Unicode简介
单机此处查看原文。
Unicode provides a unique number for every character, no matter what the platform, program, or language is.
Fundamentally, computers just deal with numbers. They store letters and other characters by assigning a number for each one. Before the Unicode standard was developed, there were many different systems, called character encodings, for assigning these numbers. These earlier character encodings were limited and did not cover characters for all the world’s languages. Even for a single language like English, no single encoding covered all the letters, punctuation, and technical symbols in common use. Pictographic languages, such as Japanese, were a challenge to support with these earlier encoding standards.
Early character encodings also conflicted with one another. That is, two encodings could use the same number for two different characters, or use different numbers for the same character. Any given computer might have to support many different encodings. However, when data is passed between computers and different encodings it increased the risk of data corruption or errors.
Character encodings existed for a handful of “large” languages. But many languages lacked character support altogether.
UTF
A Unicode transformation format (UTF) is an algorithmic mapping from every Unicode code point (except surrogate code points) to a unique byte sequence. The ISO/IEC 10646 standard uses the term “UCS transformation format” for UTF; the two terms are merely synonyms for the same concept.
The Unicode Standard supports three character encoding forms: UTF-32, UTF-16, and UTF-8. Each encoding form maps the Unicode code points U+0000..U+D7FF and U+E000..U+10FFFF to unique code unit sequences. The size of the code unit is specified for each encoding form.
Which of the UTFs do I need to support?
UTF-8 is most common on the web. UTF-16 is used by Java and Windows. UTF-8 and UTF-32 are used by Linux and various Unix systems. The conversions between all of them are algorithmically based, fast and lossless. This makes it easy to support data input or output in multiple formats, while using a particular UTF for internal storage or processing.
What are some of the differences between the UTFs?
The following table summarizes some of the properties of each of the UTFs.
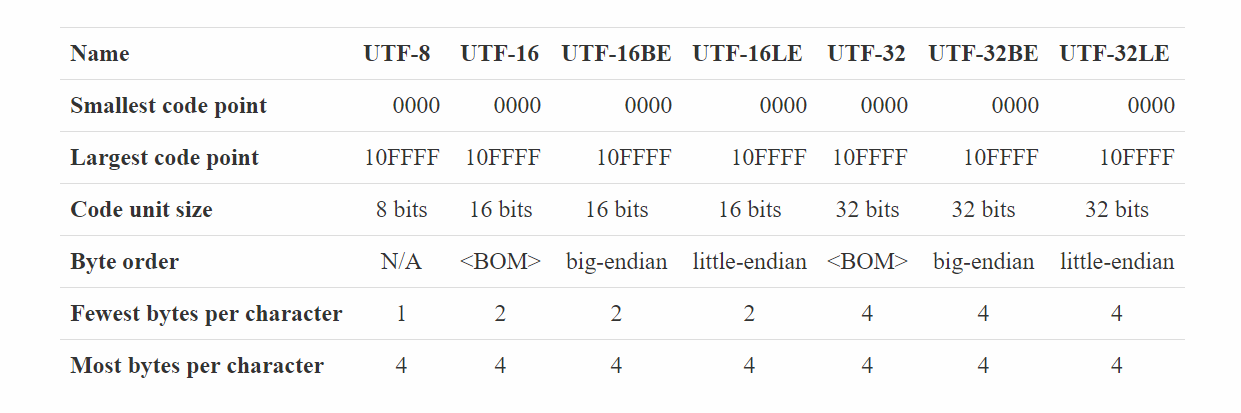
code point、code unit等的含义,stackoverflow上的解答比较到位,如下:
-
Character is an overloaded term than can mean many things.
-
A code point is the atomic unit of information. Text is a sequence of code points. Each code point is a number which is given meaning by the Unicode standard.
-
A code unit is the unit of storage of a part of an encoded code point. In UTF-8 this means 8-bits, in UTF-16 this means 16-bits. A single code unit may represent a full code point, or part of a code point. For example, the snowman glyph (
☃) is a single code point but 3 UTF-8 code units, and 1 UTF-16 code unit. -
A grapheme is a sequence of one or more code points that are displayed as a single, graphical unit that a reader recognizes as a single element of the writing system. For example, both
aandäare graphemes, but they may consist of multiple code points (e.g.ämay be two code points, one for the base characterafollowed by one for the diaresis; but there's also an alternative, legacy, single code point representing this grapheme). Some code points are never part of any grapheme (e.g. the zero-width non-joiner, or directional overrides). -
A glyph is an image, usually stored in a font (which is a collection of glyphs), used to represent graphemes or parts thereof. Fonts may compose multiple glyphs into a single representation, for example, if the above
äis a single code point, a font may chose to render that as two separate, spatially overlaid glyphs. For OTF, the font's GSUB and GPOS tables contain substitution and positioning information to make this work. A font may contain multiple alternative glyphs for the same grapheme, too.