分类算法评估矩阵
(1)分类准确度
(2)对数损失函数log_loss()
(3)混淆矩阵confusion_matrix()
(4)AUC图-----一般在排序(rank)时用AUC图比准确率、召回率、f1值要好
(5)分类报告classification_report()
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
# print(iris.keys())#dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names', 'filename'])
from sklearn.model_selection import train_test_split
features = iris['data']
labels = iris['target']
from sklearn.metrics import confusion_matrix
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score,KFold
kfold = KFold(n_splits=10,random_state=4)
model = LogisticRegression()
scoring = 'neg_log_loss'
result = cross_val_score(model,features,labels,scoring = scoring,cv=kfold)
print('Logloss:%.3f(%.3f)'%(result.mean(),result.std()))
7.1 分类模型评估
1、二分类
混淆矩阵:confusion_matrix()

混淆矩阵特别适用于监督学习,用要用于分类结果和预测值的比较。
混淆矩阵中对角线的元素代表正确分类的数量;
非对角线元素代表错误分类的数量。
所以最为理想的模型(拿测试集来看),应该是一个对角阵。若无法得到对角阵,对角线上的数字之和如果占统治地位也是可以的。


片面的追求查准率可能会降低召回率

2、多分类


recall参数中的average()的取值:
binary表示二分类
micro表示多元混淆矩阵中的第一种方法
macro表示的是一种不加权的平均
weighted表示加权的平均
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
# print(iris.keys())#dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names', 'filename'])
from sklearn.model_selection import train_test_split
features = iris['data']
labels = iris['target']
print(iris['target_names'])
# #得到验证集,占比20%
# X_tt,X_validation,Y_tt,Y_validation= train_test_split(features,labels,test_size=0.2)
#得到测试集,占比20%
X_train,X_test,Y_train,Y_test = train_test_split(features,labels,test_size=0.33)
print('train:',len(X_train),'
','test',len(X_test))
from sklearn.metrics import confusion_matrix
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X_train,Y_train)
predicted = model.predict(X_test)
matrix = confusion_matrix(Y_test,predicted)
classes = ['setosa','versicolor','virginica']
dataframe = pd.DataFrame(data=matrix,index=classes,columns=classes)
print(dataframe)
'''
setosa versicolor virginica
setosa 13 0 0
versicolor 0 15 3
virginica 0 0 19
''
3、 反应分类效果的图及ROC曲线阈值的选取
(1)ROC、AUC

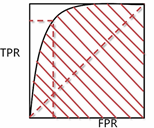
选取标准:让TPR(召回率)尽可能的大,FPR(错误接受率)尽可能的小,所以选取其拐点
AUC表示的是ROC曲线下的面积,可以直接反应ROC曲线像左上方靠近的程度。
如何做ROC曲线?
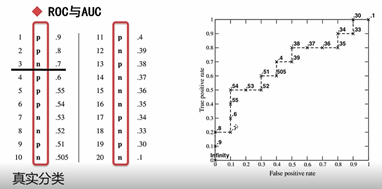
xy_lst = [(X_train, Y_train), (X_validation, Y_validation), (X_test, Y_test)]
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve,auc,roc_auc_score
f = plt.figure()
for i in range(len(xy_lst)):
X_part = xy_lst[i][0]
Y_part = xy_lst[i][1]
Y_pred = mdl.predict(X_part)
# Y_pred = mdl.predict_classes(X_part)#用predict()时输出的是连续值,使用predict_classes()时输出的是分类标注
# print(i)
print(Y_pred)
Y_pred = np.array(Y_pred[:,1]).reshape((1,-1))[0]
# from sklearn.metrics import accuracy_score, recall_score, f1_score
# print(i, '---:', 'Nural Network', '准确率:', accuracy_score(Y_part, Y_pred),
# '召回率:', recall_score(Y_part, Y_pred),
# 'F1分数:', f1_score(Y_part, Y_pred))
f.add_subplot(1,3,i+1)
fpr,tpr,thresholds = roc_curve(Y_part,Y_pred)
plt.plot(fpr,tpr)
plt.shaow()
#这两个函数功能一样
print('Nural Network','AUC',auc(fpr,tpr))
print('Nural Network','AUC Score',roc_auc_score(Y_part,Y_pred))
'''
Nural Network AUC 0.9610879734019506
Nural Network AUC Score 0.9610879734019506
Nural Network AUC 0.961721658936862
Nural Network AUC Score 0.961721658936862
Nural Network AUC 0.9637020039792525
Nural Network AUC Score 0.9637020039792525
'''

(2)增益图与KS图

其中KS图中关注的是,TPR曲线与FPR曲线的差距,这个差距反映了对正类样本的区分度。
7.2 回归模型评估
平均绝对误差:MAE
均方根误差:MSE
决定系数:R2------若R2越大,表示通过回归关系,自变量对因变量的解释程度越高。若=0.8,则表示回归关系可以解释因变量80%的变异。

用的较多的是MSE
from sklearn.metrics import mean_squared_error,mean_absolute_error,r2_score
print('MSE:',mean_squared_error(label.values,Y_pred))
print('RMAE:', np.sqrt(mean_squared_error(label.values, Y_pred)))
print('MAE:', mean_squared_error(label.values, Y_pred))
print('R2:', r2_score(label.values, Y_pred))
'''
Coef: [0.27156879 0.26782676]
MSE: 0.059538252102813126
RMAE: 0.2440046149211386
MAE: 0.059538252102813126
R2: 0.16759592760720865
'''
7.2 非监督模型评估
7.2.1 聚类模型评估

方法:
(1) RMS
RMS的值越大表示每个类距离这个类的中心的距离越远,所以RMS的值越小证明聚类效果越好。
(2)轮廓系数
轮廓系数越趋近于1,效果越好,所以b(i)要尽可能大,a(i)要尽可能小
#silhouette_score是轮廓系数的包
from sklearn.metrics import silhouette_score
try:
print(clt_name,i,silhouette_score(X,clt_res))
except:
pass
'''
Kmeans 0 0.390739091845987
Kmeans 1 0.42898184841340414
Kmeans 2 0.8260921886020176
Kmeans 3 0.3759997153149254
DBSCAN 0 0.11333211124678177
DBSCAN 1 0.33401193078310676
DBSCAN 2 0.8260921886020176
Agglomerative 0 0.34520063433620435
Agglomerative 1 0.42223257086171395
Agglomerative 2 0.8260921886020176
Agglomerative 3 0.33587365431949173
'''
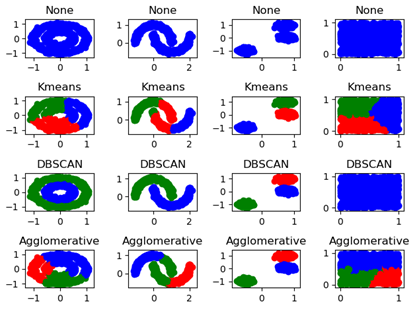
由此证明,在该场景下,KMeans的效果是最好的。
7.2.2 关联模型评估
支持度:可找到最大的频繁项集
置信度:组合之间的关系,一个项集对另一个项集是否有着比较强的决定关系
提升度:由置信度计算出,一个项集对另一个项集是否有提升作用