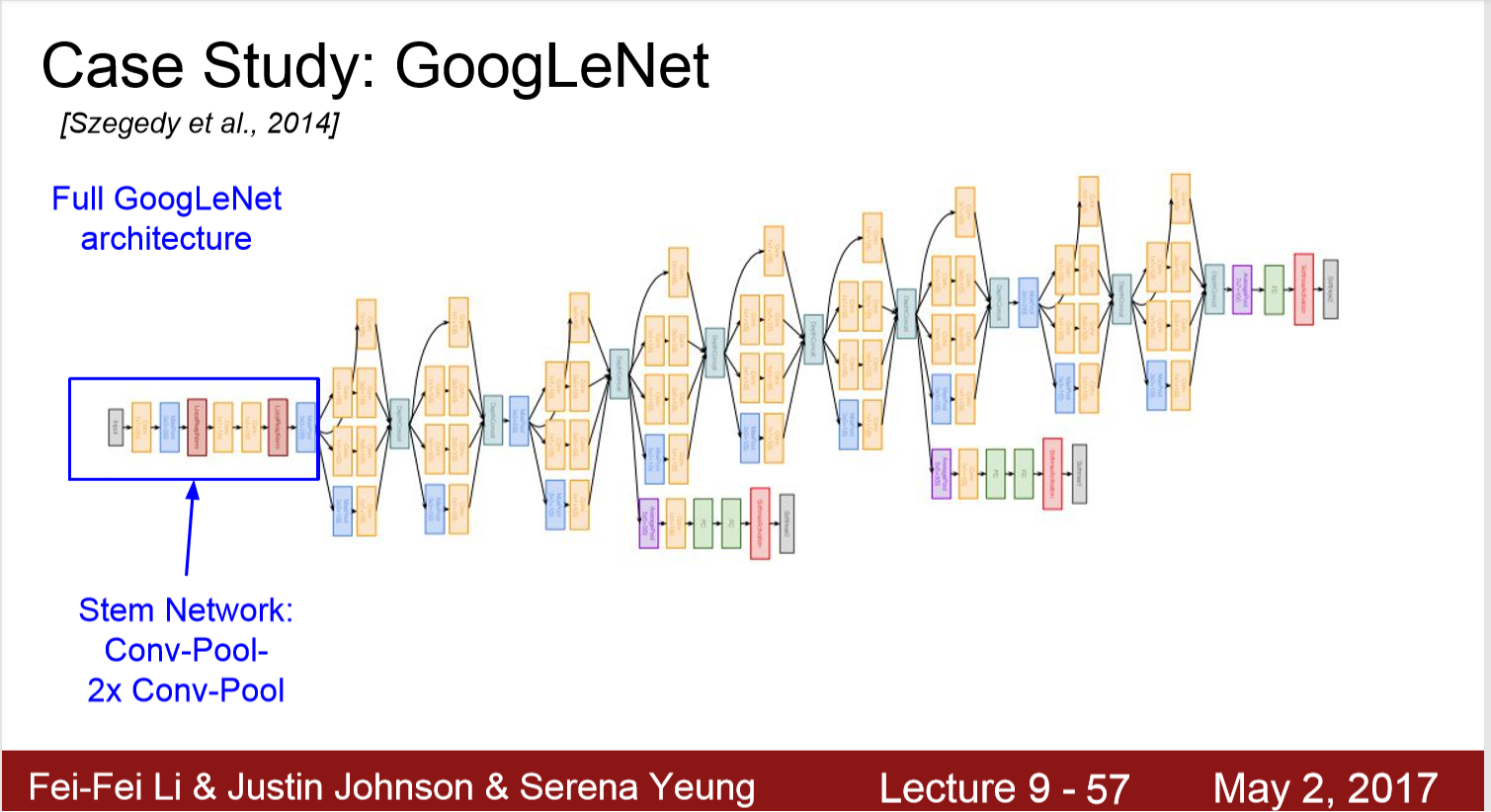
1. 22层神经网络,一层inception算两层
2. 使用了高效的inception结构
3.没有全连接层
4.只有5millon参数,比AlexNet的60M,VGG16的138M
Inception Module 的好处:
解释1:在直观感觉上在多个尺度上同时进行卷积,能提取到不同尺度的特征。特征更为丰富也意味着最后分类判断时更加准确。
