Http协议的认识
HTPP协议的定义:全称 Hyper text transfer protocol (超文本传输协议),主要作用是客户端和服务器端的交互,实现从WWW将文本传输到客户端进行渲染显示,就是我们常说的c/s,客户端和服务器模式。而且是个问答模式,只有客户端发送请求了,服务器端才会响应发送数据,是单向的。而现在webservice可以实现服务器端主动向客户端发送数据。
HTTP的两大特点:
1.无连接:http在传输之前是需要建立tcp/ip连接的,我的理解就是建立一条通道,建立一条客户端到服务端的通道,然后http开始发送请求;之前的版本,每一次http请求和响应完成后,这条连接是自动关闭的,所以每一次请求都会频繁的建立tcp/ip连接,从http1.1版本后,在报头里面有个connection来控制这条连接;当connection:close时候,还是像以前一样,响应完后关闭;如果设置为connection:keep-alive;都会在一定的时间内,监听是否还有请求,没有的话,则会去关闭它;这个时间是由timeout来控制的。
2.无状态:每一次http事务,都是没有联系的。就是说同一个客户端这次请求和上次请求在服务端是分辨不出来的,所以采用了cookie和session来解决无状态协议;用来识别同一个用户;
如何理解HTTP是应用层协议:换句话说就是软件上的一种协议。
以下是ISO模型和TCP/IP模型的比较
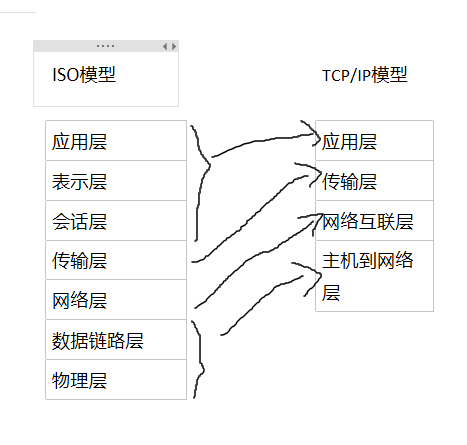
我们所说的HTTP协议就是工作在顶层的协议,然后往下看,会到传输层,再到网络层,也就是建立tcp/ip连接;最后通过我们的实际链路进行传输交互;
这里在扩展一个知识点:TCP和UDP的区别
TCP是必须先请求服务器端,询问我这由数据是否可以开始传送,当服务器端给出回复可以的话,就建立好了连接,然后客户端开始发送请求数据了;
但是UDP是直接把数据发送过去,没有征求你的同意,这样的话由优点也有缺点
1.首先服务器端可能暂时没办法接收和处理数据,你硬塞给它的话,肯定会造成数据的丢包,这就是最大的漏洞;
2.UDP减少了询问的时间,当然效率也就比较高了。
而我们通常都是用TCP,相对来说安全,不至于丢包,如果数据量小且不重要的倒是可以考虑UDP;个人见解;
HTTP工作流程:
http的每一次过程都被称为一个事务,这个事务是没有记忆能力的。
第一步:根据URL上的域名,在本地host中查找ip与端口号,若没有,则到DHCP中进行查找;
第二步:根据ip和端口,访问web服务器,请求建立连接,也就是TCP三次握手的第一步;
第三步:服务端接到请求做出反应,回复可以开始传输数据;TCP三次握手的第二步;
第四步:就是http发送请求数据,TCP三次握手的第三步;
第五步:服务器接受到http的请求数据,则进行响应,并返回一定的数据;
第六步:客户端根据得到的数据继续渲染显示。
