一、池化技术之线程池
什么是池化技术?简单来说就是优化资源的使用,我准备好了一些资源,有人要用就到我这里拿,用完了就还给我。而一个比较重要的的实现就是线程池。那么线程池用到了池化技术有什么好处呢?
- 降低资源的消耗
- 提高响应的速度
- 方便管理
也就是 线程复用、可以控制最大并发数、管理线程
二、线程池的五种实现方式
其实线程池我更愿意说成四种封装实现方式,一种原始实现方式。这四种封装的实现方式都是依赖于最原始的的实现方式。所以这里我们先介绍四种封装的实现方式
newSingleThreadExecutor()
这个线程池很有意思,说是线程池,但是池子里面只有一条线程。如果线程因为异常而停止,会自动新建一个线程补充。
我们可以测试一下:
我们对线程池执行十条打印任务,可以发现它们用的都是同一条线程
public static void test01() {
ExecutorService threadPool = Executors.newSingleThreadExecutor();
try {
//对线程进行执行十条打印任务
for(int i = 1; i <= 10; i++){
threadPool.execute(()->{
System.out.println(Thread.currentThread().getName()+"=>执行完毕!");
});
}
} catch (Exception e) {
e.printStackTrace();
} finally {
//用完线程池一定要记得关闭
threadPool.shutdown();
}
}
pool-1-thread-1=>执行完毕!
pool-1-thread-1=>执行完毕!
pool-1-thread-1=>执行完毕!
pool-1-thread-1=>执行完毕!
pool-1-thread-1=>执行完毕!
pool-1-thread-1=>执行完毕!
pool-1-thread-1=>执行完毕!
pool-1-thread-1=>执行完毕!
pool-1-thread-1=>执行完毕!
newFixedThreadPool(指定线程数量)
这个线程池是可以指定我们的线程池大小的,可以针对我们具体的业务和情况来分配大小。它是创建一个核心线程数跟最大线程数相同的线程池,因此池中的线程数量既不会增加也不会变少,如果有空闲线程任务就会被执行,如果没有就放入任务队列,等待空闲线程。
我们同样来测试一下:
public static void test02() {
ExecutorService threadPool = Executors.newFixedThreadPool(5);
try {
//对线程进行执行十条打印任务
for(int i = 1; i <= 10; i++){
threadPool.execute(()->{
System.out.println(Thread.currentThread().getName()+"=>执行完毕!");
});
}
} catch (Exception e) {
e.printStackTrace();
} finally {
//用完线程池一定要记得关闭
threadPool.shutdown();
}
}
我们创建了五条线程的线程池,在打印任务的时候,可以发现线程都有进行工作
pool-1-thread-1=>执行完毕!
pool-1-thread-1=>执行完毕!
pool-1-thread-1=>执行完毕!
pool-1-thread-1=>执行完毕!
pool-1-thread-1=>执行完毕!
pool-1-thread-1=>执行完毕!
pool-1-thread-2=>执行完毕!
pool-1-thread-3=>执行完毕!
pool-1-thread-5=>执行完毕!
pool-1-thread-4=>执行完毕!