解释2:利用稀疏矩阵分解成密集矩阵计算的原理来加快收敛速度。 传统的网络filter是只有3*3*depth,这样的输出会非常均匀,这可以理解成输出了一个稀疏分布的特征集;
而inception模块,采用多个卷积核(1*1,3*3,5*5),在不同尺度上提取特征,输出的256个特征就是相关性强的聚集在一起,’冗余‘信息较少,这样的数据集在bp收敛快。
解释3: fire togethter, wire together ,把相关性强的特征汇聚到一起。
观点来自博文https://www.cnblogs.com/leebxo/p/10315490.html

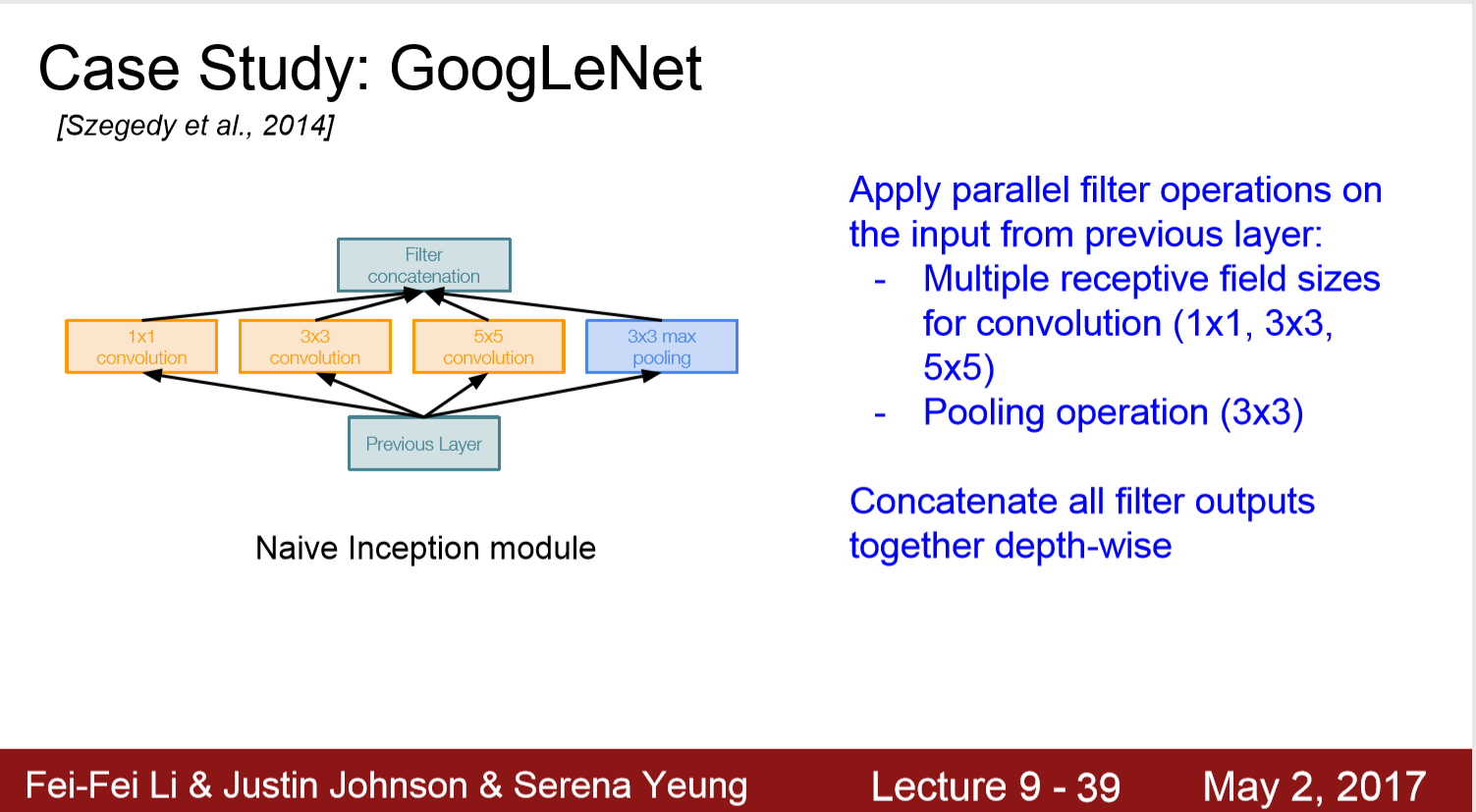
Inception Module:
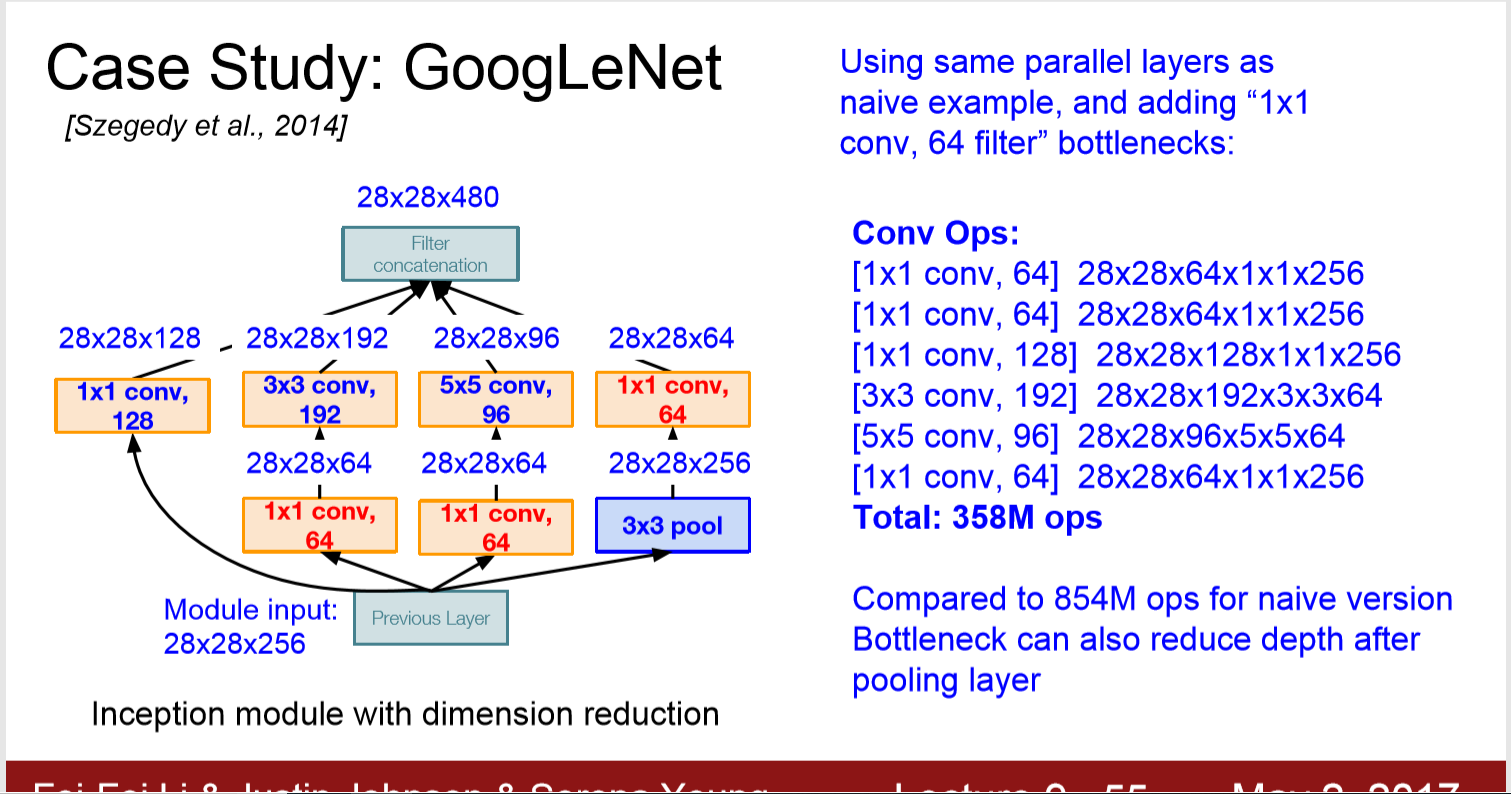
Naive Inception Module: 直接将三个卷积层与一个池化层的输出cat到一起
问题: 复杂度太高
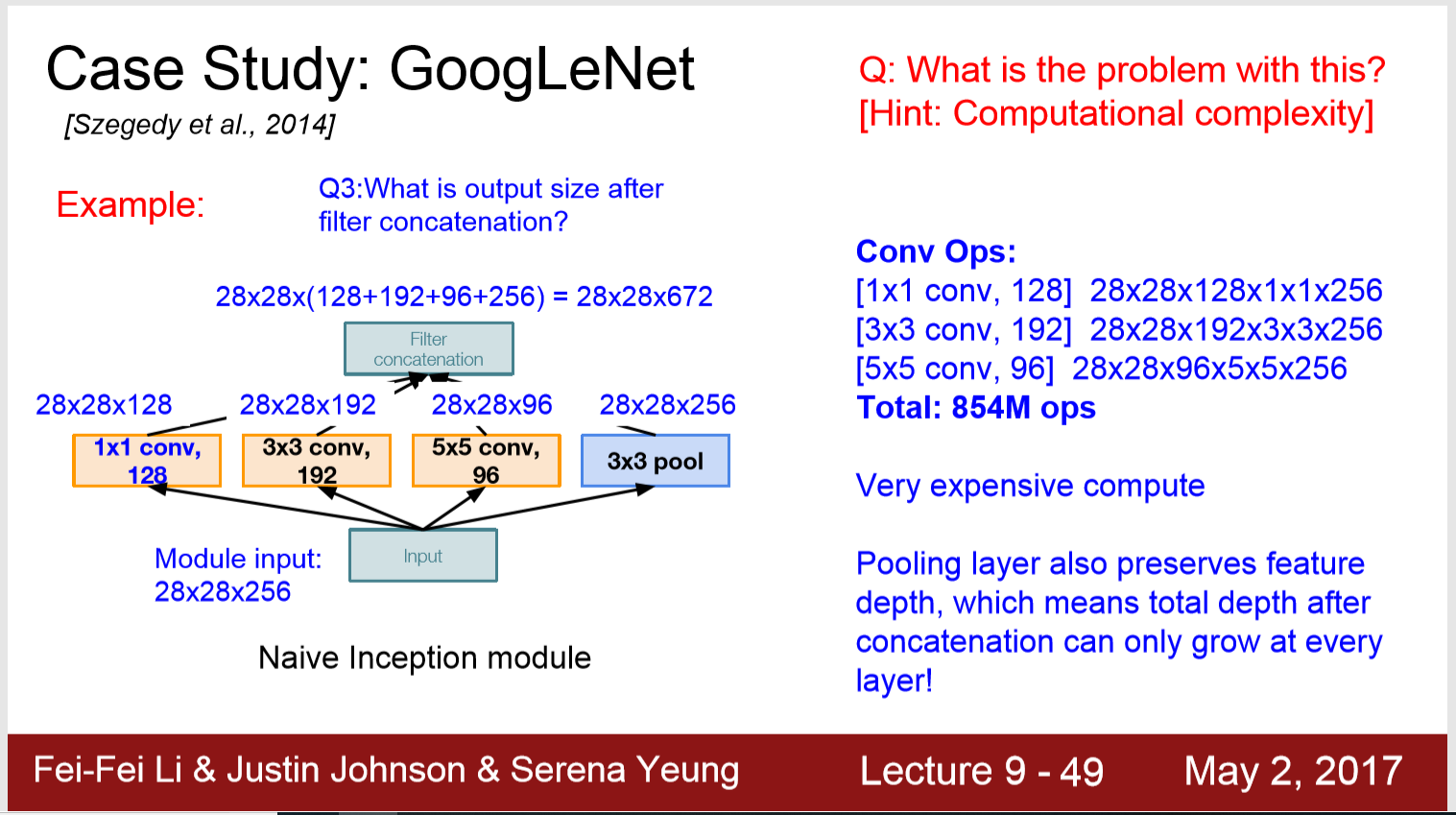
