昨天写的因为没有及时发布,又丢失了,现在重写一遍重点。
1. activation functions

1) 总结:一般都用ReLu,因为在x>0时,不会出现梯度消失
可以尝试Leakly ReLu ELU Maxout(参数加倍) tanh(0-centered)
不要用Sigmoid
2)Sigmoid: 3个缺点
1 当x太大或者太小时,函数切线斜率接近于0,在ChainRule,梯度传递时会出现梯度消失。
2 不是0-centered,会导致Loss收敛速度慢,特别是sigmoid输出值都是正数 [ 0,1 ],导致input总是 all postive or all negative,在梯度选择时候不会选择下图的蓝线,而是红线。(这点不是很懂)
3 exp() 函数 比较 compitational-expensive

3)tanh: 1pos 1neg
1 梯度消失
2 0-centered
4) ReLu 4pos 2neg
1 x>0时不会出现梯度消失
2 f(x) = max(0,x) computationally efficient
3 比 sigmoid tanh 收敛快6倍
4. 比sigmoid 更符合生物学原理
1 x<0时 梯度消失
2 不是0-centered
5) Leaky ReLu / PReLu /ELU / MAXOUT
在 x<0时 不会梯度消失
2. Data Preprocessing
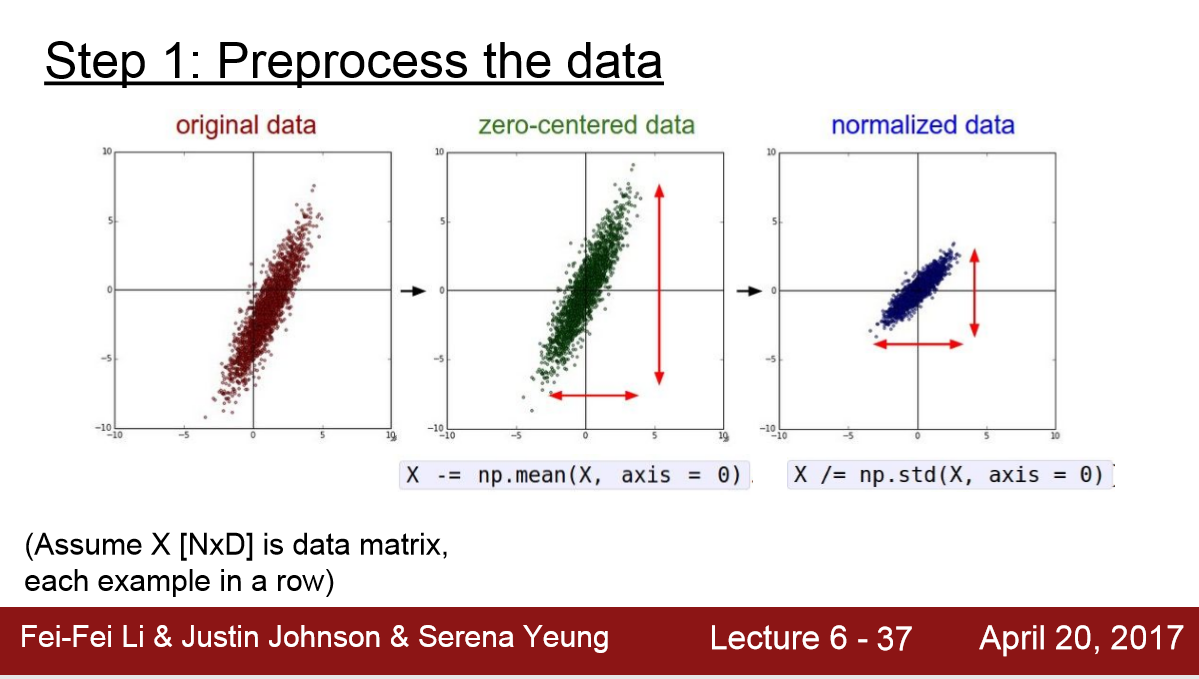
1) 在CV里一般只做 0-centered 不做 Normalization。因为对于image的像素点来说 取值都属于[ 0,255 ]
为什么要做0-center呢:
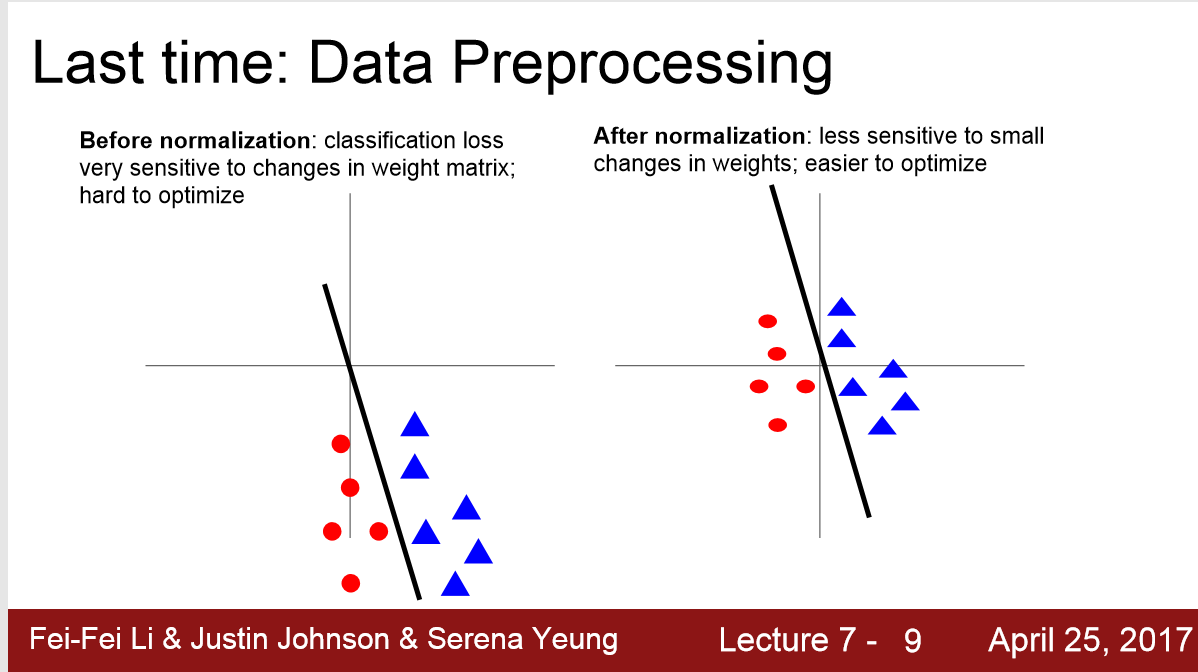
如下图,在做二分类时,斜率只要移动一点点,分类器就会失败,loss_function对参数向量或weight matrix非常敏感;
当我们0-center之后,loss_function会less sensitive to small changes in weight
2) 可以按整张图来做平均,也可以按RGB三通道来做平均,但是平均值是所有输入的像素平均

