变量。线程由CPU独立调度执行,在多CPU环境下就允许多个线程同时运行。同样多线程也可以实现并发操作,每个请求分配一个线程来处理。
线程和进程各自有什么区别和优劣呢?
-
进程是资源分配的最小单位,线程是程序执行的最小单位。
-
进程有自己的独立地址空间,每启动一个进程,系统就会为它分配地址空间,建立数据表来维护代码段、堆栈段和数据段,这种操作非常昂贵。而线程是共享进程中的数据的,使用相同的地址空间,因此CPU切换一个线程的花费远比进程要小很多,同时创建一个线程的开销也比进程要小很多。
-
线程之间的通信更方便,同一进程下的线程共享全局变量、静态变量等数据,而进程之间的通信需要以通信的方式(IPC)进行。不过如何处理好同步与互斥是编写多线程程序的难点。
-
但是多进程程序更健壮,多线程程序只要有一个线程死掉,整个进程也死掉了,而一个进程死掉并不会对另外一个进程造成影响,因为进程有自己独立的地址空间。
老外的原话是这么说的 —-《Unix网络编程》:
fork is expensive. Memory is copied from the parent to the child, all descriptors are duplicated in the child, and so on. Current implementations use a technique called copy-on-write, which avoids a copy of the parent’s data space to the child until the child needs its own copy. But, regardless of this optimization, fork is expensive.
IPC is required to pass information between the parent and child after the fork. Passing information from the parent to the child before the fork is easy, since the child starts with a copy of the parent’s data space and with a copy of all the parent’s descriptors. But, returning information from the child to the parent takes more work.
Threads help with both problems. Threads are sometimes called lightweight processes since a thread is “lighter weight” than a process. That is, thread creation can be 10–100 times faster than process creation.
All threads within a process share the same global memory. This makes the sharing of information easy between the threads, but along with this simplicity comes the problem
深入剖析Linux IO原理和几种零拷贝机制的实现
前言
零拷贝(Zero-copy)技术指在计算机执行操作时,CPU 不需要先将数据从一个内存区域复制到另一个内存区域,从而可以减少上下文切换以及 CPU 的拷贝时间。它的作用是在数据报从网络设备到用户程序空间传递的过程中,减少数据拷贝次数,减少系统调用,实现 CPU 的零参与,彻底消除 CPU 在这方面的负载。实现零拷贝用到的最主要技术是 DMA 数据传输技术和内存区域映射技术。
- 零拷贝机制可以减少数据在内核缓冲区和用户进程缓冲区之间反复的 I/O 拷贝操作。
- 零拷贝机制可以减少用户进程地址空间和内核地址空间之间因为上下文切换而带来的 CPU 开销。
正文
1. 物理内存和虚拟内存
由于操作系统的进程与进程之间是共享 CPU 和内存资源的,因此需要一套完善的内存管理机制防止进程之间内存泄漏的问题。为了更加有效地管理内存并减少出错,现代操作系统提供了一种对主存的抽象概念,即是虚拟内存(Virtual Memory)。虚拟内存为每个进程提供了一个一致的、私有的地址空间,它让每个进程产生了一种自己在独享主存的错觉(每个进程拥有一片连续完整的内存空间)。
1.1. 物理内存
物理内存(Physical memory)是相对于虚拟内存(Virtual Memory)而言的。物理内存指通过物理内存条而获得的内存空间,而虚拟内存则是指将硬盘的一块区域划分来作为内存。内存主要作用是在计算机运行时为操作系统和各种程序提供临时储存。在应用中,自然是顾名思义,物理上,真实存在的插在主板内存槽上的内存条的容量的大小。
1.2. 虚拟内存
虚拟内存是计算机系统内存管理的一种技术。 它使得应用程序认为它拥有连续的可用的内存(一个连续完整的地址空间)。而实际上,虚拟内存通常是被分隔成多个物理内存碎片,还有部分暂时存储在外部磁盘存储器上,在需要时进行数据交换,加载到物理内存中来。 目前,大多数操作系统都使用了虚拟内存,如 Windows 系统的虚拟内存、Linux 系统的交换空间等等。
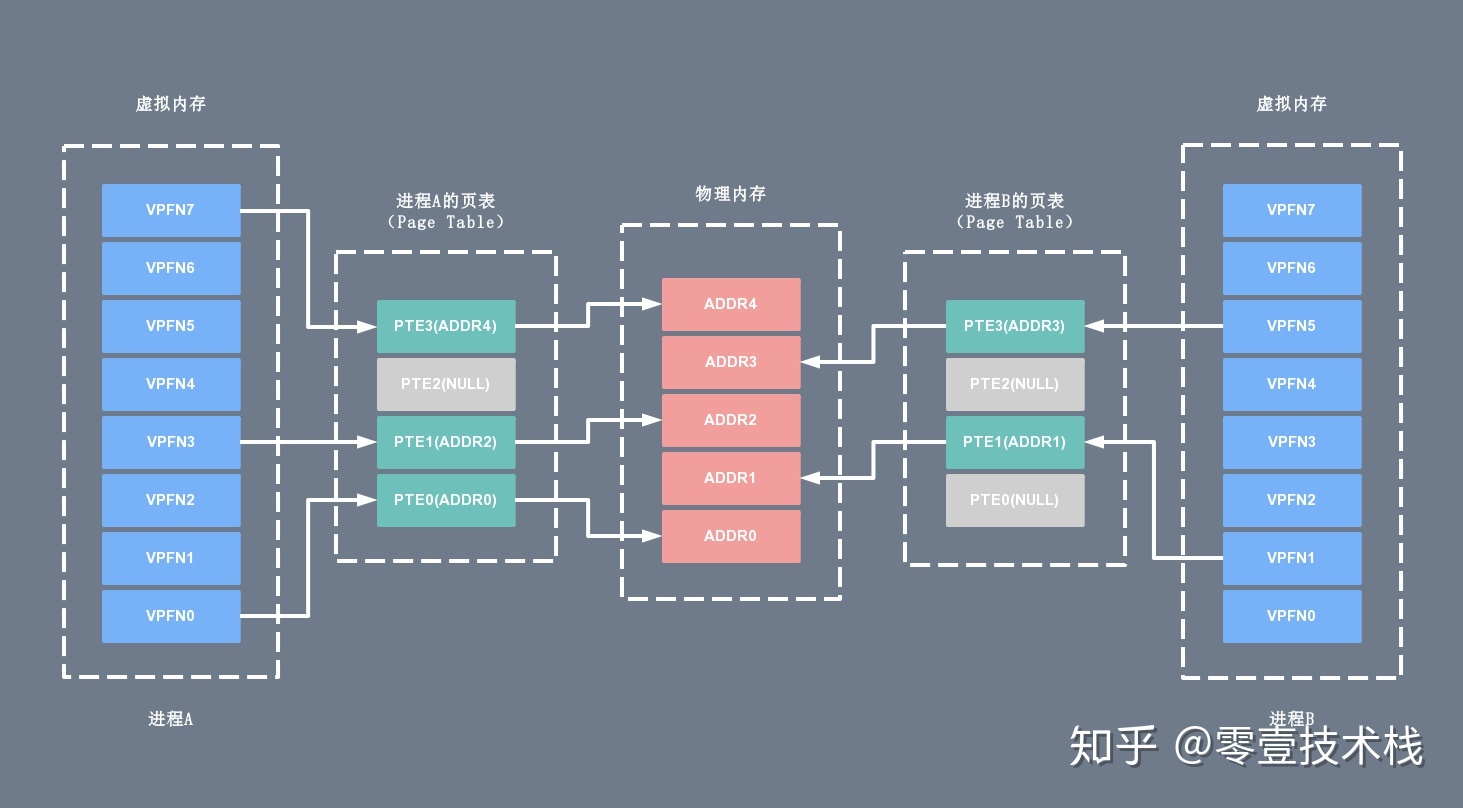
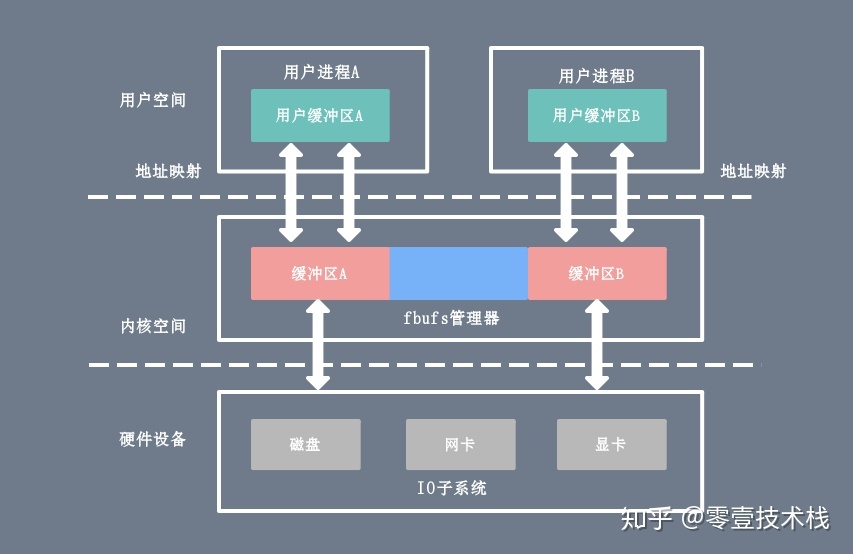
虚拟内存地址和用户进程紧密相关,一般来说不同进程里的同一个虚拟地址指向的物理地址是不一样的,所以离开进程谈虚拟内存没有任何意义。每个进程所能使用的虚拟地址大小和 CPU 位数有关。在 32 位的系统上,虚拟地址空间大小是 2 ^ 32 = 4G,在 64位系统上,虚拟地址空间大小是 2 ^ 64= 2 ^ 34G,而实际的物理内存可能远远小于虚拟内存的大小。每个用户进程维护了一个单独的页表(Page Table),虚拟内存和物理内存就是通过这个页表实现地址空间的映射的。下面给出两个进程 A、B 各自的虚拟内存空间以及对应的物理内存之间的地址映射示意图:
当进程执行一个程序时,需要先从先内存中读取该进程的指令,然后执行,获取指令时用到的就是虚拟地址。这个虚拟地址是程序链接时确定的(内核加载并初始化进程时会调整动态库的地址范围)。为了获取到实际的数据,CPU 需要将虚拟地址转换成物理地址,CPU 转换地址时需要用到进程的页表(Page Table),而页表(Page Table)里面的数据由操作系统维护。
其中页表(Page Table)可以简单的理解为单个内存映射(Memory Mapping)的链表(当然实际结构很复杂),里面的每个内存映射(Memory Mapping)都将一块虚拟地址映射到一个特定的地址空间(物理内存或者磁盘存储空间)。每个进程拥有自己的页表(Page Table),和其它进程的页表(Page Table)没有关系。
通过上面的介绍,我们可以简单的将用户进程申请并访问物理内存(或磁盘存储空间)的过程总结如下:
- 用户进程向操作系统发出内存申请请求
- 系统会检查进程的虚拟地址空间是否被用完,如果有剩余,给进程分配虚拟地址
- 系统为这块虚拟地址创建的内存映射(Memory Mapping),并将它放进该进程的页表(Page Table)
- 系统返回虚拟地址给用户进程,用户进程开始访问该虚拟地址
- CPU 根据虚拟地址在此进程的页表(Page Table)中找到了相应的内存映射(Memory Mapping),但是这个内存映射(Memory Mapping)没有和物理内存关联,于是产生缺页中断
- 操作系统收到缺页中断后,分配真正的物理内存并将它关联到页表相应的内存映射(Memory Mapping)。中断处理完成后 CPU 就可以访问内存了
- 当然缺页中断不是每次都会发生,只有系统觉得有必要延迟分配内存的时候才用的着,也即很多时候在上面的第 3 步系统会分配真正的物理内存并和内存映射(Memory Mapping)进行关联。
在用户进程和物理内存(磁盘存储器)之间引入虚拟内存主要有以下的优点:
- 地址空间:提供更大的地址空间,并且地址空间是连续的,使得程序编写、链接更加简单
- 进程隔离:不同进程的虚拟地址之间没有关系,所以一个进程的操作不会对其它进程造成影响
- 数据保护:每块虚拟内存都有相应的读写属性,这样就能保护程序的代码段不被修改,数据块不能被执行等,增加了系统的安全性
- 内存映射:有了虚拟内存之后,可以直接映射磁盘上的文件(可执行文件或动态库)到虚拟地址空间。这样可以做到物理内存延时分配,只有在需要读相应的文件的时候,才将它真正的从磁盘上加载到内存中来,而在内存吃紧的时候又可以将这部分内存清空掉,提高物理内存利用效率,并且所有这些对应用程序是都透明的
- 共享内存:比如动态库只需要在内存中存储一份,然后将它映射到不同进程的虚拟地址空间中,让进程觉得自己独占了这个文件。进程间的内存共享也可以通过映射同一块物理内存到进程的不同虚拟地址空间来实现共享
- 物理内存管理:物理地址空间全部由操作系统管理,进程无法直接分配和回收,从而系统可以更好的利用内存,平衡进程间对内存的需求
2. 内核空间和用户空间
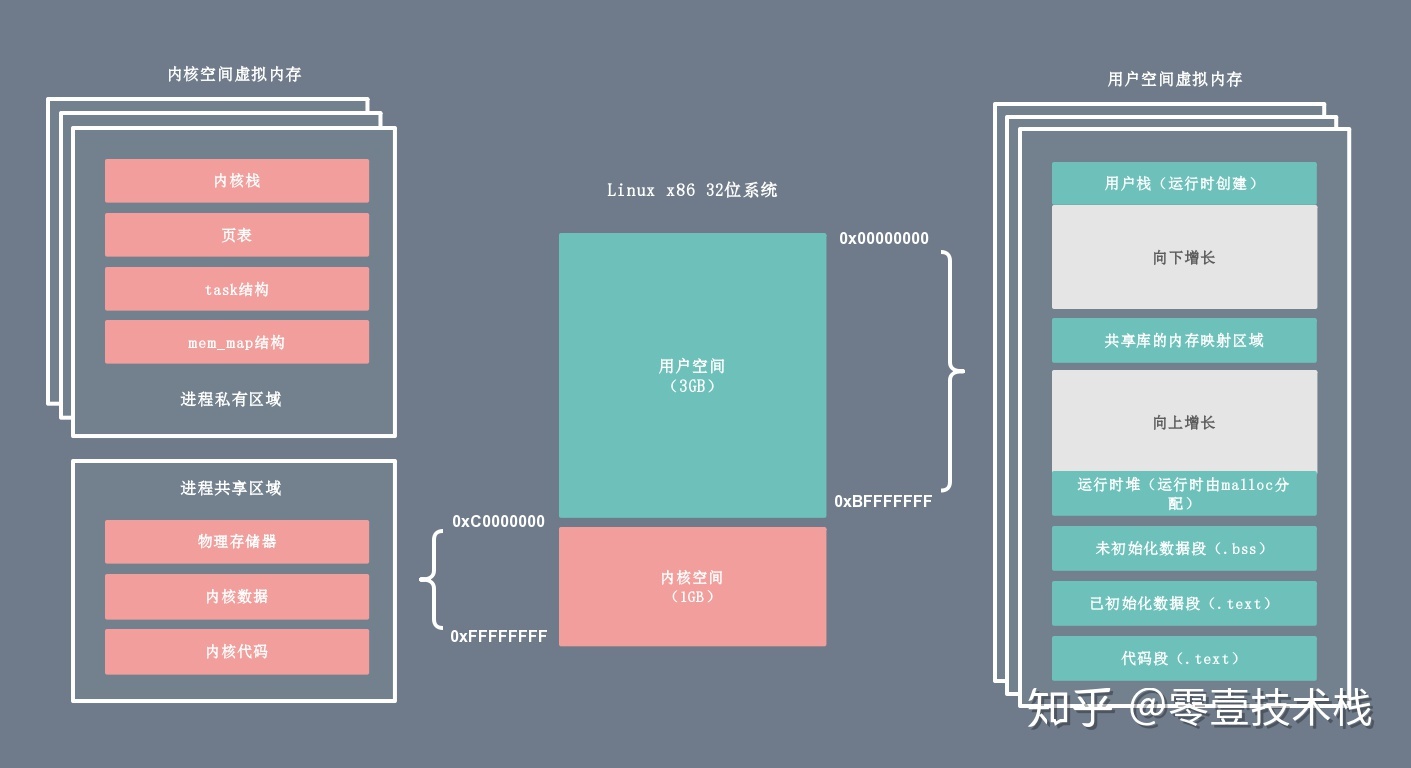
操作系统的核心是内核,独立于普通的应用程序,可以访问受保护的内存空间,也有访问底层硬件设备的权限。为了避免用户进程直接操作内核,保证内核安全,操作系统将虚拟内存划分为两部分,一部分是内核空间(Kernel-space),一部分是用户空间(User-space)。 在 Linux 系统中,内核模块运行在内核空间,对应的进程处于内核态;而用户程序运行在用户空间,对应的进程处于用户态。
内核进程和用户进程所占的虚拟内存比例是 1:3,而 Linux x86_32 系统的寻址空间(虚拟存储空间)为 4G(2的32次方),将最高的 1G 的字节(从虚拟地址 0xC0000000 到 0xFFFFFFFF)供内核进程使用,称为内核空间;而较低的 3G 的字节(从虚拟地址 0x00000000 到 0xBFFFFFFF),供各个用户进程使用,称为用户空间。下图是一个进程的用户空间和内核空间的内存布局:
2.1. 内核空间
内核空间总是驻留在内存中,它是为操作系统的内核保留的。应用程序是不允许直接在该区域进行读写或直接调用内核代码定义的函数的。上图左侧区域为内核进程对应的虚拟内存,按访问权限可以分为进程私有和进程共享两块区域。
- 进程私有的虚拟内存:每个进程都有单独的内核栈、页表、task 结构以及 mem_map 结构等。
- 进程共享的虚拟内存:属于所有进程共享的内存区域,包括物理存储器、内核数据和内核代码区域。
2.2. 用户空间
每个普通的用户进程都有一个单独的用户空间,处于用户态的进程不能访问内核空间中的数据,也不能直接调用内核函数的 ,因此要进行系统调用的时候,就要将进程切换到内核态才行。用户空间包括以下几个内存区域:
- 运行时栈:由编译器自动释放,存放函数的参数值,局部变量和方法返回值等。每当一个函数被调用时,该函数的返回类型和一些调用的信息被存储到栈顶,调用结束后调用信息会被弹出弹出并释放掉内存。栈区是从高地址位向低地址位增长的,是一块连续的内在区域,最大容量是由系统预先定义好的,申请的栈空间超过这个界限时会提示溢出,用户能从栈中获取的空间较小。
- 运行时堆:用于存放进程运行中被动态分配的内存段,位于 BSS 和栈中间的地址位。由卡发人员申请分配(malloc)和释放(free)。堆是从低地址位向高地址位增长,采用链式存储结构。频繁地 malloc/free 造成内存空间的不连续,产生大量碎片。当申请堆空间时,库函数按照一定的算法搜索可用的足够大的空间。因此堆的效率比栈要低的多。
- 代码段:存放 CPU 可以执行的机器指令,该部分内存只能读不能写。通常代码区是共享的,即其它执行程序可调用它。假如机器中有数个进程运行相同的一个程序,那么它们就可以使用同一个代码段。
- 未初始化的数据段:存放未初始化的全局变量,BSS 的数据在程序开始执行之前被初始化为 0 或 NULL。
- 已初始化的数据段:存放已初始化的全局变量,包括静态全局变量、静态局部变量以及常量。
- 内存映射区域:例如将动态库,共享内存等虚拟空间的内存映射到物理空间的内存,一般是 mmap 函数所分配的虚拟内存空间。
3. Linux的内部层级结构
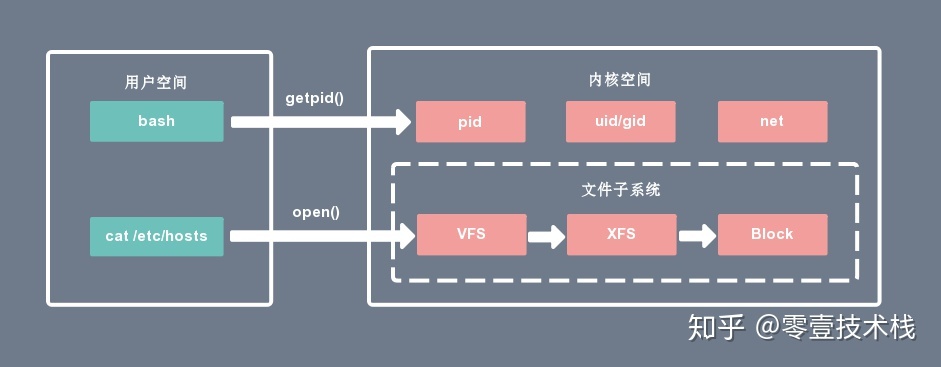
内核态可以执行任意命令,调用系统的一切资源,而用户态只能执行简单的运算,不能直接调用系统资源。用户态必须通过系统接口(System Call),才能向内核发出指令。比如,当用户进程启动一个 bash 时,它会通过 getpid() 对内核的 pid 服务发起系统调用,获取当前用户进程的 ID;当用户进程通过 cat 命令查看主机配置时,它会对内核的文件子系统发起系统调用。
- 内核空间可以访问所有的 CPU 指令和所有的内存空间、I/O 空间和硬件设备。
- 用户空间只能访问受限的资源,如果需要特殊权限,可以通过系统调用获取相应的资源。
- 用户空间允许页面中断,而内核空间则不允许。
- 内核空间和用户空间是针对线性地址空间的。
- x86 CPU中用户空间是 0 – 3G 的地址范围,内核空间是 3G – 4G 的地址范围。x86_64 CPU 用户空间地址范围为0x0000000000000000 – 0x00007fffffffffff,内核地址空间为 0xffff880000000000 – 最大地址。
- 所有内核进程(线程)共用一个地址空间,而用户进程都有各自的地址空间。
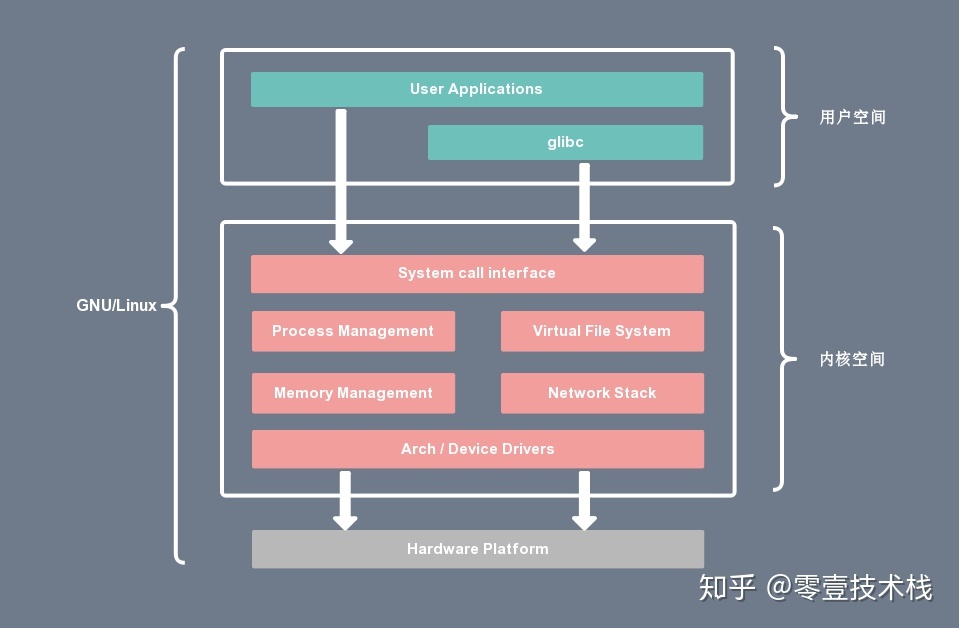
有了用户空间和内核空间的划分后,Linux 内部层级结构可以分为三部分,从最底层到最上层依次是硬件、内核空间和用户空间,如下图所示:
4. Linux I/O读写方式
Linux 提供了轮询、I/O 中断以及 DMA 传输这 3 种磁盘与主存之间的数据传输机制。其中轮询方式是基于死循环对 I/O 端口进行不断检测。I/O 中断方式是指当数据到达时,磁盘主动向 CPU 发起中断请求,由 CPU 自身负责数据的传输过程。 DMA 传输则在 I/O 中断的基础上引入了 DMA 磁盘控制器,由 DMA 磁盘控制器负责数据的传输,降低了 I/O 中断操作对 CPU 资源的大量消耗。
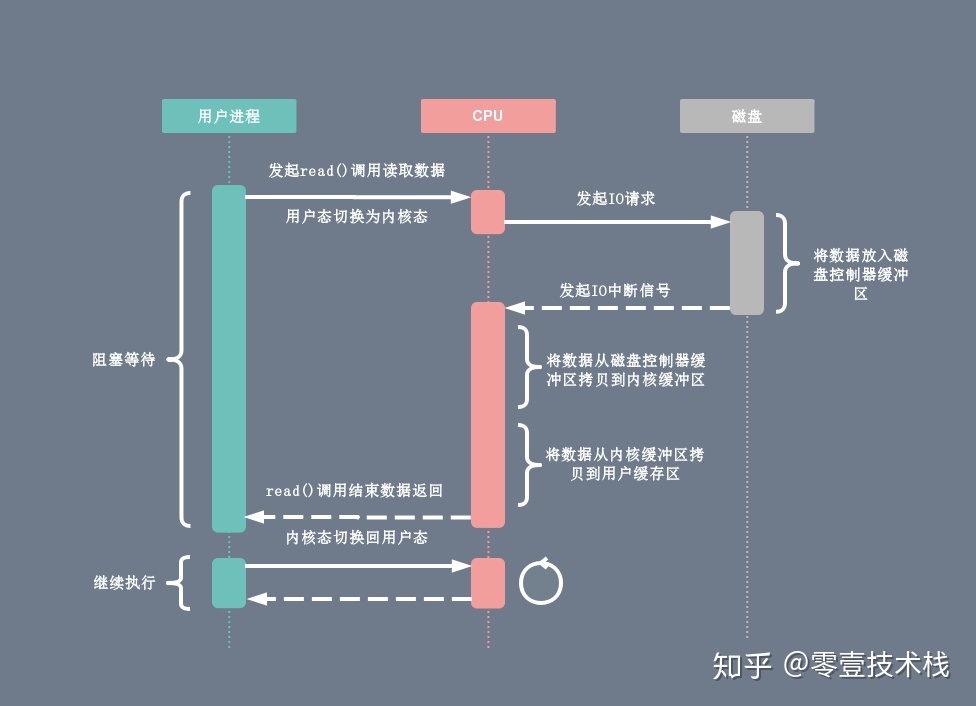
4.1. I/O中断原理
在 DMA 技术出现之前,应用程序与磁盘之间的 I/O 操作都是通过 CPU 的中断完成的。每次用户进程读取磁盘数据时,都需要 CPU 中断,然后发起 I/O 请求等待数据读取和拷贝完成,每次的 I/O 中断都导致 CPU 的上下文切换。
- 用户进程向 CPU 发起 read 系统调用读取数据,由用户态切换为内核态,然后一直阻塞等待数据的返回。
- CPU 在接收到指令以后对磁盘发起 I/O 请求,将磁盘数据先放入磁盘控制器缓冲区。
- 数据准备完成以后,磁盘向 CPU 发起 I/O 中断。
- CPU 收到 I/O 中断以后将磁盘缓冲区中的数据拷贝到内核缓冲区,然后再从内核缓冲区拷贝到用户缓冲区。
- 用户进程由内核态切换回用户态,解除阻塞状态,然后等待 CPU 的下一个执行时间钟。
4.2. DMA传输原理
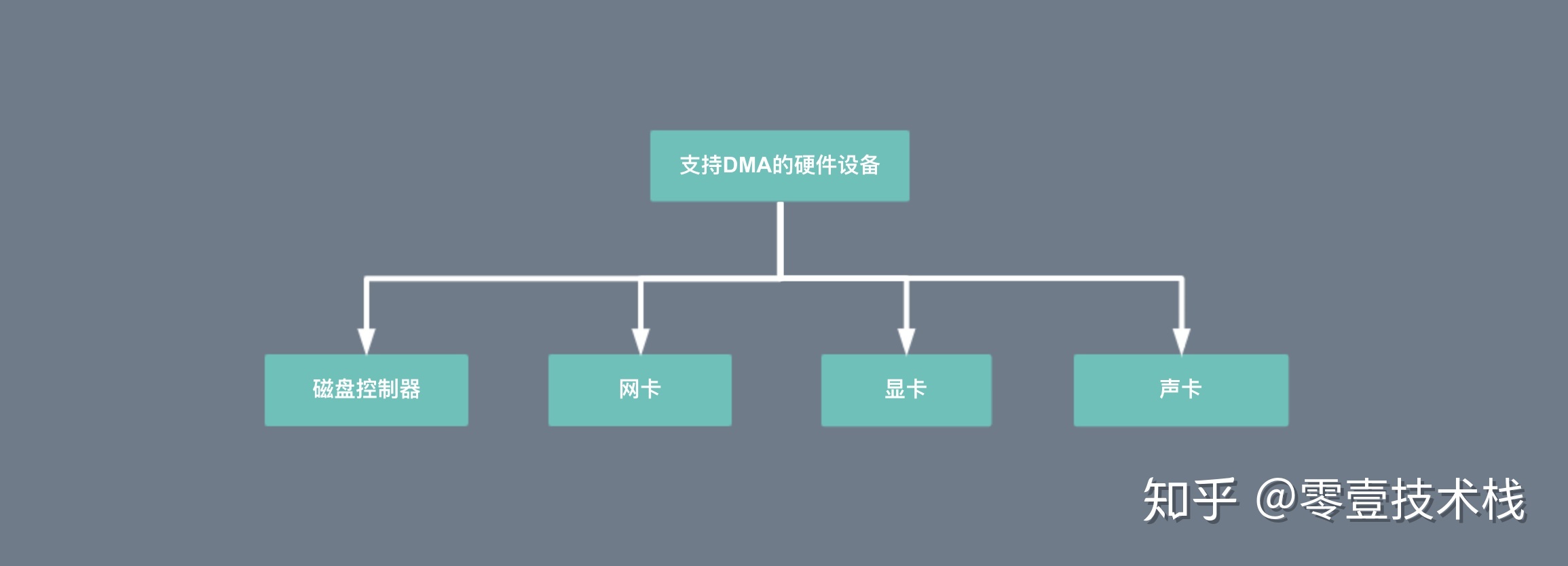
DMA 的全称叫直接内存存取(Direct Memory Access),是一种允许外围设备(硬件子系统)直接访问系统主内存的机制。也就是说,基于 DMA 访问方式,系统主内存于硬盘或网卡之间的数据传输可以绕开 CPU 的全程调度。目前大多数的硬件设备,包括磁盘控制器、网卡、显卡以及声卡等都支持 DMA 技术。
整个数据传输操作在一个 DMA 控制器的控制下进行的。CPU 除了在数据传输开始和结束时做一点处理外(开始和结束时候要做中断处理),在传输过程中 CPU 可以继续进行其他的工作。这样在大部分时间里,CPU 计算和 I/O 操作都处于并行操作,使整个计算机系统的效率大大提高。
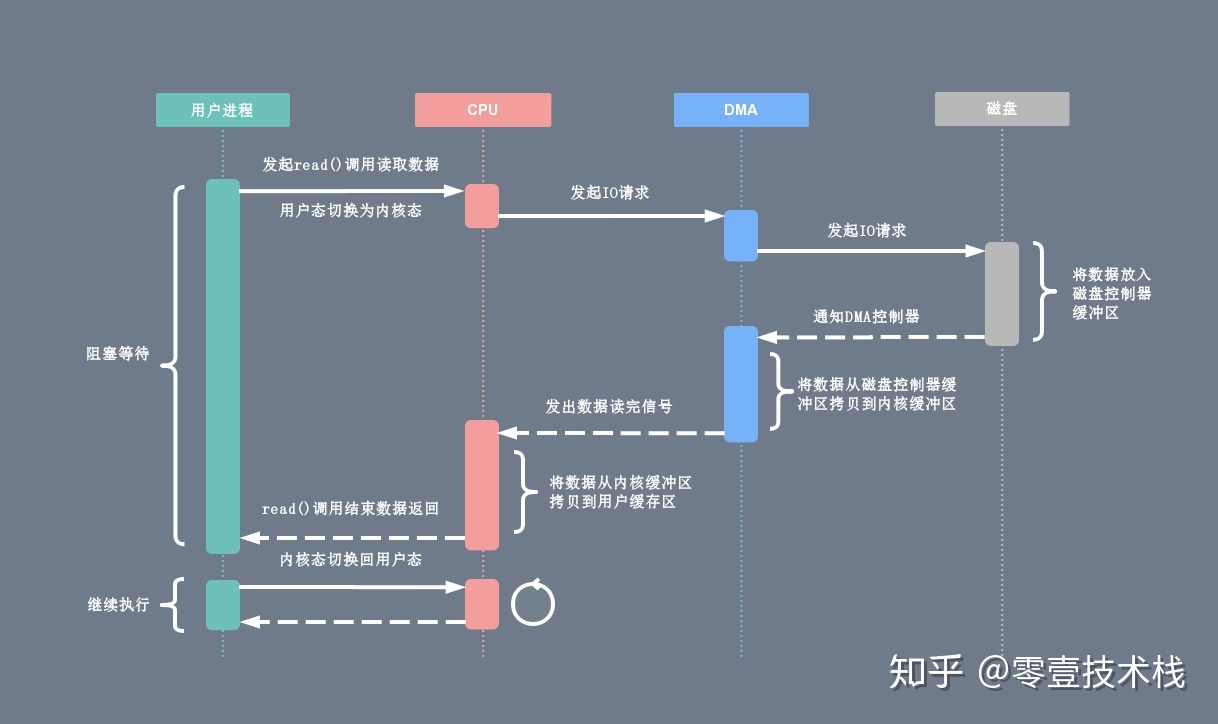
有了 DMA 磁盘控制器接管数据读写请求以后,CPU 从繁重的 I/O 操作中解脱,数据读取操作的流程如下:
- 用户进程向 CPU 发起 read 系统调用读取数据,由用户态切换为内核态,然后一直阻塞等待数据的返回。
- CPU 在接收到指令以后对 DMA 磁盘控制器发起调度指令。
- DMA 磁盘控制器对磁盘发起 I/O 请求,将磁盘数据先放入磁盘控制器缓冲区,CPU 全程不参与此过程。
- 数据读取完成后,DMA 磁盘控制器会接受到磁盘的通知,将数据从磁盘控制器缓冲区拷贝到内核缓冲区。
- DMA 磁盘控制器向 CPU 发出数据读完的信号,由 CPU 负责将数据从内核缓冲区拷贝到用户缓冲区。
- 用户进程由内核态切换回用户态,解除阻塞状态,然后等待 CPU 的下一个执行时间钟。
5. 传统I/O方式
为了更好的理解零拷贝解决的问题,我们首先了解一下传统 I/O 方式存在的问题。在 Linux 系统中,传统的访问方式是通过 write() 和 read() 两个系统调用实现的,通过 read() 函数读取文件到到缓存区中,然后通过 write() 方法把缓存中的数据输出到网络端口,伪代码如下:
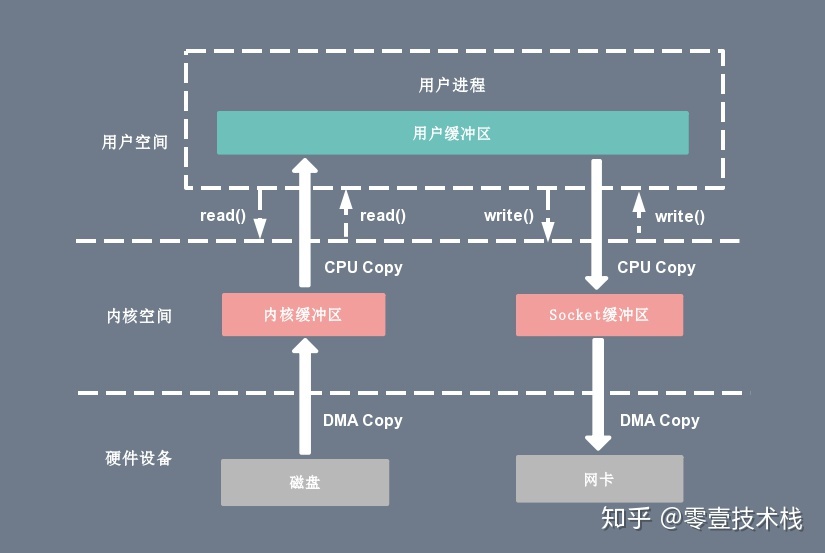
read(file_fd, tmp_buf, len); write(socket_fd, tmp_buf, len);下图分别对应传统 I/O 操作的数据读写流程,整个过程涉及 2 次 CPU 拷贝、2 次 DMA 拷贝总共 4 次拷贝,以及 4 次上下文切换,下面简单地阐述一下相关的概念。
- 上下文切换:当用户程序向内核发起系统调用时,CPU 将用户进程从用户态切换到内核态;当系统调用返回时,CPU 将用户进程从内核态切换回用户态。
- CPU拷贝:由 CPU 直接处理数据的传送,数据拷贝时会一直占用 CPU 的资源。
- DMA拷贝:由 CPU 向DMA磁盘控制器下达指令,让 DMA 控制器来处理数据的传送,数据传送完毕再把信息反馈给 CPU,从而减轻了 CPU 资源的占有率。
5.1. 传统读操作
当应用程序执行 read 系统调用读取一块数据的时候,如果这块数据已经存在于用户进程的页内存中,就直接从内存中读取数据;如果数据不存在,则先将数据从磁盘加载数据到内核空间的读缓存(read buffer)中,再从读缓存拷贝到用户进程的页内存中。
read(file_fd, tmp_buf, len);基于传统的 I/O 读取方式,read 系统调用会触发 2 次上下文切换,1 次 DMA 拷贝和 1 次 CPU 拷贝,发起数据读取的流程如下:
- 用户进程通过 read() 函数向内核(kernel)发起系统调用,上下文从用户态(user space)切换为内核态(kernel space)。
- CPU利用DMA控制器将数据从主存或硬盘拷贝到内核空间(kernel space)的读缓冲区(read buffer)。
- CPU将读缓冲区(read buffer)中的数据拷贝到用户空间(user space)的用户缓冲区(user buffer)。
- 上下文从内核态(kernel space)切换回用户态(user space),read 调用执行返回。
5.2. 传统写操作
当应用程序准备好数据,执行 write 系统调用发送网络数据时,先将数据从用户空间的页缓存拷贝到内核空间的网络缓冲区(socket buffer)中,然后再将写缓存中的数据拷贝到网卡设备完成数据发送。
write(socket_fd, tmp_buf, len);基于传统的 I/O 写入方式,write() 系统调用会触发 2 次上下文切换,1 次 CPU 拷贝和 1 次 DMA 拷贝,用户程序发送网络数据的流程如下:
- 用户进程通过 write() 函数向内核(kernel)发起系统调用,上下文从用户态(user space)切换为内核态(kernel space)。
- CPU 将用户缓冲区(user buffer)中的数据拷贝到内核空间(kernel space)的网络缓冲区(socket buffer)。
- CPU 利用 DMA 控制器将数据从网络缓冲区(socket buffer)拷贝到网卡进行数据传输。
- 上下文从内核态(kernel space)切换回用户态(user space),write 系统调用执行返回。
6. 零拷贝方式
在 Linux 中零拷贝技术主要有 3 个实现思路:用户态直接 I/O、减少数据拷贝次数以及写时复制技术。
- 用户态直接 I/O:应用程序可以直接访问硬件存储,操作系统内核只是辅助数据传输。这种方式依旧存在用户空间和内核空间的上下文切换,硬件上的数据直接拷贝至了用户空间,不经过内核空间。因此,直接 I/O 不存在内核空间缓冲区和用户空间缓冲区之间的数据拷贝。
- 减少数据拷贝次数:在数据传输过程中,避免数据在用户空间缓冲区和系统内核空间缓冲区之间的CPU拷贝,以及数据在系统内核空间内的CPU拷贝,这也是当前主流零拷贝技术的实现思路。
- 写时复制技术:写时复制指的是当多个进程共享同一块数据时,如果其中一个进程需要对这份数据进行修改,那么将其拷贝到自己的进程地址空间中,如果只是数据读取操作则不需要进行拷贝操作。
6.1. 用户态直接I/O
用户态直接 I/O 使得应用进程或运行在用户态(user space)下的库函数直接访问硬件设备,数据直接跨过内核进行传输,内核在数据传输过程除了进行必要的虚拟存储配置工作之外,不参与任何其他工作,这种方式能够直接绕过内核,极大提高了性能。
用户态直接 I/O 只能适用于不需要内核缓冲区处理的应用程序,这些应用程序通常在进程地址空间有自己的数据缓存机制,称为自缓存应用程序,如数据库管理系统就是一个代表。其次,这种零拷贝机制会直接操作磁盘 I/O,由于 CPU 和磁盘 I/O 之间的执行时间差距,会造成大量资源的浪费,解决方案是配合异步 I/O 使用。
6.2. mmap + write
一种零拷贝方式是使用 mmap + write 代替原来的 read + write 方式,减少了 1 次 CPU 拷贝操作。mmap 是 Linux 提供的一种内存映射文件方法,即将一个进程的地址空间中的一段虚拟地址映射到磁盘文件地址,mmap + write 的伪代码如下:
tmp_buf = mmap(file_fd, len); write(socket_fd, tmp_buf, len);使用 mmap 的目的是将内核中读缓冲区(read buffer)的地址与用户空间的缓冲区(user buffer)进行映射,从而实现内核缓冲区与应用程序内存的共享,省去了将数据从内核读缓冲区(read buffer)拷贝到用户缓冲区(user buffer)的过程,然而内核读缓冲区(read buffer)仍需将数据到内核写缓冲区(socket buffer),大致的流程如下图所示:
基于 mmap + write 系统调用的零拷贝方式,整个拷贝过程会发生 4 次上下文切换,1 次 CPU 拷贝和 2 次 DMA 拷贝,用户程序读写数据的流程如下:
- 用户进程通过 mmap() 函数向内核(kernel)发起系统调用,上下文从用户态(user space)切换为内核态(kernel space)。
- 将用户进程的内核空间的读缓冲区(read buffer)与用户空间的缓存区(user buffer)进行内存地址映射。
- CPU利用DMA控制器将数据从主存或硬盘拷贝到内核空间(kernel space)的读缓冲区(read buffer)。
- 上下文从内核态(kernel space)切换回用户态(user space),mmap 系统调用执行返回。
- 用户进程通过 write() 函数向内核(kernel)发起系统调用,上下文从用户态(user space)切换为内核态(kernel space)。
- CPU将读缓冲区(read buffer)中的数据拷贝到的网络缓冲区(socket buffer)。
- CPU利用DMA控制器将数据从网络缓冲区(socket buffer)拷贝到网卡进行数据传输。
- 上下文从内核态(kernel space)切换回用户态(user space),write 系统调用执行返回。
mmap 主要的用处是提高 I/O 性能,特别是针对大文件。对于小文件,内存映射文件反而会导致碎片空间的浪费,因为内存映射总是要对齐页边界,最小单位是 4 KB,一个 5 KB 的文件将会映射占用 8 KB 内存,也就会浪费 3 KB 内存。
mmap 的拷贝虽然减少了 1 次拷贝,提升了效率,但也存在一些隐藏的问题。当 mmap 一个文件时,如果这个文件被另一个进程所截获,那么 write 系统调用会因为访问非法地址被 SIGBUS 信号终止,SIGBUS 默认会杀死进程并产生一个 coredump,服务器可能因此被终止。
6.3. sendfile
sendfile 系统调用在 Linux 内核版本 2.1 中被引入,目的是简化通过网络在两个通道之间进行的数据传输过程。sendfile 系统调用的引入,不仅减少了 CPU 拷贝的次数,还减少了上下文切换的次数,它的伪代码如下:
sendfile(socket_fd, file_fd, len);通过 sendfile 系统调用,数据可以直接在内核空间内部进行 I/O 传输,从而省去了数据在用户空间和内核空间之间的来回拷贝。与 mmap 内存映射方式不同的是, sendfile 调用中 I/O 数据对用户空间是完全不可见的。也就是说,这是一次完全意义上的数据传输过程。
基于 sendfile 系统调用的零拷贝方式,整个拷贝过程会发生 2 次上下文切换,1 次 CPU 拷贝和 2 次 DMA 拷贝,用户程序读写数据的流程如下:
- 用户进程通过 sendfile() 函数向内核(kernel)发起系统调用,上下文从用户态(user space)切换为内核态(kernel space)。
- CPU 利用 DMA 控制器将数据从主存或硬盘拷贝到内核空间(kernel space)的读缓冲区(read buffer)。
- CPU 将读缓冲区(read buffer)中的数据拷贝到的网络缓冲区(socket buffer)。
- CPU 利用 DMA 控制器将数据从网络缓冲区(socket buffer)拷贝到网卡进行数据传输。
- 上下文从内核态(kernel space)切换回用户态(user space),sendfile 系统调用执行返回。
相比较于 mmap 内存映射的方式,sendfile 少了 2 次上下文切换,但是仍然有 1 次 CPU 拷贝操作。sendfile 存在的问题是用户程序不能对数据进行修改,而只是单纯地完成了一次数据传输过程。
6.4. sendfile + DMA gather copy
Linux 2.4 版本的内核对 sendfile 系统调用进行修改,为 DMA 拷贝引入了 gather 操作。它将内核空间(kernel space)的读缓冲区(read buffer)中对应的数据描述信息(内存地址、地址偏移量)记录到相应的网络缓冲区( socket buffer)中,由 DMA 根据内存地址、地址偏移量将数据批量地从读缓冲区(read buffer)拷贝到网卡设备中,这样就省去了内核空间中仅剩的 1 次 CPU 拷贝操作,sendfile 的伪代码如下:
sendfile(socket_fd, file_fd, len);在硬件的支持下,sendfile 拷贝方式不再从内核缓冲区的数据拷贝到 socket 缓冲区,取而代之的仅仅是缓冲区文件描述符和数据长度的拷贝,这样 DMA 引擎直接利用 gather 操作将页缓存中数据打包发送到网络中即可,本质就是和虚拟内存映射的思路类似。
基于 sendfile + DMA gather copy 系统调用的零拷贝方式,整个拷贝过程会发生 2 次上下文切换、0 次 CPU 拷贝以及 2 次 DMA 拷贝,用户程序读写数据的流程如下:
- 用户进程通过 sendfile() 函数向内核(kernel)发起系统调用,上下文从用户态(user space)切换为内核态(kernel space)。
- CPU 利用 DMA 控制器将数据从主存或硬盘拷贝到内核空间(kernel space)的读缓冲区(read buffer)。
- CPU 把读缓冲区(read buffer)的文件描述符(file descriptor)和数据长度拷贝到网络缓冲区(socket buffer)。
- 基于已拷贝的文件描述符(file descriptor)和数据长度,CPU 利用 DMA 控制器的 gather/scatter 操作直接批量地将数据从内核的读缓冲区(read buffer)拷贝到网卡进行数据传输。
- 上下文从内核态(kernel space)切换回用户态(user space),sendfile 系统调用执行返回。
sendfile + DMA gather copy 拷贝方式同样存在用户程序不能对数据进行修改的问题,而且本身需要硬件的支持,它只适用于将数据从文件拷贝到 socket 套接字上的传输过程。
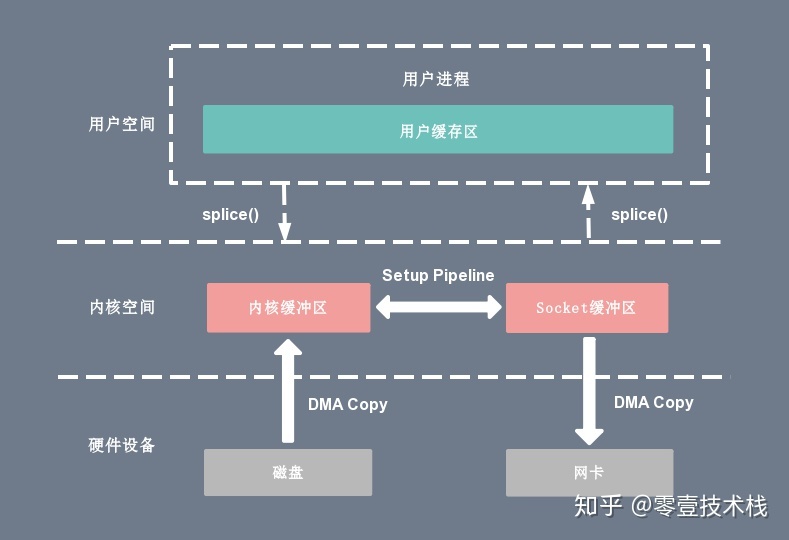
6.5. splice
sendfile 只适用于将数据从文件拷贝到 socket 套接字上,同时需要硬件的支持,这也限定了它的使用范围。Linux 在 2.6.17 版本引入 splice 系统调用,不仅不需要硬件支持,还实现了两个文件描述符之间的数据零拷贝。splice 的伪代码如下:
splice(fd_in, off_in, fd_out, off_out, len, flags);splice 系统调用可以在内核空间的读缓冲区(read buffer)和网络缓冲区(socket buffer)之间建立管道(pipeline),从而避免了两者之间的 CPU 拷贝操作。
基于 splice 系统调用的零拷贝方式,整个拷贝过程会发生 2 次上下文切换,0 次 CPU 拷贝以及 2 次 DMA 拷贝,用户程序读写数据的流程如下:
- 用户进程通过 splice() 函数向内核(kernel)发起系统调用,上下文从用户态(user space)切换为内核态(kernel space)。
- CPU 利用 DMA 控制器将数据从主存或硬盘拷贝到内核空间(kernel space)的读缓冲区(read buffer)。
- CPU 在内核空间的读缓冲区(read buffer)和网络缓冲区(socket buffer)之间建立管道(pipeline)。
- CPU 利用 DMA 控制器将数据从网络缓冲区(socket buffer)拷贝到网卡进行数据传输。
- 上下文从内核态(kernel space)切换回用户态(user space),splice 系统调用执行返回。
splice 拷贝方式也同样存在用户程序不能对数据进行修改的问题。除此之外,它使用了 Linux 的管道缓冲机制,可以用于任意两个文件描述符中传输数据,但是它的两个文件描述符参数中有一个必须是管道设备。
6.6. 写时复制
在某些情况下,内核缓冲区可能被多个进程所共享,如果某个进程想要这个共享区进行 write 操作,由于 write 不提供任何的锁操作,那么就会对共享区中的数据造成破坏,写时复制的引入就是 Linux 用来保护数据的。
写时复制指的是当多个进程共享同一块数据时,如果其中一个进程需要对这份数据进行修改,那么就需要将其拷贝到自己的进程地址空间中。这样做并不影响其他进程对这块数据的操作,每个进程要修改的时候才会进行拷贝,所以叫写时拷贝。这种方法在某种程度上能够降低系统开销,如果某个进程永远不会对所访问的数据进行更改,那么也就永远不需要拷贝。
6.7. 缓冲区共享
缓冲区共享方式完全改写了传统的 I/O 操作,因为传统 I/O 接口都是基于数据拷贝进行的,要避免拷贝就得去掉原先的那套接口并重新改写,所以这种方法是比较全面的零拷贝技术,目前比较成熟的一个方案是在 Solaris 上实现的 fbuf(Fast Buffer,快速缓冲区)。
fbuf 的思想是每个进程都维护着一个缓冲区池,这个缓冲区池能被同时映射到用户空间(user space)和内核态(kernel space),内核和用户共享这个缓冲区池,这样就避免了一系列的拷贝操作。
缓冲区共享的难度在于管理共享缓冲区池需要应用程序、网络软件以及设备驱动程序之间的紧密合作,而且如何改写 API 目前还处于试验阶段并不成熟。
7. Linux零拷贝对比
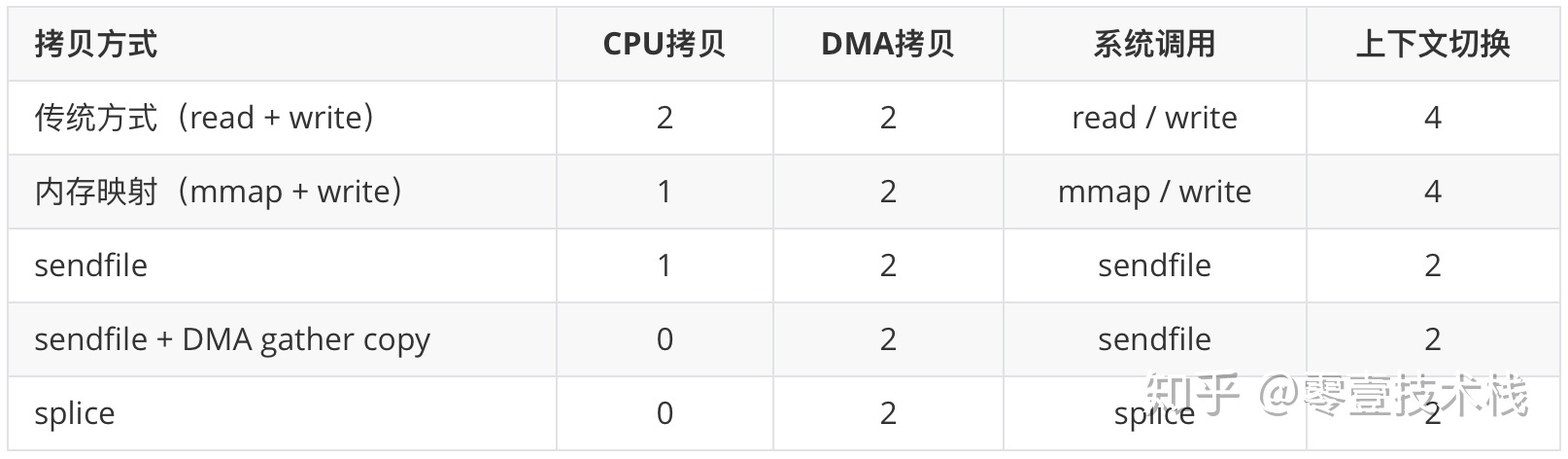
无论是传统 I/O 拷贝方式还是引入零拷贝的方式,2 次 DMA Copy 是都少不了的,因为两次 DMA 都是依赖硬件完成的。下面从 CPU 拷贝次数、DMA 拷贝次数以及系统调用几个方面总结一下上述几种 I/O 拷贝方式的差别。
8. Java NIO零拷贝实现
在 Java NIO 中的通道(Channel)就相当于操作系统的内核空间(kernel space)的缓冲区,而缓冲区(Buffer)对应的相当于操作系统的用户空间(user space)中的用户缓冲区(user buffer)。
- 通道(Channel)是全双工的(双向传输),它既可能是读缓冲区(read buffer),也可能是网络缓冲区(socket buffer)。
- 缓冲区(Buffer)分为堆内存(HeapBuffer)和堆外内存(DirectBuffer),这是通过 malloc() 分配出来的用户态内存。
堆外内存(DirectBuffer)在使用后需要应用程序手动回收,而堆内存(HeapBuffer)的数据在 GC 时可能会被自动回收。因此,在使用 HeapBuffer 读写数据时,为了避免缓冲区数据因为 GC 而丢失,NIO 会先把 HeapBuffer 内部的数据拷贝到一个临时的 DirectBuffer 中的本地内存(native memory),这个拷贝涉及到 sun.misc.Unsafe.copyMemory() 的调用,背后的实现原理与 memcpy() 类似。 最后,将临时生成的 DirectBuffer 内部的数据的内存地址传给 I/O 调用函数,这样就避免了再去访问 Java 对象处理 I/O 读写。
8.1. MappedByteBuffer
MappedByteBuffer 是 NIO 基于内存映射(mmap)这种零拷贝方式的提供的一种实现,它继承自 ByteBuffer。FileChannel 定义了一个 map() 方法,它可以把一个文件从 position 位置开始的 size 大小的区域映射为内存映像文件。抽象方法 map() 方法在 FileChannel 中的定义如下:
public abstract MappedByteBuffer map(MapMode mode, long position, long size) throws IOException;
- mode:限定内存映射区域(MappedByteBuffer)对内存映像文件的访问模式,包括只可读(READ_ONLY)、可读可写(READ_WRITE)和写时拷贝(PRIVATE)三种模式。
- position:文件映射的起始地址,对应内存映射区域(MappedByteBuffer)的首地址。
- size:文件映射的字节长度,从 position 往后的字节数,对应内存映射区域(MappedByteBuffer)的大小。
MappedByteBuffer 相比 ByteBuffer 新增了 fore()、load() 和 isLoad() 三个重要的方法:
- fore():对于处于 READ_WRITE 模式下的缓冲区,把对缓冲区内容的修改强制刷新到本地文件。
- load():将缓冲区的内容载入物理内存中,并返回这个缓冲区的引用。
- isLoaded():如果缓冲区的内容在物理内存中,则返回 true,否则返回 false。
下面给出一个利用 MappedByteBuffer 对文件进行读写的使用示例:
private final static String CONTENT = "Zero copy implemented by MappedByteBuffer"; private final static String FILE_NAME = "/mmap.txt"; private final static String CHARSET = "UTF-8";
- 写文件数据:打开文件通道 fileChannel 并提供读权限、写权限和数据清空权限,通过 fileChannel 映射到一个可写的内存缓冲区 mappedByteBuffer,将目标数据写入 mappedByteBuffer,通过 force() 方法把缓冲区更改的内容强制写入本地文件。
@Test public void writeToFileByMappedByteBuffer() { Path path = Paths.get(getClass().getResource(FILE_NAME).getPath()); byte[] bytes = CONTENT.getBytes(Charset.forName(CHARSET)); try (FileChannel fileChannel = FileChannel.open(path, StandardOpenOption.READ, StandardOpenOption.WRITE, StandardOpenOption.TRUNCATE_EXISTING)) { MappedByteBuffer mappedByteBuffer = fileChannel.map(READ_WRITE, 0, bytes.length); if (mappedByteBuffer != null) { mappedByteBuffer.put(bytes); mappedByteBuffer.force(); } } catch (IOException e) { e.printStackTrace(); } }
- 读文件数据:打开文件通道 fileChannel 并提供只读权限,通过 fileChannel 映射到一个只可读的内存缓冲区 mappedByteBuffer,读取 mappedByteBuffer 中的字节数组即可得到文件数据。
@Test public void readFromFileByMappedByteBuffer() { Path path = Paths.get(getClass().getResource(FILE_NAME).getPath()); int length = CONTENT.getBytes(Charset.forName(CHARSET)).length; try (FileChannel fileChannel = FileChannel.open(path, StandardOpenOption.READ)) { MappedByteBuffer mappedByteBuffer = fileChannel.map(READ_ONLY, 0, length); if (mappedByteBuffer != null) { byte[] bytes = new byte[length]; mappedByteBuffer.get(bytes); String content = new String(bytes, StandardCharsets.UTF_8); assertEquals(content, "Zero copy implemented by MappedByteBuffer"); } } catch (IOException e) { e.printStackTrace(); } }下面介绍 map() 方法的底层实现原理。map() 方法是 java.nio.channels.FileChannel 的抽象方法,由子类 sun.nio.ch.FileChannelImpl.java 实现,下面是和内存映射相关的核心代码:
