本次作业要求来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3223
1、安装linux
VMware下载安装
VMware的下载安装就好办了,下载直接百度如下,哈哈:
下载完成即可安装,安装可以全部采取默认,看个人而定,博主的安装目录是自选的。
安装完成之后启动VMware,需要输入产品密钥(vmware workstation 12),博主随便百度了一个,猿友看你的是否有效:
5A02H-AU243-TZJ49-GTC7K-3C61N- 1
- 1
VMware安装完毕,下面介绍在VMware安装Ubuntu。
三、在VMware安装Ubuntu
1、创建虚拟机
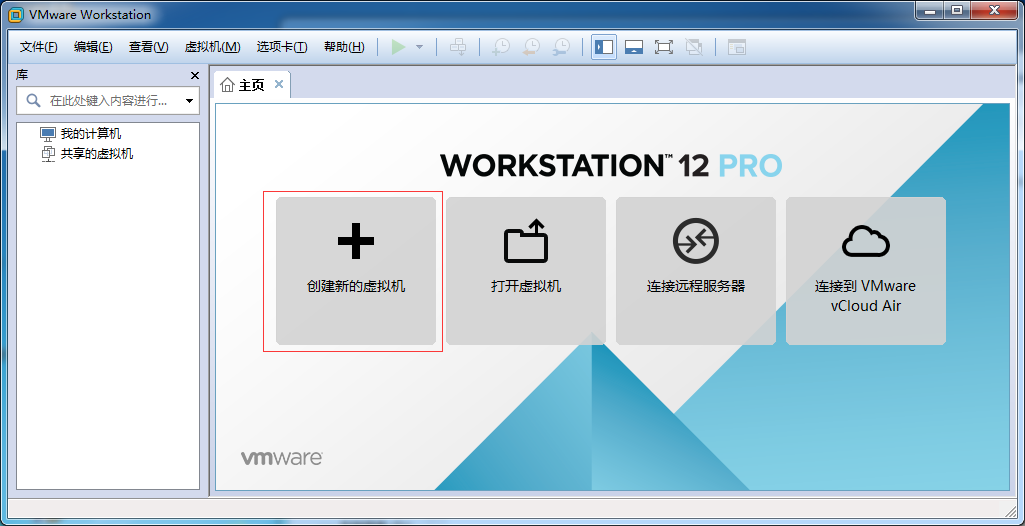
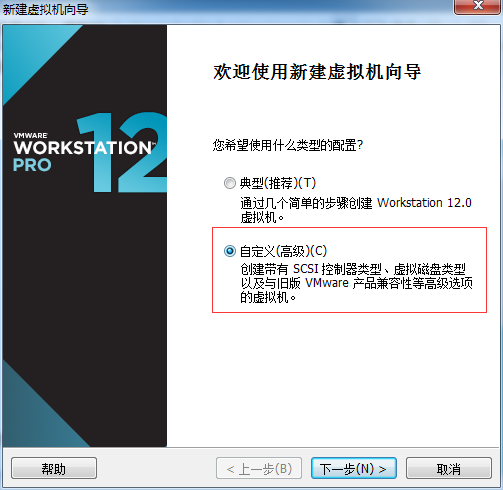
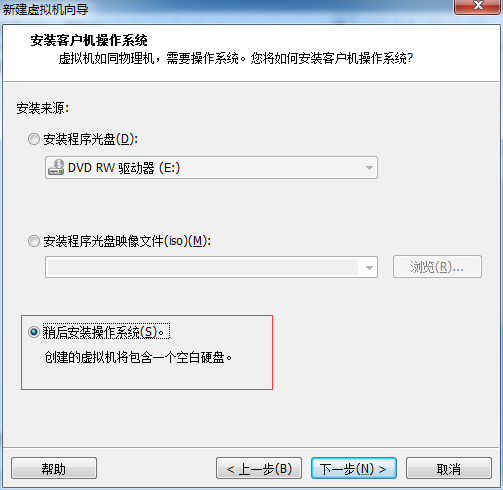
18、下面就开始正式安装了:
19、安装完成之后,会提示重启,点击现在重启
20、重启成功之后,会来到桌面,博主的重启中遇到一些问题,手动重启的,影响不大:
2、安装mysql
安装mysql
tar -xvzf mysql-5.6.38-linux-glibc2.12-i686.tar.gz
mv mysql-5.6.38-linux-glibc2.12-i686/ mysql
-
执行命令:groupadd mysql和useradd -r -g mysql mysql
- 创建mysql数据目录,新目录不存在则创建
数据库数据默认目录datadir=/var/lib/mysql,可通过vim /etc/my.cnf 查看

