简单的WordCount栗子--类似于编程语言中的hello world
1.shell脚本run.sh
1 HADOOP_CMD="/usr/local/src/hadoop-1.2.1/bin/hadoop" 2 STREAM_JAR_PATH="/usr/local/src/hadoop-1.2.1/contrib/streaming/hadoop-streaming-1.2.1.jar" 3 4 INPUT_FILE_PATH="/input.txt" 5 OUTPUT_PATH="/output" 6 7 $HADOOP_CMD fs -rmr -skipTrash $OUTPUT_PATH #如果输出文件目录存在就先删除 8 9 # Step 1. 10 $HADOOP_CMD jar $STREAM_JAR_PATH 11 -input $INPUT_FILE_PATH #-input:指定输入文件hdfs路径,支持通配符*,支持指定多个文件或目录, 可多次使用 12 -output $OUTPUT_PATH #-output:指定输出文件的hdfs路径, 路径不能存在,执行作业用户必须有创建该目录的权限,只能用一次 13 -mapper "python map.py" #自己写的mapper程序 14 -reducer "python red.py" #自己写的reducer程序 15 -file ./map.py #-file:分发文件到计算节点,1.map和reduce的执行文件;2.map和reduce要用的输入文件.如果要用的文件太大,需要用hdfs存储,类似的配置有-cacheFile,-cacheArchive分别用于向计算节点分发hdfs文件和hdfs压缩文件 16 -file ./red.py
17 -jobconf mapred.job.name="WordCount" #设置作业的名称
2.map.py
1 #!/usr/local/bin/python 2 3 import sys 4 5 for line in sys.stdin: 6 ss = line.strip().split(' ') 7 for s in ss: 8 if s.strip() != "": 9 print "%s %s" % (s, 1) #标准输出用 分割,会自动识别为key,value
3.red.py
1 #!/usr/local/bin/python 2 3 import sys 4 5 current_word = None 6 count_pool = [] 7 sum = 0 8 9 for line in sys.stdin: 10 word, val = line.strip().split(' ') 11 12 if current_word == None: 13 current_word = word 14 15 if current_word != word: 16 for count in count_pool: 17 sum += count 18 print "%s %s" % (current_word, sum) 19 current_word = word 20 count_pool = [] 21 sum = 0 22 23 count_pool.append(int(val)) 24 25 for count in count_pool: 26 sum += count 27 print "%s %s" % (current_word, str(sum))
启动hadoop集群后, 运行shell脚本:

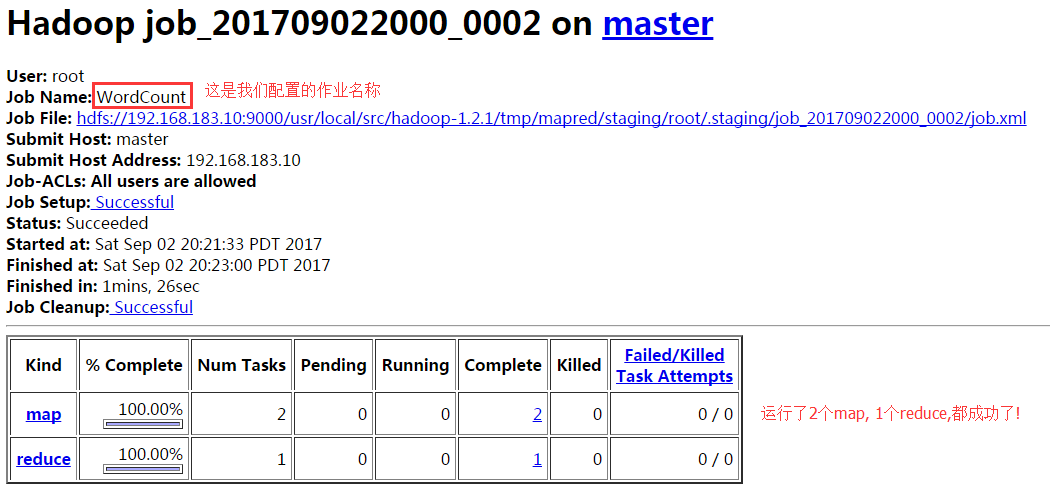
以下是Tracking URL中的部分内容:
查看输出到hdfs的目录/output

运行以下命令查看结果中排名前十的单词
