一、前言
HttpRunner3.X支持三种方式的参数化,参数名称的定义分为两种情况:
- 独立参数单独进行定义;
- 多个参数具有关联性的参数需要将其定义在一起,采用短横线(-)进行连接。
数据源指定支持三种方式:
- 列表:["张三", "李四", "王五"] —— 这种属于直接指定参数列表,该种方式最为简单易用,适合参数列表比较小的情况
- debugtalk.py的回调,${get_styleCode()} —— 调用 debugtalk.py 中自定义的函数生成参数列表:该种方式最为灵活,可通过自定义 Python 函数实现任意场景的数据驱动机制,当需要动态生成参数列表时也需要选择该种方式
- Parameterize类的回调,例如csv:${parameterize(account.csv)} ——注:这种适合数据量比较大的情况,后面会换一种方式实现
假如测试用例中定义了多个参数,那么测试用例在运行时会对参数进行笛卡尔积组合,覆盖所有参数组合情况。
如果使用过pytest的参数化的小伙伴一定不会陌生,@pytest.mark.parametrize()会先将param作为一个动态参数,传递给param,然后由httprunner在进行参数化,httprunner在pytest的parametrize上封装了一层,增加了csv及debugtalk.py参数化的支持。
二、源码介绍Parameters 中的使用方法
def parse_parameters(parameters: Dict,) -> List[Dict]: """ parse parameters and generate cartesian product. Args: parameters (Dict) parameters: parameter name and value mapping parameter value may be in three types: (1) data list, e.g. ["iOS/10.1", "iOS/10.2", "iOS/10.3"] (2) call built-in parameterize function, "${parameterize(account.csv)}" (3) call custom function in debugtalk.py, "${gen_app_version()}" Returns: list: cartesian product list Examples: >>> parameters = { "user_agent": ["iOS/10.1", "iOS/10.2", "iOS/10.3"], "username-password": "${parameterize(account.csv)}", "app_version": "${gen_app_version()}", } >>> parse_parameters(parameters) """ parsed_parameters_list: List[List[Dict]] = []
三、实例讲解
1、前置工作
1)httprunner3.x中的参数化需要引入pytest和处理参数化的函数
import pytest from httprunner import Parameters
2)选取某个查询接口作为例子
POST https://xxx.mand/contract/page
{
"styleCode": "",
"purchaserNameLike": "",
"status": "",
"pageNum": 1,
"pageSize": 20,
}
2、第一种列表:笛卡尔积组合
2个入参进行了参数化,以下示例,运行后得到的用例执行次数是2*3,如图1所示,
# NOTE: Generated By HttpRunner v3.1.5 # FROM: harsearch.har # 参数化驱动 import self as self from httprunner import HttpRunner, Config, Step, RunRequest, RunTestCase,Parameters import pytest from config.ExcelUtiltest import ParseExcel class TestCaseSearch(HttpRunner): @pytest.mark.parametrize("param", Parameters({"styleCode": ['S21001061', 'S21000597'],"purchaserNameLike":['测试','南京公司','测试2']})) def test_start(self, param): super().test_start(param) config = Config("参数化搜索").verify(False) teststeps = [ Step( RunRequest("搜索接口") .post("https://xxx.mand/web/v1/contract/page") .with_headers( **{ "Connection": "keep-alive", "Content-Length": "249", } ) .with_json( { "styleCode": "$styleCode", "purchaserNameLike": "$purchaserNameLike", "status": "", "pageNum": 1, "pageSize": 20, } ) .validate() .assert_equal("status_code", 200) .assert_equal('headers."Content-Type"', "application/json") .assert_equal("body.successful", True) .assert_equal("body.code", "200") .assert_equal("body.message", "请求成功") ), ] if __name__ == "__main__": TestCaseSearch().test_start()
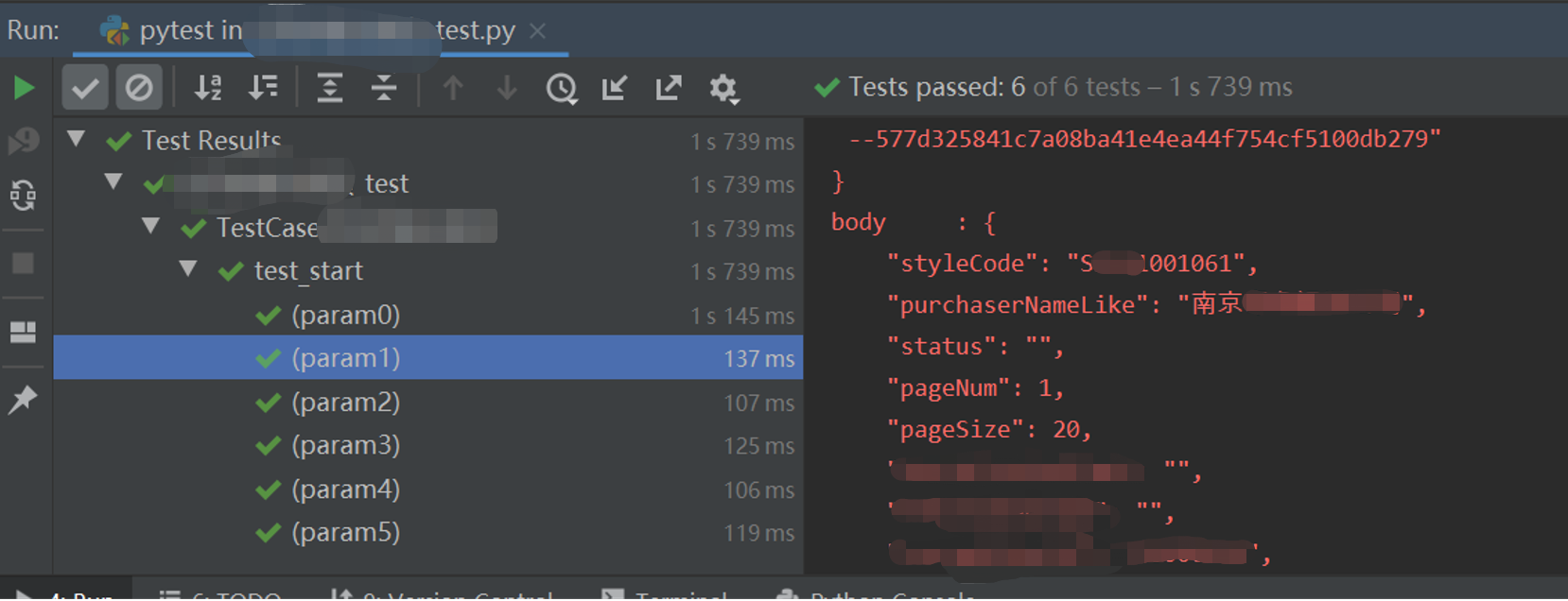
图1:笛卡尔积组合 即n*m
3、第二种debugtalk.py的回调函数
在debugtalk.py中定义一个函数,返回列表
def get_styleCode(): return [ {'styleCode':'S21001217'}, {'styleCode': 'S21001211'}, ]
在searchdriver_test.py文件调用,运行后的结果如图2所示,
# NOTE: Generated By HttpRunner v3.1.5 # FROM: harsearch.har # 参数化驱动 import self as self from httprunner import HttpRunner, Config, Step, RunRequest, RunTestCase,Parameters import pytest from config.ExcelUtiltest import ParseExcel class TestCaseSearch(HttpRunner): @pytest.mark.parametrize("param",Parameters({'styleCode':'${get_styleCode()}'})) def test_start(self, param): super().test_start(param) config = Config("参数化搜索").verify(False) teststeps = [ Step( RunRequest("搜索接口") .post("https://xxx.mand/web/v1/contract/page") .with_headers( **{ "Connection": "keep-alive", "Content-Length": "249", } ) .with_json( { "styleCode": "$styleCode", "purchaserNameLike": "", "status": "", "pageNum": 1, "pageSize": 20, } ) .validate() .assert_equal("status_code", 200) .assert_equal('headers."Content-Type"', "application/json") .assert_equal("body.successful", True) .assert_equal("body.code", "200") .assert_equal("body.message", "请求成功") ), ] if __name__ == "__main__": TestCaseSearch().test_start()

图2:调用debugtalk
4、第三种excel文件作为参数化输入
1)根据网上查的资料,httprunner3.x可以用.csv作为数据源,写法如下,.csv如图3所示,
csv的路径要使用相对路径,不支持绝对路径不支持\符号的路径,csv映射的时候,参数名要以“-”分割,name和pwd使用的-进行分割
疑问点:我在用这种方式时,会提示参数类型不正确,想不明白为什么别人可以运行成功呢,哈哈哈