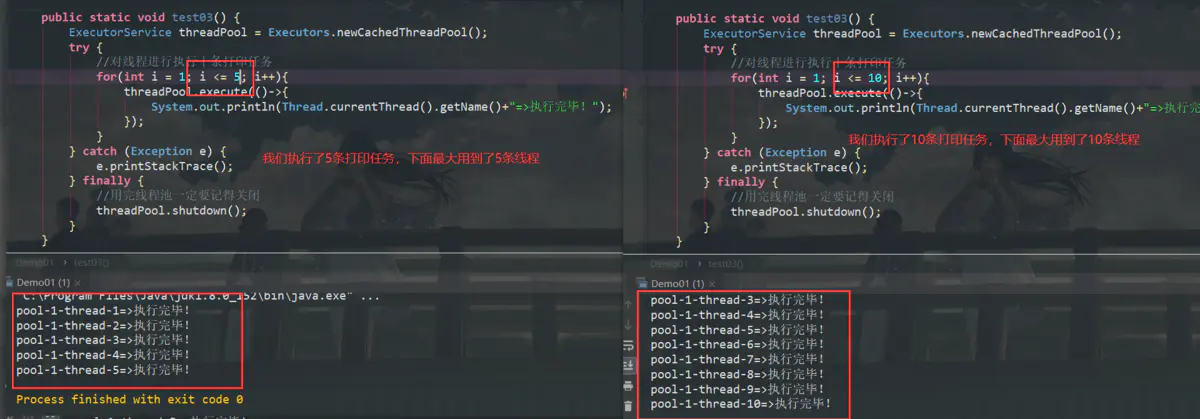
newCachedThreadPool()
这个线程池是创建一个核心线程数为0,最大线程为Inter.MAX_VALUE的线程池,也就是说没有限制,线程池中的线程数量不确定,但如果有空闲线程可以复用,则优先使用,如果没有空闲线程,则创建新线程处理任务,处理完放入线程池。
我们同样来测试一下
newScheduledThreadPool(指定最大线程数量)
创建一个没有最大线程数限制的可以定时执行线程池
在这里,还有创建一个只有单个线程的可以定时执行线程池(Executors.newSingleThreadScheduledExecutor())这些都是上面的线程池扩展开来了,不详细介绍了。
三、介绍线程池的七大参数
上面我们也说到了线程池有五种实现方式,但是实际上我们就介绍了四种。那么最后一种是什么呢?不急,我们可以点开我们上面线程池实现方式的源码进行查看,可以发现
- newSingleThreadExecutor()的实现源码
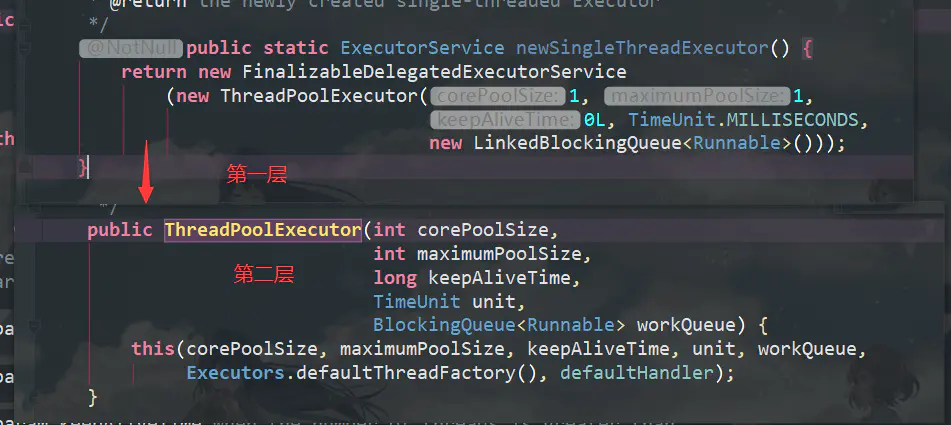
而点开其他几个线程池到最后都可以发现,他们实际上用的就是这个ThreadPoolExecutor。我们把源代码粘过来分析,其实也就是这七大参数
/**
* Creates a new {@code ThreadPoolExecutor} with the given initial
* parameters.
*
* @param corePoolSize the number of threads to keep in the pool, even
* if they are idle, unless {@code allowCoreThreadTimeOut} is set
* @param maximumPoolSize the maximum number of threads to allow in the
* pool
* @param keepAliveTime when the number of threads is greater than
* the core, this is the maximum time that excess idle threads
* will wait for new tasks before terminating.
* @param unit the time unit for the {@code keepAliveTime} argument
* @param workQueue the queue to use for holding tasks before they are
* executed. This queue will hold only the {@code Runnable}
* tasks submitted by the {@code execute} method.
* @param threadFactory the factory to use when the executor
* creates a new thread
* @param handler the handler to use when execution is blocked
* because the thread bounds and queue capacities are reached
* @throws IllegalArgumentException if one of the following holds:<br>
* {@code corePoolSize < 0}<br>
* {@code keepAliveTime < 0}<br>
* {@code maximumPoolSize <= 0}<br>
* {@code maximumPoolSize < corePoolSize}
* @throws NullPointerException if {@code workQueue}
* or {@code threadFactory} or {@code handler} is null
*/
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
毫无悬念,这就是最后一种方式,也是其他实现方式的基础。而用这种方式也是最容易控制,因为我们可以自由的设置参数。在阿里巴巴开发手册中也提到了

所以我们更需要去了解这七大参数,在平时用线程池的时候尽量去用ThreadPoolExecutor。而关于这七大参数我们简单概括就是
- corePoolSize: 线程池核心线程个数
- workQueue: 用于保存等待执行任务的阻塞队列
- maximunPoolSize: 线程池最大线程数量
- ThreadFactory: 创建线程的工厂
- RejectedExecutionHandler: 队列满,并且线程达到最大线程数量的时候,对新任务的处理策略
- keeyAliveTime: 空闲线程存活时间
- TimeUnit: 存活时间单位
而关于线程池最大线程数量,我们也有两种设置方式
- CPU密集型
获得cpu的核数,不同的硬件不一样,设置核数的的线程数量。
我们可以通过代码Runtime.getRuntime().availableProcessors();获取,然后设置。 - IO密集型
IO非常消耗资源,所有我们需要计算大型的IO程序任务有多少个。
一般来说,线程池最大值 > 大型任务的数量即可
一般设置大型任务的数量*2
这里我们用一个例子可以更好理解这些参数在线程池里面的位置和作用。
如图,我们这是一个银行
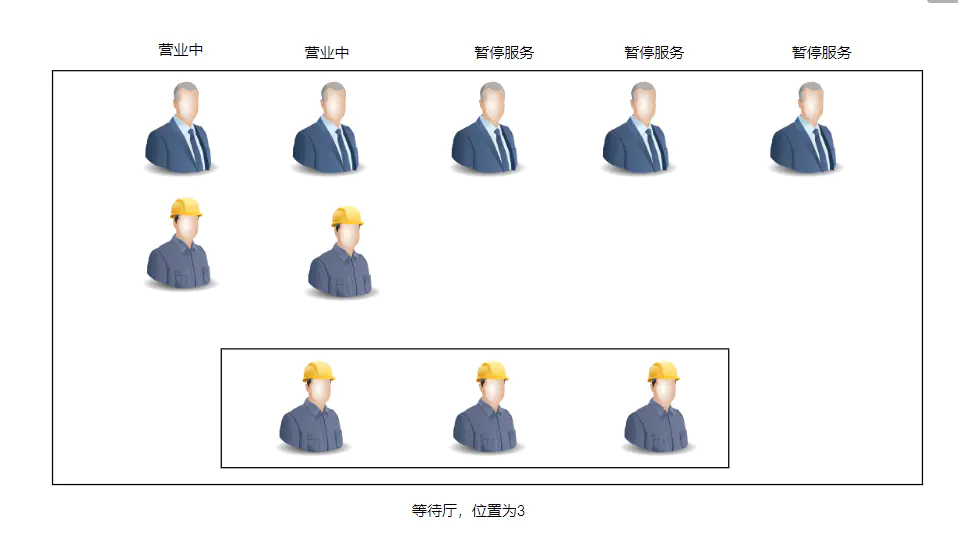
我们一共有五个柜台,可以理解为线程池的最大线程数量,而其中有两个是在营业中,可以理解为线程池核心线程个数。而下面的等待厅可以理解为用于保存等待执行任务的阻塞队列。银行就是创建线程的工厂。
而关于空闲线程存活时间,我们可以理解为如下图这种情况,当五个营业中,却只有两个人需要被服务,而其他三个人一直处于等待的情况下,等了一个小时了,他们被通知下班了。这一个小时时间就可以说是空闲线程存活时间,而存活时间单位,顾名思义。
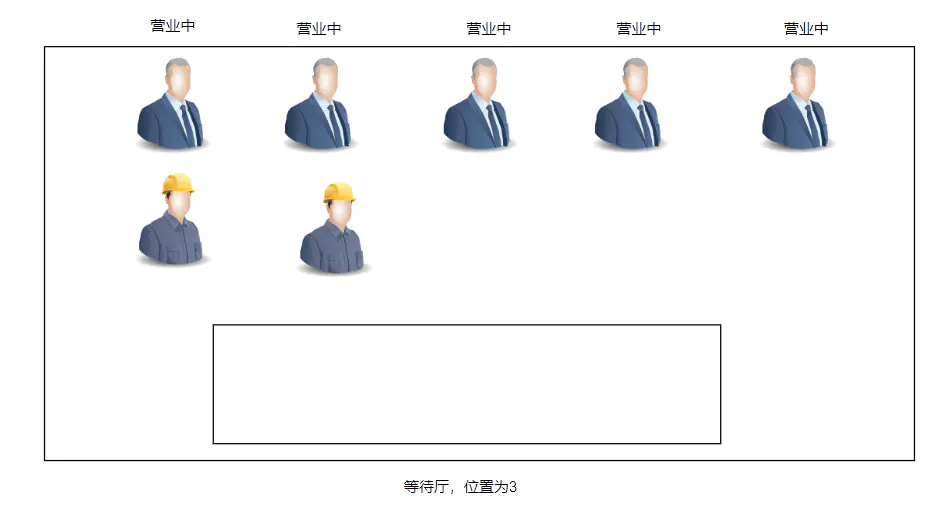
到现在我们就剩一个拒绝策略还没介绍,什么是拒绝策略呢?我们可以假设当银行五个柜台都有人在被服务,如下图。而等待厅这个时候也是充满了人,银行实在容不下人了。
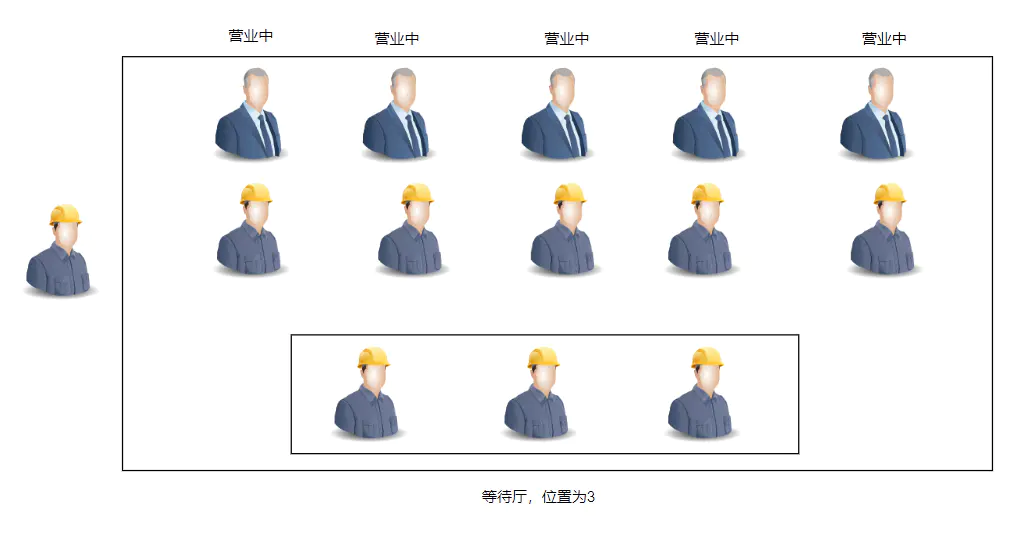
这个时候对银行外面那个等待的人的处理策略就是拒绝策略。
我们同样了解之后用代码来测试一下:
public static void test05(){
ExecutorService threadPool = new ThreadPoolExecutor(
//核心线程数量
2,
//最大线程数量
5,
//空闲线程存活时间
3,
//存活单位
TimeUnit.SECONDS,
//这里我们使用大多数线程池都默认使用的阻塞队列,并使容量为3
new LinkedBlockingDeque<>(3),
Executors.defaultThreadFactory(),
//我们使用默认的线程池都默认用的拒绝策略
new ThreadPoolExecutor.AbortPolicy()
);
try {
//对线程进行执行十条打印任务
for(int i = 1; i <= 2; i++){
threadPool.execute(()->{
System.out.println(Thread.currentThread().getName()+"=>执行完毕!");
});
}
} catch (Exception e) {
e.printStackTrace();
} finally {
//用完线程池一定要记得关闭
threadPool.shutdown();
}
}
我们执行打印两条任务,可以发现线程池只用到了我们的核心两条线程,相当于只有两个人需要被服务,所以我们就开了两个柜台。
pool-1-thread-1=>执行完毕!