public MappedByteBuffer map(MapMode mode, long position, long size) throws IOException { int pagePosition = (int)(position % allocationGranularity); long mapPosition = position - pagePosition; long mapSize = size + pagePosition; try { addr = map0(imode, mapPosition, mapSize); } catch (OutOfMemoryError x) { System.gc(); try { Thread.sleep(100); } catch (InterruptedException y) { Thread.currentThread().interrupt(); } try { addr = map0(imode, mapPosition, mapSize); } catch (OutOfMemoryError y) { throw new IOException("Map failed", y); } } int isize = (int)size; Unmapper um = new Unmapper(addr, mapSize, isize, mfd); if ((!writable) || (imode == MAP_RO)) { return Util.newMappedByteBufferR(isize, addr + pagePosition, mfd, um); } else { return Util.newMappedByteBuffer(isize, addr + pagePosition, mfd, um); } }map() 方法通过本地方法 map0() 为文件分配一块虚拟内存,作为它的内存映射区域,然后返回这块内存映射区域的起始地址。
- 文件映射需要在 Java 堆中创建一个 MappedByteBuffer 的实例。如果第一次文件映射导致 OOM,则手动触发垃圾回收,休眠 100ms 后再尝试映射,如果失败则抛出异常。
- 通过 Util 的 newMappedByteBuffer (可读可写)方法或者 newMappedByteBufferR(仅读) 方法方法反射创建一个 DirectByteBuffer 实例,其中 DirectByteBuffer 是 MappedByteBuffer 的子类。
map() 方法返回的是内存映射区域的起始地址,通过(起始地址 + 偏移量)就可以获取指定内存的数据。这样一定程度上替代了 read() 或 write() 方法,底层直接采用 sun.misc.Unsafe 类的 getByte() 和 putByte() 方法对数据进行读写。
private native long map0(int prot, long position, long mapSize) throws IOException;上面是本地方法(native method)map0 的定义,它通过 JNI(Java Native Interface)调用底层 C 的实现,这个 native 函数(Java_sun_nio_ch_FileChannelImpl_map0)的实现位于 JDK 源码包下的 native/sun/nio/ch/FileChannelImpl.c 这个源文件里面。
JNIEXPORT jlong JNICALL Java_sun_nio_ch_FileChannelImpl_map0(JNIEnv *env, jobject this, jint prot, jlong off, jlong len) { void *mapAddress = 0; jobject fdo = (*env)->GetObjectField(env, this, chan_fd); jint fd = fdval(env, fdo); int protections = 0; int flags = 0; if (prot == sun_nio_ch_FileChannelImpl_MAP_RO) { protections = PROT_READ; flags = MAP_SHARED; } else if (prot == sun_nio_ch_FileChannelImpl_MAP_RW) { protections = PROT_WRITE | PROT_READ; flags = MAP_SHARED; } else if (prot == sun_nio_ch_FileChannelImpl_MAP_PV) { protections = PROT_WRITE | PROT_READ; flags = MAP_PRIVATE; } mapAddress = mmap64( 0, /* Let OS decide location */ len, /* Number of bytes to map */ protections, /* File permissions */ flags, /* Changes are shared */ fd, /* File descriptor of mapped file */ off); /* Offset into file */ if (mapAddress == MAP_FAILED) { if (errno == ENOMEM) { JNU_ThrowOutOfMemoryError(env, "Map failed"); return IOS_THROWN; } return handle(env, -1, "Map failed"); } return ((jlong) (unsigned long) mapAddress); }可以看出 map0() 函数最终是通过 mmap64() 这个函数对 Linux 底层内核发出内存映射的调用, mmap64() 函数的原型如下:
#include <sys/mman.h> void *mmap64(void *addr, size_t len, int prot, int flags, int fd, off64_t offset);下面详细介绍一下 mmap64() 函数各个参数的含义以及参数可选值:
- addr:文件在用户进程空间的内存映射区中的起始地址,是一个建议的参数,通常可设置为 0 或 NULL,此时由内核去决定真实的起始地址。当 flags 为 MAP_FIXED 时,addr 就是一个必选的参数,即需要提供一个存在的地址。
- len:文件需要进行内存映射的字节长度
- prot:控制用户进程对内存映射区的访问权限
- PROT_READ:读权限
- PROT_WRITE:写权限
- PROT_EXEC:执行权限
- PROT_NONE:无权限
- flags:控制内存映射区的修改是否被多个进程共享
- MAP_PRIVATE:对内存映射区数据的修改不会反映到真正的文件,数据修改发生时采用写时复制机制
- MAP_SHARED:对内存映射区的修改会同步到真正的文件,修改对共享此内存映射区的进程是可见的
- MAP_FIXED:不建议使用,这种模式下 addr 参数指定的必须的提供一个存在的 addr 参数
- fd:文件描述符。每次 map 操作会导致文件的引用计数加 1,每次 unmap 操作或者结束进程会导致引用计数减 1
- offset:文件偏移量。进行映射的文件位置,从文件起始地址向后的位移量
下面总结一下 MappedByteBuffer 的特点和不足之处:
- MappedByteBuffer 使用是堆外的虚拟内存,因此分配(map)的内存大小不受 JVM 的 -Xmx 参数限制,但是也是有大小限制的。
- 如果当文件超出 Integer.MAX_VALUE 字节限制时,可以通过 position 参数重新 map 文件后面的内容。
- MappedByteBuffer 在处理大文件时性能的确很高,但也存内存占用、文件关闭不确定等问题,被其打开的文件只有在垃圾回收的才会被关闭,而且这个时间点是不确定的。
- MappedByteBuffer 提供了文件映射内存的 mmap() 方法,也提供了释放映射内存的 unmap() 方法。然而 unmap() 是 FileChannelImpl 中的私有方法,无法直接显示调用。因此,用户程序需要通过 Java 反射的调用 sun.misc.Cleaner 类的 clean() 方法手动释放映射占用的内存区域。
public static void clean(final Object buffer) throws Exception { AccessController.doPrivileged((PrivilegedAction) () -> { try { Method getCleanerMethod = buffer.getClass().getMethod("cleaner", new Class[0]); getCleanerMethod.setAccessible(true); Cleaner cleaner = (Cleaner) getCleanerMethod.invoke(buffer, new Object[0]); cleaner.clean(); } catch(Exception e) { e.printStackTrace(); } }); }8.2. DirectByteBuffer
DirectByteBuffer 的对象引用位于 Java 内存模型的堆里面,JVM 可以对 DirectByteBuffer 的对象进行内存分配和回收管理,一般使用 DirectByteBuffer 的静态方法 allocateDirect() 创建 DirectByteBuffer 实例并分配内存。
public static ByteBuffer allocateDirect(int capacity) { return new DirectByteBuffer(capacity); }DirectByteBuffer 内部的字节缓冲区位在于堆外的(用户态)直接内存,它是通过 Unsafe 的本地方法 allocateMemory() 进行内存分配,底层调用的是操作系统的 malloc() 函数。
DirectByteBuffer(int cap) { super(-1, 0, cap, cap); boolean pa = VM.isDirectMemoryPageAligned(); int ps = Bits.pageSize(); long size = Math.max(1L, (long)cap + (pa ? ps : 0)); Bits.reserveMemory(size, cap); long base = 0; try { base = unsafe.allocateMemory(size); } catch (OutOfMemoryError x) { Bits.unreserveMemory(size, cap); throw x; } unsafe.setMemory(base, size, (byte) 0); if (pa && (base % ps != 0)) { address = base + ps - (base & (ps - 1)); } else { address = base; } cleaner = Cleaner.create(this, new Deallocator(base, size, cap)); att = null; }除此之外,初始化 DirectByteBuffer 时还会创建一个 Deallocator 线程,并通过 Cleaner 的 freeMemory() 方法来对直接内存进行回收操作,freeMemory() 底层调用的是操作系统的 free() 函数。
private static class Deallocator implements Runnable { private static Unsafe unsafe = Unsafe.getUnsafe(); private long address; private long size; private int capacity; private Deallocator(long address, long size, int capacity) { assert (address != 0); this.address = address; this.size = size; this.capacity = capacity; } public void run() { if (address == 0) { return; } unsafe.freeMemory(address); address = 0; Bits.unreserveMemory(size, capacity); } }由于使用 DirectByteBuffer 分配的是系统本地的内存,不在 JVM 的管控范围之内,因此直接内存的回收和堆内存的回收不同,直接内存如果使用不当,很容易造成 OutOfMemoryError。
说了这么多,那么 DirectByteBuffer 和零拷贝有什么关系?前面有提到在 MappedByteBuffer 进行内存映射时,它的 map() 方法会通过 Util.newMappedByteBuffer() 来创建一个缓冲区实例,初始化的代码如下:
static MappedByteBuffer newMappedByteBuffer(int size, long addr, FileDescriptor fd, Runnable unmapper) { MappedByteBuffer dbb; if (directByteBufferConstructor == null) initDBBConstructor(); try { dbb = (MappedByteBuffer)directByteBufferConstructor.newInstance( new Object[] { new Integer(size), new Long(addr), fd, unmapper }); } catch (InstantiationException | IllegalAccessException | InvocationTargetException e) { throw new InternalError(e); } return dbb; } private static void initDBBRConstructor() { AccessController.doPrivileged(new PrivilegedAction() { public Void run() { try { Class<?> cl = Class.forName("java.nio.DirectByteBufferR"); Constructor<?> ctor = cl.getDeclaredConstructor( new Class<?>[] { int.class, long.class, FileDescriptor.class, Runnable.class }); ctor.setAccessible(true); directByteBufferRConstructor = ctor; } catch (ClassNotFoundException | NoSuchMethodException | IllegalArgumentException | ClassCastException x) { throw new InternalError(x); } return null; }}); }DirectByteBuffer 是 MappedByteBuffer 的具体实现类。实际上,Util.newMappedByteBuffer() 方法通过反射机制获取 DirectByteBuffer 的构造器,然后创建一个 DirectByteBuffer 的实例,对应的是一个单独用于内存映射的构造方法:
protected DirectByteBuffer(int cap, long addr, FileDescriptor fd, Runnable unmapper) { super(-1, 0, cap, cap, fd); address = addr; cleaner = Cleaner.create(this, unmapper); att = null; }因此,除了允许分配操作系统的直接内存以外,DirectByteBuffer 本身也具有文件内存映射的功能,这里不做过多说明。我们需要关注的是,DirectByteBuffer 在 MappedByteBuffer 的基础上提供了内存映像文件的随机读取 get() 和写入 write() 的操作。
- 内存映像文件的随机读操作
public byte get() { return ((unsafe.getByte(ix(nextGetIndex())))); } public byte get(int i) { return ((unsafe.getByte(ix(checkIndex(i))))); }
- 内存映像文件的随机写操作
public ByteBuffer put(byte x) { unsafe.putByte(ix(nextPutIndex()), ((x))); return this; } public ByteBuffer put(int i, byte x) { unsafe.putByte(ix(checkIndex(i)), ((x))); return this; }内存映像文件的随机读写都是借助 ix() 方法实现定位的, ix() 方法通过内存映射空间的内存首地址(address)和给定偏移量 i 计算出指针地址,然后由 unsafe 类的 get() 和 put() 方法和对指针指向的数据进行读取或写入。
private long ix(int i) { return address + ((long)i << 0); }8.3. FileChannel
FileChannel 是一个用于文件读写、映射和操作的通道,同时它在并发环境下是线程安全的,基于 FileInputStream、FileOutputStream 或者 RandomAccessFile 的 getChannel() 方法可以创建并打开一个文件通道。FileChannel 定义了 transferFrom() 和 transferTo() 两个抽象方法,它通过在通道和通道之间建立连接实现数据传输的。
- transferTo():通过 FileChannel 把文件里面的源数据写入一个 WritableByteChannel 的目的通道。
public abstract long transferTo(long position, long count, WritableByteChannel target) throws IOException;
- transferFrom():把一个源通道 ReadableByteChannel 中的数据读取到当前 FileChannel 的文件里面。
public abstract long transferFrom(ReadableByteChannel src, long position, long count) throws IOException;下面给出 FileChannel 利用 transferTo() 和 transferFrom() 方法进行数据传输的使用示例:
private static final String CONTENT = "Zero copy implemented by FileChannel"; private static final String SOURCE_FILE = "/source.txt"; private static final String TARGET_FILE = "/target.txt"; private static final String CHARSET = "UTF-8";首先在类加载根路径下创建 source.txt 和 target.txt 两个文件,对源文件 source.txt 文件写入初始化数据。
@Before public void setup() { Path source = Paths.get(getClassPath(SOURCE_FILE)); byte[] bytes = CONTENT.getBytes(Charset.forName(CHARSET)); try (FileChannel fromChannel = FileChannel.open(source, StandardOpenOption.READ, StandardOpenOption.WRITE, StandardOpenOption.TRUNCATE_EXISTING)) { fromChannel.write(ByteBuffer.wrap(bytes)); } catch (IOException e) { e.printStackTrace(); } }对于 transferTo() 方法而言,目的通道 toChannel 可以是任意的单向字节写通道 WritableByteChannel;而对于 transferFrom() 方法而言,源通道 fromChannel 可以是任意的单向字节读通道 ReadableByteChannel。其中,FileChannel、SocketChannel 和 DatagramChannel 等通道实现了 WritableByteChannel 和 ReadableByteChannel 接口,都是同时支持读写的双向通道。为了方便测试,下面给出基于 FileChannel 完成 channel-to-channel 的数据传输示例。
- 通过 transferTo() 将 fromChannel 中的数据拷贝到 toChannel
@Test public void transferTo() throws Exception { try (FileChannel fromChannel = new RandomAccessFile( getClassPath(SOURCE_FILE), "rw").getChannel(); FileChannel toChannel = new RandomAccessFile( getClassPath(TARGET_FILE), "rw").getChannel()) { long position = 0L; long offset = fromChannel.size(); fromChannel.transferTo(position, offset, toChannel); } }
- 通过 transferFrom() 将 fromChannel 中的数据拷贝到 toChannel
@Test public void transferFrom() throws Exception { try (FileChannel fromChannel = new RandomAccessFile( getClassPath(SOURCE_FILE), "rw").getChannel(); FileChannel toChannel = new RandomAccessFile( getClassPath(TARGET_FILE), "rw").getChannel()) { long position = 0L; long offset = fromChannel.size(); toChannel.transferFrom(fromChannel, position, offset); } }下面介绍 transferTo() 和 transferFrom() 方法的底层实现原理,这两个方法也是 java.nio.channels.FileChannel 的抽象方法,由子类 sun.nio.ch.FileChannelImpl.java 实现。transferTo() 和 transferFrom() 底层都是基于 sendfile 实现数据传输的,其中 FileChannelImpl.java 定义了 3 个常量,用于标示当前操作系统的内核是否支持 sendfile 以及 sendfile 的相关特性。
private static volatile boolean transferSupported = true; private static volatile boolean pipeSupported = true; private static volatile boolean fileSupported = true;
- transferSupported:用于标记当前的系统内核是否支持 sendfile() 调用,默认为 true。
- pipeSupported:用于标记当前的系统内核是否支持文件描述符(fd)基于管道(pipe)的 sendfile() 调用,默认为 true。
- fileSupported:用于标记当前的系统内核是否支持文件描述符(fd)基于文件(file)的 sendfile() 调用,默认为 true。
下面以 transferTo() 的源码实现为例。FileChannelImpl 首先执行 transferToDirectly() 方法,以 sendfile 的零拷贝方式尝试数据拷贝。如果系统内核不支持 sendfile,进一步执行 transferToTrustedChannel() 方法,以 mmap 的零拷贝方式进行内存映射,这种情况下目的通道必须是 FileChannelImpl 或者 SelChImpl 类型。如果以上两步都失败了,则执行 transferToArbitraryChannel() 方法,基于传统的 I/O 方式完成读写,具体步骤是初始化一个临时的 DirectBuffer,将源通道 FileChannel 的数据读取到 DirectBuffer,再写入目的通道 WritableByteChannel 里面。
public long transferTo(long position, long count, WritableByteChannel target) throws IOException { // 计算文件的大小 long sz = size(); // 校验起始位置 if (position > sz) return 0; int icount = (int)Math.min(count, Integer.MAX_VALUE); // 校验偏移量 if ((sz - position) < icount) icount = (int)(sz - position); long n; if ((n = transferToDirectly(position, icount, target)) >= 0) return n; if ((n = transferToTrustedChannel(position, icount, target)) >= 0) return n; return transferToArbitraryChannel(position, icount, target); }接下来重点分析一下 transferToDirectly() 方法的实现,也就是 transferTo() 通过 sendfile 实现零拷贝的精髓所在。可以看到,transferToDirectlyInternal() 方法先获取到目的通道 WritableByteChannel 的文件描述符 targetFD,获取同步锁然后执行 transferToDirectlyInternal() 方法。
private long transferToDirectly(long position, int icount, WritableByteChannel target) throws IOException { // 省略从target获取targetFD的过程 if (nd.transferToDirectlyNeedsPositionLock()) { synchronized (positionLock) { long pos = position(); try { return transferToDirectlyInternal(position, icount, target, targetFD); } finally { position(pos); } } } else { return transferToDirectlyInternal(position, icount, target, targetFD); } }最终由 transferToDirectlyInternal() 调用本地方法 transferTo0() ,尝试以 sendfile 的方式进行数据传输。如果系统内核完全不支持 sendfile,比如 Windows 操作系统,则返回 UNSUPPORTED 并把 transferSupported 标识为 false。如果系统内核不支持 sendfile 的一些特性,比如说低版本的 Linux 内核不支持 DMA gather copy 操作,则返回 UNSUPPORTED_CASE 并把 pipeSupported 或者 fileSupported 标识为 false。
private long transferToDirectlyInternal(long position, int icount, WritableByteChannel target, FileDescriptor targetFD) throws IOException { assert !nd.transferToDirectlyNeedsPositionLock() || Thread.holdsLock(positionLock); long n = -1; int ti = -1; try { begin(); ti = threads.add(); if (!isOpen()) return -1; do { n = transferTo0(fd, position, icount, targetFD); } while ((n == IOStatus.INTERRUPTED) && isOpen()); if (n == IOStatus.UNSUPPORTED_CASE) { if (target instanceof SinkChannelImpl) pipeSupported = false; if (target instanceof FileChannelImpl) fileSupported = false; return IOStatus.UNSUPPORTED_CASE; } if (n == IOStatus.UNSUPPORTED) { transferSupported = false; return IOStatus.UNSUPPORTED; } return IOStatus.normalize(n); } finally { threads.remove(ti); end (n > -1); } }本地方法(native method)transferTo0() 通过 JNI(Java Native Interface)调用底层 C 的函数,这个 native 函数(Java_sun_nio_ch_FileChannelImpl_transferTo0)同样位于 JDK 源码包下的 native/sun/nio/ch/FileChannelImpl.c 源文件里面。JNI 函数 Java_sun_nio_ch_FileChannelImpl_transferTo0() 基于条件编译对不同的系统进行预编译,下面是 JDK 基于 Linux 系统内核对 transferTo() 提供的调用封装。
#if defined(__linux__) || defined(__solaris__) #include <sys/sendfile.h> #elif defined(_AIX) #include <sys/socket.h> #elif defined(_ALLBSD_SOURCE) #include <sys/types.h> #include <sys/socket.h> #include <sys/uio.h> #define lseek64 lseek #define mmap64 mmap #endif JNIEXPORT jlong JNICALL Java_sun_nio_ch_FileChannelImpl_transferTo0(JNIEnv *env, jobject this, jobject srcFDO, jlong position, jlong count, jobject dstFDO) { jint srcFD = fdval(env, srcFDO); jint dstFD = fdval(env, dstFDO); #if defined(__linux__) off64_t offset = (off64_t)position; jlong n = sendfile64(dstFD, srcFD, &offset, (size_t)count); return n; #elif defined(__solaris__) result = sendfilev64(dstFD, &sfv, 1, &numBytes); return result; #elif defined(__APPLE__) result = sendfile(srcFD, dstFD, position, &numBytes, NULL, 0); return result; #endif }对 Linux、Solaris 以及 Apple 系统而言,transferTo0() 函数底层会执行 sendfile64 这个系统调用完成零拷贝操作,sendfile64() 函数的原型如下:
#include <sys/sendfile.h> ssize_t sendfile64(int out_fd, int in_fd, off_t *offset, size_t count);下面简单介绍一下 sendfile64() 函数各个参数的含义:
- out_fd:待写入的文件描述符
- in_fd:待读取的文件描述符
- offset:指定 in_fd 对应文件流的读取位置,如果为空,则默认从起始位置开始
- count:指定在文件描述符 in_fd 和 out_fd 之间传输的字节数
在 Linux 2.6.3 之前,out_fd 必须是一个 socket,而从 Linux 2.6.3 以后,out_fd 可以是任何文件。也就是说,sendfile64() 函数不仅可以进行网络文件传输,还可以对本地文件实现零拷贝操作。
9. 其它的零拷贝实现
9.1. Netty零拷贝
Netty 中的零拷贝和上面提到的操作系统层面上的零拷贝不太一样, 我们所说的 Netty 零拷贝完全是基于(Java 层面)用户态的,它的更多的是偏向于数据操作优化这样的概念,具体表现在以下几个方面:
- Netty 通过 DefaultFileRegion 类对 java.nio.channels.FileChannel 的 tranferTo() 方法进行包装,在文件传输时可以将文件缓冲区的数据直接发送到目的通道(Channel)
- ByteBuf 可以通过 wrap 操作把字节数组、ByteBuf、ByteBuffer 包装成一个 ByteBuf 对象, 进而避免了拷贝操作
- ByteBuf 支持 slice 操作, 因此可以将 ByteBuf 分解为多个共享同一个存储区域的 ByteBuf,避免了内存的拷贝
- Netty 提供了 CompositeByteBuf 类,它可以将多个 ByteBuf 合并为一个逻辑上的 ByteBuf,避免了各个 ByteBuf 之间的拷贝
其中第 1 条属于操作系统层面的零拷贝操作,后面 3 条只能算用户层面的数据操作优化。
9.2. RocketMQ和Kafka对比
RocketMQ 选择了 mmap + write 这种零拷贝方式,适用于业务级消息这种小块文件的数据持久化和传输;而 Kafka 采用的是 sendfile 这种零拷贝方式,适用于系统日志消息这种高吞吐量的大块文件的数据持久化和传输。但是值得注意的一点是,Kafka 的索引文件使用的是 mmap + write 方式,数据文件使用的是 sendfile 方式。
小结
本文开篇详述了 Linux 操作系统中的物理内存和虚拟内存,内核空间和用户空间的概念以及 Linux 内部的层级结构。在此基础上,进一步分析和对比传统 I/O 方式和零拷贝方式的区别,然后介绍了 Linux 内核提供的几种零拷贝实现,包括内存映射 mmap、sendfile、sendfile + DMA gather copy 以及 splice 几种机制,并从系统调用和拷贝次数层面对它们进行了对比。接下来从源码着手分析了 Java NIO 对零拷贝的实现,主要包括基于内存映射(mmap)方式的 MappedByteBuffer 以及基于 sendfile 方式的 FileChannel。最后在篇末简单的阐述了一下 Netty 中的零拷贝机制,以及 RocketMQ 和 Kafka 两种消息队列在零拷贝实现方式上的区别。
Linux I/O 原理和 Zero-copy 技术全面揭秘
两万字长文从虚拟内存、I/O 缓冲区,用户态&内核态以及 I/O 模式等等知识点全面而又详尽地剖析 Linux 系统的 I/O 底层原理,分析了 Linux 传统的 I/O 模式的弊端,进而引入 Linux Zero-copy 零拷贝技术的介绍和原理解析,将零拷贝技术和传统的 I/O 模式进行区分和对比,帮助读者理解 Linux 内核对 I/O 模块的优化改进思路。 全网最深度和详尽的 Linux I/O 及零拷贝技术的解析文章导言
如今的网络应用早已从 CPU 密集型转向了 I/O 密集型,网络服务器大多是基于
C-S模型,也即客户端 - 服务端模型,客户端需要和服务端进行大量的网络通信,这也决定了现代网络应用的性能瓶颈:I/O。传统的 Linux 操作系统的标准 I/O 接口是基于数据拷贝操作的,即 I/O 操作会导致数据在操作系统内核地址空间的缓冲区和用户进程地址空间定义的缓冲区之间进行传输。设置缓冲区最大的好处是可以减少磁盘 I/O 的操作,如果所请求的数据已经存放在操作系统的高速缓冲存储器中,那么就不需要再进行实际的物理磁盘 I/O 操作;然而传统的 Linux I/O 在数据传输过程中的数据拷贝操作深度依赖 CPU,也就是说 I/O 过程需要 CPU 去执行数据拷贝的操作,因此导致了极大的系统开销,限制了操作系统有效进行数据传输操作的能力。
I/O 是决定网络服务器性能瓶颈的关键,而传统的 Linux I/O 机制又会导致大量的数据拷贝操作,损耗性能,所以我们亟需一种新的技术来解决数据大量拷贝的问题,这个答案就是零拷贝(Zero-copy)。
计算机存储器
既然要分析 Linux I/O,就不能不了解计算机的各类存储器。
存储器是计算机的核心部件之一,在完全理想的状态下,存储器应该要同时具备以下三种特性:
- 速度足够快:存储器的存取速度应当快于 CPU 执行一条指令,这样 CPU 的效率才不会受限于存储器
- 容量足够大:容量能够存储计算机所需的全部数据
- 价格足够便宜:价格低廉,所有类型的计算机都能配备
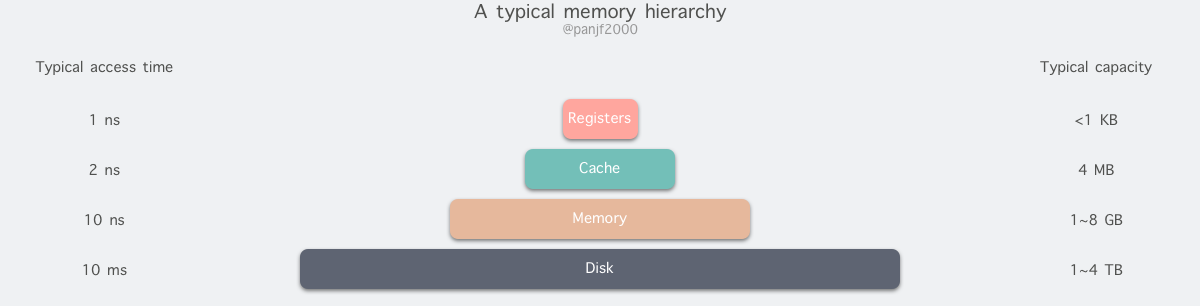
但是现实往往是残酷的,我们目前的计算机技术无法同时满足上述的三个条件,于是现代计算机的存储器设计采用了一种分层次的结构:
从顶至底,现代计算机里的存储器类型分别有:寄存器、高速缓存、主存和磁盘,这些存储器的速度逐级递减而容量逐级递增 。存取速度最快的是寄存器,因为寄存器的制作材料和 CPU 是相同的,所以速度和 CPU 一样快,CPU 访问寄存器是没有时延的,然而因为价格昂贵,因此容量也极小,一般 32 位的 CPU 配备的寄存器容量是 32✖️32 Bit,64 位的 CPU 则是 64✖️64 Bit,不管是 32 位还是 64 位,寄存器容量都小于 1 KB,且寄存器也必须通过软件自行管理。
第二层是高速缓存,也即我们平时了解的 CPU 高速缓存 L1、L2、L3,一般 L1 是每个 CPU 独享,L3 是全部 CPU 共享,而 L2 则根据不同的架构设计会被设计成独享或者共享两种模式之一,比如 Intel 的多核芯片采用的是共享 L2 模式而 AMD 的多核芯片则采用的是独享 L2 模式。
第三层则是主存,也即主内存,通常称作随机访问存储器(Random Access Memory, RAM)。是与 CPU 直接交换数据的内部存储器。它可以随时读写(刷新时除外),而且速度很快,通常作为操作系统或其他正在运行中的程序的临时资料存储介质。
最后则是磁盘,磁盘和主存相比,每个二进制位的成本低了两个数量级,因此容量比之会大得多,动辄上 GB、TB,而问题是访问速度则比主存慢了大概三个数量级。机械硬盘速度慢主要是因为机械臂需要不断在金属盘片之间移动,等待磁盘扇区旋转至磁头之下,然后才能进行读写操作,因此效率很低。
主内存是操作系统进行 I/O 操作的重中之重,绝大部分的工作都是在用户进程和内核的内存缓冲区里完成的,因此我们接下来需要提前学习一些主存的相关原理。
物理内存
我们平时一直提及的物理内存就是上文中对应的第三种计算机存储器,RAM 主存,它在计算机中以内存条的形式存在,嵌在主板的内存槽上,用来加载各式各样的程序与数据以供 CPU 直接运行和使用。
虚拟内存
在计算机领域有一句如同摩西十诫般神圣的哲言:"计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决",从内存管理、网络模型、并发调度甚至是硬件架构,都能看到这句哲言在闪烁着光芒,而虚拟内存则是这一哲言的完美实践之一。
虚拟内存是现代计算机中的一个非常重要的存储器抽象,主要是用来解决应用程序日益增长的内存使用需求:现代物理内存的容量增长已经非常快速了,然而还是跟不上应用程序对主存需求的增长速度,对于应用程序来说内存还是不够用,因此便需要一种方法来解决这两者之间的容量差矛盾。
计算机对多程序内存访问的管理经历了
静态重定位-->动态重定位-->交换(swapping)技术-->虚拟内存,最原始的多程序内存访问是直接访问绝对内存地址,这种方式几乎是完全不可用的方案,因为如果每一个程序都直接访问物理内存地址的话,比如两个程序并发执行以下指令的时候:mov cx, 2 mov bx, 1000H mov ds, bx mov [0], cx ... mov ax, [0] add ax, ax这一段汇编表示在地址 1000:0 处存入数值 2,然后在后面的逻辑中把该地址的值取出来乘以 2,最终存入 ax 寄存器的值就是 4,如果第二个程序存入 cx 寄存器里的值是 3,那么并发执行的时候,第一个程序最终从 ax 寄存器里得到的值就可能是 6,这就完全错误了,得到脏数据还顶多算程序结果错误,要是其他程序往特定的地址里写入一些危险的指令而被另一个程序取出来执行,还可能会导致整个系统的崩溃。所以,为了确保进程间互不干扰,每一个用户进程都需要实时知晓当前其他进程在使用哪些内存地址,这对于写程序的人来说无疑是一场噩梦。
因此,操作绝对内存地址是完全不可行的方案,那就只能用操作相对内存地址,我们知道每个进程都会有自己的进程地址,从 0 开始,可以通过相对地址来访问内存,但是这同样有问题,还是前面类似的问题,比如有两个大小为 16KB 的程序 A 和 B,现在它们都被加载进了内存,内存地址段分别是 0 ~ 16384,16384 ~ 32768。A 的第一条指令是
jmp 1024,而在地址 1024 处是一条mov指令,下一条指令是add,基于前面的mov指令做加法运算,与此同时,B 的第一条指令是jmp 1028,本来在 B 的相对地址 1028 处应该也是一条mov去操作自己的内存地址上的值,但是由于这两个程序共享了段寄存器,因此虽然他们使用了各自的相对地址,但是依然操作的还是绝对内存地址,于是 B 就会跳去执行add指令,这时候就会因为非法的内存操作而 crash。有一种
静态重定位的技术可以解决这个问题,它的工作原理非常简单粗暴:当 B 程序被加载到地址 16384 处之后,把 B 的所有相对内存地址都加上 16384,这样的话当 B 执行jmp 1028之时,其实执行的是jmp 1028+16384,就可以跳转到正确的内存地址处去执行正确的指令了,但是这种技术并不通用,而且还会对程序装载进内存的性能有影响。再往后,就发展出来了存储器抽象:地址空间,就好像进程是 CPU 的抽象,地址空间则是存储器的抽象,每个进程都会分配独享的地址空间,但是独享的地址空间又带来了新的问题:如何实现不同进程的相同相对地址指向不同的物理地址?最开始是使用
动态重定位技术来实现,这是用一种相对简单的地址空间到物理内存的映射方法。基本原理就是为每一个 CPU 配备两个特殊的硬件寄存器:基址寄存器和界限寄存器,用来动态保存每一个程序的起始物理内存地址和长度,比如前文中的 A,B 两个程序,当 A 运行时基址寄存器和界限寄存器就会分别存入 0 和 16384,而当 B 运行时则两个寄存器又会分别存入 16384 和 32768。然后每次访问指定的内存地址时,CPU 会在把地址发往内存总线之前自动把基址寄存器里的值加到该内存地址上,得到一个真正的物理内存地址,同时还会根据界限寄存器里的值检查该地址是否溢出,若是,则产生错误中止程序,动态重定位技术解决了静态重定位技术造成的程序装载速度慢的问题,但是也有新问题:每次访问内存都需要进行加法和比较运算,比较运算本身可以很快,但是加法运算由于进位传递时间的问题,除非使用特殊的电路,否则会比较慢。然后就是
交换(swapping)技术,这种技术简单来说就是动态地把程序在内存和磁盘之间进行交换保存,要运行一个进程的时候就把程序的代码段和数据段调入内存,然后再把程序封存,存入磁盘,如此反复。为什么要这么麻烦?因为前面那两种重定位技术的前提条件是计算机内存足够大,能够把所有要运行的进程地址空间都加载进主存,才能够并发运行这些进程,但是现实往往不是如此,内存的大小总是有限的,所有就需要另一类方法来处理内存超载的情况,第一种便是简单的交换技术:
先把进程 A 换入内存,然后启动进程 B 和 C,也换入内存,接着 A 被从内存交换到磁盘,然后又有新的进程 D 调入内存,用了 A 退出之后空出来的内存空间,最后 A 又被重新换入内存,由于内存布局已经发生了变化,所以 A 在换入内存之时会通过软件或者在运行期间通过硬件(基址寄存器和界限寄存器)对其内存地址进行重定位,多数情况下都是通过硬件。
另一种处理内存超载的技术就是
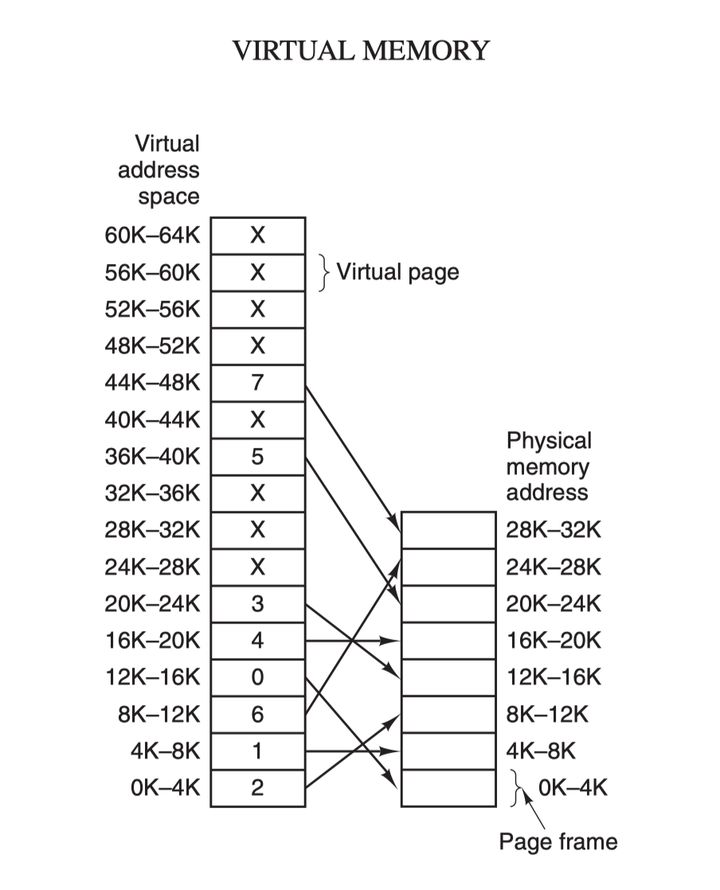
虚拟内存技术了,它比交换(swapping)技术更复杂而又更高效,是目前最新应用最广泛的存储器抽象技术:虚拟内存的核心原理是:为每个程序设置一段"连续"的虚拟地址空间,把这个地址空间分割成多个具有连续地址范围的页 (page),并把这些页和物理内存做映射,在程序运行期间动态映射到物理内存。当程序引用到一段在物理内存的地址空间时,由硬件立刻执行必要的映射;而当程序引用到一段不在物理内存中的地址空间时,由操作系统负责将缺失的部分装入物理内存并重新执行失败的指令:
虚拟地址空间按照固定大小划分成被称为页(page)的若干单元,物理内存中对应的则是页框(page frame)。这两者一般来说是一样的大小,如上图中的是 4KB,不过实际上计算机系统中一般是 512 字节到 1 GB,这就是虚拟内存的分页技术。因为是虚拟内存空间,每个进程分配的大小是 4GB (32 位架构),而实际上当然不可能给所有在运行中的进程都分配 4GB 的物理内存,所以虚拟内存技术还需要利用到前面介绍的
交换(swapping)技术,在进程运行期间只分配映射当前使用到的内存,暂时不使用的数据则写回磁盘作为副本保存,需要用的时候再读入内存,动态地在磁盘和内存之间交换数据。其实虚拟内存技术从某种角度来看的话,很像是糅合了基址寄存器和界限寄存器之后的新技术。它使得整个进程的地址空间可以通过较小的单元映射到物理内存,而不需要为程序的代码和数据地址进行重定位。
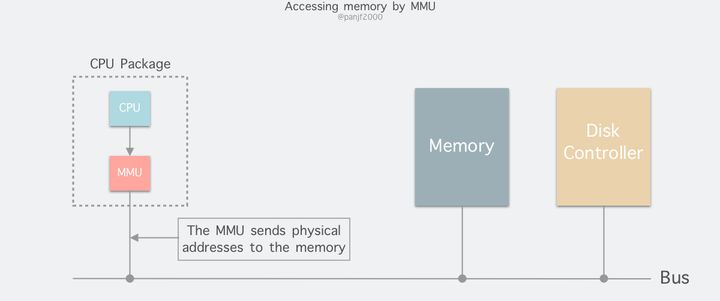
进程在运行期间产生的内存地址都是虚拟地址,如果计算机没有引入虚拟内存这种存储器抽象技术的话,则 CPU 会把这些地址直接发送到内存地址总线上,直接访问和虚拟地址相同值的物理地址;如果使用虚拟内存技术的话,CPU 则是把这些虚拟地址通过地址总线送到内存管理单元(Memory Management Unit,MMU),MMU 将虚拟地址映射为物理地址之后再通过内存总线去访问物理内存:
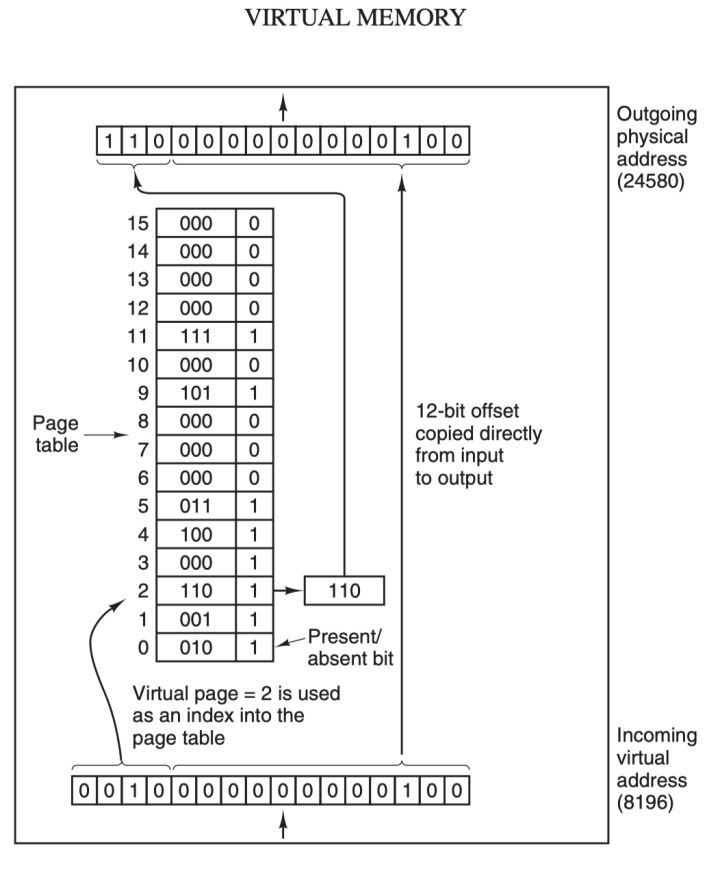
虚拟地址(比如 16 位地址 8196=0010 000000000100)分为两部分:虚拟页号(高位部分)和偏移量(低位部分),虚拟地址转换成物理地址是通过页表(page table)来实现的,页表由页表项构成,页表项中保存了页框号、修改位、访问位、保护位和 "在/不在" 位等信息,从数学角度来说页表就是一个函数,入参是虚拟页号,输出是物理页框号,得到物理页框号之后复制到寄存器的高三位中,最后直接把 12 位的偏移量复制到寄存器的末 12 位构成 15 位的物理地址,即可以把该寄存器的存储的物理内存地址发送到内存总线:
在 MMU 进行地址转换时,如果页表项的 "在/不在" 位是 0,则表示该页面并没有映射到真实的物理页框,则会引发一个缺页中断,CPU 陷入操作系统内核,接着操作系统就会通过页面置换算法选择一个页面将其换出 (swap),以便为即将调入的新页面腾出位置,如果要换出的页面的页表项里的修改位已经被设置过,也就是被更新过,则这是一个脏页 (dirty page),需要写回磁盘更新改页面在磁盘上的副本,如果该页面是"干净"的,也就是没有被修改过,则直接用调入的新页面覆盖掉被换出的旧页面即可。
最后,还需要了解的一个概念是转换检测缓冲器(Translation Lookaside Buffer,TLB),也叫快表,是用来加速虚拟地址映射的,因为虚拟内存的分页机制,页表一般是保存内存中的一块固定的存储区,导致进程通过 MMU 访问内存比直接访问内存多了一次内存访问,性能至少下降一半,因此需要引入加速机制,即 TLB 快表,TLB 可以简单地理解成页表的高速缓存,保存了最高频被访问的页表项,由于一般是硬件实现的,因此速度极快,MMU 收到虚拟地址时一般会先通过硬件 TLB 查询对应的页表号,若命中且该页表项的访问操作合法,则直接从 TLB 取出对应的物理页框号返回,若不命中则穿透到内存页表里查询,并且会用这个从内存页表里查询到最新页表项替换到现有 TLB 里的其中一个,以备下次缓存命中。
至此,我们介绍完了包含虚拟内存在内的多项计算机存储器抽象技术,虚拟内存的其他内容比如针对大内存的多级页表、倒排页表,以及处理缺页中断的页面置换算法等等,以后有机会再单独写一篇文章介绍,或者各位读者也可以先行去查阅相关资料了解,这里就不再深入了。
用户态和内核态
一般来说,我们在编写程序操作 Linux I/O 之时十有八九是在用户空间和内核空间之间传输数据,因此有必要先了解一下 Linux 的用户态和内核态的概念。
首先是用户态和内核态:
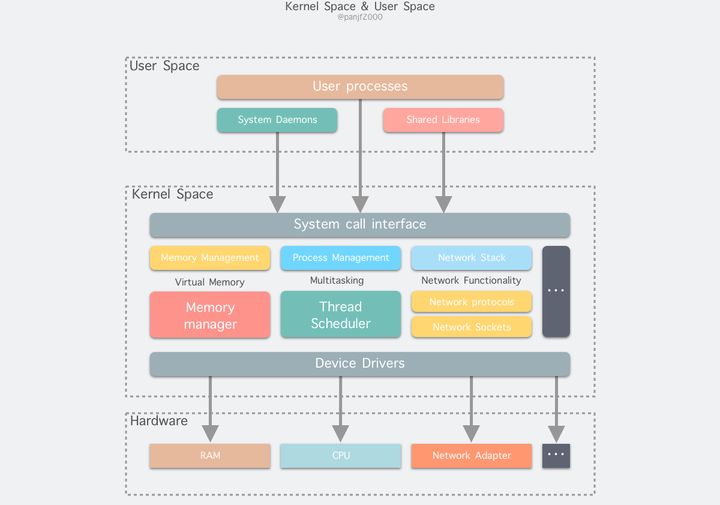
从宏观上来看,Linux 操作系统的体系架构分为用户态和内核态(或者用户空间和内核)。内核从本质上看是一种软件 —— 控制计算机的硬件资源,并提供上层应用程序 (进程) 运行的环境。用户态即上层应用程序 (进程) 的运行空间,应用程序 (进程) 的执行必须依托于内核提供的资源,这其中包括但不限于 CPU 资源、存储资源、I/O 资源等等。
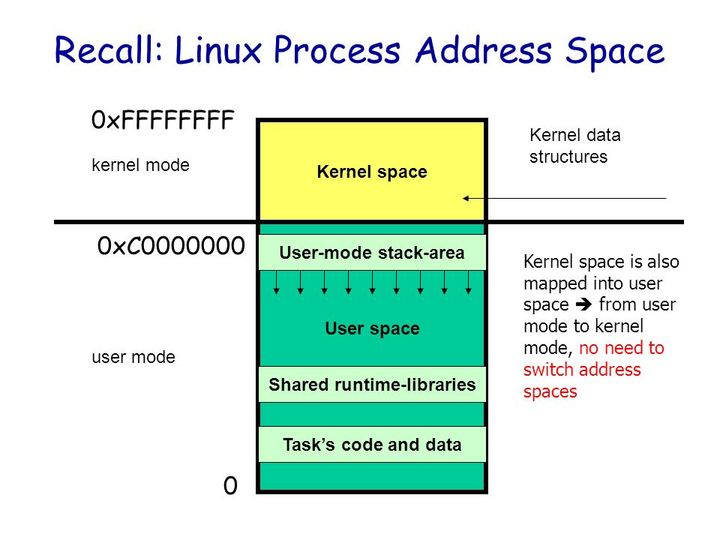
现代操作系统都是采用虚拟存储器,那么对 32 位操作系统而言,它的寻址空间(虚拟存储空间)为 2^32 B = 4G。操作系统的核心是内核,独立于普通的应用程序,可以访问受保护的内存空间,也有访问底层硬件设备的所有权限。为了保证用户进程不能直接操作内核(kernel),保证内核的安全,操心系统将虚拟空间划分为两部分,一部分为内核空间,一部分为用户空间。针对 Linux 操作系统而言,将最高的 1G 字节(从虚拟地址 0xC0000000 到 0xFFFFFFFF),供内核使用,称为内核空间,而将较低的 3G 字节(从虚拟地址 0x00000000 到 0xBFFFFFFF),供各个进程使用,称为用户空间。
因为操作系统的资源是有限的,如果访问资源的操作过多,必然会消耗过多的系统资源,而且如果不对这些操作加以区分,很可能造成资源访问的冲突。所以,为了减少有限资源的访问和使用冲突,Unix/Linux 的设计哲学之一就是:对不同的操作赋予不同的执行等级,就是所谓特权的概念。简单说就是有多大能力做多大的事,与系统相关的一些特别关键的操作必须由最高特权的程序来完成。Intel 的 x86 架构的 CPU 提供了 0 到 3 四个特权级,数字越小,特权越高,Linux 操作系统中主要采用了 0 和 3 两个特权级,分别对应的就是内核态和用户态。运行于用户态的进程可以执行的操作和访问的资源都会受到极大的限制,而运行在内核态的进程则可以执行任何操作并且在资源的使用上没有限制。很多程序开始时运行于用户态,但在执行的过程中,一些操作需要在内核权限下才能执行,这就涉及到一个从用户态切换到内核态的过程。比如 C 函数库中的内存分配函数 malloc(),它具体是使用 sbrk() 系统调用来分配内存,当 malloc 调用 sbrk() 的时候就涉及一次从用户态到内核态的切换,类似的函数还有 printf(),调用的是 wirte() 系统调用来输出字符串,等等。
用户进程在系统中运行时,大部分时间是处在用户态空间里的,在其需要操作系统帮助完成一些用户态没有特权和能力完成的操作时就需要切换到内核态。那么用户进程如何切换到内核态去使用那些内核资源呢?答案是:1) 系统调用(trap),2) 异常(exception)和 3) 中断(interrupt)。
- 系统调用:用户进程主动发起的操作。用户态进程发起系统调用主动要求切换到内核态,陷入内核之后,由操作系统来操作系统资源,完成之后再返回到进程。
- 异常:被动的操作,且用户进程无法预测其发生的时机。当用户进程在运行期间发生了异常(比如某条指令出了问题),这时会触发由当前运行进程切换到处理此异常的内核相关进程中,也即是切换到了内核态。异常包括程序运算引起的各种错误如除 0、缓冲区溢出、缺页等。
- 中断:当外围设备完成用户请求的操作后,会向 CPU 发出相应的中断信号,这时 CPU 会暂停执行下一条即将要执行的指令而转到与中断信号对应的处理程序去执行,如果前面执行的指令是用户态下的程序,那么转换的过程自然就会是从用户态到内核态的切换。中断包括 I/O 中断、外部信号中断、各种定时器引起的时钟中断等。中断和异常类似,都是通过中断向量表来找到相应的处理程序进行处理。区别在于,中断来自处理器外部,不是由任何一条专门的指令造成,而异常是执行当前指令的结果。
通过上面的分析,我们可以得出 Linux 的内部层级可分为三大部分:
- 用户空间;
- 内核空间;
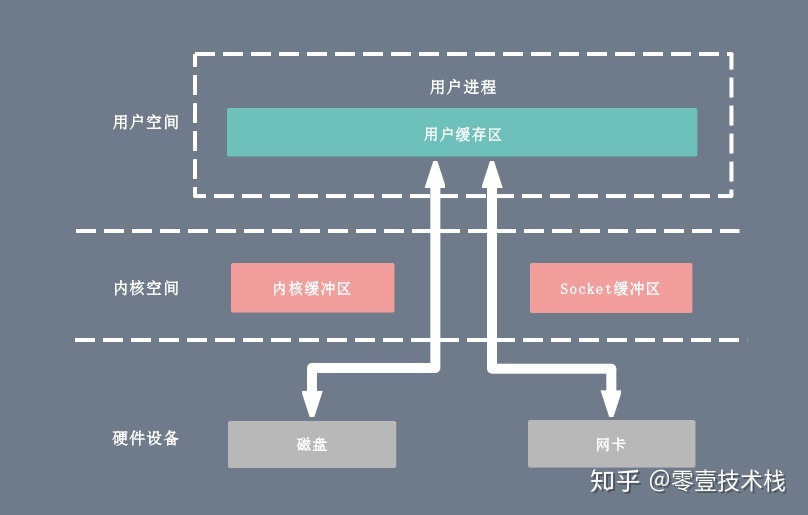
- 硬件。
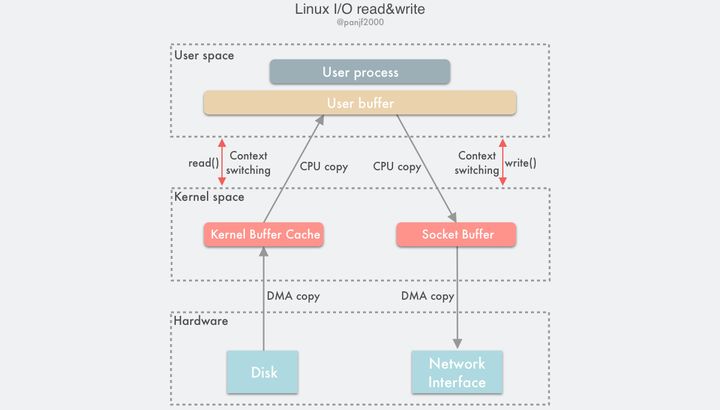
Linux I/O
I/O 缓冲区
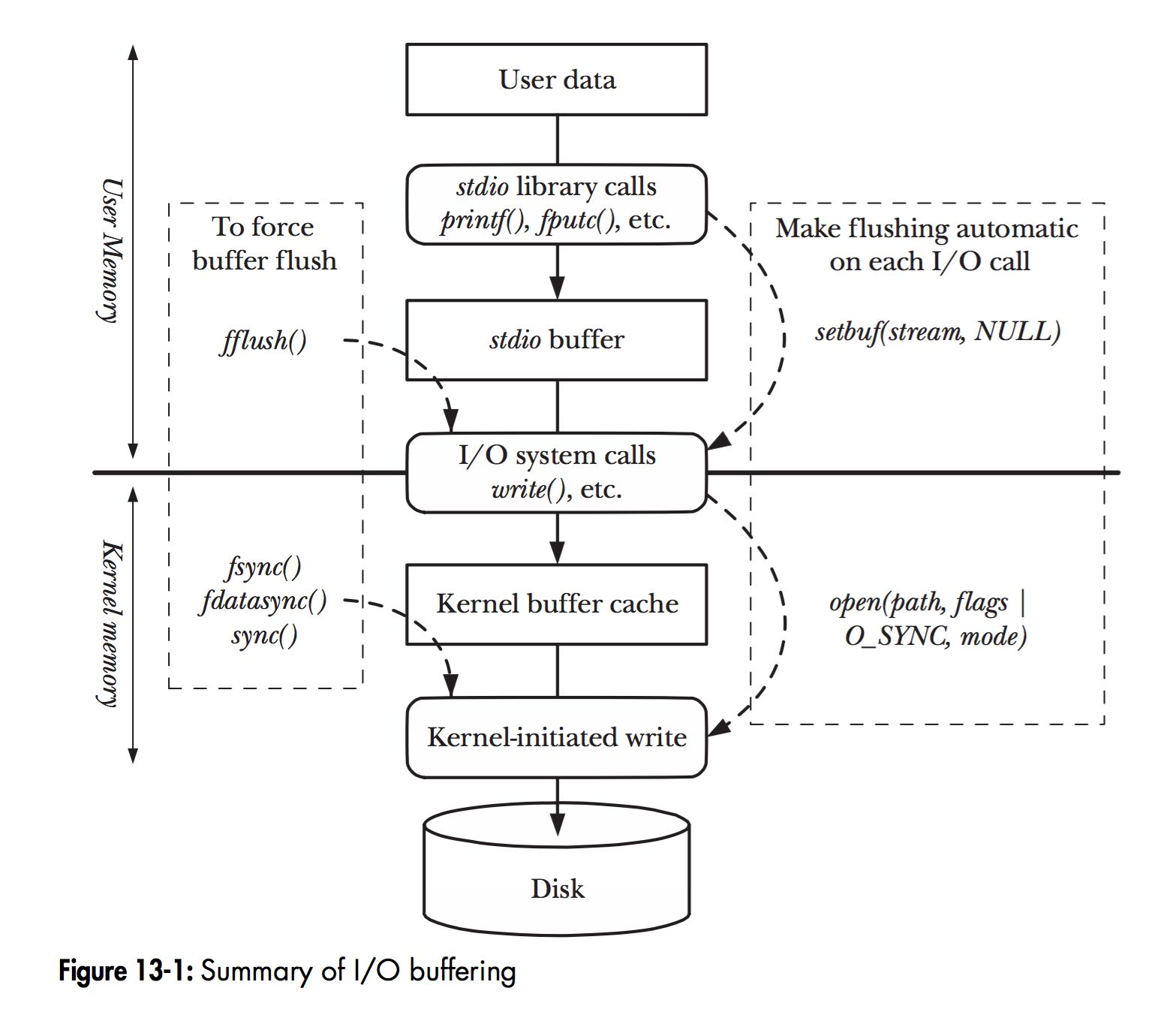
在 Linux 中,当程序调用各类文件操作函数后,用户数据(User Data)到达磁盘(Disk)的流程如上图所示。
图中描述了 Linux 中文件操作函数的层级关系和内存缓存层的存在位置,中间的黑色实线是用户态和内核态的分界线。
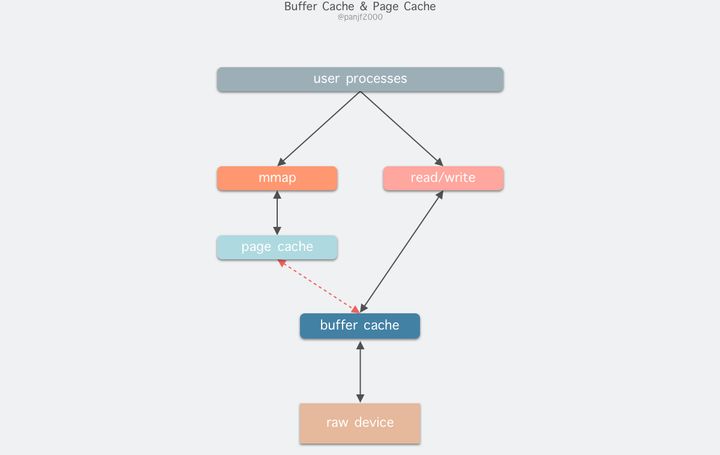
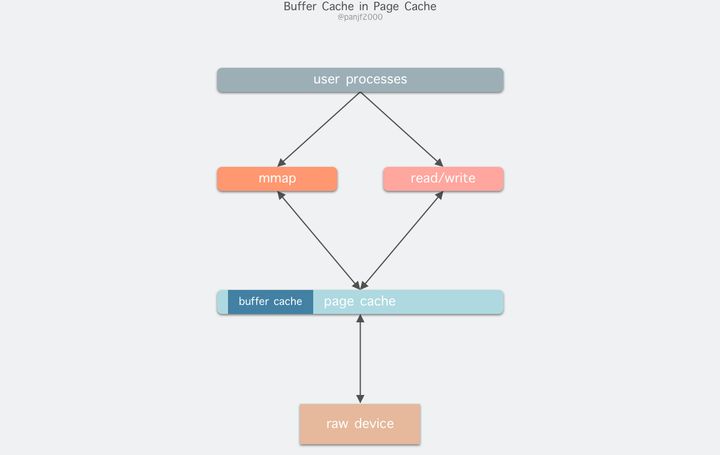
read(2)/write(2)是 Linux 系统中最基本的 I/O 读写系统调用,我们开发操作 I/O 的程序时必定会接触到它们,而在这两个系统调用和真实的磁盘读写之间存在一层称为Kernel buffer cache的缓冲区缓存。在 Linux 中 I/O 缓存其实可以细分为两个:Page Cache和Buffer Cache,这两个其实是一体两面,共同组成了 Linux 的内核缓冲区(Kernel Buffer Cache):
- 读磁盘:内核会先检查
Page Cache里是不是已经缓存了这个数据,若是,直接从这个内存缓冲区里读取返回,若否,则穿透到磁盘去读取,然后再缓存在Page Cache里,以备下次缓存命中;- 写磁盘:内核直接把数据写入
Page Cache,并把对应的页标记为 dirty,添加到 dirty list 里,然后就直接返回,内核会定期把 dirty list 的页缓存 flush 到磁盘,保证页缓存和磁盘的最终一致性。
Page Cache会通过页面置换算法如 LRU 定期淘汰旧的页面,加载新的页面。可以看出,所谓 I/O 缓冲区缓存就是在内核和磁盘、网卡等外设之间的一层缓冲区,用来提升读写性能的。在 Linux 还不支持虚拟内存技术之前,还没有页的概念,因此
Buffer Cache是基于操作系统读写磁盘的最小单位 -- 块(block)来进行的,所有的磁盘块操作都是通过Buffer Cache来加速,Linux 引入虚拟内存的机制来管理内存后,页成为虚拟内存管理的最小单位,因此也引入了Page Cache来缓存 Linux 文件内容,主要用来作为文件系统上的文件数据的缓存,提升读写性能,常见的是针对文件的read()/write()操作,另外也包括了通过mmap()映射之后的块设备,也就是说,事实上 Page Cache 负责了大部分的块设备文件的缓存工作。而Buffer Cache用来在系统对块设备进行读写的时候,对块进行数据缓存的系统来使用,实际上负责所有对磁盘的 I/O 访问:
因为
Buffer Cache是对粒度更细的设备块的缓存,而Page Cache是基于虚拟内存的页单元缓存,因此还是会基于Buffer Cache,也就是说如果是缓存文件内容数据就会在内存里缓存两份相同的数据,这就会导致同一份文件保存了两份,冗余且低效。另外一个问题是,调用write后,有效数据是在Buffer Cache中,而非Page Cache中。这就导致mmap访问的文件数据可能存在不一致问题。为了规避这个问题,所有基于磁盘文件系统的write,都需要调用update_vm_cache()函数,该操作会把调用write之后的Buffer Cache更新到Page Cache去。由于有这些设计上的弊端,因此在 Linux 2.4 版本之后,kernel 就将两者进行了统一,Buffer Cache不再以独立的形式存在,而是以融合的方式存在于Page Cache中:
融合之后就可以统一操作
Page Cache和Buffer Cache:处理文件 I/O 缓存交给Page Cache,而当底层 RAW device 刷新数据时以Buffer Cache的块单位来实际处理。I/O 模式
在 Linux 或者其他 Unix-like 操作系统里,I/O 模式一般有三种:
- 程序控制 I/O
- 中断驱动 I/O
- DMA I/O
下面我分别详细地讲解一下这三种 I/O 模式。
程序控制 I/O
这是最简单的一种 I/O 模式,也叫忙等待或者轮询:用户通过发起一个系统调用,陷入内核态,内核将系统调用翻译成一个对应设备驱动程序的过程调用,接着设备驱动程序会启动 I/O 不断循环去检查该设备,看看是否已经就绪,一般通过返回码来表示,I/O 结束之后,设备驱动程序会把数据送到指定的地方并返回,切回用户态。
比如发起系统调用
read():
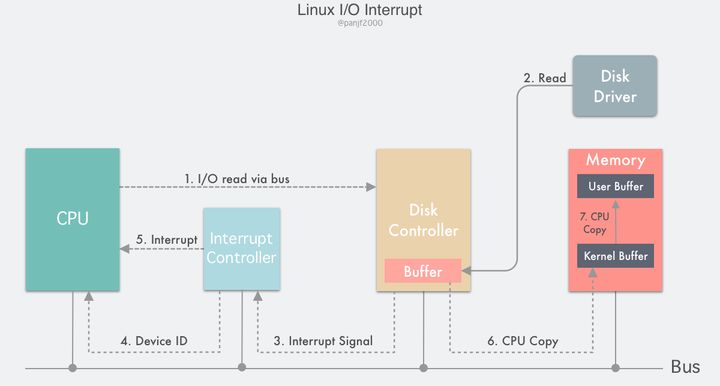
中断驱动 I/O
第二种 I/O 模式是利用中断来实现的:
流程如下:
- 用户进程发起一个
read()系统调用读取磁盘文件,陷入内核态并由其所在的 CPU 通过设备驱动程序向设备寄存器写入一个通知信号,告知设备控制器 (我们这里是磁盘控制器)要读取数据;- 磁盘控制器启动磁盘读取的过程,把数据从磁盘拷贝到磁盘控制器缓冲区里;
- 完成拷贝之后磁盘控制器会通过总线发送一个中断信号到中断控制器,如果此时中断控制器手头还有正在处理的中断或者有一个和该中断信号同时到达的更高优先级的中断,则这个中断信号将被忽略,而磁盘控制器会在后面持续发送中断信号直至中断控制器受理;
- 中断控制器收到磁盘控制器的中断信号之后会通过地址总线存入一个磁盘设备的编号,表示这次中断需要关注的设备是磁盘;
- 中断控制器向 CPU 置起一个磁盘中断信号;
- CPU 收到中断信号之后停止当前的工作,把当前的 PC/PSW 等寄存器压入堆栈保存现场,然后从地址总线取出设备编号,通过编号找到中断向量所包含的中断服务的入口地址,压入 PC 寄存器,开始运行磁盘中断服务,把数据从磁盘控制器的缓冲区拷贝到主存里的内核缓冲区;
- 最后 CPU 再把数据从内核缓冲区拷贝到用户缓冲区,完成读取操作,
read()返回,切换回用户态。DMA I/O
并发系统的性能高低究其根本,是取决于如何对 CPU 资源的高效调度和使用,而回头看前面的中断驱动 I/O 模式的流程,可以发现第 6、7 步的数据拷贝工作都是由 CPU 亲自完成的,也就是在这两次数据拷贝阶段中 CPU 是完全被占用而不能处理其他工作的,那么这里明显是有优化空间的;第 7 步的数据拷贝是从内核缓冲区到用户缓冲区,都是在主存里,所以这一步只能由 CPU 亲自完成,但是第 6 步的数据拷贝,是从磁盘控制器的缓冲区到主存,是两个设备之间的数据传输,这一步并非一定要 CPU 来完成,可以借助 DMA 来完成,减轻 CPU 的负担。
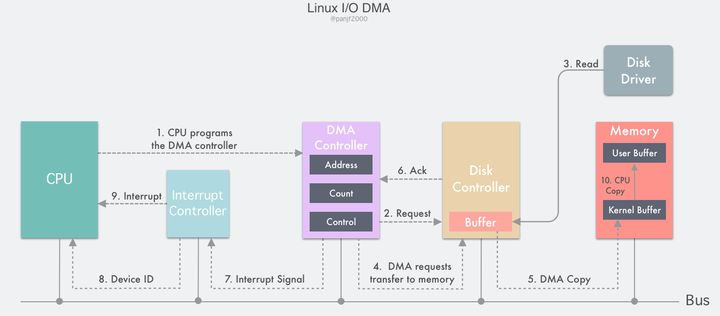
DMA 全称是 Direct Memory Access,也即直接存储器存取,是一种用来提供在外设和存储器之间或者存储器和存储器之间的高速数据传输。整个过程无须 CPU 参与,数据直接通过 DMA 控制器进行快速地移动拷贝,节省 CPU 的资源去做其他工作。
目前,大部分的计算机都配备了 DMA 控制器,而 DMA 技术也支持大部分的外设和存储器。借助于 DMA 机制,计算机的 I/O 过程就能更加高效:
DMA 控制器内部包含若干个可以被 CPU 读写的寄存器:一个主存地址寄存器 MAR(存放要交换数据的主存地址)、一个外设地址寄存器 ADR(存放 I/O 设备的设备码,或者是设备信息存储区的寻址信息)、一个字节数寄存器 WC(对传送数据的总字数进行统计)、和一个或多个控制寄存器。
- 用户进程发起一个
read()系统调用读取磁盘文件,陷入内核态并由其所在的 CPU 通过设置 DMA 控制器的寄存器对它进行编程:把内核缓冲区和磁盘文件的地址分别写入 MAR 和 ADR 寄存器,然后把期望读取的字节数写入 WC 寄存器,启动 DMA 控制器;- DMA 控制器根据 ADR 寄存器里的信息知道这次 I/O 需要读取的外设是磁盘的某个地址,便向磁盘控制器发出一个命令,通知它从磁盘读取数据到其内部的缓冲区里;
- 磁盘控制器启动磁盘读取的过程,把数据从磁盘拷贝到磁盘控制器缓冲区里,并对缓冲区内数据的校验和进行检验,如果数据是有效的,那么 DMA 就可以开始了;
- DMA 控制器通过总线向磁盘控制器发出一个读请求信号从而发起 DMA 传输,这个信号和前面的中断驱动 I/O 小节里 CPU 发给磁盘控制器的读请求是一样的,它并不知道或者并不关心这个读请求是来自 CPU 还是 DMA 控制器;
- 紧接着 DMA 控制器将引导磁盘控制器将数据传输到 MAR 寄存器里的地址,也就是内核缓冲区;
- 数据传输完成之后,返回一个 ack 给 DMA 控制器,WC 寄存器里的值会减去相应的数据长度,如果 WC 还不为 0,则重复第 4 步到第 6 步,一直到 WC 里的字节数等于 0;
- 收到 ack 信号的 DMA 控制器会通过总线发送一个中断信号到中断控制器,如果此时中断控制器手头还有正在处理的中断或者有一个和该中断信号同时到达的更高优先级的中断,则这个中断信号将被忽略,而 DMA 控制器会在后面持续发送中断信号直至中断控制器受理;
- 中断控制器收到磁盘控制器的中断信号之后会通过地址总线存入一个主存设备的编号,表示这次中断需要关注的设备是主存;
- 中断控制器向 CPU 置起一个 DMA 中断的信号;
- CPU 收到中断信号之后停止当前的工作,把当前的 PC/PSW 等寄存器压入堆栈保存现场,然后从地址总线取出设备编号,通过编号找到中断向量所包含的中断服务的入口地址,压入 PC 寄存器,开始运行 DMA 中断服务,把数据从内核缓冲区拷贝到用户缓冲区,完成读取操作,
read()返回,切换回用户态。传统 I/O 读写模式
Linux 中传统的 I/O 读写是通过
read()/write()系统调用完成的,read()把数据从存储器 (磁盘、网卡等) 读取到用户缓冲区,write()则是把数据从用户缓冲区写出到存储器:#include ssize_t read(int fd, void *buf, size_t count); ssize_t write(int fd, const void *buf, size_t count);一次完整的读磁盘文件然后写出到网卡的底层传输过程如下:
可以清楚看到这里一共触发了 4 次用户态和内核态的上下文切换,分别是
read()/write()调用和返回时的切换,2 次 DMA 拷贝,2 次 CPU 拷贝,加起来一共 4 次拷贝操作。通过引入 DMA,我们已经把 Linux 的 I/O 过程中的 CPU 拷贝次数从 4 次减少到了 2 次,但是 CPU 拷贝依然是代价很大的操作,对系统性能的影响还是很大,特别是那些频繁 I/O 的场景,更是会因为 CPU 拷贝而损失掉很多性能,我们需要进一步优化,降低、甚至是完全避免 CPU 拷贝。
零拷贝 (Zero-copy)
Zero-copy 是什么?
Wikipedia 的解释如下:
"Zero-copy" describes computer operations in which the CPU does not perform the task of copying data from one memory area to another. This is frequently used to save CPU cycles and memory bandwidth when transmitting a file over a network.零拷贝技术是指计算机执行操作时,CPU不需要先将数据从某处内存复制到另一个特定区域。这种技术通常用于通过网络传输文件时节省 CPU 周期和内存带宽。
Zero-copy 能做什么?
- 减少甚至完全避免操作系统内核和用户应用程序地址空间这两者之间进行数据拷贝操作,从而减少用户态 -- 内核态上下文切换带来的系统开销。
- 减少甚至完全避免操作系统内核缓冲区之间进行数据拷贝操作。
- 帮助用户进程绕开操作系统内核空间直接访问硬件存储接口操作数据。
- 利用 DMA 而非 CPU 来完成硬件接口和内核缓冲区之间的数据拷贝,从而解放 CPU,使之能去执行其他的任务,提升系统性能。
Zero-copy 的实现方式有哪些?
从 zero-copy 这个概念被提出以来,相关的实现技术便犹如雨后春笋,层出不穷。但是截至目前为止,并没有任何一种 zero-copy 技术能满足所有的场景需求,还是计算机领域那句无比经典的名言:"There is no silver bullet"!
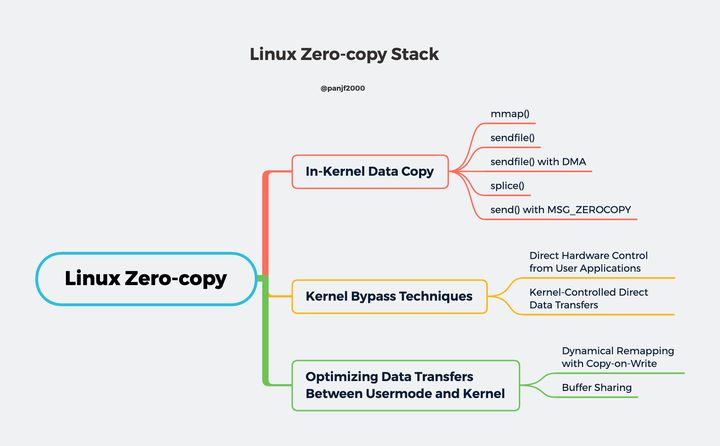
而在 Linux 平台上,同样也有很多的 zero-copy 技术,新旧各不同,可能存在于不同的内核版本里,很多技术可能有了很大的改进或者被更新的实现方式所替代,这些不同的实现技术按照其核心思想可以归纳成大致的以下三类:
- 减少甚至避免用户空间和内核空间之间的数据拷贝:在一些场景下,用户进程在数据传输过程中并不需要对数据进行访问和处理,那么数据在 Linux 的
Page Cache和用户进程的缓冲区之间的传输就完全可以避免,让数据拷贝完全在内核里进行,甚至可以通过更巧妙的方式避免在内核里的数据拷贝。这一类实现一般是通过增加新的系统调用来完成的,比如 Linux 中的 mmap(),sendfile() 以及 splice() 等。- 绕过内核的直接 I/O:允许在用户态进程绕过内核直接和硬件进行数据传输,内核在传输过程中只负责一些管理和辅助的工作。这种方式其实和第一种有点类似,也是试图避免用户空间和内核空间之间的数据传输,只是第一种方式是把数据传输过程放在内核态完成,而这种方式则是直接绕过内核和硬件通信,效果类似但原理完全不同。
- 内核缓冲区和用户缓冲区之间的传输优化:这种方式侧重于在用户进程的缓冲区和操作系统的页缓存之间的 CPU 拷贝的优化。这种方法延续了以往那种传统的通信方式,但更灵活。
减少甚至避免用户空间和内核空间之间的数据拷贝
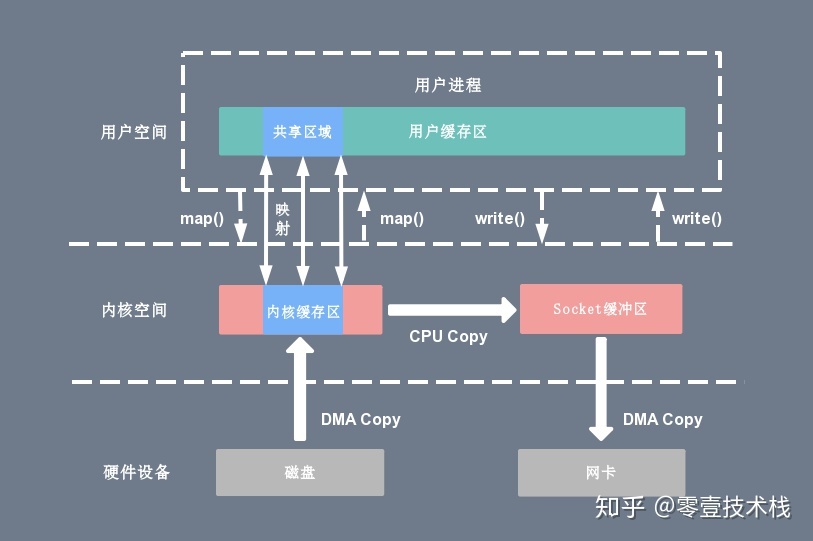
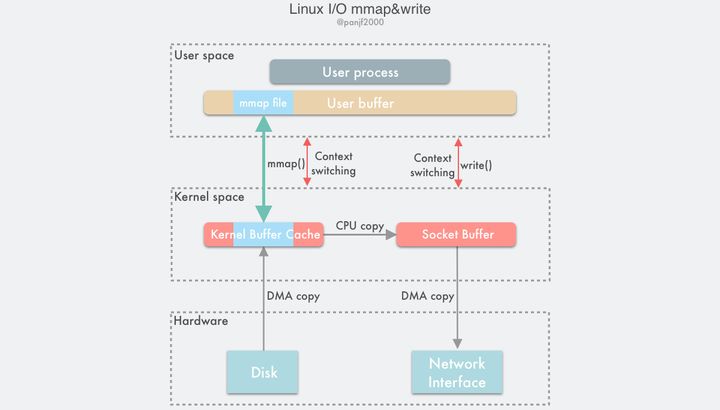
mmap()
#include <sys/mman.h> void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset); int munmap(void *addr, size_t length);一种简单的实现方案是在一次读写过程中用 Linux 的另一个系统调用
mmap()替换原先的read(),mmap()也即是内存映射(memory map):把用户进程空间的一段内存缓冲区(user buffer)映射到文件所在的内核缓冲区(kernel buffer)上。
利用
mmap()替换read(),配合write()调用的整个流程如下:
- 用户进程调用
mmap(),从用户态陷入内核态,将内核缓冲区映射到用户缓存区;- DMA 控制器将数据从硬盘拷贝到内核缓冲区;
mmap()返回,上下文从内核态切换回用户态;- 用户进程调用
write(),尝试把文件数据写到内核里的套接字缓冲区,再次陷入内核态;- CPU 将内核缓冲区中的数据拷贝到的套接字缓冲区;
- DMA 控制器将数据从套接字缓冲区拷贝到网卡完成数据传输;
write()返回,上下文从内核态切换回用户态。通过这种方式,有两个优点:一是节省内存空间,因为用户进程上的这一段内存是虚拟的,并不真正占据物理内存,只是映射到文件所在的内核缓冲区上,因此可以节省一半的内存占用;二是省去了一次 CPU 拷贝,对比传统的 Linux I/O 读写,数据不需要再经过用户进程进行转发了,而是直接在内核里就完成了拷贝。所以使用
mmap()之后的拷贝次数是 2 次 DMA 拷贝,1 次 CPU 拷贝,加起来一共 3 次拷贝操作,比传统的 I/O 方式节省了一次 CPU 拷贝以及一半的内存,不过因为mmap()也是一个系统调用,因此用户态和内核态的切换还是 4 次。
mmap()因为既节省 CPU 拷贝次数又节省内存,所以比较适合大文件传输的场景。虽然mmap()完全是符合 POSIX 标准的,但是它也不是完美的,因为它并不总是能达到理想的数据传输性能。首先是因为数据数据传输过程中依然需要一次 CPU 拷贝,其次是内存映射技术是一个开销很大的虚拟存储操作:这种操作需要修改页表以及用内核缓冲区里的文件数据汰换掉当前 TLB 里的缓存以维持虚拟内存映射的一致性。但是,因为内存映射通常针对的是相对较大的数据区域,所以对于相同大小的数据来说,内存映射所带来的开销远远低于 CPU 拷贝所带来的开销。此外,使用mmap()还可能会遇到一些需要值得关注的特殊情况,例如,在mmap()-->write()这两个系统调用的整个传输过程中,如果有其他的进程突然截断了这个文件,那么这时用户进程就会因为访问非法地址而被一个从总线传来的 SIGBUS 中断信号杀死并且产生一个 core dump。有两种解决办法:
- 设置一个信号处理器,专门用来处理 SIGBUS 信号,这个处理器直接返回,
write()就可以正常返回已写入的字节数而不会被 SIGBUS 中断,errno 错误码也会被设置成 success。然而这实际上是一个掩耳盗铃的解决方案,因为 BIGBUS 信号的带来的信息是系统发生了一些很严重的错误,而我们却选择忽略掉它,一般不建议采用这种方式。- 通过内核的文件租借锁(这是 Linux 的叫法,Windows 上称之为机会锁)来解决这个问题,这种方法相对来说更好一些。我们可以通过内核对文件描述符上读/写的租借锁,当另外一个进程尝试对当前用户进程正在进行传输的文件进行截断的时候,内核会发送给用户一个实时信号:RT_SIGNAL_LEASE 信号,这个信号会告诉用户内核正在破坏你加在那个文件上的读/写租借锁,这时
write()系统调用会被中断,并且当前用户进程会被 SIGBUS 信号杀死,返回值则是中断前写的字节数,errno 同样会被设置为 success。文件租借锁需要在对文件进行内存映射之前设置,最后在用户进程结束之前释放掉。sendfile()
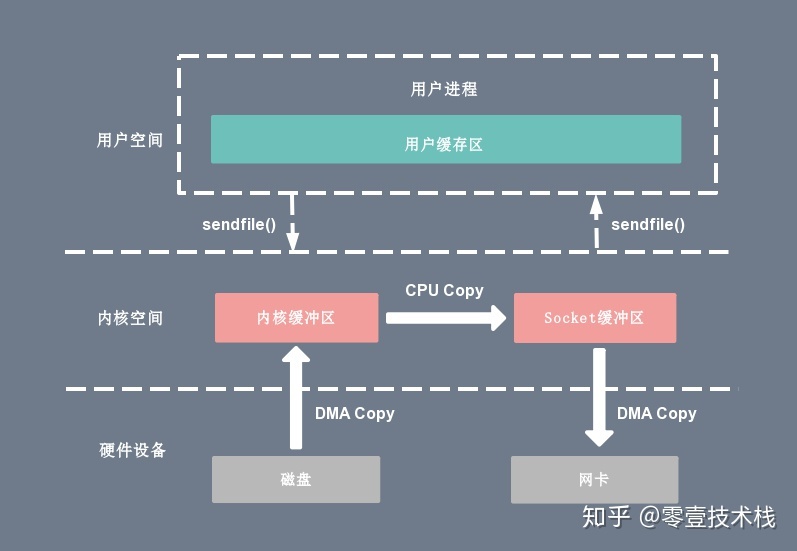
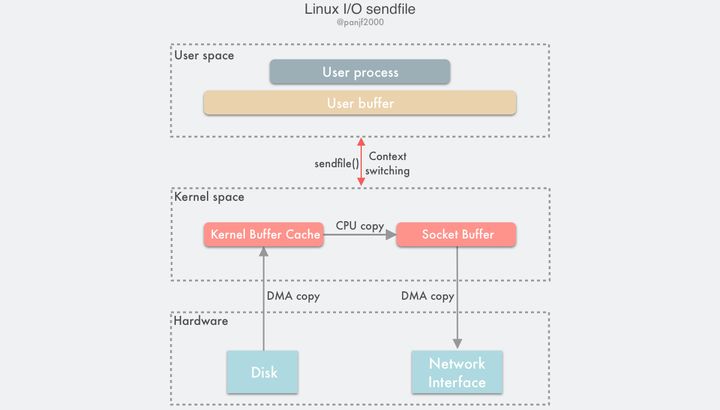
在 Linux 内核 2.1 版本中,引入了一个新的系统调用
sendfile():#include <sys/sendfile.h> ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);从功能上来看,这个系统调用将
mmap()+write()这两个系统调用合二为一,实现了一样效果的同时还简化了用户接口,其他的一些 Unix-like 的系统像 BSD、Solaris 和 AIX 等也有类似的实现,甚至 Windows 上也有一个功能类似的 API 函数TransmitFile。out_fd 和 in_fd 分别代表了写入和读出的文件描述符,in_fd 必须是一个指向文件的文件描述符,且要能支持类
mmap()内存映射,不能是 Socket 类型,而 out_fd 在 Linux 内核 2.6.33 版本之前只能是一个指向 Socket 的文件描述符,从 2.6.33 之后则可以是任意类型的文件描述符。off_t 是一个代表了 in_fd 偏移量的指针,指示sendfile()该从 in_fd 的哪个位置开始读取,函数返回后,这个指针会被更新成sendfile()最后读取的字节位置处,表明此次调用共读取了多少文件数据,最后的 count 参数则是此次调用需要传输的字节总数。
使用
sendfile()完成一次数据读写的流程如下:
- 用户进程调用
sendfile()从用户态陷入内核态;- DMA 控制器将数据从硬盘拷贝到内核缓冲区;
- CPU 将内核缓冲区中的数据拷贝到套接字缓冲区;
- DMA 控制器将数据从套接字缓冲区拷贝到网卡完成数据传输;
sendfile()返回,上下文从内核态切换回用户态。基于
sendfile(), 整个数据传输过程中共发生 2 次 DMA 拷贝和 1 次 CPU 拷贝,这个和mmap()+write()相同,但是因为sendfile()只是一次系统调用,因此比前者少了一次用户态和内核态的上下文切换开销。读到这里,聪明的读者应该会开始提问了:"sendfile()会不会遇到和mmap()+write()相似的文件截断问题呢?",很不幸,答案是肯定的。sendfile()一样会有文件截断的问题,但欣慰的是,sendfile()不仅比mmap()+write()在接口使用上更加简洁,而且处理文件截断时也更加优雅:如果sendfile()过程中遭遇文件截断,则sendfile()系统调用会被中断杀死之前返回给用户进程其中断前所传输的字节数,errno 会被设置为 success,无需用户提前设置信号处理器,当然你要设置一个进行个性化处理也可以,也不需要像之前那样提前给文件描述符设置一个租借锁,因为最终结果还是一样的。
sendfile()相较于mmap()的另一个优势在于数据在传输过程中始终没有越过用户态和内核态的边界,因此极大地减少了存储管理的开销。即便如此,sendfile()依然是一个适用性很窄的技术,最适合的场景基本也就是一个静态文件服务器了。而且根据 Linus 在 2001 年和其他内核维护者的邮件列表内容,其实当初之所以决定在 Linux 上实现sendfile()仅仅是因为在其他操作系统平台上已经率先实现了,而且有大名鼎鼎的 Apache Web 服务器已经在使用了,为了兼容 Apache Web 服务器才决定在 Linux 上也实现这个技术,而且sendfile()实现上的简洁性也和 Linux 内核的其他部分集成得很好,所以 Linus 也就同意了这个提案。然而
sendfile()本身是有很大问题的,从不同的角度来看的话主要是:
- 首先一个是这个接口并没有进行标准化,导致
sendfile()在 Linux 上的接口实现和其他类 Unix 系统的实现并不相同;- 其次由于网络传输的异步性,很难在接收端实现和
sendfile()对接的技术,因此接收端一直没有实现对应的这种技术;- 最后从性能方面考量,因为
sendfile()在把磁盘文件从内核缓冲区(page cache)传输到到套接字缓冲区的过程中依然需要 CPU 参与,这就很难避免 CPU 的高速缓存被传输的数据所污染。此外,需要说明下,
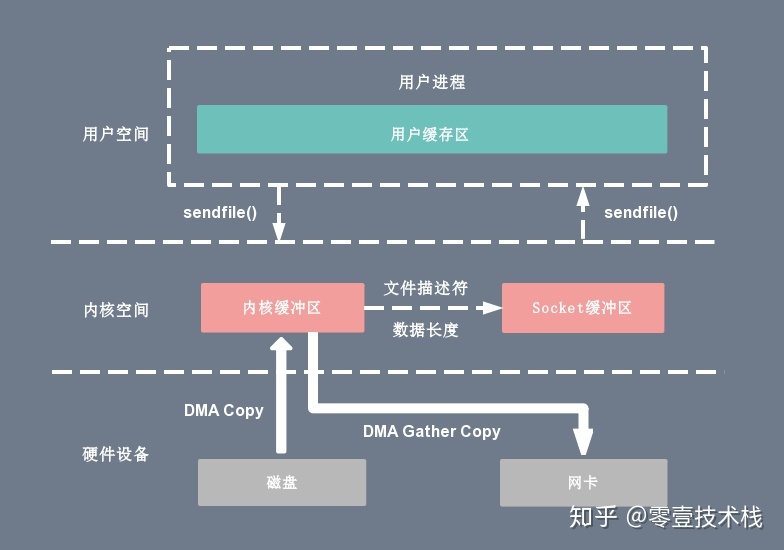
sendfile()的最初设计并不是用来处理大文件的,因此如果需要处理很大的文件的话,可以使用另一个系统调用sendfile64(),它支持对更大的文件内容进行寻址和偏移。sendfile() with DMA Scatter/Gather Copy
上一小节介绍的
sendfile()技术已经把一次数据读写过程中的 CPU 拷贝的降低至只有 1 次了,但是人永远是贪心和不知足的,现在如果想要把这仅有的一次 CPU 拷贝也去除掉,有没有办法呢?当然有!通过引入一个新硬件上的支持,我们可以把这个仅剩的一次 CPU 拷贝也给抹掉:Linux 在内核 2.4 版本里引入了 DMA 的 scatter/gather -- 分散/收集功能,并修改了
sendfile()的代码使之和 DMA 适配。scatter 使得 DMA 拷贝可以不再需要把数据存储在一片连续的内存空间上,而是允许离散存储,gather 则能够让 DMA 控制器根据少量的元信息:一个包含了内存地址和数据大小的缓冲区描述符,收集存储在各处的数据,最终还原成一个完整的网络包,直接拷贝到网卡而非套接字缓冲区,避免了最后一次的 CPU 拷贝:
sendfile() + DMA gather的数据传输过程如下:
- 用户进程调用
sendfile(),从用户态陷入内核态;- DMA 控制器使用 scatter 功能把数据从硬盘拷贝到内核缓冲区进行离散存储;
- CPU 把包含内存地址和数据长度的缓冲区描述符拷贝到套接字缓冲区,DMA 控制器能够根据这些信息生成网络包数据分组的报头和报尾
