神经网络激活函数
激活函数 激活函数在神经元中非常重要的。为了增强网络的表示能力和学习能 力,激活函数需要具备以下几点性质:
1. 连续并可导(允许少数点上不可导)的非线性函数。可导的激活函数可以 直接利用数值优化的方法来学习网络参数。
2. 激活函数及其导函数要尽可能的简单,有利于提高网络计算效率。
3. 激活函数的导函数的值域要在一个合适的区间内,不能太大也不能太小, 否则会影响训练的效率和稳定性。
Sigmoid型函数是指一类S型曲线函数,为两端饱和函数。常用的Sigmoid 型函数有Logistic函数和Tanh函数。

Logistic函数可以看成是一个“挤压”函数,把一个实数域的输入“挤压” 到(0,1)。1)其输出直接可以看作是概率分布,使得神经网络可以更好地和统 计学习模型进行结合。2)其可以看作是一个软性门(Soft Gate),用来控制其 它神经元输出信息的数量。
Tanh函数是也一种Sigmoid型函数。

Tanh函数的输出是零中心 化的(Zero-Centered),而Logistic函数的输出恒大于0。非零中心化的输出会使得其后一层的神经元的输入发生偏置偏移(Bias Shift),并进一步使得梯度 下降的收敛速度变慢。
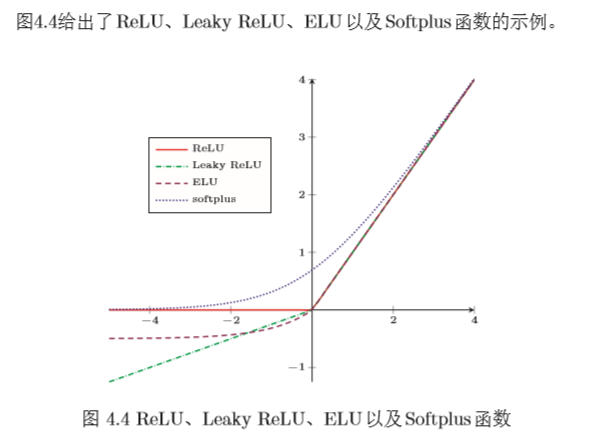
修正线性单元(Rectified Linear Unit,ReLU) [Nair and Hinton, 2010],也叫rectifier函数[Glorot et al., 2011],是目前深层神经网络中经常使用的激活函 数。ReLU实际上是一个斜坡(ramp)函数。
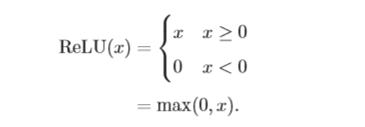
优点:采用ReLU的神经元只需要进行加、乘和比较的操作,计算上更加高效。ReLU函数被认为有生物上的解释性,比如单侧抑制、宽兴奋边界(即兴奋程度 也可以非常高)。在生物神经网络中,同时处于兴奋状态的神经元非常稀疏。人脑中在同一时刻大概只有1∼4%的神经元处于活跃状态。Sigmoid型激活函数会导致一个非稀疏的神经网络,而ReLU却具有很好的稀疏性,大约50%的神 经元会处于激活状态。
在优化方面,相比于Sigmoid型函数的两端饱和,ReLU函数为左饱和函数, 且在x > 0时导数为1,在一定程度上缓解了神经网络的梯度消失问题,加速梯度下降的收敛速度。
缺点:ReLU函数的输出是非零中心化的,给后一层的神经网络引入偏置偏移,会影响梯度下降的效率。此外,ReLU神经元在训练时比较容易“死亡”。在训练时,如果参数在一次不恰当的更新后,第一个隐藏层中的某个 ReLU神经元在 所有的训练数据上都不能被激活,那么这个神经元自身参数的梯度永远都会是 0,在以后的训练过程中永远不能被激活。这种现象称为死亡ReLU问题(Dying ReLU Problem),并且也有可能会发生在其它隐藏层。
在实际使用中,为了避免上述情况,有几种ReLU的变种也会被广泛使用。
带泄露的ReLU(Leaky ReLU)在输入 x < 0时,保持一个很小的梯度λ。 这样当神经元非激活时也能有一个非零的梯度可以更新参数,避免永远不能被 激活[Maas et al., 2013]。
带参数的ReLU(Parametric ReLU,PReLU)引入一个可学习的参数,不 同神经元可以有不同的参数[He et al., 2015]。
Softplus函数[Dugas et al., 2001]可以看作是rectifier函数的平滑版本,Softplus函数其导数刚好是Logistic函数。Softplus函数虽然也有具有单侧抑制、 宽兴奋边界的特性,却没有稀疏激活性。
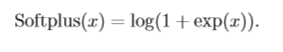