@pytest.mark.parametrize("param",Parameters({"styleCode-purchaserNameLike": "${parameterize(testdatastyleCode.csv)}"})) def test_start(self, param): super().test_start(param)

图3:.csv文件
2)踩了坑后,经过别人的指点下(这个装饰器只接收list类型的),所以决定写个读取excel的方法,并转换成list,然后用例直接调用即可
在config文件下新建ExcelUtiltest.py(excel封装参考https://www.cnblogs.com/du-hong/p/10892379.html)
#封装解析excel的方法 from openpyxl import load_workbook class ParseExcel: def __init__(self,excelPath,sheetName): # 将要读取excel加载到内存 self.wb=load_workbook(excelPath) # 通过工作表名获取一个工作表对象 #self.sheet=self.wb.get_sheet_by_name(sheetName) self.sheet = self.wb[sheetName] # 获取工作表中存在数据的区域最大行号 self.maxRowNum=self.sheet.max_row def getDatasFromSheet(self): # 存放从表中取出的数据 datalist=[] for line in list(self.sheet.rows)[1:]: # 遍历工作表中数据区域每一行 tmplist=[] tmplist.append(line[1].value) tmplist.append(line[2].value) datalist.append(tmplist) print(datalist) return datalist '''if __name__ == '__main__': #excelPath = 'E:\03UI test\UnittestProject\TestData\search_data_list.xlsx' excelPath = 'E:\05\api_test\testdata\styleCode.xlsx' sheetName=u'Sheet1' pe = ParseExcel(excelPath, sheetName) for i in pe.getDatasFromSheet(): print(i[0],i[1])'''
在用例文件searchdriver_test.py进行调用(这里直接用Parameters,如有多个参数,用横杠-),excel文件如图4所示,运行结果如图5所示
# NOTE: Generated By HttpRunner v3.1.5 # FROM: harsearch.har # 参数化驱动 import self as self from httprunner import HttpRunner, Config, Step, RunRequest, RunTestCase,Parameters import pytest from config.ExcelUtiltest import ParseExcel class TestCaseSearch(HttpRunner): data = ParseExcel('E:\05\api_test\testdata\styleCode.xlsx','Sheet1') datalist = data.getDatasFromSheet() #下面是为了方便理解,直接指定的list数据 #@pytest.mark.parametrize('param',Parameters({'styleCode-purchaserNameLike':[['S21001170','南京公司'],['S21001213','南京公司']]}),) @pytest.mark.parametrize('param', Parameters({'styleCode-purchaserNameLike': datalist}), ) def test_start(self, param): super().test_start(param) config = Config("参数化搜索").verify(False) teststeps = [ Step( RunRequest("查询接口") .post("https://xxx.mand/web/v1/contract/page") .with_headers( **{ "Connection": "keep-alive", } ) .with_json( { "styleCode": "$styleCode", "purchaserNameLike": "$purchaserNameLike", "status": "", "pageNum": 