- DMA 控制器根据缓冲区描述符里的内存地址和数据大小,使用 scatter-gather 功能开始从内核缓冲区收集离散的数据并组包,最后直接把网络包数据拷贝到网卡完成数据传输;
sendfile()返回,上下文从内核态切换回用户态。基于这种方案,我们就可以把这仅剩的唯一一次 CPU 拷贝也给去除了(严格来说还是会有一次,但是因为这次 CPU 拷贝的只是那些微乎其微的元信息,开销几乎可以忽略不计),理论上,数据传输过程就再也没有 CPU 的参与了,也因此 CPU 的高速缓存再不会被污染了,也不再需要 CPU 来计算数据校验和了,CPU 可以去执行其他的业务计算任务,同时和 DMA 的 I/O 任务并行,此举能极大地提升系统性能。
splice()
sendfile()+ DMA Scatter/Gather 的零拷贝方案虽然高效,但是也有两个缺点:
- 这种方案需要引入新的硬件支持;
- 虽然
sendfile()的输出文件描述符在 Linux kernel 2.6.33 版本之后已经可以支持任意类型的文件描述符,但是输入文件描述符依然只能指向文件。这两个缺点限制了
sendfile()+ DMA Scatter/Gather 方案的适用场景。为此,Linux 在 2.6.17 版本引入了一个新的系统调用splice(),它在功能上和sendfile()非常相似,但是能够实现在任意类型的两个文件描述符时之间传输数据;而在底层实现上,splice()又比sendfile()少了一次 CPU 拷贝,也就是等同于sendfile()+ DMA Scatter/Gather,完全去除了数据传输过程中的 CPU 拷贝。
splice()系统调用函数定义如下:#include #include int pipe(int pipefd[2]); int pipe2(int pipefd[2], int flags); ssize_t splice(int fd_in, loff_t *off_in, int fd_out, loff_t *off_out, size_t len, unsigned int flags);fd_in 和 fd_out 也是分别代表了输入端和输出端的文件描述符,这两个文件描述符必须有一个是指向管道设备的,这也是一个不太友好的限制,虽然 Linux 内核开发的官方从这个系统调用推出之时就承诺未来可能会重构去掉这个限制,然而他们许下这个承诺之后就如同石沉大海,如今 14 年过去了,依旧杳无音讯...
off_in 和 off_out 则分别是 fd_in 和 fd_out 的偏移量指针,指示内核从哪里读取和写入数据,len 则指示了此次调用希望传输的字节数,最后的 flags 是系统调用的标记选项位掩码,用来设置系统调用的行为属性的,由以下 0 个或者多个值通过『或』操作组合而成:
- SPLICE_F_MOVE:指示
splice()尝试仅仅是移动内存页面而不是复制,设置了这个值不代表就一定不会复制内存页面,复制还是移动取决于内核能否从管道中移动内存页面,或者管道中的内存页面是否是完整的;这个标记的初始实现有很多 bug,所以从 Linux 2.6.21 版本开始就已经无效了,但还是保留了下来,因为在未来的版本里可能会重新被实现。- SPLICE_F_NONBLOCK:指示
splice()不要阻塞 I/O,也就是使得splice()调用成为一个非阻塞调用,可以用来实现异步数据传输,不过需要注意的是,数据传输的两个文件描述符也最好是预先通过 O_NONBLOCK 标记成非阻塞 I/O,不然splice()调用还是有可能被阻塞。- SPLICE_F_MORE:通知内核下一个
splice()系统调用将会有更多的数据传输过来,这个标记对于输出端是 socket 的场景非常有用。
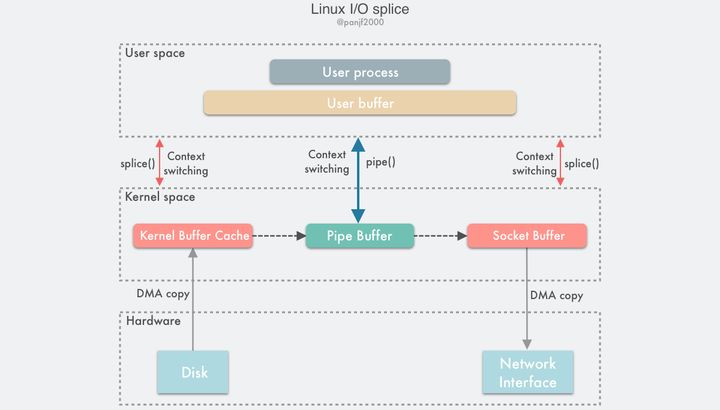
splice()是基于 Linux 的管道缓冲区 (pipe buffer) 机制实现的,所以splice()的两个入参文件描述符才要求必须有一个是管道设备,一个典型的splice()用法是:int pfd[2]; pipe(pfd); ssize_t bytes = splice(file_fd, NULL, pfd[1], NULL, 4096, SPLICE_F_MOVE); assert(bytes != -1); bytes = splice(pfd[0], NULL, socket_fd, NULL, bytes, SPLICE_F_MOVE | SPLICE_F_MORE); assert(bytes != -1);数据传输过程图:
使用
splice()完成一次磁盘文件到网卡的读写过程如下:
- 用户进程调用
pipe(),从用户态陷入内核态,创建匿名单向管道,pipe()返回,上下文从内核态切换回用户态;- 用户进程调用
splice(),从用户态陷入内核态;- DMA 控制器将数据从硬盘拷贝到内核缓冲区,从管道的写入端"拷贝"进管道,
splice()返回,上下文从内核态回到用户态;- 用户进程再次调用
splice(),从用户态陷入内核态;- 内核把数据从管道的读取端"拷贝"到套接字缓冲区,DMA 控制器将数据从套接字缓冲区拷贝到网卡;
splice()返回,上下文从内核态切换回用户态。相信看完上面的读写流程之后,读者肯定会非常困惑:说好的
splice()是sendfile()的改进版呢?sendfile()好歹只需要一次系统调用,splice()居然需要三次,这也就罢了,居然中间还搞出来一个管道,而且还要在内核空间拷贝两次,这算个毛的改进啊?我最开始了解
splice()的时候,也是这个反应,但是深入学习它之后,才渐渐知晓个中奥妙,且听我细细道来:先来了解一下 pipe buffer 管道,管道是 Linux 上用来供进程之间通信的信道,管道有两个端:写入端和读出端,从进程的视角来看,管道表现为一个 FIFO 字节流环形队列:
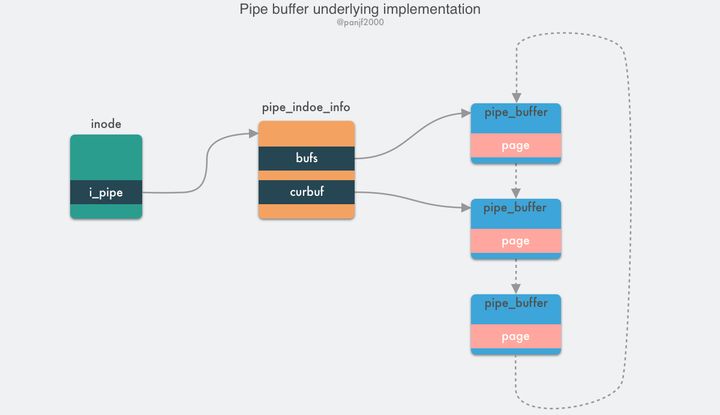
管道本质上是一个内存中的文件,也就是本质上还是基于 Linux 的 VFS,用户进程可以通过
pipe()系统调用创建一个匿名管道,创建完成之后会有两个 VFS 的 file 结构体的 inode 分别指向其写入端和读出端,并返回对应的两个文件描述符,用户进程通过这两个文件描述符读写管道;管道的容量单位是一个虚拟内存的页,也就是 4KB,总大小一般是 16 个页,基于其环形结构,管道的页可以循环使用,提高内存利用率。 Linux 中以 pipe_buffer 结构体封装管道页,file 结构体里的 inode 字段里会保存一个 pipe_inode_info 结构体指代管道,其中会保存很多读写管道时所需的元信息,环形队列的头部指针页,读写时的同步机制如互斥锁、等待队列等:struct pipe_buffer { struct page *page; // 内存页结构 unsigned int offset, len; // 偏移量,长度 const struct pipe_buf_operations *ops; unsigned int flags; unsigned long private; }; struct pipe_inode_info { struct mutex mutex; wait_queue_head_t wait; unsigned int nrbufs, curbuf, buffers; unsigned int readers; unsigned int writers; unsigned int files; unsigned int waiting_writers; unsigned int r_counter; unsigned int w_counter; struct page *tmp_page; struct fasync_struct *fasync_readers; struct fasync_struct *fasync_writers; struct pipe_buffer *bufs; struct user_struct *user; };pipe_buffer 中保存了数据在内存中的页、偏移量和长度,以这三个值来定位数据,注意这里的页不是虚拟内存的页,而用的是物理内存的页框,因为管道时跨进程的信道,因此不能使用虚拟内存来表示,只能使用物理内存的页框定位数据;管道的正常读写操作是通过 pipe_write()/pipe_read() 来完成的,通过把数据读取/写入环形队列的 pipe_buffer 来完成数据传输。
splice()是基于 pipe buffer 实现的,但是它在通过管道传输数据的时候却是零拷贝,因为它在写入读出时并没有使用 pipe_write()/pipe_read() 真正地在管道缓冲区写入读出数据,而是通过把数据在内存缓冲区中的物理内存页框指针、偏移量和长度赋值给前文提及的 pipe_buffer 中对应的三个字段来完成数据的"拷贝",也就是其实只拷贝了数据的内存地址等元信息。
splice()在 Linux 内核源码中的内部实现是do_splice()函数,而写入读出管道则分别是通过do_splice_to()和do_splice_from(),这里我们重点来解析下写入管道的源码,也就是do_splice_to(),我现在手头的 Linux 内核版本是 v4.8.17,我们就基于这个版本来分析,至于读出的源码函数do_splice_from(),原理是相通的,大家举一反三即可。
splice()写入数据到管道的调用链式:do_splice()-->do_splice_to()-->splice_read()static long do_splice(struct file *in, loff_t __user *off_in, struct file *out, loff_t __user *off_out, size_t len, unsigned int flags) { ... // 判断是写出 fd 是一个管道设备,则进入数据写入的逻辑 if (opipe) { if (off_out) return -ESPIPE; if (off_in) { if (!(in->f_mode & FMODE_PREAD)) return -EINVAL; if (copy_from_user(&offset, off_in, sizeof(loff_t))) return -EFAULT; } else { offset = in->f_pos; } // 调用 do_splice_to 把文件内容写入管道 ret = do_splice_to(in, &offset, opipe, len, flags); if (!off_in) in->f_pos = offset; else if (copy_to_user(off_in, &offset, sizeof(loff_t))) ret = -EFAULT; return ret; } return -EINVAL; }进入
do_splice_to()之后,再调用splice_read():static long do_splice_to(struct file *in, loff_t *ppos, struct pipe_inode_info *pipe, size_t len, unsigned int flags) { ssize_t (*splice_read)(struct file *, loff_t *, struct pipe_inode_info *, size_t, unsigned int); int ret; if (unlikely(!(in->f_mode & FMODE_READ))) return -EBADF; ret = rw_verify_area(READ, in, ppos, len); if (unlikely(ret < 0)) return ret; if (unlikely(len > MAX_RW_COUNT)) len = MAX_RW_COUNT; // 判断文件的文件的 file 结构体的 f_op 中有没有可供使用的、支持 splice 的 splice_read 函数指针 // 因为是 splice() 调用,因此内核会提前给这个函数指针指派一个可用的函数 if (in->f_op->splice_read) splice_read = in->f_op->splice_read; else splice_read = default_file_splice_read; return splice_read(in, ppos, pipe, len, flags); }
in->f_op->splice_read这个函数指针根据文件描述符的类型不同有不同的实现,比如这里的 in 是一个文件,因此是generic_file_splice_read(),如果是 socket 的话,则是sock_splice_read(),其他的类型也会有对应的实现,总之我们这里将使用的是generic_file_splice_read()函数,这个函数会继续调用内部函数__generic_file_splice_read完成以下工作:
- 在 page cache 页缓存里进行搜寻,看看我们要读取这个文件内容是否已经在缓存里了,如果是则直接用,否则如果不存在或者只有部分数据在缓存中,则分配一些新的内存页并进行读入数据操作,同时会增加页框的引用计数;
- 基于这些内存页,初始化 splice_pipe_desc 结构,这个结构保存会保存文件数据的地址元信息,包含有物理内存页框地址,偏移、数据长度,也就是 pipe_buffer 所需的三个定位数据的值;
- 最后,调用
splice_to_pipe(),splice_pipe_desc 结构体实例是函数入参。ssize_t splice_to_pipe(struct pipe_inode_info *pipe, struct splice_pipe_desc *spd) { ... for (;;) { if (!pipe->readers) { send_sig(SIGPIPE, current, 0); if (!ret) ret = -EPIPE; break; } if (pipe->nrbufs < pipe->buffers) { int newbuf = (pipe->curbuf + pipe->nrbufs) & (pipe->buffers - 1); struct pipe_buffer *buf = pipe->bufs + newbuf; // 写入数据到管道,没有真正拷贝数据,而是内存地址指针的移动, // 把物理页框、偏移量和数据长度赋值给 pipe_buffer 完成数据入队操作 buf->page = spd->pages[page_nr]; buf->offset = spd->partial[page_nr].offset; buf->len = spd->partial[page_nr].len; buf->private = spd->partial[page_nr].private; buf->ops = spd->ops; if (spd->flags & SPLICE_F_GIFT) buf->flags |= PIPE_BUF_FLAG_GIFT; pipe->nrbufs++; page_nr++; ret += buf->len; if (pipe->files) do_wakeup = 1; if (!--spd->nr_pages) break; if (pipe->nrbufs < pipe->buffers) continue; break; } ... }这里可以清楚地看到
splice()所谓的写入数据到管道其实并没有真正地拷贝数据,而是玩了个 tricky 的操作:只进行内存地址指针的拷贝而不真正去拷贝数据。所以,数据splice()在内核中并没有进行真正的数据拷贝,因此splice()系统调用也是零拷贝。还有一点需要注意,前面说过管道的容量是 16 个内存页,也就是 16 * 4KB = 64 KB,也就是说一次往管道里写数据的时候最好不要超过 64 KB,否则的话会
splice()会阻塞住,除非在创建管道的时候使用的是pipe2()并通过传入O_NONBLOCK属性将管道设置为非阻塞。即使
splice()通过内存地址指针避免了真正的拷贝开销,但是算起来它还要使用额外的管道来完成数据传输,也就是比sendfile()多了两次系统调用,这不是又增加了上下文切换的开销吗?为什么不直接在内核创建管道并调用那两次splice(),然后只暴露给用户一次系统调用呢?实际上因为splice()利用管道而非硬件来完成零拷贝的实现比sendfile()+ DMA Scatter/Gather 的门槛更低,因此后来的sendfile()的底层实现就已经替换成splice()了。至于说
splice()本身的 API 为什么还是这种使用模式,那是因为 Linux 内核开发团队一直想把基于管道的这个限制去掉,但不知道因为什么一直搁置,所以这个 API 也就一直没变化,只能等内核团队哪天想起来了这一茬,然后重构一下使之不再依赖管道,在那之前,使用splice()依然还是需要额外创建管道来作为中间缓冲,如果你的业务场景很适合使用splice(),但又是性能敏感的,不想频繁地创建销毁 pipe buffer 管道缓冲区,那么可以参考一下 HAProxy 使用splice()时采用的优化方案:预先分配一个 pipe buffer pool 缓存管道,每次调用spclie()的时候去缓存池里取一个管道,用完就放回去,循环利用,提升性能。send() with MSG_ZEROCOPY
Linux 内核在 2017 年的 v4.14 版本接受了来自 Google 工程师 Willem de Bruijn 在 TCP 网络报文的通用发送接口
send()中实现的 zero-copy 功能 (MSG_ZEROCOPY) 的 patch,通过这个新功能,用户进程就能够把用户缓冲区的数据通过零拷贝的方式经过内核空间发送到网络套接字中去,这个新技术和前文介绍的几种零拷贝方式相比更加先进,因为前面几种零拷贝技术都是要求用户进程不能处理加工数据而是直接转发到目标文件描述符中去的。Willem de Bruijn 在他的论文里给出的压测数据是:采用 netperf 大包发送测试,性能提升 39%,而线上环境的数据发送性能则提升了 5%~8%,官方文档陈述说这个特性通常只在发送 10KB 左右大包的场景下才会有显著的性能提升。一开始这个特性只支持 TCP,到内核 v5.0 版本之后才支持 UDP。这个功能的使用模式如下:
if (setsockopt(socket_fd, SOL_SOCKET, SO_ZEROCOPY, &one, sizeof(one))) error(1, errno, "setsockopt zerocopy"); ret = send(socket_fd, buffer, sizeof(buffer), MSG_ZEROCOPY);首先第一步,先给要发送数据的 socket 设置一个 SOCK_ZEROCOPY option,然后在调用
send()发送数据时再设置一个 MSG_ZEROCOPY option,其实理论上来说只需要调用setsockopt()或者send()时传递这个 zero-copy 的 option 即可,两者选其一,但是这里却要设置同一个 option 两次,官方的说法是为了兼容send()API 以前的设计上的一个错误:send()以前的实现会忽略掉未知的 option,为了兼容那些可能已经不小心设置了 MSG_ZEROCOPY option 的程序,故而设计成了两步设置。不过我猜还有一种可能:就是给使用者提供更灵活的使用模式,因为这个新功能只在大包场景下才可能会有显著的性能提升,但是现实场景是很复杂的,不仅仅是全部大包或者全部小包的场景,有可能是大包小包混合的场景,因此使用者可以先调用setsockopt()设置 SOCK_ZEROCOPY option,然后再根据实际业务场景中的网络包尺寸选择是否要在调用send()时使用 MSG_ZEROCOPY 进行 zero-copy 传输。因为
