0、python中append和extend的区别
append()和extend()都是列表中的方法,可参考另一篇博客【列表基础用法说明】;
append()和extend()都可以增加列表元素,但是extend()添加的元素必须是可迭代的。
看例子吧!!!
>>> list =[1,2] >>> list.append(3) >>> list [1, 2, 3] #由于4不可迭代,将会报错 >>> list.extend(4) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'int' object is not iterable #此时添加的是一个列表,故可以添加成功 >>> list.extend([4]) >>> list [1, 2, 3, 4] #再试一次,还是ok的! >>> list.extend([4,'hjsk']) >>> list [1, 2, 3, 4, 4, 'hjsk']
1、pandas中如何去重
有两种方法:
- 使用duplicated()方法可以返回一个布尔型的Series,表示各行是否重复,然后使用布尔过滤即可去掉重复值;
- pandas提供了去重方法drop_duplicates(),默认全部列,也可以指定特定列。
具体可参考另一篇博文【Pandas数据初探索之缺失值处理与丢弃数据第3部分】
2、pandas中如何排序
Pandas排序中有多种方法:
- 根据索引排序(df.sort_index())
- 根据某一列的值进行排序(df.sort_values())
- 随机重排
具体可参考另一篇博文Pandas之排序
3、大数据量情况下,SQL中如何去重
http://www.itpub.net/thread-1896385-1-1.html
使用用分区表,按日分区,再按分区去重。每个分区按所有列(除)ID外分组取最小的ID,把得到的数据insert到一张新建的表中,再删除原表分区的数据(truncate 分区),再重新插回来分区即可。
create table t_new
select min(id) as id,
a1,a2,a3
from t
group by a1,a2,a3
rename t to t_old
rename t_new to t
4、pandas中两个DataFrame的连接成一个DataFrame
1、Pandas中将两个DataFrame连接成一个DataFrame使用pd.concat([df1,df2])--->此时需注意这些对象应该是列表形式进行传入
[具体可参考另一篇博文Pandas之数据合并与轴向连接]
2、Pandas中对于数据的融合,一般使用pd.merge()、df.join()、df.combine_first(),[具体可参考另一篇博文Pandas之数据融合]
与concat()的区别在于,concat()的重点在于连接两个DatFrame,而merge()、join()可对于索引或是列进行更为详细的操作;
concat()和join()都可以连接两个DataFrame,merge()更加侧重于两个DataFrame有无相同的列,要求有某些部分相似。
combine_first()则是可以使用一个DatFrame中的值对另一个DataFrame中的缺失值按照索引进行补齐。
| concat | 基于索引拼接,主要的是基于行的拼接 |
| join | 主要基于列的拼接 |
| combine_first | 基于索引进行缺失值补齐 |
3、Numpy中,对于数组的拼接,可使用concatenate()或是vstack()、hstack(),[具体可参考另一篇博文Numpy之concatenate()、vstack()、hstack()区别]
5、pandas中对于时间问题的操作
参考博客
(1)【Python中的日期与时间数据(介绍时序数据、datetime模块介绍、字符串与时间互换)】
(2)【Pandas时间序列处理的基础(时序数据类型、筛选、子集提取、重复时间索引操作)】
(3)【Pandas时序数据处理(日期范围pd.date_range()、频率(基础频率表)及移动(shift()、rollforward()、rollback()))】
(4)【Pandas时间序列处理之时区处理(UTC查看、获取、时区意识型TimeStamp对象、本地化与转换、计算)】
(5)【时序数据处理之日期(Period、PeriodIndex、asfreq、财政年度)及算数运算(to_timestamp()、to_period())】
(6)【Pandas时序数据处理之重采样与频率转换(升降采样、resample()、OHLC、groupby()重采样)】
6、数学建模的流程
7、K-Means、PCA原理
一、聚类和K-menas
(1)聚类
聚类的本质是将数据集中相似的样本分组的过程。
每个组成为一个簇,每个簇的样本对应一个潜在的类别,而这些簇满足两个条件:
- 相同的簇距离比较近
- 不同的簇距离比较远
(2)K-Means
单从理论上来说,K-Means是一种无监督学习的聚类方法,所有的样本没有样本标签。但是在实际工作中,一般会将扩展为半监督学习方法进行使用,给其中的一些样本人为的加上标签,通过聚类后来对其准备度进行计算能够更好的量化K-Means的性能。
K-Means是一种硬聚类算法,对K-Means模型的求解如下:




K-Means算法流程如下:
- 随机选取k个点作为初始中心
- 重复:
- 将每个样本指派到最近的中心,形成k个类
- 重新计算每个类的中心为该类样本均值
- 直至中心不再发生变化
二、PCA降维
关于降维方面的知识,日前笔者在抖音上发布一则视频,题目为《维度灾难》,若感兴趣可前去观看,抖音号名“夏小夏”,抖音号“361349323”;
至于具体的PCA算法,笔者在另一随笔分类《python3数据分析与挖掘》的《探索性数据分析(多因子与复合分析)的4.1.4 主成分分析(PCA)与奇异值分解(SVD)》中已详细说明。以后如有机会,将会更为详细的进行介绍。
8、决策树、集成模型、随机森林原理
一、决策树
(1)树的构成?
根节点、叶子节点、非叶子节点
(2)如何决策节点的选择(即如何切分左子树与右树)?
使用信息增益,即特征X使类Y的不确定减少的程度; (信息增益越大, 表明不确定性减少的程度越大,表明分类效果越好,说明节点选择越好)
信息增益的衡量标准是熵,
(3)决策树的算法
A: ID3------使用信息增益(存在一定问题, 具体见下)
若特征非常稀疏,特征非常多,但是每个属性中的样本非常少;
例如编号id,此时id的信息增益最大,但是却无分类意义。此时因为没有考虑自身熵;
B: C4.5----信息增益率(解决ID3的问题,考虑了自身熵)
C4.5在ID3的基础之上,考虑了自身熵;
信息增益率 = 信息增益/自身熵值 --------->以编号id为例,其自身熵值本就很大;
C: CART----使用Gini系数作为衡量标准(用Gini系数来衡量DT中落在某一节点的不同类别的样本分布的不纯度)