修改后的目录是 mkdir -p data,没有创建文件夹,有不创建
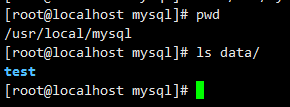
- 修改目录权限
chown -R mysql:mysql ./
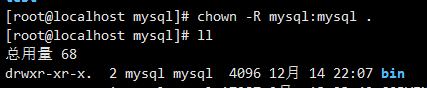
- 初始化数据库
./scripts/mysql_install_db --user=mysql --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data
- 修改权限为root
[root@localhost mysql]# chown -R root:root .
[root@localhost mysql]# chown -R mysql:mysql data
- 添加启动服务
-
[root@localhost mysql]# cp support-files/mysql.server /etc/init.d/mysql
- [root@localhost mysql]# service mysql start

- 设置root用户密码
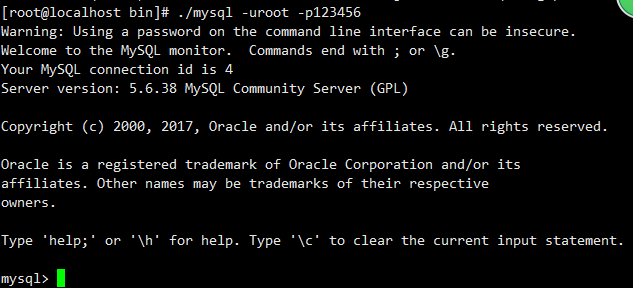
- ./bin/mysqladmin -u root password '123456'
- 遇到的问题
[root@localhost bin]# ./mysql
ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: NO)
- 解决方法
- [root@localhost bin]# ./mysqld_safe --user=mysql --skip-grant-tables --skip-networking &
-
[root@localhost bin]# ./mysql -u root mysql
- mysql> UPDATE user SET Password=PASSWORD('123456') where USER='root';
- mysql> FLUSH PRIVILEGES;
-
mysql> quit
3、计算机和虚拟机互传文件
Windows向Linux虚拟机传入文件:
下载,安装一个xshell远程软件,或其他ssh软件也行。连接上linux服务器。(例如:SecureCRT)
输入命令检查rz命令:rpm -qa |grep rz
(如果没有rz命令安装:yum -install rz)
输入rz就可以上传Windows里的文件了
Linux虚拟机向windows传入文件:
下载,安装一个xshell远程软件,或其他ssh软件也行。连接上linux服务器。(例如:SecureCRT)
输入命令检查sz命令:rpm -qa |grep sz
(如果没有sz命令安装:yum -install sz)
输入sz就可以下载到Windows中了(如果没有弹框选择下载地址,默认下载到:C:/用户/sks/下载)
4、使用VMWare安装Ubuntu
我用的是Ubuntu 12,先准备好一些软件/工具(链接均为新浪微盘)。
· VMWare Workstation (去官网免费下)
· ubuntu-12.04.1-desktop-i386.iso
· 因老师再三强调hadoop不同版本间的差异大,新手最好与老师使用相同版本的hadoop,即 hadoop-0.20.2.tar.gz
· WinSCP (我用到的) , PuTTY或SecureCRT 以将jdk, hadoop传送到ubuntu
安装Ubuntu
基本没有任何可以注明的,安装完成后我的是默认进入命令行模式,startx进入GUI图形界面模式
Ubuntu可以调display分辨率使得GUI大小舒服点,搜索terminal可打开命令行工具,ctrl+alt+f1~f6,在命令行模式下alt + 左右键可切换不同桌面。
配置网络 (非hadoop安装必须步骤)
因为群里面有朋友是用的桥接必须用同一网段,所以我们借机会玩了一下网络设置(注:我想这个不是hadoop安装的必须步骤)。Ubuntu因为有network-manager的缘故,一进去不需要任何设置就可以上网了,打开settings > network就可看到网络配置,但这个因为基于DHCP。我通过sudo vi /etc/network/interfaces设置的IP,重启后又被network-manager改回去了,提到这两种方法是相互冲突的,里面有讲到如何处理这种情况,我直接粗爆的使用 sudo apt-get autoremove network-manager -- purge把它给卸载了。
autoremove : 'autoremove' removes all package that got automatically installed to satisfy, --purge option makes apt-get to remove config files
步骤:配置静态IP > DNS > host name > hosts
配置静态IP
在VM > settings > network中可以看出我使用的是VMWare默认的NAT方式

