拜读大神的系列教程,大神好像姓崔(猜测),大神根据《机器学习实战》来讲解,讲的很清楚,读了大神的博客后,我也把我自己吸收的写下来,可能有很多错误之处,希望拍砖(拍轻点)
大神博客: https://cuijiahua.com/blog/2017/11/ml_1_knn.html ,写得很好
话不多说:
前言:
KNN算法应该是最简单的方法了(估计没有之一),在讲KNN理论之前,先讲下学校时学的两点间距离公式,即:
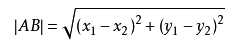
注: 这是2维坐标系里,求两点距离
一、KNN理论
首先我们有两个数据集,训练集和测试集,训练集用来训练数据,测试集用来测试训练后的准确性
有了两点间距离公式,接下来说下KNN步骤:
(1)、首先准备训练集
(2)、准备测试集
(3)、求测试集和训练集每点之间的距离
(4)、按距离升序排序
(5)、取前K个数据(K一般为奇数较好),读取每个数据的分类结果
(6)、计算每个分类出现的次数
以上是KNN大概步骤,可能光文字描述比较难懂点,其实核心就是两点间距离公式,下面就用具体的例子说明:
二、首先我们举一个电影分类的例子
首先我们看下训练集:
| 打斗镜头数 | 接吻镜头数 | 分类结果 |
| 1 | 101 | 爱情片 |
| 105 | 1 | 动作片 |
| 2 | 100 | 爱情片 |
| 100 | 1 | 动作片 |
训练集解释:电影的分类只有两个类别,即动作片和爱情片,而分类的根据是打斗镜头数和接吻镜头数, 如果打斗镜头比接吻镜头多,说明是爱情片(大家都懂的),反之则是动作片,这就是分类的规则,但大家有没有发现一个问题,如果打斗镜头和接吻镜头一样多,那这个分类究竟是动作片还是爱情片了,还是爱情动作片? 其实这时候用KNN算法是分辨不出来的,因为数据集没有这个分类
好了,训练集准备好了,接下来看下测试集:
| 打斗镜头数 | 接吻镜头数 |
| 130 | 1 |
| 1 | 100 |
以上是其实是两个测试集,下面就要分别求出分类结果:
代码如下
1 import numpy as np;
2 import operator;
3
4 def createDataSet():#创建数据集
5 group=np.array([[1,101],[5,89],[108,5],[115,8]]);#训练集特征
6 labels=np.array(['爱情片','爱情片','动作片','动作片']);#训练对应的结果
7 return group,labels;
8
9 def classisfy0(inx,dataSet,labels,k):#分类函数,即求出分类结果
10 dataSetSize=dataSet.shape[0];#获得训练集的行数
11 diffMat=np.tile(inx,(dataSetSize,1))-dataSet;#把测试集重复训练集的行数,并且测试集减去训练集,即(x1-x2),(y1-y2)
12 sqDiffMat=diffMat**2;#对矩阵每个元素求平方
13 sqDistance=sqDiffMat.sum(axis=1);#对矩阵按行求和,axis=1即按行求和
14 distance=sqDistance**0.5;#对求和后的矩阵,开方根,即距离公式的开方
15 sortedDistIndices=distance.argsort();#求出来的距离按从小大到排序,并且返回每个元素的索引,这里要注意的是:排序后的元素索引不会变,还是原来的索引,不了解的可以百度下argsort函数
16 classCount={};
17 for i in range(k):#取前K个值,并且计算出每个分类出现的次数
18 votelabel=lables[sortedDistIndices[i]];
19 classCount[votelabel]=classCount.get(votelabel,0)+1;
20 #排序,即按出现次数从大到小排序
21 sortedClassCount=sorted(classCount.items(),key=operator.itemgetter(1),reverse=True);
22 return sortedClassCount[0][0];#取第一个元素的分类结果,即出现次数最多的分类就是分类结果
23
24 if __name__=='__main__':
25 group,lables=createDataSet();
26 test=[130,1];#测试集1
27 test_class=classisfy0(test,group,lables,3);
28 print('测试集1结果:',test_class);
29 test=[1,100];#测试集2
30 test_class = classisfy0(test, group, lables, 3);
31 print('测试集2结果:',test_class)
运行结果截图:

以上就是KNN的示例
三、根据约会数据集计算出约会成功的概率
前言:大家有没有想到一个问题,如果我的数据集是多维的,那距离怎么求了,这就是另一个公式了,即欧氏距离公式,即:
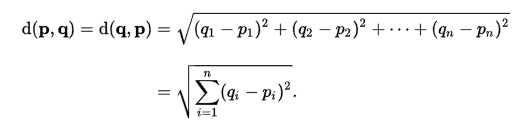
先讲到这里吧,下篇再讲怎么计算多维度的数据集分类,大家也可以根据上面电影分类来实现!
以上都是我看崔大神的博客:https://cuijiahua.com/blog/2017/11/ml_1_knn.html,学习到的,可能有些地方理解有错误,欢迎指教!