接口自动化测试,完整入门
原文转自:http://www.cnblogs.com/lovesoo/p/7845731.html#_label1
1. 什么是接口测试
顾名思义,接口测试是对系统或组件之间的接口进行测试,主要是校验数据的交换,传递和控制管理过程,以及相互逻辑依赖关系。其中接口协议分为HTTP,WebService,Dubbo,Thrift,Socket等类型,测试类型又主要分为功能测试,性能测试,稳定性测试,安全性测试等。
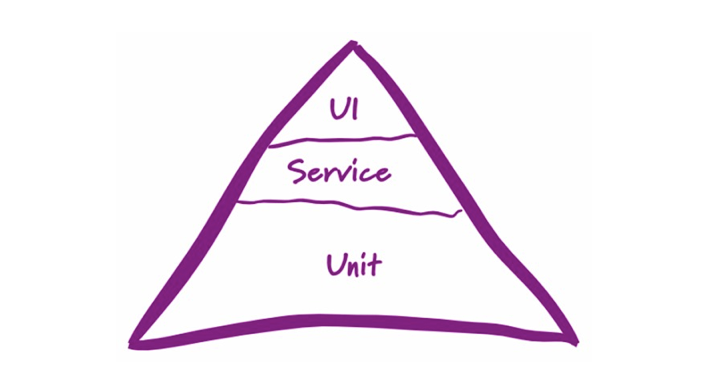
在分层测试的“金字塔”模型中,接口测试属于第二层服务集成测试范畴。相比UI层(主要是WEB或APP)自动化测试而言,接口自动化测试收益更大,且容易实现,维护成本低,有着更高的投入产出比,是每个公司开展自动化测试的首选。
下面我们以一个HTTP接口为例,完整的介绍接口自动化测试流程:从需求分析到用例设计,从脚本编写、测试执行到结果分析,并提供完整的用例设计及测试脚本。
2. 基本流程
基本的接口功能自动化测试流程如下:
需求分析 -> 用例设计 -> 脚本开发 -> 测试执行 -> 结果分析
2.1 示例接口
接口名称:豆瓣电影搜索
接口调用示例:
1) 按演职人员搜索:https://api.douban.com/v2/movie/search?q=张艺谋
3. 需求分析
需求分析是参考需求、设计等文档,在了解需求的基础上还需清楚内部的实现逻辑,并且可以在这一阶段提出需求、设计存在的不合理或遗漏之处。
如:豆瓣电影搜索接口,我理解的需求即是支持对片名,演职人员及标签的搜索,并分页返回搜索结果。
4. 用例设计
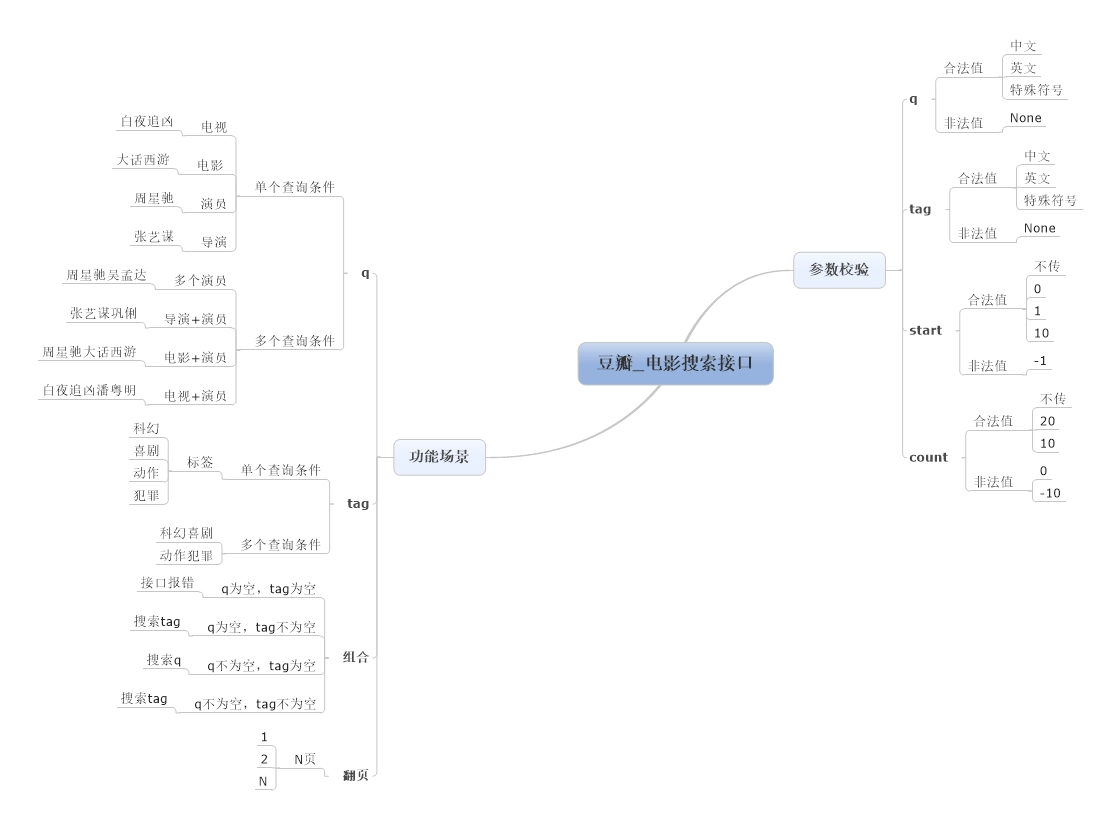
用例设计是在理解接口测试需求的基础上,使用MindManager或XMind等思维导图软件编写测试用例设计,主要内容包括参数校验,功能校验、业务场景校验、安全性及性能校验等,常用的用例设计方法有等价类划分法,边界值分析法,场景分析法,因果图,正交表等。
针对豆瓣电影搜索接口功能测试部分,我们主要从参数校验,功能校验,业务场景校验三方面,设计测试用例如下:
5. 脚本开发
依据上面编写的测试用例设计,我们使用python+nosetests框架编写了相关自动化测试脚本。可以完整实现接口自动化测试、自动执行及邮件发送测试报告功能。
5.1 相关lib安装
必要的lib库如下,使用pip命令安装即可:
pip install nose pip install nose-html-reporting pip install requests
5.2 接口调用
使用requests库,我们可以很方便的编写上述接口调用方法(如搜索q=刘德华,示例代码如下):

#coding=utf-8 import requests import json url = 'https://api.douban.com/v2/movie/search' params=dict(q=u'刘德华') r = requests.get(url, params=params) print 'Search Params: ', json.dumps(params, ensure_ascii=False) print 'Search Response: ', json.dumps(r.json(), ensure_ascii=False, indent=4)
在实际编写自动化测试脚本时,我们需要进行一些封装。如下代码中我们对豆瓣电影搜索接口进行了封装,test_q方法只需使用nosetests提供的yield方法即可很方便的循环执行列表qs中每一个测试集:
class test_doubanSearch(object):
@staticmethod
def search(params, expectNum=None):
url = 'https://api.douban.com/v2/movie/search'
r = requests.get(url, params=params)
print 'Search Params:
', json.dumps(params, ensure_ascii=False)
print 'Search Response:
', json.dumps(r.json(), ensure_ascii=False, indent=4)
def test_q(self):
# 校验搜索条件 q
qs = [u'白夜追凶', u'大话西游', u'周星驰', u'张艺谋', u'周星驰,吴孟达', u'张艺谋,巩俐', u'周星驰,大话西游', u'白夜追凶,潘粤明']
for q in qs:
params = dict(q=q)
f = partial(test_doubanSearch.search, params)
f.description = json.dumps(params, ensure_ascii=False).encode('utf-8')
yield (f,)
我们按照测试用例设计,依次编写每个功能的自动化测试脚本即可。
5.3 结果校验
在手工测试接口的时候,我们需要通过接口返回的结果判断本次测试是否通过,自动化测试也是如此。
对于本次的接口,我们搜索“q=刘德华”,我们需要判断返回的结果中是否含有“演职人员刘德华或片名刘德华”,搜索“tag=喜剧”时,需要判断返回的结果中电影类型是否为“喜剧”,结果分页时需要校验返回的结果数是否正确等。完整结果校验代码如下:
class check_response():
@staticmethod
def check_result(response, params, expectNum=None):
# 由于搜索结果存在模糊匹配的情况,这里简单处理只校验第一个返回结果的正确性
if expectNum is not None:
# 期望结果数目不为None时,只判断返回结果数目
eq_(expectNum, len(response['subjects']), '{0}!={1}'.format(expectNum, len(response['subjects'])))
else:
if not response['subjects']:
# 结果为空,直接返回失败
assert False
else:
# 结果不为空,校验第一个结果
subject = response['subjects'][0]
# 先校验搜索条件tag
if params.get('tag'):
for word in params['tag'].split(','):
genres = subject['genres']
ok_(word in genres, 'Check {0} failed!'.format(word.encode('utf-8')))
# 再校验搜索条件q
elif params.get('q'):
# 依次判断片名,导演或演员中是否含有搜索词,任意一个含有则返回成功
for word in params['q'].split(','):
title = [subject['title']]
casts = [i['name'] for i in subject['casts']]
directors = [i['name'] for i in subject['directors']]
total = title + casts + directors
ok_(any(word.lower() in i.lower() for i in total),
'Check {0} failed!'.format(word.encode('utf-8')))
@staticmethod
def check_pageSize(response):
# 判断分页结果数目是否正确
count = response.get('count')
start = response.get('start')