这三者的区别,有兴趣的可以搜索 “VMWare 桥接,NAT,Host Only的区别”。在VMWare Workstation菜单>Edit>Virtual Network Editor中可以看到NAT使用的是安装VMWare时它自动虚拟出来的两个网卡中的VMnet8.

点击NAT Settings可以看到

得到如下信息:
网关: 192.168.221.2
IP网段:192.168.221.128~254
子网掩码:255.255.255.0
:sudo vi /etc/network/interfaces
(关于vi/vim,见鸟哥的《鳥哥的 Linux 私房菜》中 vim 程式編輯器)
|
auto lo #localhost iface lo inet loopback #这一段配置的是localhost/127.0.0.1,可保留 #加上eth0, 网卡0的配置 auto eth0 iface eth9 inet static #静态ip address 192.168.221.130 netmask 255.255.255.0 gateway 192.168.221.2 dns-nameserver 192.168.221.2 8.8.8.8 #dns-search test.com 这个新学的,默认会自动给host加到.test.com |
重启网络
:sudo /etc/init.d/networking restart #重启后,才能establish eth0
:whereis ifup #...
:sudo /sbin/ifup eth0 #手动修改eth0后必须启用eth0才有效
:sudo /sbin/ifdown eth0
:sudo /etc/init.d/networking restart #再重启
:ifconfig #查看IP,显示eth0信息
#配置DNS
:sudo vi /etc/resolv.conf
加如下 google的公共DNS,
nameserver 192.168.221.2
nameserver 8.8.8.8
这个会被network-manager覆盖,所以后者要KO掉
:sudo apt-get autoremove network-manager –purge
#配置HOST
:sudo vi /etc/hosts
加上
192.168.221.130 h1
192.168.221.141 h2
192.168.221.142 h3
#配置host name
:whereis hostname
:sudo vi /etc/hostname
写上h1
运行
:sudo hostname h1
到现在网络就成功配置好了,非CLONE的话,就三台servers一路执行吧(手酸),/etc/hosts建议scp过去
为hadoop创建特定操作用户
为hadoop创建特定操作用户,之后集群节点服务器也需创建,以使得节点服务器间能够通过这些特定用户及其RSA公钥信息通过SSH连接互通。
(在这儿我吃了比较大的弹子,useradd和adduser是两个不同的命令,使用起来也不同,这一篇讲得比较清楚)
我使用的是
:sudo useradd hadoop_admin
:sudo passwd hadoop_admin
结果用它来login后,发现没有home信息,显示的是
$:
然后我切回root用户,自作主张创建了/home/hadoop_admin目录(于是这个目录就只有root有权限)
开始发现的问题是在生成rsa ssh key时提示目录无写入权限

查了下相关资料,列出用户对home的权限,发现host是root

继续
发现权限为0,说明这个用户创建得有问题,群友让我用chmod再手动设置权限(使用sudo chown -R hadoop_admin /home/hadoop_admin,这也是使用useradd需做的),我觉得太麻烦,查了下,决定重新建用户(这个在IT运维一定是不可以的吧 =O=)
:sudo deluser hadoop_admin
:sudo adduser hadoop_admin –home /home/hadoop_admin –u 545
现在正常了

1. 创建用户
:sudo adduser hadoop_admin –home /home/hadoop_admin –u 545
2. 将用户加入到可以执行sudo的用户列表
:sudo vi /etc/sudoers
将如下信息加入到文件中

3. 为用户生成SSH KEY(下讲)
安装SSH并生成RSA KEY
1. 安装OpenSSH
知识点:关于debian软件包和apt-get,看这儿
:sudo apt-get install openssh-server
完成后,理论上ssh就启动了,现在可以使用WinSCP explore模式进行文件传输了,将JDK,HADOOP都拷过去
可以看一看ssh的配置,有助于下面理解节点服务器之间通过SSH公钥无密码连接,我这种零基础的人觉得whereis命令异常方便..