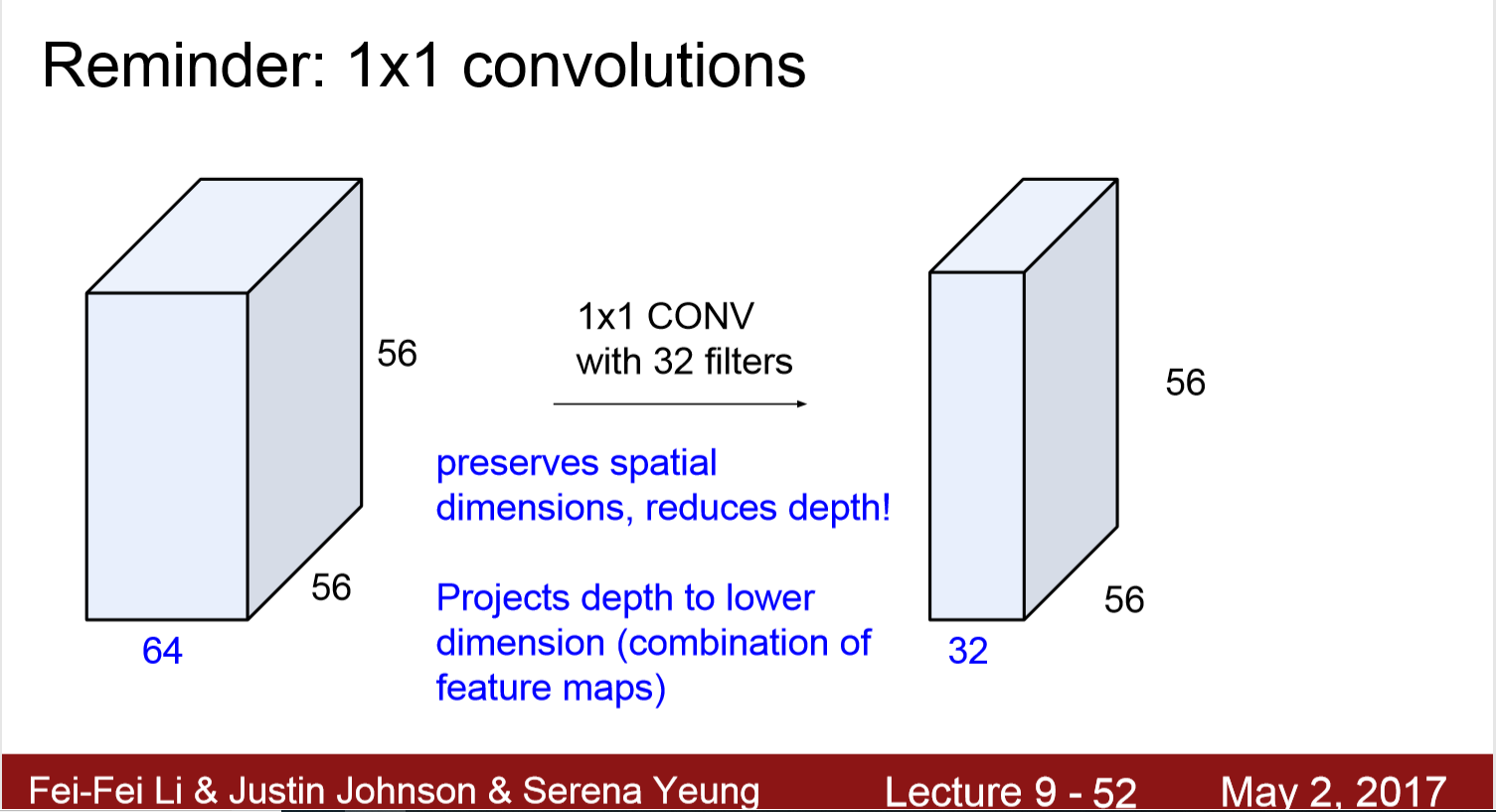
解决方法: “bottleneck” layers that use 1x1 convolutions to reduce feature depth, 将depth减半,操作就减少到原来的四分之一。
这帮助减小了一大半的计算量,加深了深度
作用1:在相同尺寸的感受野中叠加更多的卷积,能提取到更丰富的特征。这个观点来自于Network in Network(NIN, https://arxiv.org/pdf/1312.4400.pdf),图1里三个1x1卷积都起到了该作用。
这是因为每次卷积以后,都会有ReLu,这样会提取到更多非线性特征。
作用2: 减少了计算量/复杂度
额外有两个地方产生 辅助输出
AvgPool - > Conv -> FC -> FC -> Softmax -> 辅助输出
1. 辅助输出不是为了获得更好的分类性能,这是为了将额外的梯度直接注入网络下层的方法。 但是现在有了 Batch Normalization 就不太需要这些技巧来让模型收敛了。