URL:uniform resource locator 统一资源定位符,其实就是描述资源的位置,好让我们通过http协议去获取到。
例子: http://www.baidu.com/admin/index.php?name=maoxiaohai#
第一个:http 说明采用的是http协议;
第二个:www.baidu.com 会到域池里面也就是DHCP去获取到对应的ip和端口,http的默认端口是80,https是采用了ssl的,默认端口是443
第三个就是 admin/ 就是文件夹路径
第四个:index.php就是我们访问的文件
第五个:?后面的name=maoxiaohai就是我们携带过去的参数
第六个:#是个锚,具体是什么没去研究。民间高手可以留言下,互相请教;
接下来就是关于http请求和响应的格式了。
1.请求:请求行,请求报头,请求数据
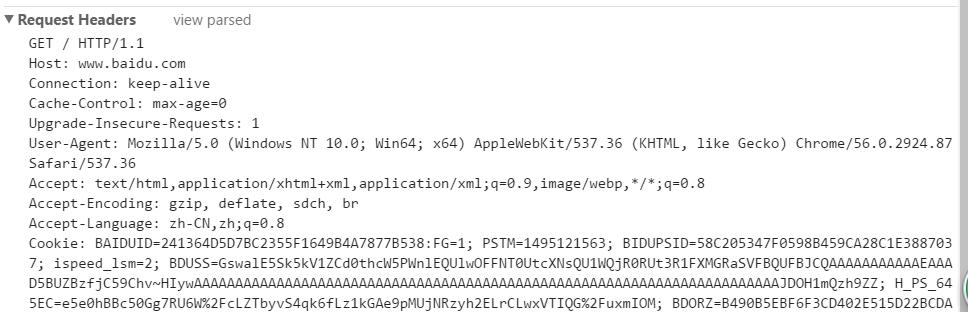
如上图所示:
第一部分:请求行,包括请求方式,ur资源路径,协议版本号。
第二部分:开始就是报头,由报头名: 报头名 格式构成;
第三部分:就是请求数据;
请求方式主要有 get post 的方式。其他的比如head put delete之类的自行百度,我也不知道具体应用在哪里,有大神会的可以给我留言。
最难的理解就是在报头那,其实报头也就是相当传输了一些数据到服务器端;我们可以通过$_server 来获取这些报头信息,比如可以看浏览器信息,请求的主机名等
1.Host:就是我们请求的主机名,域名;
2.Connection:控制tcp/ip的连接关闭
3.Cach-Controll:缓存控制,其实就是控制缓存是否存储到客户端;
4.User-Agent:用户代理,就是描述了浏览器的一些配置信息和系统配置信息,主要用处在服务器可以根据一定的规则判断是手机访问还是PC端。
5.Accept:接收什么样的格式文件,通常都是text/html之类的文件
6.Accept-Encoding:可以接收的压缩格式,大家也知道文件压缩后传输速度快好多,http传输时候会先压缩,然后传输过来,再解压缩。这个就是给服务器说我可以接收哪些格式的压缩文件,然后你可以用这个格式传输过来。
7.Accept-Language:接受的语言编码
8.Cookie:传送cookie过去。
2.响应:状态行,响应报头,响应数据
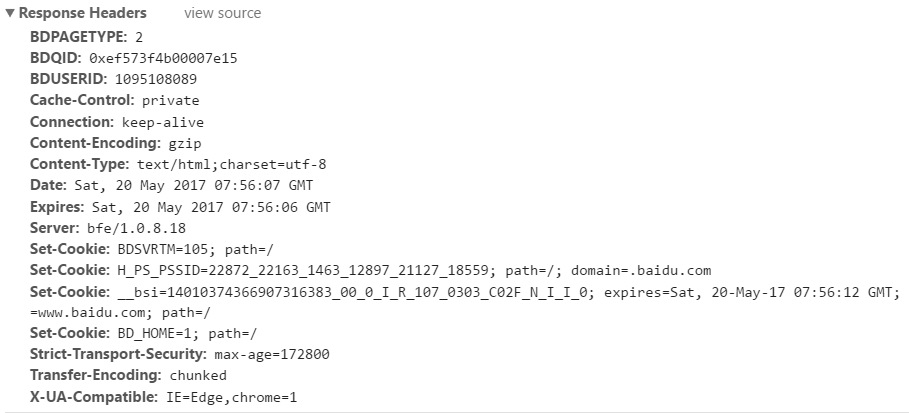
前面几个是百度的自定义报头文件。
Content-Type:返回的内容的类型和编码格式
Expires:缓存的过期时间
Server:web服务器信息
Set-Cookie:设置cookie
Transfer-Encoding:分块传输
等更多的定义自行百度。
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。互联网+时代,时刻要保持学习,携手千锋PHP,Dream It Possible。