因为安装hadoop时经常出现是否要将host加入know_host,所以这一行变得很有趣
Ubuntu debian默认打开了~/.ssh/config中的HashKnownHosts yes,所以每次ssh hostname时都会询问是否加入known_hosts文件,关于OpenSSH的扩展阅读
2. 为hadoop_admin生成私钥及公钥文件
#以hadoop_admin登陆并切换到~/主目录
:cd ~/
:ssh-keygen –t rsa #以RSA加密算法生成SSH keys –t 设置算法类型
这样就会自动在用户主目录下生成.ssh文件夹及id_rsa(prive key)和id_rsa.pub(public key)两个文件

:cd ~/.ssh
:cp id_rsa.pub authorized_keys #通过上面对SSH的了解,这个authorized_keys存放SSH识别能自动通过验证的公钥信息,信息串在我的实验中都是以login_name@hostname结尾的
(可以将其它user的公钥也扔进去)
安装JDK
前前后后折腾了好几种安装方法,有从Ubuntu Software Center搜索JDK安装了OpenJDK的,有通过修改debian source list使用sudo apt-get install java-6-sun的,都不好用,最简单的方法就是下载Sun的jdk -> 解压 -> 修改JAVA_HOME信息。
1. 准备好JDK文件
上面有讲,下载地址以及通过ssh将文件拷到VM系统中
2. 安装JDK
我是安装到/usr/lib/jvm/jdk1.7.0_21下 (这个目录最好在所有server中都统一,不然搞死人了~)
:sudo tar xvf ~/Downloads/[jdk].tar.gz –C /usr/lib/jvm
:cd /usr/lib/jvm
:ls
进去看看
3. 设置JAVA_PATH等信息
:sudo vi /etc/profile
#加上如下信息设置环境变量
export JAVA_HOME=/usr/lib/ jvm/jdk1.7.0_21
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$PATH:$JRE_HOME/lib
#执行一下使之有效
:source /etc/profile
#执行一下验证
:cd $JAVA_HOME
#若能正确定位,则设置完毕
安装hadoop
1. 准备hadoop文件
上面有讲过,将hadoop.0.20.2通过ssh传输到目标机器上
2. 安装hadoop
解压到hadoop_admin的目录下(Q: 一定要在这个目录吗) ->
:sudo tar xvf [hadoop.tar.gz路径] –C /home/hadoop_admin/hadoop/
3. 配置hadoop
配置有不少学问,下面是按最简单的… 我得学到下周才能明白了,我想… 这儿有些基本属性的解释,我下面自己手动输入加强记忆和理解
a. 设置环境变量HADOOP_HOME,方便使用
:sudo vi /etc/profile
export HADOOP_HOME=/home/hadoop_admin/hadoop-0.20.2
export JAVA_HOME=/usr/lib/syveen_jvm/jdk1.7.0_21
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$PATH:$JRE_HOME/lib:$HADOOP_HOME/bin
:source /etc/profile #执行,使之有效
:cd $HADOOP_HOME
:cd /conf/
:cd ls

