# 爬虫框架
- scrapy
- pyspider
- crawley
# Scrapy框架
- 安装:
- pip install scrapy
- conda install scrapy
- 概述
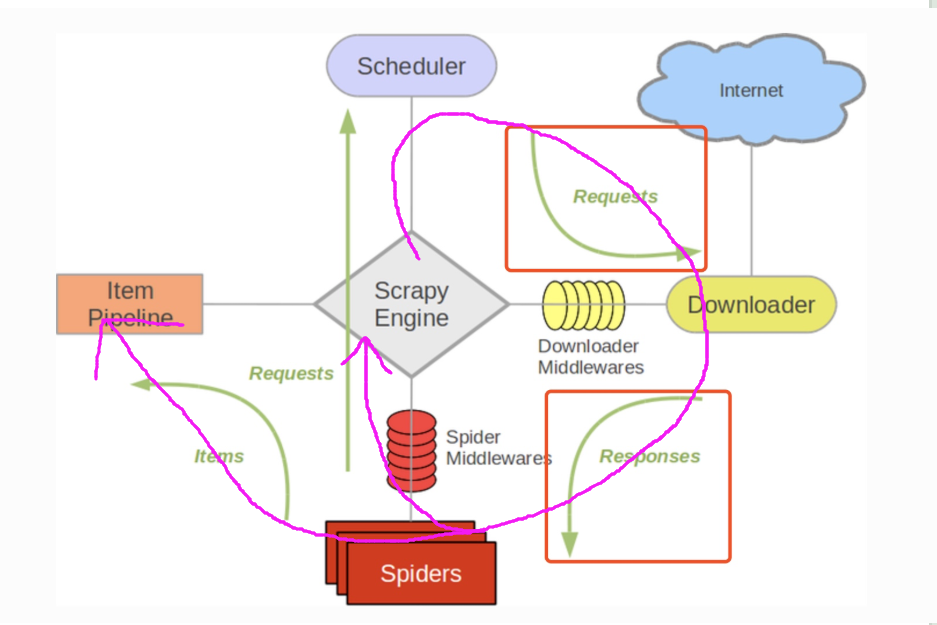
- 包含各个部件
- ScrapyEngine引擎:神经中枢、大脑、核心
- Scheduler调度器:引擎发来的request请求,调度器需要处理,然后把结果返回引擎
- Downloader下载器:得到response
- Spiders爬虫:负责把下载器得到的网页/结果进行分解,分解成数据和链接
- ItemPipeline管道:详细处理Item
- DownloaderMiddleware下载中间件:自定义下载的功能扩展组件
- SpiderMiddleware爬虫中间件:对Spiders进行功能扩展
- 爬虫项目大概流程
- 新建项目:scrapy startproject xxx
- 明确需要目标/产出:编写item.py
- 制造爬虫:路径spider/xxxspider.py
- 存储内容:pipelines.py
- ItemPipeline
- 对应的是pipelines文件
- 爬虫提取出数据存入item后,item中保存的数据需要进一步处理,比如清洗、去重、存储等
- pipeline需要处理process_item函数
- process_item
- spiders提取出来的item作为参数传入,同时传入的还有spider
- 此方法必须实现
- 必须返回一个Item对象,被遗弃的item不会被之后的pipeline处理
- __init__
- 进行一些必要的参数初始化
- open_spider(spider):
- spider对象那个被开启的时候调用
- close_spider(spider)
- 当spider对象被关闭的时候调用
- Spiders
- 对应的文件夹spiders下的文件
- __init:初始化爬虫名称,start_urls列表
- start_requests,生成Requests对象交给Scrapy下载并返回responsee
- parse:根据返回的responses解析出相应的item,item自动进入pipeline,如果需要解析出url,url自动交给requests模块,一直循环下去
- start_request:此方法仅能被调用一次,读取start_urls内容并启动循环过程
- name:设置爬虫名称
- start_urls:设置开始第一批爬取的url
- allow_domains:spider允许爬取的域名列表
- start_request(self):只被调用一次
- parse
- log:日志记录
- 中间件(DownloaderMiddlewares)
- 中间件是处于引擎和下载器中间的一层组件
- 可以有很多个,按顺序加载执行
- 作用是对发出的请求和返回的结果进行预处理
- 在middlewares文件中
- 需要在settings中设置以便生效
- 一般一个中间件完成一项功能
- 必须实现以下一个或者多个方法
- process_request(self, request, spider)
- 在request通过的时候被调用
- 必须返回None或Response或者Request或者raise IgnoreRequest
- None:scrapy将继续处理该request
- Request:scrapy会停止调用process_request,并重新调度返回的request
- Response:scrapy将不用调用其他的process_request或者process_exception,直接将该response作为结果返回,同时会调用process_response函数
- process_response(self, request, response, spider)
- 跟process_request大同小异
- 每次返回结果的时候会自动调用
- 可以有多个,按顺序调用
案例代码:
import random
import base64
#从settings设置文件中导入值:用户代理
from settings import USER_AGENTS
from settings import PROXIES
# 随机的User-Agent
class RandomUserAgent(object):
def process_request(self, request, spider):
useragent = random.choice(USER_AGENTS)
request.headers.setdefault("User-Agent", useragent)
class RandomProxy(object):
