转自http://www.dataguru.cn/forum.php?mod=viewthread&tid=286174
随着互联网的快速发展,涌现出了一大批以Facebook,Twitter,人人,微博等为代表的新型社交网站。这些网站用户数量的迅速增长使得海量的用户数据不断被产生出来,而如何有效地对这些海量的用户数据进行社交网络分析(Social Network Analysis)正成为一个越来越热门的问题。本文向大家介绍由IBM中国研究院和北京邮电大学合作开发的X-RIME开源库(http://xrime.sourceforge.net/),一个基于Hadoop的开源社交网络分析工具。
其实早在90年代初就已经有许多企业和研究机构对社交网络进行过相关研究。然而随着互联网用户的急速的增长,今日的社交网站所需处理的数据已经不是传统的解决方案所能够应对的了。例如,传统的社会网络分析算法和工具往往都是单机形式的,在面对大规模数据集的时候往往会出现存储和处理能力不足等方面问题,再加上原始输入数据和社会网络的内部表示大都属于无结构或者半结构化数据,传统关系数据库并不擅长处理此类数据,使得利用传统的社会网络分析算法和工具对大规模数据集进行处理变得更加困难。另一方面,随着Hadoop的日益流行,许多中小互联网企业可以通过搭建Hadoop集群来方便地进行大规模数据处理。然而,Hadoop并不直接提供社交网络分析的算法库,因此实施海量社交网络分析仍存在较高门槛。基于这些需求,我们设计并实现了X-RIME。
X-RIME是一个基于Hadoop的开源社会网络分析工具。依赖于Hadoop提供的大规模数据并行处理能力,X-RIME实现了对十几中网络分析算法的并行化,提供了一整套用于对大规模社会网络进行分析处理的解决方案。通过使用X-RIME,用户可以方便快捷地对海量社会网络数据进行分析,从这些海量社会网络数据中获取更深层次的有用信息,从而进一步挖掘商业价值,支持商业决策以及发现新的业务增长点。
1. X-RIME架构介绍
图一描述了X-RIME的整体架构,它主要由四层组成:HDFS,X-RIME数据模型,X-RIME算法库以及基于社交网络分析的商业智能分析应用。

图1. X-RIME整体架构
X-RIME算法库是X-RIME的核心组成部分,他基于Map/Reduce实现了十余种分布式社交网络处理算法。
X-RIME最底层采用了HDFS来存储海量数据。像很多其他基于Hadoop的数据分析解决方案一样,X-RIME也采用了HDFS来构建底层的海量数据存储设施。整个X-RIME算法库的所有的输入文件、中间结果和最终结果都会存储在HDFS上。
处于倒数第二层的X-RIME数据模型层实现了社交网络数据的“数据结构”。我们知道,社交网络的基础模型是图论中的图模型。在这个模型中,社会网络的个体被视为图中的节点,个体之间的关联被视为图中的边。 X-RIME数据模型层包括了近20 种数据结构,主要包括基于Hadoop 的对社会网络中的点、边等抽象概念的具体数据结构表示。在后面一节我们会详细介绍该数据模型的设计原则。
在X-RIME数据模型层之上的是X-RIME核心算法库(它运行在Hadoop的MapReduce框架之上)。在算法库中,我们通过map()/reduce()函数对的形式实现了十余种常见的社交网络分析算法。这些算法通过将多个Hadoop Job按算法工作流程组合在一起来共同完成相应的任务。这些算法都被相同的接口封装起来,这些接口一般包括四种参数:(1)输入文件在HDFS中的路径,它保存了与X-RIME数据模型相兼容的输入文件;(2)输出文件在HDFS中的路径,它用以保存最终的分析结果;(3)MAP/REDUCE的相关参数,例如Mapper数或者Reducer数等;(4)社交网络分析算法相关参数,例如迭代次数等。