b. 设置jdk路径,将JAVA_HOME加入到环境配置中
:sudo vi /JAVA_HOME加入到/hadoop-env.sh
不记得JDK路径的可以
:echo $JAVA_HOME
c. core-site.xml
设置name node的HDFS路径 。fs.default.name: 设置集群的name node的URI(协议hdfs,主机名/IP,端口号),集群中的每台机器都需要知道name node信息。
<configuration>
<property><name>fs.default.name</name><value>hdfs://h1:9001</value></property>
</configuration>
d. hdfs-site.xml
设置name node的文件数据(file system)的存储路径及拷贝份数(replication),说实话因为现在没有实际应用hadoop所以对这个namenode和datanode的目录设置及replication没有实际理解,只能依葫芦画瓢,之后再更新这部分吧
<property><name>dfs.name.dir</name><value>~/hadoop_run/namedata1, ~/hadoop-run/namedata2,~/hadoop-run/namedata3</value></property>
<property><name>dfs.data.dir</name><value>~/hadoop-0.20.2/data</value></property>
<property><name>dfs.replication</name><value>3</value></property>
e. mapred-site.xml
mapred: map-reduce的jobtracker信息
<property><name>mapred.job.tracker</name><value>h1:9001</value></property>
f. masters
加入master节点信息,这儿是h1
g. slaves
加入从属节点信息, 这儿是h2, h3
4. 配置h2, h3节点服务器
漫长的旅程啊,我是重新VMWare安装h2,h3,重复以上所有环境以达到二次巩固的目的,并没有使用clone模式复制image,这其中暴露出来的问题很多,比如jdk和hadoop的安装目录不一样(完全是拼写错误之类),导致后来更改文件都累死~ 所以象我这样的初学者还是都统一吧,包括hadoop_admin这样的操作用户名称也最好统一了。
4.1 安装及配置h2,h3节点服务器
重复创建hadoop_admin用户,安装ssh并生成key,到这儿就stop
4.2 将h2,h3的公钥信息导入到h1的authorized_keys中,以方便之后无密码SSH文件传输
方法为将h2,h3的文件先scp(secure copy)传输到h1目录中
在h2上 sudo scp ~/.ssh/id_rsa.pub hadoop_admin@h1:~/h2pub
在h3上 sudo scp ~/.ssh/id_rsa.pub hadoop_admin@h1:~/h3pub
在h1上
:sudo cat ~/.ssh/id_rsa.pub ~/h2pub ~/h3pub > ~/.ssh/authorized_keys #将自己的,h2和h3的公钥聚合(concatenate)在一起
:sudo scp ~/.ssh/authorized_keys hadoop_admin@h2:~/.ssh/authorized_keys #好吧,然后再拷回去(Q: slave需要吗)
:sudo scp ~/.ssh/authorized_keys hadoop_admin@h3:~/.ssh/authorized_keys
4.3 从h1直接安装JDK,HADOOP到h2,h3
a. 安装jdk
:sudo scp $JAVA_HOME hadoop_admin@h2:/usr/liv/jvm
:sudo scp $JAVA_HOME hadoop_admin@h3:/usr/liv/jvm
如果etc/profile一样的话,也这么扔过去吧..
:sudo scp /etc/profile h2:/etc/profile
:sudo scp /etc/profile h3:/etc/profile
b. 安装hadoop
:sudo scp $HADOOP_HOME hadoop_admin@h2:~/hadoop-0.20.2
:sudo scp $HADOOP_HOME hadoop_admin@h3:~/hadoop-0.20.2
c. 如果etc/hosts一样的话,把它们也搞过去吧..
:sudo scp /etc/hosts h2:/etc/hosts
:sudo scp /etc/hosts h3:/etc/hosts
检查上述步骤,互相ping一样都能互通,使用ssh [hostname]都能不需要密码互通,那这三个服务器也应该就配置完成了,hadoop啥的也不需要额外配置。
5. 格式化name node

arr.. 这个东西到底是做了啥呢? 很感兴趣,直接搜索了一把,还真有人看进源码。TBD了,之后再深入研究时会看。
6. 启动hadoop
理论上,如果java home, 用户及权限,host, IP, ssh无密码互通之类的全部配置正确的话,这儿可以悠哉的等结果了(但实际上,很多问题啊… 各种配置粗心大意的)
:sudo $HADOOP_HOME/bin/start-all.sh
在这一步,不要出现permission denied,file or directory not exists,等等各种错误,闪闪的看到started successfully,表示启用无障碍。
7. 检验是否成功
a. 进程正常
:sudo $JAVA_HOME/bin/jps
name node 4个进程
data node 3个进程



