瘦数据模型是一种最为臭名昭著并且问题多多的对关系数据库系统的滥用。不幸的是,有时又的确需要瘦数据模型。所谓瘦数据模型,就是简单地将每张表都设计为一种通用数据结构,用于存储名值对的集合。这非常像Java中的属性文件。有时这些表也可用于存储元数据,例如期望的数据类型等。这是必要的, 因为数据库只允许一列有一种类型定义。要更好地理解瘦数据模型,考虑下面这个典型的地址数据的示例,如表1-2所示。
|
表1-2典型模型中的地址数据
|
|
很显然这个地址数据表可以进一步规I范化。例如,可以创建COUNTRY (国家)、STATE (州)、 CITY (城市)和ZIP (邮编)这样的关联表。但当前这样一个设计对于大多数应用程序来说既简 单又高效,已经足够了。除非你的需求的确非常复杂,否则这个模型应该不会有任何问题。 |
|
还是使用以上的数据, |
如果将它们放入一个瘦数据模型对应的表中, |
结果将如表1-3所示。 |
|
表1-3瘦数据模型中的地址数据 |
||
|
ADDRESSJD |
FIELD |
VALUE |
|
1 |
STREET |
123 Some Street |
|
1 |
CITY |
San Francisco |
|
(续) |
||
|
ADDRESS ID |
FIELD |
VALUE |
|
1 |
STATE |
California |
|
1 |
ZIP |
12345 |
|
1 |
COUNTRY |
USA |
|
2 |
STREET |
456 Another Street |
|
2 |
STATE |
New York |
|
2 |
ZIP |
54321 |
|
2 |
COUNTRY |
USA |
这样的设计绝对是场噩梦。首先,没有任何可能对它进一步规范化了,虽然当前的模型只能 算作第一范式。其次,没有任何机会创建与COUNTRY表、CITY表、STATE表或ZIP表的关联关系了,因为我们不可能在同一列上定义多个外键。再次,如果希望执行一条涉及多个地址字段(例如,执行一个以街道和城市作为查询条件的查询语句)的“样例查询”,这样的数据实在让人头痛,它可能需要一大堆复杂的子查询。再看看更新的情况,这样的设计就性能来说也特别糟糕, 仅仅是插入一个地址就需要在同一张表上执行5条插入语句。这种情况下出现锁竞争甚至死锁的 可能性也大大增加了。此外,这个瘦数据模型中记录的数量整整是我们的规范化数据模型的5倍。 由于记录数量过大,又缺少明确的数据定义,而且更新一条记录时需要的更新语句过多,创建有 效的索引也是不可能的了。
不用再多说了,这个设计确实问题多多,我们为何要不惜一切代价避免这样的设计,原因已经再明白不过了。但话说回来,这个设计也不是毫无用处,它唯一的用武之地就在于那些需要动态字段的应用程序。有些应用程序的确有这样的需求,它允许用户对他们的记录添加额外的数据。 如果用户希望能定义新的字段,然后在应用程序运行时动态地把数据插入到这些字段中,那么这样的模型就可以工作得很好。也就是说,所有的已知数据还是应该正确地规范化,而这些额外的动态字段则可以通过关联关系与这些已知数据建立父子关系。这样的设计同样存在我们之 前讨论过的所有问题,但它们被最小化了,因为大部分数据(很可能是那些最重要的数据)都 己经被正确地规范化了。
即使在一个企业数据库中遇到了瘦数据模型,MyBatis也可以帮助你处理它。要将若干个类映射为瘦数据模型是非常困难的,甚至是根本不可能的,因为你连数据模型中可能存在哪些字段都 无法明确。此时你最好将这样的类映射为一个散列表(hashtable),而幸运的是iBATIS支持这种 映射。使用MyBatis,你不必将每一张表都映射为一个用户定义的类。MyBatis允许你将关系数据映 射为Java基本类型(primitive)、Map实例、XML还有用户定义类(如JavaBean)。这种巨大的灵 活性使得iBATIS对于包括瘦数据模型在内的复杂数据模型非常有效。
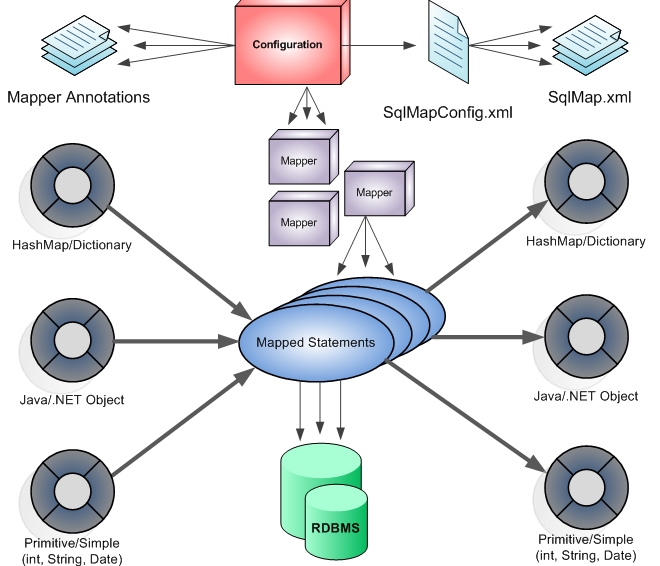
MyBatis被设计为一个混合型解决方案,它并不试图解决所有的问题,相反它只希望能解决那些最重要的问题。MyBatis从各种数据库访问工具中汲取了大量的优秀思想。像存储过程一样,所有的MyBatis语句都有一个签名,定义了语句的名字和输入输出(封装)。与内联SQL类似,MyBatis允许SQL语句按照其最自然的方式书写,并且可以直接使用语言中的变量作为输入输出参数和结 果。像动态SQL—样,MyBatis允许在运行时修改SQL。这样的查询语句可以根据用户的请求动态 构建。从对象/关系映射工具中,MyBatis借用了许多概念,包括高速缓存、延迟加载,还有更高 级的事务管理。
在一个应用程序的架构中,MyBatis适用于持久层。MyBatis也通过提供一些特性来支持其他层, 这些特性使得对所有这些层的需求的实现都变得更加容易。例如,一个Web搜索引擎可能需要搜 索结果的分页列表。MyBatis支持这种特性,因为它允许査询时指定返回结果的偏移量和行数量。这就使得分页操作可以在一个较低的层次上执行,同时保持数据库细节可以远离我们 的应用程序。
MyBatis可用于任何大小和用途的数据库。首先,MyBatis非常适合于那些较小的应用程序数据库,因为它非常容易学习和快速上手。其次,MyBatis对大型企业应用程序也非常合适,因为它没有对数据库的设计、行为或者那些可能对我们的应用程序如何使用数据库产生影响的依赖关系做 任何假设。再次,即使是对于那些在设计上存在着争议或者深陷于高层政策混乱之中的数据库, MyBatis也可以工作得很好。综上所述,MyBatis被设计得非常灵活以至于几乎可适用于任何情况了。 当然,使用MyBatis也可以为你节省大量的时间,因为你再不用写那些重复的、样本一样的代码了。
讨论了 MyBatis的理念和起源。后面将仔细解释什么是MyBatis以及它是如何工作的。
系列文章: