对应之前的tensorflow的optimizor,再次回顾一下,solver就是使得loss最小化的方法。,对于一个数据集,我们需要优化的目标函数是整个数据集中所有数据loss的平均值。
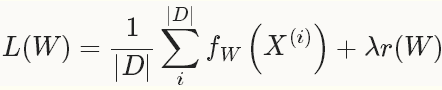
其中,fW(x(i))计算的是数据x(i)上的loss, 先将每个单独的样本x的loss求出来,然后求和,最后求均值。 r(W)是正则项(weight_decay),为了减弱过拟合现象。
这种方法也就是普通的GD。
在实际中,通常把数据分成几批,来处理也就是,其中batch size N << D,也就是SGD
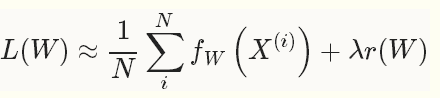
1. SGD:在深度学习中使用SGD,比较好的初始化参数的策略是把学习率设为0.01左右(base_lr: 0.01),在训练的过程中,如果loss开始出现稳定水平时,对学习率乘以一个常数因子(gamma),这样的过程重复多次。
对于momentum,一般取值在0.5--0.99之间。通常设为0.9,momentum可以让使用SGD的深度学习方法更加稳定以及快速。
base_lr: 0.01 lr_policy: "step" gamma: 0.1 stepsize: 1000 max_iter: 3500 momentum: 0.9
lr_policy设置为step,则学习率的变化规则为 base_lr * gamma ^ (floor(iter / stepsize))
即前1000次迭代,学习率为0.01; 第1001-2000次迭代,学习率为0.001; 第2001-3000次迭代,学习率为0.00001,第3001-3500次迭代,学习率为10-5
2.AdaDelta:
net: "examples/mnist/lenet_train_test.prototxt" test_iter: 100 test_interval: 500 base_lr: 1.0 lr_policy: "fixed" momentum: 0.95 weight_decay: 0.0005 display: 100 max_iter: 10000 snapshot: 5000 snapshot_prefix: "examples/mnist/lenet_adadelta" solver_mode: GPU type: "AdaDelta" delta: 1e-6
3.AdaGrad 自适应梯度
net: "examples/mnist/mnist_autoencoder.prototxt" test_state: { stage: 'test-on-train' } test_iter: 500 test_state: { stage: 'test-on-test' } test_iter: 100 test_interval: 500 test_compute_loss: true base_lr: 0.01 lr_policy: "fixed" display: 100 max_iter: 65000 weight_decay: 0.0005 snapshot: 10000 snapshot_prefix: "examples/mnist/mnist_autoencoder_adagrad_train" # solver mode: CPU or GPU solver_mode: GPU type: "AdaGrad"
5.NAG, Nesterov‘s accelerated gradient
net: "examples/mnist/mnist_autoencoder.prototxt" test_state: { stage: 'test-on-train' } test_iter: 500 test_state: { stage: 'test-on-test' } test_iter: 100 test_interval: 500 test_compute_loss: true base_lr: 0.01 lr_policy: "step" gamma: 0.1 stepsize: 10000 display: 100 max_iter: 65000 weight_decay: 0.0005 snapshot: 10000 snapshot_prefix: "examples/mnist/mnist_autoencoder_nesterov_train" momentum: 0.95 # solver mode: CPU or GPU solver_mode: GPU type: "Nesterov"
6.RMSprop:
net: "examples/mnist/lenet_train_test.prototxt" test_iter: 100 test_interval: 500 base_lr: 1.0 lr_policy: "fixed" momentum: 0.95 weight_decay: 0.0005 display: 100 max_iter: 10000 snapshot: 5000 snapshot_prefix: "examples/mnist/lenet_adadelta" solver_mode: GPU type: "RMSProp" rms_decay: 0.98
不同的solver,对应的配置参数不同,需要注意。