pool-1-thread-2=>执行完毕!
但是在我们将打印任务改到大于5的时候,(我们改成8)我们可以发现线程池的五条线程都在使用了,人太多了,我们的银行需要都开放了来服务。
for(int i = 1; i <= 8; i++)
pool-1-thread-1=>执行完毕!
pool-1-thread-1=>执行完毕!
pool-1-thread-1=>执行完毕!
pool-1-thread-1=>执行完毕!
pool-1-thread-2=>执行完毕!
pool-1-thread-3=>执行完毕!
pool-1-thread-4=>执行完毕!
pool-1-thread-5=>执行完毕!
在我们改成大于8的时候,可以发现拒绝策略触发了。银行实在容纳不下了,所以我们把外面那个人用策略打发了。
for(int i = 1; i <= 9; i++)
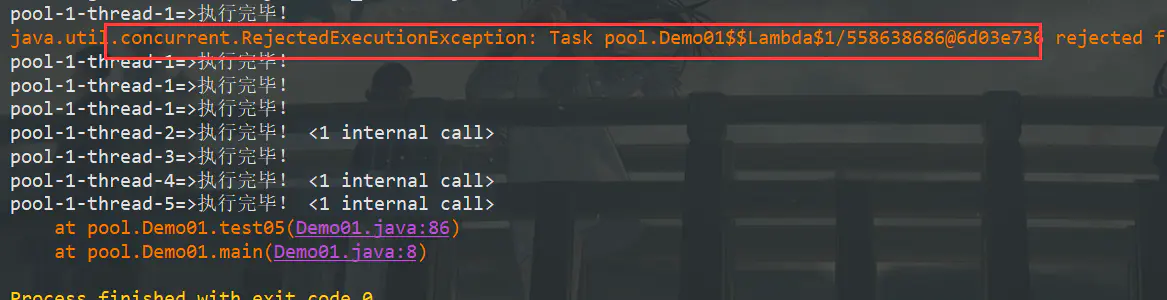
在这里我们也可以得出一个结论:
线程池大小= 最大线程数 + 阻塞队列大小
在上面我们在使用的阻塞队列是大多数的线程池都使用的阻塞队列,所以就引发思考下面这个问题。
为什么大部分的线程池都用LinkedBlockingQueue?
- LinkedBlockingQueue 使用单向链表实现,在声明LinkedBlockingQueue的时候,可以不指定队列长度,长度为Integer.MAX_VALUE, 并且新建了一个Node对象,Node对象具有item,next变量,item用于存储元素,next指向链表下一个Node对象,在刚开始的时候链表的head,last都指向该Node对象,item、next都为null,新元素放在链表的尾部,并从头部取元素。取元素的时候只是一些指针的变化,LinkedBlockingQueue给put(放入元素),take(取元素)都声明了一把锁,放入和取互不影响,效率更高。
- ArrayBlockingQueue 使用数组实现,在声明的时候必须指定长度,如果长度太大,造成内存浪费,长度太小,并发性能不高,如果数组满了,就无法放入元素,除非有其他线程取出元素,放入和取出都使用同一把锁,因此存在竞争,效率比LinkedBlockingQueue低。
四种策略
我们在使用ThreadPoolExecutor的时候是可以自己选择拒绝策略的,而拒绝策略我们所知道的有四种。
- AbortPolicy(被拒绝了抛出异常)
- CallerRunsPolicy(使用调用者所在线程执行,就是哪里来的回哪里去)
- DiscardOldestPolicy(尝试去竞争第一个,失败了也不抛异常)
- DiscardPolicy(默默丢弃、不抛异常)
AbortPolicy
我们在上面使用的就是AbortPolicy拒绝策略,在执行打印任务超出线程池大小的时候,抛出了异常。
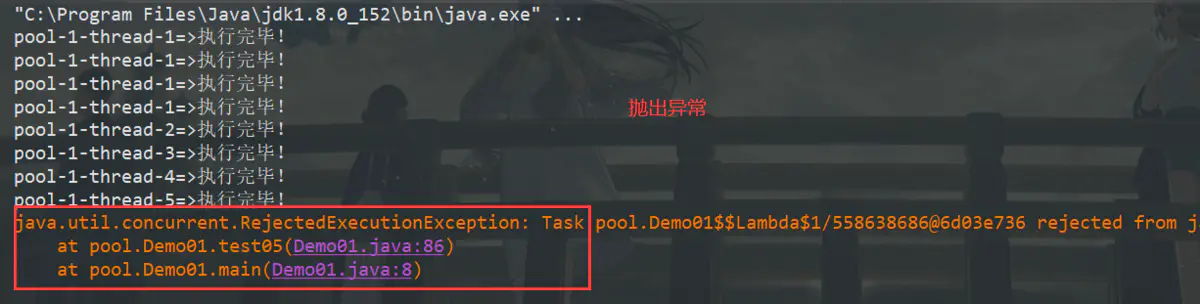
CallerRunsPolicy
我们将拒绝策略修改为CallerRunsPolicy,执行后可以发现,因为第九个打印任务被拒绝了,所以它被调用者所在的线程执行了,也就是我们的main线程。(因为它从main线程来的,现在又回到了main线程。所以我们说它从哪里来回哪里去)
ExecutorService threadPool = new ThreadPoolExecutor(
//核心线程数量
2,
//最大线程数量
5,
//空闲线程存活时间
3,
//存活单位
TimeUnit.SECONDS,
//这里我们使用大多数线程池都默认使用的阻塞队列,并使容量为3
new LinkedBlockingDeque<>(3),
Executors.defaultThreadFactory(),
//我们使用默认的线程池都默认用的拒绝策略
new ThreadPoolExecutor.CallerRunsPolicy()
);
pool-1-thread-2=>执行完毕!
main=>执行完毕!
pool-1-thread-2=>执行完毕!
pool-1-thread-1=>执行完毕!
pool-1-thread-2=>执行完毕!
pool-1-thread-1=>执行完毕!
pool-1-thread-3=>执行完毕!
pool-1-thread-4=>执行完毕!
pool-1-thread-5=>执行完毕!
DiscardOldestPolicy
尝试去竞争第一个任务,但是失败了。这里就没显示了,也不抛出异常。
pool-1-thread-1=>执行完毕!
pool-1-thread-1=>执行完毕!
pool-1-thread-1=>执行完毕!
pool-1-thread-1=>执行完毕!
pool-1-thread-2=>执行完毕!
pool-1-thread-3=>执行完毕!
pool-1-thread-4=>执行完毕!
pool-1-thread-5=>执行完毕!
DiscardPolicy
多出来的任务,默默抛弃掉,也不抛出异常。
pool-1-thread-1=>执行完毕!
pool-1-thread-1=>执行完毕!
pool-1-thread-1=>执行完毕!
pool-1-thread-1=>执行完毕!
pool-1-thread-2=>执行完毕!
pool-1-thread-3=>执行完毕!
pool-1-thread-4=>执行完毕!
pool-1-thread-5=>执行完毕!
可以看到我们的DiscardOldestPolicy与DiscardPolicy一样的结果,但是它们其实是不一样,正如我们最开始总结的那样,DiscardOldestPolicy在多出的打印任务的时候会尝试去竞争,而不是直接抛弃掉,但是很显然竞争失败不然也不会和DiscardPolicy一样的执行结果。但是如果在线程比较多的时候就可以很看出来。