当使用CART解决回归问题时,使用目标特征的方差作为不纯度的衡量标准,方差下降值作为节点分类的标准;
(4)决策树剪枝策略
A:预剪枝(相较于后剪枝而言,预剪枝较为实用,在sklearn中可以直接指定树的深度、叶子结点个数等进行指定来实现预剪枝)
在建立决策树之时,通过对参数进行控制,即树的深度(也称特征的个数)、叶子节点的个数、叶子节点的样本数、信息增益量,达到剪枝的目的。
B:后剪枝
在决策树建立完成后再根据一定的衡量标准对其进行剪枝,那么此处所说的一定衡量标准所指的什么,看下面的公式吧!!!

其中:C(T)表示当前的损失,即叶子节点样本数乘以该叶子节点的Gini值;
Tleaf 表示叶子节点的个数
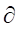 表示限制叶子节点个数的参数
表示限制叶子节点个数的参数
从上述可以看出,叶子结点个数越多,损失就会越大;
下面通过一简单例子对后剪枝进行说明:

二、集成算法
集成算法的目的:合成多个机器学习算法;
集成算法看分为三种:
A:Bagging-------其核心在于并行训练多个分类器,将最终的结果求平均值

Bagging典型的代表是随机森林,关于随机森林的介绍见下面第三部分;
Bagging可以用于回归和分类,分类以投票的形式确定最终分类器的结果,回归以求平均值的形式确定最终分类器的结果;
Bagging最大的特点在于:并行训练各个分类器,各个分类器都是相互独立的,互不影响。
B:Boosting---------其核心在与从弱分类器通过加权来加强效果,不同于Bagging的是,Boosting是串行的。
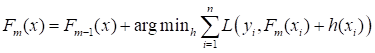
依次加入一棵树,每次的效果都比前一轮强!
Boosting的典型代表是Adaboost、XGBoost(在本篇博文后面会进行详细介绍,在随机森林后面,笔者懒癌不发会尽快写!)。
Adaboost比较关注分类数据的权重,会根据分类的效果来调整权重!
Adaboost在分类过程中的和核心在于:在本次的分类中错误,那么下次分类时会被赋予更大的权重,即更加关注被错误分类的样本!
Adaboost最后的结果是:每个分类器会根据自身的准确性来确定各自的权重,最终加权得到结果!
注意:有两个地方需要加权;第一:对误分类样本的权重设置较大;第二:确定Adaboost最终的分类结果时,每个分类器的权重会因为
C:Stacking---------核心思想在于聚合多个分类或回归模型
Stacking就是暴力的代表,而且简直就是来者不拒,简直可怕!!!
举个栗子吧!比如,现在有RF、LR、DT、XGBoost一堆分类器,Stacking就是把这一堆分类器堆叠得到结果;那具体如何堆叠呢?
Stacking是可以分阶段做的,一般分为以下两个阶段:
第一阶段:从各个分类器得出结果;
第二阶段:再构建一个分类器,使用第一阶段的结果作为特征进行训练。
注意:堆叠算法确实能够有效提升分类的准确性,毕竟堆叠了一堆分类器,总不能白用吧!但是有一个明显的缺点,速度堪忧!!!
若大家不那么关心计算速度,比较看中结果的准确性建议使用!
三、随机森林
开始介绍随机森林了!!!姐妹们,来吧!!
随机森林,显而易见,由随机和森林两部分组成,那么这两部分谁比较重要,分别代表什么含义呢?
随机:数据集采样随机,特征随机选择(是为二重随机性)
随机必须保证每棵树是有差异的,保证树的泛化能力,不然将失去意义;
森林:多个决策树(也就是大家平时所说的弱分类器,但是其实我不太赞成弱分类器这个名字,搞得好像人家好弱一样,其实每颗树都在发光发热,人家也是有尊严的)并行放在一起;
到现在你觉得谁更重要呢?当然是随机更重要!!!!
画个图来理解一下随机森林吧(emmm,当然不仅只有3个分类器,笔者为了方便只画了3个,大家可以自行脑补)!

那么随机森林有哪些优势呢?
A:能处理高维的数据,而且不用做特征选择(注意:也可以做特征选择,只是可以不用做而已)
B:能够得到Feature importance(具体怎么计算,大家可以参考sklearn的官网);
举个例子来评估一下某特征是否重要吧!假设现在有一些特征a,b,c,d,此时需要评估特征b是否重要,剩下请各位看官看图,字不好请见谅。

C:易做成并行化方法,速度快;
D:对特征的重要性容易进行可视化,便于分析;大家可以自行脑补一个条形图,将各个特征与其特征重要系数的展示;
四、XGBoost
......待补充!!
9、数据可视化常用包及其图形
请参见作者随笔分类《数据可视化》系列,先放一个链接引路吧!
【Pandas的基本绘图函数(常用参数表、图形类型、样式参数设置表、条形图、直方图、箱线图、散点图、气泡图、六边箱图、饼图)】
10、数据可视化中的分布问题
待补充
11、机器学习常见算法
之后会整理成一个完整的系列,暂时先放在这里吧!!.......