send()可能是异步发送数据,因此使用 MSG_ZEROCOPY 有一个需要特别注意的点是:调用send()之后不能立刻重用或释放 buffer,因为 buffer 中的数据不一定已经被内核读走了,所以还需要从 socket 关联的错误队列里读取一下通知消息,看看 buffer 中的数据是否已经被内核读走了:pfd.fd = fd; pfd.events = 0; if (poll(&pfd, 1, -1) != 1 || pfd.revents & POLLERR == 0) error(1, errno, "poll"); ret = recvmsg(fd, &msg, MSG_ERRQUEUE); if (ret == -1) error(1, errno, "recvmsg"); read_notification(msg); uint32_t read_notification(struct msghdr *msg) { struct sock_extended_err *serr; struct cmsghdr *cm; cm = CMSG_FIRSTHDR(msg); if (cm->cmsg_level != SOL_IP && cm->cmsg_type != IP_RECVERR) error(1, 0, "cmsg"); serr = (void *) CMSG_DATA(cm); if (serr->ee_errno != 0 || serr->ee_origin != SO_EE_ORIGIN_ZEROCOPY) error(1, 0, "serr"); return serr->ee _ data; }这个技术是基于 redhat 红帽在 2010 年给 Linux 内核提交的 virtio-net zero-copy 技术之上实现的,至于底层原理,简单来说就是通过
send()把数据在用户缓冲区中的分段指针发送到 socket 中去,利用 page pinning 页锁定机制锁住用户缓冲区的内存页,然后利用 DMA 直接在用户缓冲区通过内存地址指针进行数据读取,实现零拷贝;具体的细节可以通过阅读 Willem de Bruijn 的论文 (PDF) 深入了解。目前来说,这种技术的主要缺陷有:
- 只适用于大文件 (10KB 左右) 的场景,小文件场景因为 page pinning 页锁定和等待缓冲区释放的通知消息这些机制,甚至可能比直接 CPU 拷贝更耗时;
- 因为可能异步发送数据,需要额外调用
poll()和recvmsg()系统调用等待 buffer 被释放的通知消息,增加代码复杂度,以及会导致多次用户态和内核态的上下文切换;- MSG_ZEROCOPY 目前只支持发送端,接收端暂不支持。
绕过内核的直接 I/O
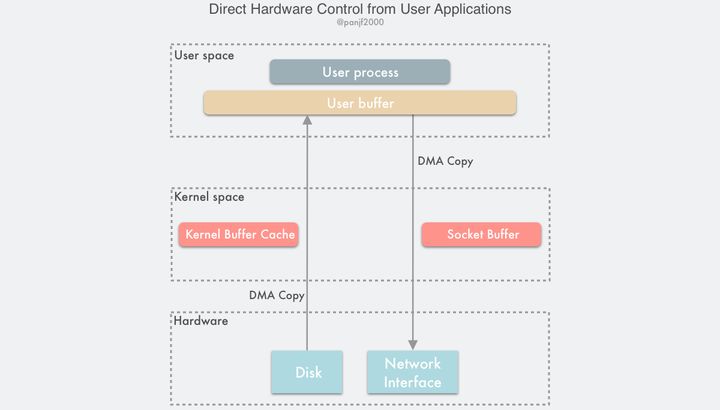
可以看出,前面种种的 zero-copy 的方法,都是在想方设法地优化减少或者去掉用户态和内核态之间以及内核态和内核态之间的数据拷贝,为了实现避免这些拷贝可谓是八仙过海,各显神通,采用了各种各样的手段,那么如果我们换个思路:其实这么费劲地去消除这些拷贝不就是因为有内核在掺和吗?如果我们绕过内核直接进行 I/O 不就没有这些烦人的拷贝问题了吗?这就是绕过内核直接 I/O 技术:
这种方案有两种实现方式:
- 用户直接访问硬件
- 内核控制访问硬件
用户直接访问硬件
这种技术赋予用户进程直接访问硬件设备的权限,这让用户进程能有直接读写硬件设备,在数据传输过程中只需要内核做一些虚拟内存配置相关的工作。这种无需数据拷贝和内核干预的直接 I/O,理论上是最高效的数据传输技术,但是正如前面所说的那样,并不存在能解决一切问题的银弹,这种直接 I/O 技术虽然有可能非常高效,但是它的适用性也非常窄,目前只适用于诸如 MPI 高性能通信、丛集计算系统中的远程共享内存等有限的场景。
这种技术实际上破坏了现代计算机操作系统最重要的概念之一 —— 硬件抽象,我们之前提过,抽象是计算机领域最最核心的设计思路,正式由于有了抽象和分层,各个层级才能不必去关心很多底层细节从而专注于真正的工作,才使得系统的运作更加高效和快速。此外,网卡通常使用功能较弱的 CPU,例如只包含简单指令集的 MIPS 架构处理器(没有不必要的功能,如浮点数计算等),也没有太多的内存来容纳复杂的软件。因此,通常只有那些基于以太网之上的专用协议会使用这种技术,这些专用协议的设计要比远比 TCP/IP 简单得多,而且多用于局域网环境中,在这种环境中,数据包丢失和损坏很少发生,因此没有必要进行复杂的数据包确认和流量控制机制。而且这种技术还需要定制的网卡,所以它是高度依赖硬件的。
与传统的通信设计相比,直接硬件访问技术给程序设计带来了各种限制:由于设备之间的数据传输是通过 DMA 完成的,因此用户空间的数据缓冲区内存页必须进行 page pinning(页锁定),这是为了防止其物理页框地址被交换到磁盘或者被移动到新的地址而导致 DMA 去拷贝数据的时候在指定的地址找不到内存页从而引发缺页错误,而页锁定的开销并不比 CPU 拷贝小,所以为了避免频繁的页锁定系统调用,应用程序必须分配和注册一个持久的内存池,用于数据缓冲。
用户直接访问硬件的技术可以得到极高的 I/O 性能,但是其应用领域和适用场景也极其的有限,如集群或网络存储系统中的节点通信。它需要定制的硬件和专门设计的应用程序,但相应地对操作系统内核的改动比较小,可以很容易地以内核模块或设备驱动程序的形式实现出来。直接访问硬件还可能会带来严重的安全问题,因为用户进程拥有直接访问硬件的极高权限,所以如果你的程序设计没有做好的话,可能会消耗本来就有限的硬件资源或者进行非法地址访问,可能也会因此间接地影响其他正在使用同一设备的应用程序,而因为绕开了内核,所以也无法让内核替你去控制和管理。
内核控制访问硬件
相较于用户直接访问硬件技术,通过内核控制的直接访问硬件技术更加的安全,它比前者在数据传输过程中会多干预一点,但也仅仅是作为一个代理人这样的角色,不会参与到实际的数据传输过程,内核会控制 DMA 引擎去替用户进程做缓冲区的数据传输工作。同样的,这种方式也是高度依赖硬件的,比如一些集成了专有网络栈协议的网卡。这种技术的一个优势就是用户集成去 I/O 时的接口不会改变,就和普通的
read()/write()系统调用那样使用即可,所有的脏活累活都在内核里完成,用户接口友好度很高,不过需要注意的是,使用这种技术的过程中如果发生了什么不可预知的意外从而导致无法使用这种技术进行数据传输的话,则内核会自动切换为最传统 I/O 模式,也就是性能最差的那种模式。这种技术也有着和用户直接访问硬件技术一样的问题:DMA 传输数据的过程中,用户进程的缓冲区内存页必须进行 page pinning 页锁定,数据传输完成后才能解锁。CPU 高速缓存内保存的多个内存地址也会被冲刷掉以保证 DMA 传输前后的数据一致性。这些机制有可能会导致数据传输的性能变得更差,因为
read()/write()系统调用的语义并不能提前通知 CPU 用户缓冲区要参与 DMA 数据传输传输,因此也就无法像内核缓冲区那样可依提前加载进高速缓存,提高性能。由于用户缓冲区的内存页可能分布在物理内存中的任意位置,因此一些实现不好的 DMA 控制器引擎可能会有寻址限制从而导致无法访问这些内存区域。一些技术比如 AMD64 架构中的 IOMMU,允许通过将 DMA 地址重新映射到内存中的物理地址来解决这些限制,但反过来又可能会导致可移植性问题,因为其他的处理器架构,甚至是 Intel 64 位 x86 架构的变种 EM64T 都不具备这样的特性单元。此外,还可能存在其他限制,比如 DMA 传输的数据对齐问题,又会导致无法访问用户进程指定的任意缓冲区内存地址。内核缓冲区和用户缓冲区之间的传输优化
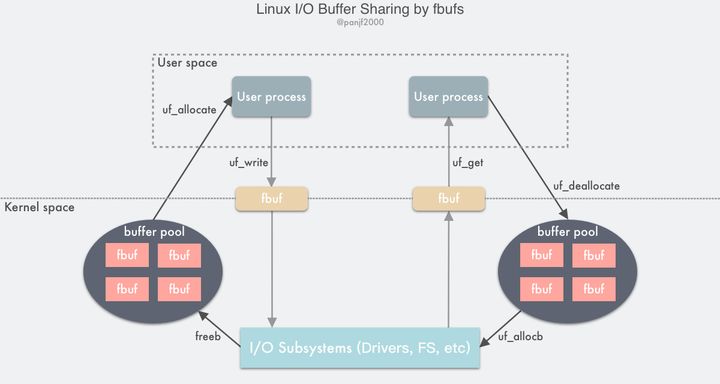
到目前为止,我们讨论的 zero-copy 技术都是基于减少甚至是避免用户空间和内核空间之间的 CPU 数据拷贝的,虽然有一些技术非常高效,但是大多都有适用性很窄的问题,比如
sendfile()、splice()这些,效率很高,但是都只适用于那些用户进程不需要直接处理数据的场景,比如静态文件服务器或者是直接转发数据的代理服务器。现在我们已经知道,硬件设备之间的数据可以通过 DMA 进行传输,然而却并没有这样的传输机制可以应用于用户缓冲区和内核缓冲区之间的数据传输。不过另一方面,广泛应用在现代的 CPU 架构和操作系统上的虚拟内存机制表明,通过在不同的虚拟地址上重新映射页面可以实现在用户进程和内核之间虚拟复制和共享内存,尽管一次传输的内存颗粒度相对较大:4KB 或 8KB。
因此如果要在实现在用户进程内处理数据(这种场景比直接转发数据更加常见)之后再发送出去的话,用户空间和内核空间的数据传输就是不可避免的,既然避无可避,那就只能选择优化了,因此本章节我们要介绍两种优化用户空间和内核空间数据传输的技术:
- 动态重映射与写时拷贝 (Copy-on-Write)
- 缓冲区共享 (Buffer Sharing)
动态重映射与写时拷贝 (Copy-on-Write)
前面我们介绍过利用内存映射技术来减少数据在用户空间和内核空间之间的复制,通常简单模式下,用户进程是对共享的缓冲区进行同步阻塞读写的,这样不会有 data race 问题,但是这种模式下效率并不高,而提升效率的一种方法就是异步地对共享缓冲区进行读写,而这样的话就必须引入保护机制来避免数据冲突问题,写时复制 (Copy on Write) 就是这样的一种技术。
写入时复制(Copy-on-write,COW)是一种计算机程序设计领域的优化策略。其核心思想是,如果有多个调用者(callers)同时请求相同资源(如内存或磁盘上的数据存储),他们会共同获取相同的指针指向相同的资源,直到某个调用者试图修改资源的内容时,系统才会真正复制一份专用副本(private copy)给该调用者,而其他调用者所见到的最初的资源仍然保持不变。这过程对其他的调用者都是透明的。此作法主要的优点是如果调用者没有修改该资源,就不会有副本(private copy)被创建,因此多个调用者只是读取操作时可以共享同一份资源。举一个例子,引入了 COW 技术之后,用户进程读取磁盘文件进行数据处理最后写到网卡,首先使用内存映射技术让用户缓冲区和内核缓冲区共享了一段内存地址并标记为只读 (read-only),避免数据拷贝,而当要把数据写到网卡的时候,用户进程选择了异步写的方式,系统调用会直接返回,数据传输就会在内核里异步进行,而用户进程就可以继续其他的工作,并且共享缓冲区的内容可以随时再进行读取,效率很高,但是如果该进程又尝试往共享缓冲区写入数据,则会产生一个 COW 事件,让试图写入数据的进程把数据复制到自己的缓冲区去修改,这里只需要复制要修改的内存页即可,无需所有数据都复制过去,而如果其他访问该共享内存的进程不需要修改数据则可以永远不需要进行数据拷贝。
COW 是一种建构在虚拟内存冲映射技术之上的技术,因此它需要 MMU 的硬件支持,MMU 会记录当前哪些内存页被标记成只读,当有进程尝试往这些内存页中写数据的时候,MMU 就会抛一个异常给操作系统内核,内核处理该异常时为该进程分配一份物理内存并复制数据到此内存地址,重新向 MMU 发出执行该进程的写操作。
COW 最大的优势是节省内存和减少数据拷贝,不过却是通过增加操作系统内核 I/O 过程复杂性作为代价的。当确定采用 COW 来复制页面时,重要的是注意空闲页面的分配位置。许多操作系统为这类请求提供了一个空闲的页面池。当进程的堆栈或堆要扩展时或有写时复制页面需要管理时,通常分配这些空闲页面。操作系统分配这些页面通常采用称为按需填零的技术。按需填零页面在需要分配之前先填零,因此会清除里面旧的内容。
局限性:
COW 这种零拷贝技术比较适用于那种多读少写从而使得 COW 事件发生较少的场景,因为 COW 事件所带来的系统开销要远远高于一次 CPU 拷贝所产生的。此外,在实际应用的过程中,为了避免频繁的内存映射,可以重复使用同一段内存缓冲区,因此,你不需要在只用过一次共享缓冲区之后就解除掉内存页的映射关系,而是重复循环使用,从而提升性能,不过这种内存页映射的持久化并不会减少由于页表往返移动和 TLB 冲刷所带来的系统开销,因为每次接收到 COW 事件之后对内存页而进行加锁或者解锁的时候,页面的只读标志 (read-ony) 都要被更改为 (write-only)。
缓冲区共享 (Buffer Sharing)
从前面的介绍可以看出,传统的 Linux I/O 接口,都是基于复制/拷贝的:数据需要在操作系统内核空间和用户空间的缓冲区之间进行拷贝。在进行 I/O 操作之前,用户进程需要预先分配好一个内存缓冲区,使用
read()系统调用时,内核会将从存储器或者网卡等设备读入的数据拷贝到这个用户缓冲区里;而使用write()系统调用时,则是把用户内存缓冲区的数据拷贝至内核缓冲区。为了实现这种传统的 I/O 模式,Linux 必须要在每一个 I/O 操作时都进行内存虚拟映射和解除。这种内存页重映射的机制的效率严重受限于缓存体系结构、MMU 地址转换速度和 TLB 命中率。如果能够避免处理 I/O 请求的虚拟地址转换和 TLB 刷新所带来的开销,则有可能极大地提升 I/O 性能。而缓冲区共享就是用来解决上述问题的一种技术。
最早支持 Buffer Sharing 的操作系统是 Solaris。后来,Linux 也逐步支持了这种 Buffer Sharing 的技术,但时至今日依然不够完整和成熟。
操作系统内核开发者们实现了一种叫 fbufs 的缓冲区共享的框架,也即快速缓冲区( Fast Buffers ),使用一个 fbuf 缓冲区作为数据传输的最小单位,使用这种技术需要调用新的操作系统 API,用户区和内核区、内核区之间的数据都必须严格地在 fbufs 这个体系下进行通信。fbufs 为每一个用户进程分配一个 buffer pool,里面会储存预分配 (也可以使用的时候再分配) 好的 buffers,这些 buffers 会被同时映射到用户内存空间和内核内存空间。fbufs 只需通过一次虚拟内存映射操作即可创建缓冲区,有效地消除那些由存储一致性维护所引发的大多数性能损耗。
传统的 Linux I/O 接口是通过把数据在用户缓冲区和内核缓冲区之间进行拷贝传输来完成的,这种数据传输过程中需要进行大量的数据拷贝,同时由于虚拟内存技术的存在,I/O 过程中还需要频繁地通过 MMU 进行虚拟内存地址到物理内存地址的转换,高速缓存的汰换以及 TLB 的刷新,这些操作均会导致性能的损耗。而如果利用 fbufs 框架来实现数据传输的话,首先可以把 buffers 都缓存到 pool 里循环利用,而不需要每次都去重新分配,而且缓存下来的不止有 buffers 本身,而且还会把虚拟内存地址到物理内存地址的映射关系也缓存下来,也就可以避免每次都进行地址转换,从发送接收数据的层面来说,用户进程和 I/O 子系统比如设备驱动程序、网卡等可以直接传输整个缓冲区本身而不是其中的数据内容,也可以理解成是传输内存地址指针,这样就就避免了大量的数据内容拷贝:用户进程/ IO 子系统通过发送一个个的 fbuf 写出数据到内核而非直接传递数据内容,相对应的,用户进程/ IO 子系统通过接收一个个的 fbuf 而从内核读入数据,这样就能减少传统的
read()/write()系统调用带来的数据拷贝开销:
- 发送方用户进程调用
uf_allocate从自己的 buffer pool 获取一个 fbuf 缓冲区,往其中填充内容之后调用uf_write向内核区发送指向 fbuf 的文件描述符;- I/O 子系统接收到 fbuf 之后,调用
uf_allocb从接收方用户进程的 buffer pool 获取一个 fubf 并用接收到的数据进行填充,然后向用户区发送指向 fbuf 的文件描述符;- 接收方用户进程调用
uf_get接收到 fbuf,读取数据进行处理,完成之后调用uf_deallocate把 fbuf 放回自己的 buffer pool。fbufs 的缺陷
共享缓冲区技术的实现需要依赖于用户进程、操作系统内核、以及 I/O 子系统 (设备驱动程序,文件系统等)之间协同工作。比如,设计得不好的用户进程容易就会修改已经发送出去的 fbuf 从而污染数据,更要命的是这种问题很难 debug。虽然这个技术的设计方案非常精彩,但是它的门槛和限制却不比前面介绍的其他技术少:首先会对操作系统 API 造成变动,需要使用新的一些 API 调用,其次还需要设备驱动程序配合改动,还有由于是内存共享,内核需要很小心谨慎地实现对这部分共享的内存进行数据保护和同步的机制,而这种并发的同步机制是非常容易出 bug 的从而又增加了内核的代码复杂度,等等。因此这一类的技术还远远没有到发展成熟和广泛应用的阶段,目前大多数的实现都还处于实验阶段。
总结
本文中我主要讲解了 Linux I/O 底层原理,然后介绍并解析了 Linux 中的 Zero-copy 技术,并给出了 Linux 对 I/O 模块的优化和改进思路。
Linux 的 Zero-copy 技术可以归纳成以下三大类:
- 减少甚至避免用户空间和内核空间之间的数据拷贝:在一些场景下,用户进程在数据传输过程中并不需要对数据进行访问和处理,那么数据在 Linux 的
Page Cache和用户进程的缓冲区之间的传输就完全可以避免,让数据拷贝完全在内核里进行,甚至可以通过更巧妙的方式避免在内核里的数据拷贝。这一类实现一般是是通过增加新的系统调用来完成的,比如 Linux 中的 mmap(),sendfile() 以及 splice() 等。- 绕过内核的直接 I/O:允许在用户态进程绕过内核直接和硬件进行数据传输,内核在传输过程中只负责一些管理和辅助的工作。这种方式其实和第一种有点类似,也是试图避免用户空间和内核空间之间的数据传输,只是第一种方式是把数据传输过程放在内核态完成,而这种方式则是直接绕过内核和硬件通信,效果类似但原理完全不同。
- 内核缓冲区和用户缓冲区之间的传输优化:这种方式侧重于在用户进程的缓冲区和操作系统的页缓存之间的 CPU 拷贝的优化。这种方法延续了以往那种传统的通信方式,但更灵活。
本文从虚拟内存、I/O 缓冲区,用户态&内核态以及 I/O 模式等等知识点全面而又详尽地剖析了 Linux 系统的 I/O 底层原理,分析了 Linux 传统的 I/O 模式的弊端,进而引入 Linux Zero-copy 零拷贝技术的介绍和原理解析,通过将零拷贝技术和传统的 I/O 模式进行区分和对比,带领读者经历了 Linux I/O 的演化历史,通过帮助读者理解 Linux 内核对 I/O 模块的优化改进思路,相信不仅仅是让读者了解 Linux 底层系统的设计原理,更能对读者们在以后优化改进自己的程序设计过程中能够有所启发。
参考&延伸阅读
- MODERN OPERATING SYSTEMS
- Zero Copy I: User-Mode Perspective
- Message Passing for Gigabit/s Networks with “Zero-Copy” under Linux
- ZeroCopy: Techniques, Benefits and Pitfalls
- Zero-copy networking
- Driver porting: Zero-copy user-space access
- sendmsg copy avoidance with MSG_ZEROCOPY
- It’s all about buffers: zero-copy, mmap and Java NIO
- Linux Zero Copy
- Two new system calls: splice() and sync_file_range()
- Circular pipes
- The future of the page cache
- Provide a zero-copy method on KVM virtio-net.