Blob,layer Net, solver配置文件的编写
blob: 数据节点,4维数组:num, channel, width, height,相当于 一个tensor, n个tensor组成, n deminsional 矩阵。
在一个卷积层中,输入一张3通道图片,有96个卷积核,每个核大小为11*11,因此这个Blob是96*3*11*11. 而在一个全连接层中,假设输入1024通道图片,输出1000个数据,则Blob为1000*1024。
layer: 层是网络的多个组成部分,从bottom输入,处理后,经过top输出,每一种类型的层都有三种关键的计算:setup,forward and backward
setup: 层的建立和初始化,以及在整个模型中的连接初始化。
forward: 从bottom得到输入数据,进行计算,并将计算结果送到top,进行输出。
backward: 从层的输出端top得到数据的梯度,计算当前层的梯度,并将计算结果送到bottom,向前传递。
net:由多个layer组成,比如data+conv+pool+fc+fc2+loss
给出 一个简单的2层神经网络的模型定义( 加上loss 层就变成三层了),先给出这个网络的拓扑。
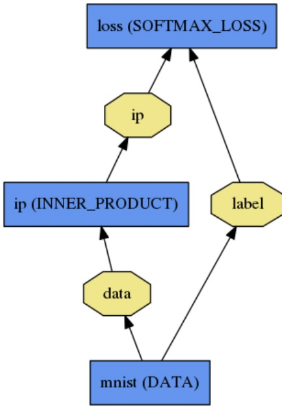
第一层:name为mnist, type为Data,没有输入(bottom),只有两个输出(top),一个为data,一个为label
第二层:name为ip,type为InnerProduct, 输入数据data, 输出数据ip
name: "LogReg" layer { name: "mnist" type: "Data" top: "data" top: "label" data_param { source: "input_leveldb" batch_size: 64 } } layer { name: "ip" type: "InnerProduct" bottom: "data" top: "ip" inner_product_param { num_output: 2 } } layer { name: "loss" type: "SoftmaxWithLoss" bottom: "ip" bottom: "label" top: "loss" }
solver,是caffe的核心,相当于TensorFlow中的optimizor,caffe运行必须带一个参数就是solver的配置文件
# caffe train --solver=*_solver.prototxt
solver的主要作用是调用forward和backward算法来更新参数,最小化loss,大概有6种算法:
- Stochastic Gradient Descent (
type: "SGD"), - AdaDelta (
type: "AdaDelta"), - Adaptive Gradient (
type: "AdaGrad"), - Adam (
type: "Adam"), - Nesterov’s Accelerated Gradient (
type: "Nesterov") - RMSprop (
type: "RMSProp")
在每一次的迭代过程中,solver做了这几步工作:
1、调用forward算法来计算最终的输出值,以及对应的loss
2、调用backward算法来计算每层的梯度
3、根据选用的slover方法,利用梯度进行参数更新
4、记录并保存每次迭代的学习率、快照,以及对应的状态。
net: "examples/mnist/lenet_train_test.prototxt" test_iter: 100 test_interval: 500 base_lr: 0.01 momentum: 0.9 type: SGD weight_decay: 0.0005 lr_policy: "inv" gamma: 0.0001 power: 0.75 display: 100 max_iter: 20000 snapshot: 5000 snapshot_prefix: "examples/mnist/lenet" solver_mode: CPU
net:设置深度网络模型。
test_iter: 迭代次数100
test_interval:500次进行一次测试
base_lr,lr_policy,gamma, power, 这四行可以放在一起理解,用于学习率的设置。只要是梯度下降法来求解优化,都会有一个学习率,也叫步长。base_lr用于设置基础学习率,在迭代的过程中,可以对基础学习率进行调整。怎么样进行调整,就是调整的策略,由lr_policy来设置。
lr_policy可以设置为下面这些值,相应的学习率的计算为:
-
- - fixed: 保持base_lr不变.
- - step: 如果设置为step,则还需要设置一个stepsize, 返回 base_lr * gamma ^ (floor(iter / stepsize)),其中iter表示当前的迭代次数
- - exp: 返回base_lr * gamma ^ iter, iter为当前迭代次数
- - inv: 如果设置为inv,还需要设置一个power, 返回base_lr * (1 + gamma * iter) ^ (- power)
- - multistep: 如果设置为multistep,则还需要设置一个stepvalue。这个参数和step很相似,step是均匀等间隔变化,而multistep则是根据 stepvalue值变化
- - poly: 学习率进行多项式误差, 返回 base_lr (1 - iter/max_iter) ^ (power)
- - sigmoid: 学习率进行sigmod衰减,返回 base_lr ( 1/(1 + exp(-gamma * (iter - stepsize))))