图一中最顶层是基于社交网络分析的商业智能分析应用。它通过调用X-RIME核心算法库来实现对社交网络的数据分析。如果需要的话,用户还能将它与已有的数据仓库解决方案集成(例如JAQL,Mahout等),从而提供一个更加完整、高效的综合商业智能分析解决方案。
2. X-RIME 数据模型的设计原则
X-RIME 的设计目标是用来专门做大规模数据集社会网络分析的工具,因此我们对X-RIME 数据模型进行设计时必须考虑以下两点原则:X-RIME 需要处理大规模数据集;X-RIME 分析的对象是社会网络。X-RIME 处理大规模数据集的能力主要依赖于Hadoop的大规模并行处理能力,因此只要X-RIME 中所有的数据结构都是基于HADOOP 的海量数据集接口即可。这里我们重点分析X-RIME分析的对象即社会网络的特点。之前的分析中已经提到社会网络的基础模型是图论中的图模型,在这个模型里,社会网络中的个体被视为图里的结点v ,结点的集合为V ;个体之间的关联被视为图里面的边e,边的集合是E = {e (u, v) | u∈V, v∈V},因此整个模型就可以看作是G = (V, E)。基于此我们对X-RIME 的数据模型做了如下考量:
2.1 采用邻接矩阵还是邻接表

图2. 稀疏图和稠密图的邻接表与邻接矩阵形式
如图 2 所示,要表示一个图G = (V, E),有两种标准的方法,即邻接矩阵和邻接表。一般认为当|E|远小于|V|2的图属于稀疏图,反之则认为是稠密图。使用邻接矩阵表示法的优点在于可以很快判断两个给定结点是否存在连接边,缺点在于当要表示的图是稠密图的时候有大量的空间会被浪费。邻接表表示方式的优点在于节省空间,缺点在于判断两个给定结点是否存在连接表需要遍历其中某个结点的邻接表,效率较低。基于以下两点考虑,我们采用了邻接表的方式表示X-RIME 中的图结构:
(1)社交网络一般属于稀疏图结构,因此使用邻接表表示可以节省大量空间,提高空间利用率。
(2)X-RIME 中大部分算法不需要快速判断两个给定结点是否存在连接边。
(2)X-RIME 中大部分算法不需要快速判断两个给定结点是否存在连接边。
2.2 边的表现形式
在邻接表中,结点之间的关系需要使用边来承载,边的形式可以有多种,如有向边,无向边,自环边(自己指向自己)等。考虑到在社会网络中,上述几种边都有可能存在,在不同的应用场景中有不同需求,因此我们需要有灵活的数据结构来支持上述各种不同形式的边。此外还有一种情况需要考虑,当有向边用{from, to}来表示时,传统的邻接表表示法只是将这条边信息记录在from 端,但是在社会网络分析中,我们可能存在某种场景需要同时将这条边信息记录在to 端,X-RIME 的设计中考虑了这种应用场景。
2.3 额外的承载信息

图3. 社会网络中结点和边需要存储额外信息
X-RIME 需要处理的社会网络图与传统的简单图不一样,它是个体以及个体之间复杂关系的一种抽象。如图3 所示,在社会网络中,结点自身往往需要存储一些额外的信息,例如当图中的结点表示人的时候,可能需要额外记录这个人的性别、年龄、家庭地址等信息;结点之间的关系(边)往往也需要存储一些额外的信息,例如当图中的边表示两个人是好朋友的时候,可能需要额外记录这条边的强度(好友关系的强烈程度)、边的类型(关系类型,如家人、朋友、同学等)、好友间的物理距离等。基于上述考虑,X-RIME 的设计中必须考虑为结点和边提供额外的信息存储功能。
2.4 比较器
在社会网络中,个体和边需要进行某种程度的对比。例如在好友关系网中,人们可能希望比较得出哪些人是自己最好的朋友,人们同样可能希望比较得出自己在好友心目中的重要程度等。映射到X-RIME 中,大量的运算的确需要对结点以及边进行比较。这种比较可以是简单的数值比较(例如边的权值比较)也可以是复杂的逻辑比较(例如综合边的关系类型,边的强度,结点之间的物理距离等进行比较)。X-RIME 的设计中必须考虑数据类型之间的比较,需要设计各种比较器。