1, "pageSize": 20, } ) .validate() .assert_equal("status_code", 200) .assert_equal('headers."Content-Type"', "application/json") .assert_equal("body.successful", True) .assert_equal("body.code", "200") .assert_equal("body.message", "请求成功") ), ] if __name__ == "__main__": TestCaseSearch().test_start()

图4:excel文件数据
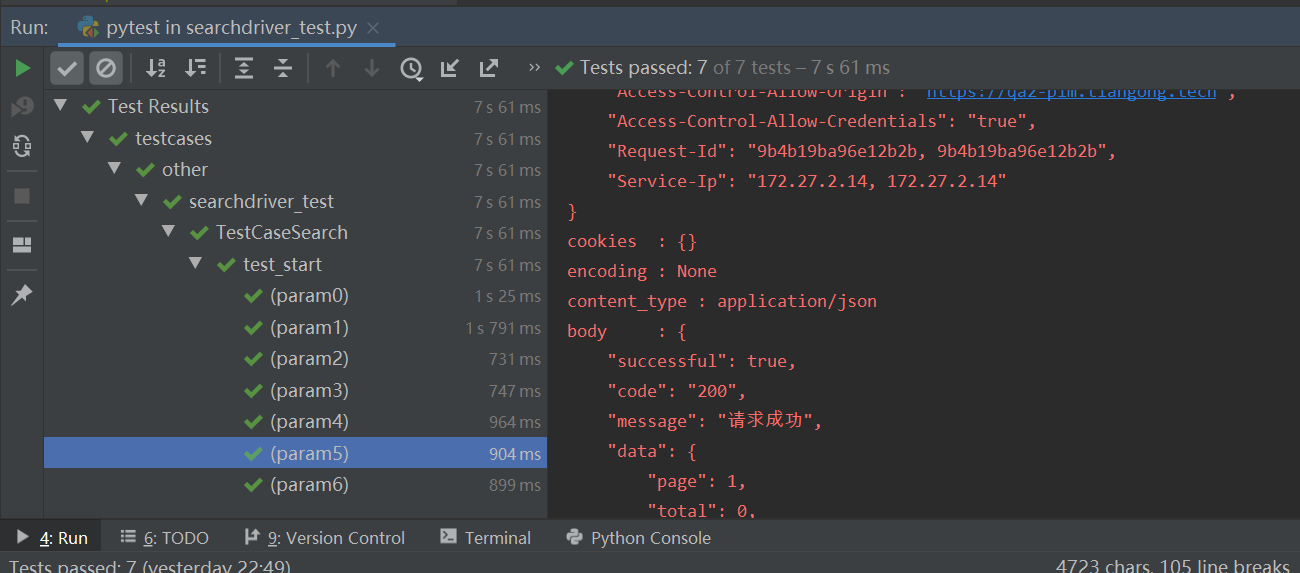
图5:excel参数化运行结果
5、补充附上写入excel的方法
#封装excel的方法 from openpyxl import load_workbook import openpyxl class ParseExcel: def __init__(self,excelPath,sheetName): # 将要读取excel加载到内存 self.wb=load_workbook(excelPath) # 通过工作表名获取一个工作表对象 #self.sheet=self.wb.get_sheet_by_name(sheetName) self.sheet = self.wb[sheetName] # 获取工作表中存在数据的区域最大行号 self.maxRowNum=self.sheet.max_row '''读取excel的函数''' def getDatasFromSheet(self): # 存放从表中取出的数据 datalist=[] for line in list(self.sheet.rows)[1:]: # 遍历工作表中数据区域每一行 tmplist=[] tmplist.append(line[1].value) tmplist.append(line[2].value) tmplist.append(line[3].value) #有多少列,这里就加多少 datalist.append(tmplist) print(datalist) return datalist '''往excel写入数据''' def op_toExcel(data, fileName): # openpyxl库储存数据到excel workbook = openpyxl.load_workbook(fileName) #打开指定excel文件 worksheet = workbook['Sheet1'] # 选定一个worksheet ''' worksheet.cell(row=2,column=4,value="test") # 第一种写法:指定行列值 worksheet['F2'] = "test2" # 第二种写法:指定单元格 print(worksheet['F2'].value) # 把内容读取出来 ''' worksheet.append(['id', 'hotel', 'price']) # 添加表头 for i in range(len(data[0])): d = data[i]['id'], data[i]['name'], data[i]['price'] worksheet.append(d) # 每次写入一行 workbook.save(fileName) # 数据用例 testdata = [ {'id':1,'name':'张三','price':100}, {'id':2,'name':'李四','price':200}, {'id':3,'name':'王五','price':300}, ] fileName='E:\05Zapi_test\testdata\toExcel.xlsx' ParseExcel.op_toExcel(testdata,fileName) ''' # 执行打印读取的excel内容 if __name__ == '__main__': #excelPath = 'E:\03UI test\UnittestProject\TestData\search_data_list.xlsx' excelPath = 'E:\05\api_test\testdata\styleCode.xlsx' sheetName=u'Sheet1' pe = ParseExcel(excelPath, sheetName) for i in pe.getDatasFromSheet(): print(i[0],i[1]) '''