def process_request(self, request, spider):
proxy = random.choice(PROXIES)
if proxy['user-passwd] is None:
# 没有代理账户登录的代理使用方式
request.meta['proxy'] = "http://" + proxy['ip_port']
else:
# 对账户密码进行base64编码转换
base64_userpasswd = base64.b64encode(proxy['user_passwd'])
# 对应到代理服务器的信令格式里
request.headers['proxy-Authorization'] = 'Basic' + base64_userpasswd
request.meta['proxy'] = "http://" + proxy['ip_port']
- 设置sttings,参照scrapy中文文档
- 去重
- 为防止爬虫陷入死循环,需要去重
- 即在spider中的parse函数中,返回的Request的时候加上dont_filter=False参数
myspider(scrapy.Spider):
def parse():
...
yield scrapy.Request(url=url, callback=self.parse, dont_filter=False)
- 如何在scrapy使用selenium
- 可以放入中间件中的process-request函数中
- 在函数中调用selenium,完成爬取后返回Responses
class MyMiddlewares(object):
def process_request(self, request, spider):
driver = webdriver.Chrom()
html = driver.page_source
driver.quit()
return HtmlResponse(url=request.url, encoding='utf-8', body=html, request=request)
- scrapy-shell
- 启动
- Linux:ctr+t,打开终端,然后输入scrapy shell "http://www.xxx.com"
- windows:打开Anaconda Prompt,输入scrapy shell "http://www.xxx.com"
- 输入地址后自动下载指定url网页
- 下载完成后,url的内容保存在response的变量中,如果需要,我们要调用response
- response
- 爬取到的内容保存在response中
- response.body是网页的html
- response.headers是返回的http头信息
- response.xpath()允许使用xpath语法选择内容
- response.css()允许通过css语法选取内容
- selector
- 选择器,允许用户使用选择器来选择自己想要的内容
- response.selector.xpath:response.xpath是selector.xpath的快捷方式
- response.selector.css:ressponse.css是它的快捷方式
- selector.extract():把节点的内容用unicode形式返回
- selector.re:允许用户通过正则选择内容
- 例子:
# 1、用xpath找class为asd的div标签下的有style属性的p标签,然后接着继续找这个标签下面的a标签的href属性
rsts = response.xpath("//div[@class='asd']/p[@style]/a/@href")
# 2、用for in 打印找到内容
for i in rsts:
print(i.extract())
# 分布式爬虫
- 单机爬虫的问题
- 单机效率问题
- IO吞吐量
- 多爬虫问题
- 数据共享
- 在空间上不同的多台机器,可以成为分布式
- 解决多爬虫问题
- 共享队列
- 去重
- Redis内存数据库
- 同时内容可以落地保存到硬盘
- 去重
- 可以把它理解成一个dict、set、list的集合体
- 可以对保存的内容进行生命周期控制
- 分布式爬虫在scrapy框架中使用只需要改settings的设置就可以
- 内容保存数据库
- MongoDB
- Mysql等传统关系数据库
- 安装scrapy_redis
- pip install scrapy_redis
- github.com/rolando/scrapy_redis
- scrapy_redis官方网站
- scrapy-redis.readthedocs.org
# 推荐书籍
- Python爬虫开发与项目实战
- 精通python爬虫框架scrapy
- 崔庆才