2.5 效率问题
X-RIME 需要处理的是大规模海量数据,如果我们对输入数据的读写处理只是简单地根据原始的文本文件格式进行读写,势必影响效率,因为这样多了一个中间转换过程,需要读入内存再根据特定的数据结构格式进行转换。Hadoop 提供的序列化IO 接口为我们提供了一个有效的方法来提高读写效率。在读取输入数据之前,我们需要预先对原始文本进行转换,通过Hadoop 序列化IO 接口的序列化功能将其转换成二进制镜像文件形式,这样每次X-RIME 读取被序列化产生的二进制文件的时候可以直接通过Hadoop 序列化IO 接口的反序列化功能将镜像文件装载到内存里,输出的时候直接通过Hadoop IO 的序列化功能进行输出,效率大大提高。两种读写方式的示意图如图4 所示。
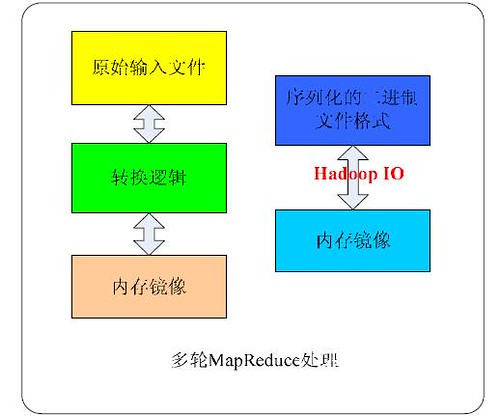
图4. 两种输入输出方式(左:较为低效的传统方式,右:高效的序列化方式)
3. X-RIME使用介绍
使用X-RIME大致可以分为四步。第一步:获取原始数据,例如使用爬虫获取原始网站数据。第二步:对数据进行预处理以转化成X-RIME数据模型所支持的格式。这个步骤与用户提供的具体数据格式相关,因而通常由X-RIME用户自己实现。第三步:调用X-RIME算法库对这些数据进行社交网络分析。第四步:对X-RIME的输出结果进行整合,生成易于理解的文档。
下面我们来介绍下使用X-RIME对某BBS中一个分论坛进行弱连通分支(Weakly Connected Components,后面简称WCC)算法分析的结果。在BBS中,每一个帖子的发起者A是一个节点,而如果另一个用户B回复了这个帖子,我们说这两个用户间形成了一个关系,即B指向了A。
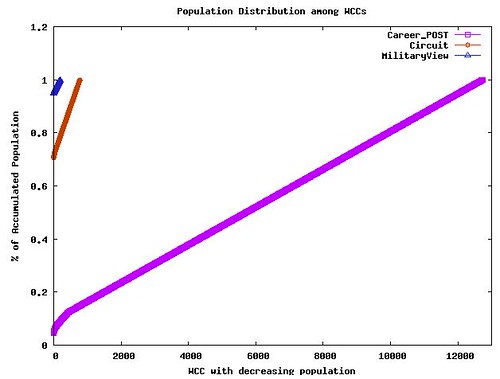
图5. 弱连通分布
图5中的蓝红紫三条线分别代表该BBS中MilitaryView版, Circuit版和Career_POST版的WCC分布情况。从图中我们可以看到,MilitaryView版和Circuit版中大部分的用户的WCC值都很高。这说明这两个版块中的大部分用户彼此都直接或者间接的联系在一起。相反的,Career_POST版中大部分的用户彼此间的联系都非常松散。其实这个结果非常易于理解,因为MilitaryView和Circuit版是专门的版块,在这个版块的用户大都是基于相同的兴趣而产生的发帖、回帖行为,因此彼此间的互动更频繁、联系更紧密;相对的,Career_POST版主要被用于发布和浏览招聘信息,因此用户的回帖行为不多,用户间的关联性不强。
4. 总结
X-RIME作为基于Hadoop的开源工具,为大家提供了一种方便快捷地进行大规模社交网络分析的新选择。如果您对X-RIME有什么新的需求或者建议,欢迎您直接与我们联系:chengc@cn.ibm.com。
参考文献
[1] X-RIME Homepage: http://xrime.sourceforge.net/
[2] Wei Xue, JuWei Shi, Bo Yang. X-RIME: Cloud-Based Large Scale Social Network Analysis. Proceedings of 2010 IEEE International Conference on Services Computing.
[3] Kai Shuang, Yin Yang, Bin Cai, Zhe Xiang. X-RIME: HADOOP-BASED LARGE-SCALE SOCIAL NETWORK ANALYSIS. Proceedings of IC-BNMT2010.
[4] 杨寅.大规模社会网络分析数据模型的设计与实现. 中国科技论文在线.