3.Weight Initialization
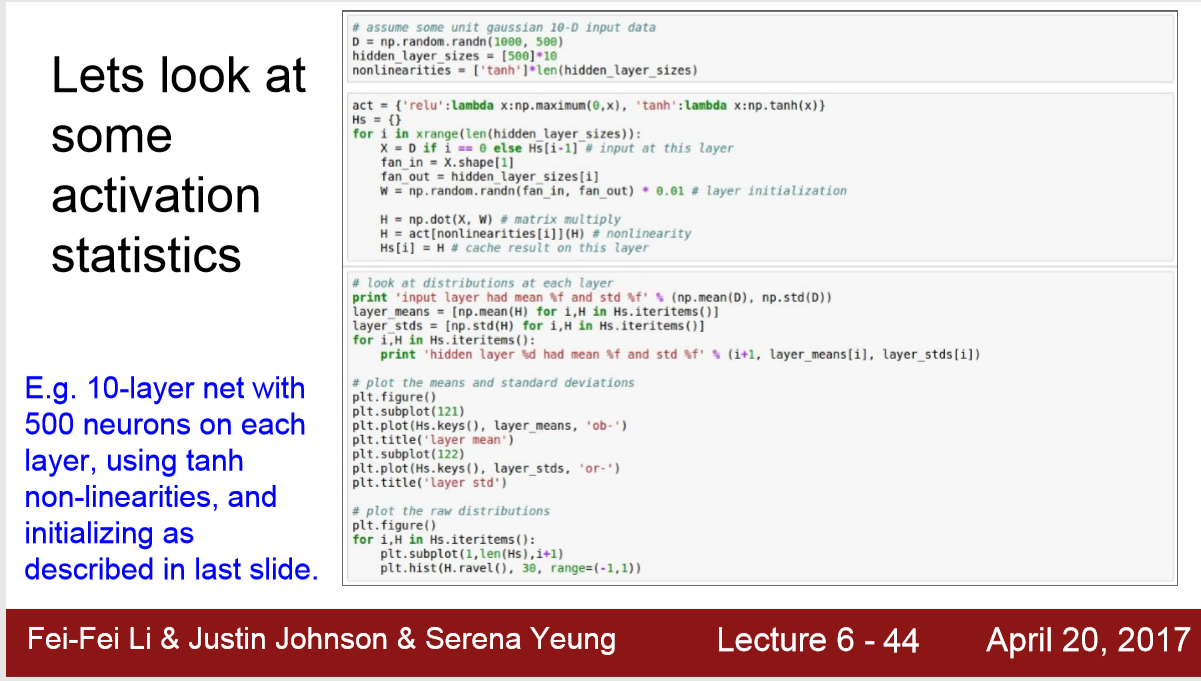
numpy.random.randn()可以生成高斯分布的数
如图所示,如果你用一个很小的初始权重,不断的用 0.01乘以输入值,那输出值会很快的趋近于0
同理,如果权重很大,输出值很快就会达到sigmoid或者tanh的饱和区
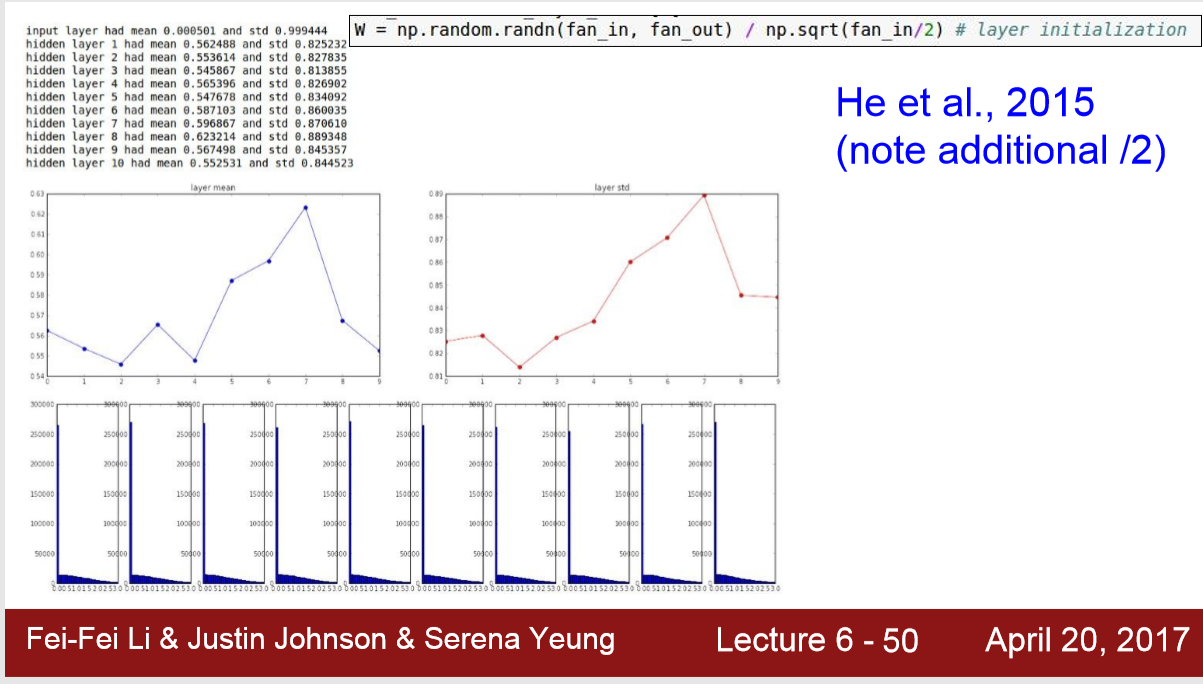
所以,应该设置 W = np.random.randn(in,out) / np.sqrt ( in / 2)

1)W = 0.01*np.random.randn(D,H)
1. 对 small networks可以, 对于deeper networks不太行

2)W = 1.0*np.random.randn(D,H)
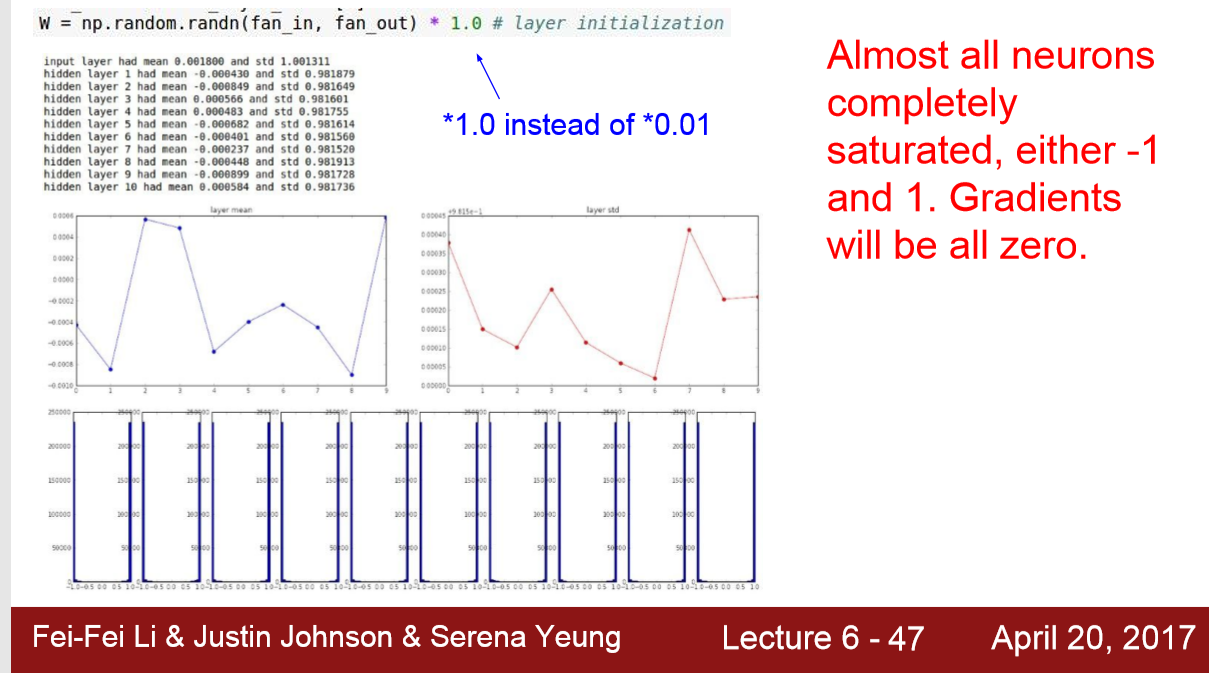
3) 需要 ‘/2’ 是因为ReLu在x<0初饱和,出现梯度消失
4.Batch Normalization


https://www.cnblogs.com/skyfsm/p/8453498.html
https://www.cnblogs.com/guoyaohua/p/8724433.html
1) 为什么用BN上面这篇文章讲的很好
1. 将每一层发生偏移或变动的输入值的分布,重新拉回到均值为0,方差为1的高斯分布里。
因为在比如sigmod,tanh激活函数里,发生偏移就意味着饱和度变大,梯度趋近于0,所以很难收敛,或收敛很慢;
但是拉回标准高斯分布对应的值,往往是激活函数里,梯度最大的地方,梯度下降就快。
2. IID独立同分布假设,就是假设训练数据和测试数据是满足相同分布的,这是通过训练数据获得的模型能够在测试集获得好的效果的一个基本保障。
2) BN一般用于标准CNN中
3) 在testing中运用BN时,使用的参数 mean variance 还是training时候的
5. Babysitting the Learning Process 监督训练,调整超参数
learning rate 一般在 [1e-5,1e-3]