网络结构
前馈神经网络,每一层中的神经元接受前一层神经元的输出,并输出到下一层神 经元。整个网络中的信息是朝一个方向传播,没有反向的信息传播,可以用一 个有向无环路图表示。前馈网络包括全连接前馈网络和卷积神经网络等。
前馈网络可以看作一个函数,通过简单非线性函数的多次复合,实现输入 空间到输出空间的复杂映射。这种网络结构简单,易于实现。
反馈网络中神经元不但可以接收其它神经元的信号,也可以接收自己的反馈信号。
和前馈网络相比,反馈网络中的神经元具有记忆功能,在不同的时刻具 有不同的状态。反馈神经网络中的信息传播可以是单向或双向传递,因此可用一个有向循环图或无向图来表示。反馈网络包括循环神经网络[第6章],Hopfield网络、玻尔兹曼机等。
图网络
前馈网络和反馈网络的输入都可以表示为向量或向量序列。但实际应用中 很多数据是图结构的数据,比如知识图谱、社交网络、分子(molecular )网络 等。前馈网络和反馈网络很难处理图结构的数据。 图网络是定义在图结构数据上的神经网络。图中每个节点都一 个或一组神经元构成。节点之间的连接可以是有向的,也可以是无向的。每个 节点可以收到来自相邻节点或自身的信息。
图网络是前馈网络和记忆网络的泛化,包含很多不同的实现方式,比如图 卷积网络(Graph Convolutional Network,GCN) [Kipf and Welling, 2016]、消 息传递网络(Message Passing Neural Network,MPNN)[Gilmer et al., 2017] 等。
无监督学习
无监督学习是一种十分重要的机器学习方法。广义上讲,监督学习也可以看作是一个类特殊的无监督学习,即估计条件概率p(y|x)。条件概率p(y|x)可以通过贝叶斯公式转为估计概率p(y)和p(x|y),并通过无监督密度估计来求解。
无监督学习问题主要可以分为聚类、特征学习、密度估计等几种类型。
稀疏编码(Sparse Coding)也是一种受哺乳动物视觉系统中简单细胞感受 野而启发的模型。在哺乳动物的初级视觉皮层(primary visual cortex)中,每个神经元仅对处于其感受野中特定的刺激信号做出响应,比如特定方向的边缘、条纹等特征。
编码是对d维空间中的样本x找到其在p维空间中的表示(或投影),其目 标通常是编码的各个维度都是统计独立的,并且可以重构出输入样本。编码的 关键是找到一组“完备”的基向量A,比如主成分分析等。但是主成分分析得 到编码通常是稠密向量,没有稀疏性。
稀疏编码的每一维都可以看作是一种特征。和基于稠密向量的分布式表示相比,稀疏编码具有更小的计算量和更好的可解释性等优点。
- 计算量 ,稀疏性带来的最大好处就是可以极大地降低计算量。
- 可解释性 ,因为稀疏编码只有少数的非零元素,相当于将一个输入样本表示为少 数几个相关的特征。这样我们可以更好地描述其特征,并易于理解。
- 特征选择 ,稀疏性带来的另外一个好处是可以实现特征的自动选择,只选择和 输入样本相关的最少特征,从而可以更好地表示输入样本,降低噪声并减轻过 拟合。
自编码器(Auto-Encoder,AE)是通过无监督的方式来学习一组数据的有效编码(或表示)。 假设有一组d维的样本x(n) ∈Rd,1≤ n ≤ N,自编码器将这组数据映射到特征空间得到每个样本的编码z(n) ∈ Rp,1 ≤ n ≤ N,并且希望这组编码可以 重构出原来的样本。
我们使用自编码器是为了得到有效的数据表示,因此在训练结束后,我们一般去掉解码器,只保留编码器。编码器的输出可以直接作为后续机器学习模型的输入。
自编码器除了可以学习低维编码之外,也学习高维的稀疏编码。假设中间隐藏层z的维度为p大于输入样本x的维度d,并让z尽量稀疏,这就是稀疏自编码器(Sparse Auto-Encoder)。和稀疏编码一样,稀疏自编码器的优点是有 很高的可解释性,并同时进行了隐式的特征选择。
对于很多数据来说,仅使用两层神经网络的自编码器还不足以获取一种好 的数据表示。为了获取更好的数据表示,我们可以使用更深层的神经网络。深层神经网络作为自编码器提取的数据表示一般会更加抽象,能够更好地捕捉到 数据的语义信息。在实践中经常使用逐层堆叠的方式来训练一个深层的自编码器,称为堆叠自编码器(Stacked Auto-Encoder,SAE)。堆叠自编码一般可以 采用逐层训练(layer-wise training)来学习网络参数。
信息论
熵(Entropy)最早是物理学的概念,用于表示一个热力学系统的无序程度。 在信息论中,熵用来衡量一个随机事件的不确定性。假设对一个随机变量X(取 值集合为X,概率分布为p(x),x ∈X)进行编码,自信息I(x)是变量X = x时 的信息量或编码长度,定义为

熵是一个随机变量的平均编码长度,即自信息的数学期望。熵越高,则随机 变量的信息越多;熵越低,则信息越少。如果变量X 当且仅当在x时p(x)=1, 则熵为0。也就是说,对于一个确定的信息,其熵为0,信息量也为0。如果其概率 分布为一个均匀分布,则熵最大。
对于两个离散随机变量X 和Y ,假设X 取值集合为X; Y 取值集合为Y,其 联合概率分布满足为p(x,y),则 X 和Y 的联合熵(Joint Entropy)为
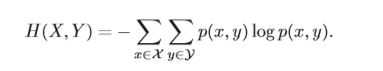
X 和Y 的条件熵(Conditional Entropy)为
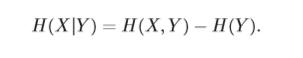
互信息(Mutual Information)是衡量已知一个变量时,另一个变量不确定 性的减少程度。两个离散随机变量X 和Y 的互信息定义为 :
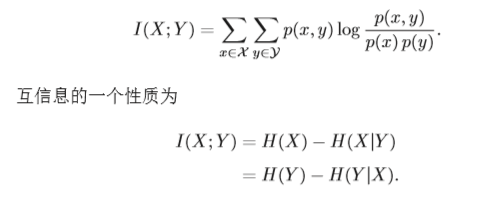
如果X 和Y 相互独立,即X 不对Y 提供任何信息,反之亦然,因此它们的互信 息为零。
对应分布为p(x)的随机变量,熵H(p)表示其最优编码长度。交叉熵(Cross Entropy)是按照概率分布q的最优编码对真实分布为p的信息进行编码的长度, 定义为
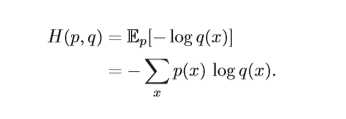
在给定p的情况下,如果q和p越接近,交叉熵越小;如果q和p越远,交 叉熵就越大。
KL散度(Kullback-Leibler Divergence),也叫KL距离或相对熵(Relative Entropy),是用概率分布q来近似p时所造成的信息损失量。KL散度是按照概 率分布q的最优编码对真实分布为p的信息进行编码,其平均编码长度H(p,q) 和p的最优平均编码长度H(p)之间的差异。对于离散概率分布p和q,从q到p 的KL散度定义为

KL散度可以是衡量两个概率分布之间的距离。KL散度总是非负的, DKL(p∥q)≥ 0。只有当p = q时,DKL(p∥q)=0。如果两个分布越接近,KL散度越小;如果 两个分布越远,KL散度就越大。但KL散度并不是一个真正的度量或距离,一 是KL散度不满足距离的对称性,二是KL散度不满足距离的三角不等式性质。
JS散度(Jensen–Shannon Divergence)是一种对称的衡量两个分布相似度 的度量方式,定义为
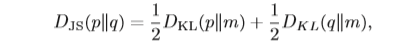 其中m = 1/2(p+q)。
其中m = 1/2(p+q)。
JS散度是KL散度一种改进。但两种散度有存在一个问题,即如果两个分 布p,q 个分布没有重叠或者重叠非常少时,KL散度和JS散度都很难衡量两个 分布的距离。