total = response.get('total')
diff = total - start
if diff >= count:
expectPageSize = count
elif count > diff > 0:
expectPageSize = diff
else:
expectPageSize = 0
eq_(expectPageSize, len(response['subjects']), '{0}!={1}'.format(expectPageSize, len(response['subjects'])))
5.4 执行测试
对于上述测试脚本,我们使用nosetests命令可以方便的运行自动化测试,并可使用nose-html-reporting插件生成html格式测试报告。
运行命令如下:
nosetests -v test_doubanSearch.py:test_doubanSearch --with-html --html-report=TestReport.html
5.5 发送邮件报告
测试完成之后,我们可以使用smtplib模块提供的方法发送html格式测试报告。基本流程是读取测试报告 -> 添加邮件内容及附件 -> 连接邮件服务器 -> 发送邮件 -> 退出,示例代码如下:
import smtplib
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
def send_mail():
# 读取测试报告内容
with open(report_file, 'r') as f:
content = f.read().decode('utf-8')
msg = MIMEMultipart('mixed')
# 添加邮件内容
msg_html = MIMEText(content, 'html', 'utf-8')
msg.attach(msg_html)
# 添加附件
msg_attachment = MIMEText(content, 'html', 'utf-8')
msg_attachment["Content-Disposition"] = 'attachment; filename="{0}"'.format(report_file)
msg.attach(msg_attachment)
msg['Subject'] = mail_subjet
msg['From'] = mail_user
msg['To'] = ';'.join(mail_to)
try:
# 连接邮件服务器
s = smtplib.SMTP(mail_host, 25)
# 登陆
s.login(mail_user, mail_pwd)
# 发送邮件
s.sendmail(mail_user, mail_to, msg.as_string())
# 退出
s.quit()
except Exception as e:
print "Exceptioin ", e
6. 结果分析
打开nosetests运行完成后生成的测试报告,可以看出本次测试共执行了51条测试用例,50条成功,1条失败。
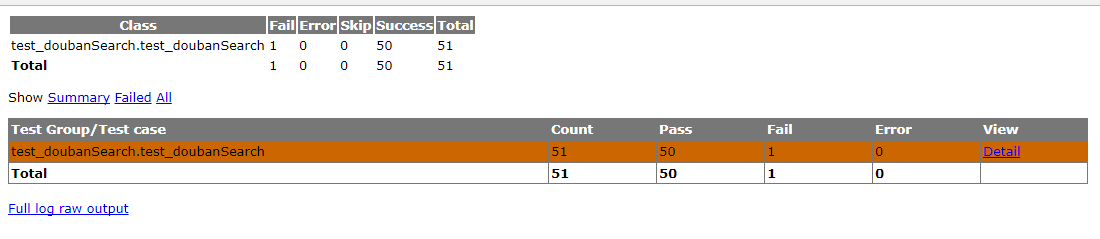
失败的用例可以看到传入的参数是:{"count": -10, "tag": "喜剧"},此时返回的结果数与我们的期望结果不一致(count为负数时,期望结果是接口报错或使用默认值20,但实际返回的结果数目是189。赶紧去给豆瓣提bug啦- -)

7. 完整脚本
豆瓣电影搜索接口的完整自动化测试脚本,我已上传到的GitHub。下载地址:https://github.com/lovesoo/test_demo/tree/master/test_douban
下载完成之后,使用如下命令即可进行完整的接口自动化测试并通过邮件发送最终的测试报告:
python test_doubanSearch.py
最终发送测试报告邮件,截图如下: